竞赛:糖尿病遗传风险检测挑战赛(科大讯飞)


目录
8.2将训练集20%划分为验证集,使用LightGBM完成训练
一、赛事背景
截至2022年,中国糖尿病患者近1.3亿。中国糖尿病患病原因受生活方式、老龄化、城市化、家族遗传等多种因素影响。同时,糖尿病患者趋向年轻化。
糖尿病可导致心血管、肾脏、脑血管并发症的发生。因此,准确诊断出患有糖尿病个体具有非常重要的临床意义。糖尿病早期遗传风险预测将有助于预防糖尿病的发生。
根据《中国2型糖尿病防治指南(2017年版)》,糖尿病的诊断标准是具有典型糖尿病症状(烦渴多饮、多尿、多食、不明原因的体重下降)且随机静脉血浆葡萄糖≥11.1mmol/L或空腹静脉血浆葡萄糖≥7.0mmol/L或口服葡萄糖耐量试验(OGTT)负荷后2h血浆葡萄糖≥11.1mmol/L。
在这次比赛中,您需要通过训练数据集构建糖尿病遗传风险预测模型,然后预测出测试数据集中个体是否患有糖尿病,和我们一起帮助糖尿病患者解决这“甜蜜的烦恼”。
二、赛事任务
2.1 数据集字段说明
编号:标识个体身份的数字;
性别:1表示男性,0表示女性;
出生年份:出生的年份;
体重指数:体重除以身高的平方,单位kg/m2;
糖尿病家族史:标识糖尿病的遗传特性,记录家族里面患有糖尿病的家属,分成三种标识,分别是父母有一方患有糖尿病、叔叔或者姑姑有一方患有糖尿病、无记录;
舒张压:心脏舒张时,动脉血管弹性回缩时,产生的压力称为舒张压,单位mmHg;
口服耐糖量测试:诊断糖尿病的一种实验室检查方法。比赛数据采用120分钟耐糖测试后的血糖值,单位mmol/L;
胰岛素释放实验:空腹时定量口服葡萄糖刺激胰岛β细胞释放胰岛素。比赛数据采用服糖后120分钟的血浆胰岛素水平,单位pmol/L;
肱三头肌皮褶厚度:在右上臂后面肩峰与鹰嘴连线的重点处,夹取与上肢长轴平行的皮褶,纵向测量,单位cm;
患有糖尿病标识:数据标签,1表示患有糖尿病,0表示未患有糖尿病。
2.2 训练集说明
训练集(比赛训练集.csv)一共有5070条数据,用于构建您的预测模型(您可能需要先进行数据分析)。数据的字段有编号、性别、出生年份、体重指数、糖尿病家族史、舒张压、口服耐糖量测试、胰岛素释放实验、肱三头肌皮褶厚度、患有糖尿病标识(最后一列),您也可以通过特征工程技术构建新的特征。
2.3 测试集说明
测试集(比赛测试集.csv)一共有1000条数据,用于验证预测模型的性能。数据的字段有编号、性别、出生年份、体重指数、糖尿病家族史、舒张压、口服耐糖量测试、胰岛素释放实验、肱三头肌皮褶厚度。
三、提交说明
对于测试数据集当中的个体,您必须预测其是否患有糖尿病(患有糖尿病:1,未患有糖尿病:0),预测值只能是整数1或者0。提交的数据应该具有如下格式:
uuid,label
1,0
2,1
3,1
...
本次比赛中,预测模型的结果文件需要命名成:预测结果.csv,然后提交。请确保您提交的文件格式规范。
四、评估指标
对于提交的结果,系统会采用二分类任务中的F1-score指标进行评价,F1-score越大说明预测模型性能越好,F1-score的定义如下:

其中:


五、数据分析
5.1导入数据
- 解压比赛数据,并使用pandas进行读取;
import pandas as pd
train_df = pd.read_csv('./糖尿病遗传风险预测挑战赛公开数据/比赛训练集.csv', encoding='gbk')
test_df = pd.read_csv('./糖尿病遗传风险预测挑战赛公开数据/比赛测试集.csv', encoding='gbk')
print(train_df.shape, test_df.shape)
print(train_df.dtypes, test_df.dtypes)5.2查看训练集和测试集字段类型
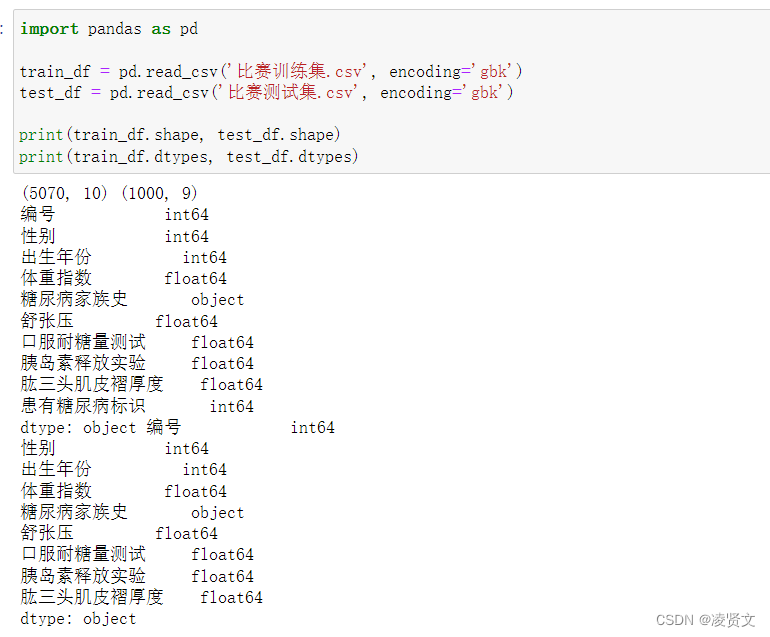
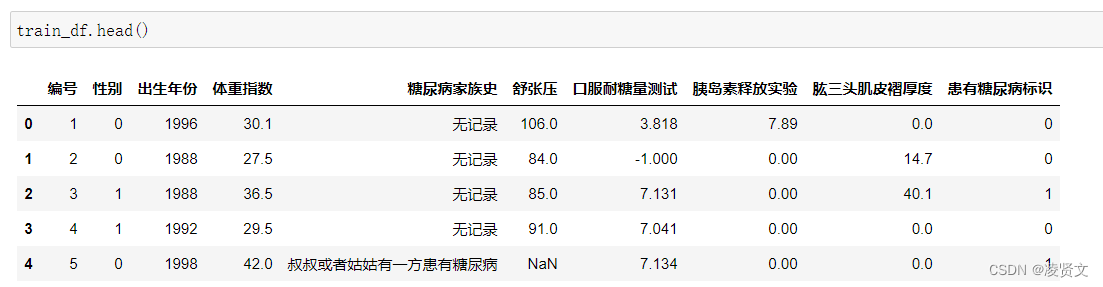
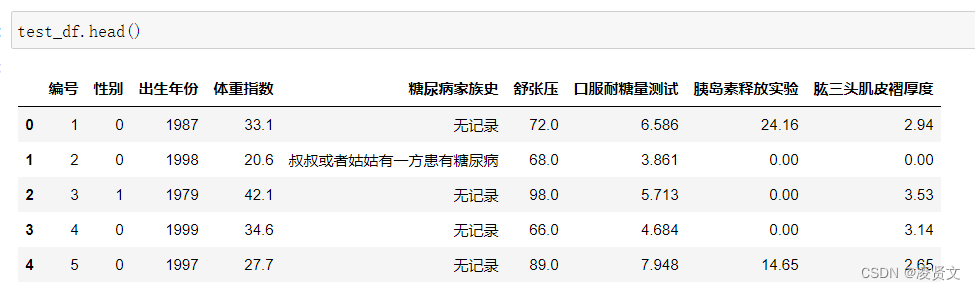
![]()
5.3统计字段的缺失值
train_df.isnull().sum()编号 0
性别 0
出生年份 0
体重指数 0
糖尿病家族史 0
舒张压 247
口服耐糖量测试 0
胰岛素释放实验 0
肱三头肌皮褶厚度 0
患有糖尿病标识 0
dtype: int64test_df.isnull().sum()编号 0
性别 0
出生年份 0
体重指数 0
糖尿病家族史 0
舒张压 49
口服耐糖量测试 0
胰岛素释放实验 0
肱三头肌皮褶厚度 0
dtype: int64训练集和测试集各列缺失比例计算
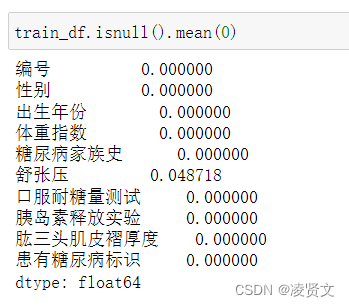
![]()

![]()
唯一包含缺失值的是舒张压这一列,且缺失值占比不大。
但是明显的发现训练集中:
口服耐糖量测试为-1的也属于缺失值,胰岛素释放实验为0的也属于缺失值,肱三头肌厚度为0的也属于缺失值,待后面在处理。
5.4分析字段类型

![]() 截图来自阿水。
截图来自阿水。

训练集和测试集描述

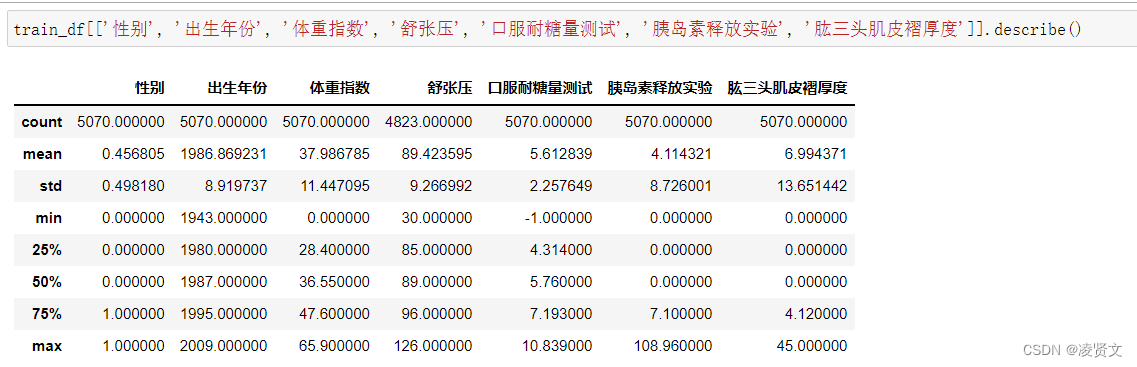
5.5字段相关性
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['FangSong'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 训练集相关性热力图矩阵
plt.subplots(figsize=(10,10))
sns.heatmap(train_df.corr(method='pearson'), annot=True, vmax=1, square=True, cmap='YlGnBu')
plt.savefig('train_pearson.jpg', dpi=800)
如何画热力图:
# 测试集相关性热力图矩阵
plt.subplots(figsize=(10,10))
sns.heatmap(test_df.corr(method='pearson'), annot=True, vmax=1, square=True, cmap='YlGnBu')
plt.savefig('test_pearson.jpg', dpi=800)
从热力图可以看出,训练集中体重指数和肱三头肌皮褶厚度与标签的相关性相对较高,肱三头肌皮褶厚度与标签的相关性最高。各字段之间的相关性普遍不高。
六、逻辑回归尝试
6.1导入sklearn的逻辑回归
# 构建逻辑回归模型
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import MinMaxScaler
from sklearn.pipeline import make_pipeline# 构建逻辑回归模型
model = make_pipeline(
MinMaxScaler(),
LogisticRegression()
)
model.fit(train_dataset,train_data["患有糖尿病标识"])
6.2使用训练集和逻辑回归进行训练,并在测试集上进行预测;
test_dataset["label"] = model.predict(test_dataset.drop(["编号"],axis=1))test_dataset.rename({"编号":'uuid'},axis=1)[['uuid','label']].to_csv("submit_lr.csv",index=None)
6.3提交结果

6.4尝试决策树模型
# 尝试构建决策树模型
model = make_pipeline(
MinMaxScaler(),
DecisionTreeClassifier()
)
model.fit(train_dataset,train_data["患有糖尿病标识"])
test_dataset["label"] = model.predict(test_dataset.drop(["编号",'label'],axis=1))
test_dataset.rename({"编号":'uuid'},axis=1)[['uuid','label']].to_csv("submit_dt.csv",index=None)结果:

七、特征工程
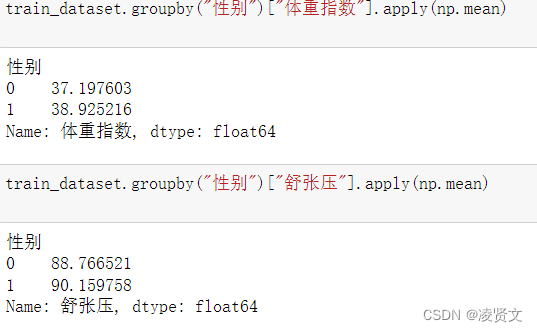
7.1统计每个性别对应的[体重指数]、[舒张压]平均值
train_dataset.groupby("性别")["体重指数"].apply(np.mean)
![]()
7.2计算每个患者与每个性别平均值的差异
"""
人体的成人体重指数正常值是在18.5-24之间
低于18.5是体重指数过轻
在24-27之间是体重超重
27以上考虑是肥胖
高于32了就是非常的肥胖。
"""
def BMI(a):
if a<18.5:
return 0
elif 18.5<=a<=24:
return 1
elif 24<a<=27:
return 2
elif 27<a<=32:
return 3
else:
return 4
data['BMI']=data['体重指数'].apply(BMI)
data['出生年份']=2022-data['出生年份'] #换成年龄
#糖尿病家族史
"""
无记录
叔叔或者姑姑有一方患有糖尿病/叔叔或姑姑有一方患有糖尿病
父母有一方患有糖尿病
"""
def FHOD(a):
if a=='无记录':
return 0
elif a=='叔叔或者姑姑有一方患有糖尿病' or a=='叔叔或姑姑有一方患有糖尿病':
return 1
else:
return 2
data['糖尿病家族史']=data['糖尿病家族史'].apply(FHOD)
data['舒张压']=data['舒张压'].fillna(-1)
"""
舒张压范围为60-90
"""
def DBP(a):
if a<60:
return 0
elif 60<=a<=90:
return 1
elif a>90:
return 2
else:
return a
data['DBP']=data['舒张压'].apply(DBP)
data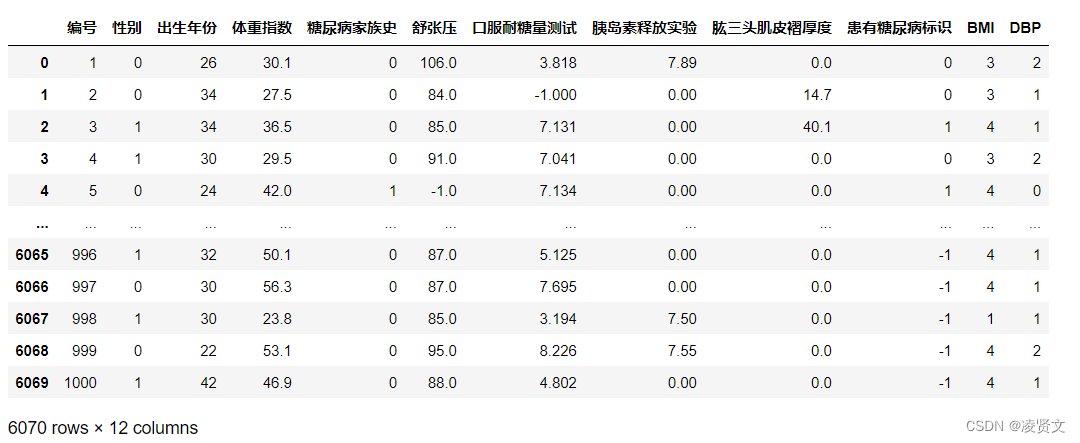
八、高阶树模型
8.1安装lightgbm
import lightgbm as lgb
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import MinMaxScaler
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
8.2将训练集20%划分为验证集,使用LightGBM完成训练
train_data = pd.read_csv("比赛训练集.csv",encoding='gbk')
test_data = pd.read_csv("比赛测试集.csv",encoding='gbk')
train_data = pd.get_dummies(train_data)
test_data = pd.get_dummies(test_data)
# 划分数据集
train_x,valid_x = train_test_split(train_data,test_size=0.2)clf_lgb = lgb.LGBMClassifier(
max_depth=3,
n_estimators=4000,
n_jobs=-1,
verbose=-1,
verbosity=-1,
learning_rate=0.1,
)
clf_lgb.fit(train_x.drop(["患有糖尿病标识"],axis=1),train_x["患有糖尿病标识"])
predicts = clf_lgb.predict(valid_x.drop(["患有糖尿病标识"],axis=1))
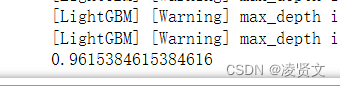
print(accuracy_score(valid_x["患有糖尿病标识"], predicts))
[LightGBM] [Warning] verbosity is set=-1, verbose=-1 will be ignored. Current value: verbosity=-1
0.9546351084812623# 搜索参数
kfold = StratifiedKFold(n_splits=5,shuffle=True,random_state=2022)
classifier = lgb.LGBMClassifier()
params = {
" max_depth":[4,5,6],
"n_estimators":[3000,4000,5000],
"learning_rate":[0.15,0.2,0.25]
}
clf = GridSearchCV(estimator=classifier,param_grid=params,verbose=True,cv=kfold)
clf.fit(train_x.drop(["患有糖尿病标识"],axis=1),train_x["患有糖尿病标识"])
predicts1 = clf.best_estimator_.predict(valid_x.drop(["患有糖尿病标识"],axis=1))
print(accuracy_score(valid_x["患有糖尿病标识"], predicts1))
九、多折训练与集成
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.model_selection import KFold
import lightgbm as lgb
# 读取数据
train_df = pd.read_csv('./糖尿病遗传风险预测挑战赛公开数据/比赛训练集.csv', encoding='gbk')
test_df = pd.read_csv('./糖尿病遗传风险预测挑战赛公开数据/比赛测试集.csv', encoding='gbk')
# 基础特征工程
train_df['体重指数_round'] = train_df['体重指数'] // 10
test_df['体重指数_round'] = train_df['体重指数'] // 10
train_df['口服耐糖量测试'] = train_df['口服耐糖量测试'].replace(-1, np.nan)
test_df['口服耐糖量测试'] = test_df['口服耐糖量测试'].replace(-1, np.nan)
dict_糖尿病家族史 = {
'无记录': 0,
'叔叔或姑姑有一方患有糖尿病': 1,
'叔叔或者姑姑有一方患有糖尿病': 1,
'父母有一方患有糖尿病': 2
}
train_df['糖尿病家族史'] = train_df['糖尿病家族史'].map(dict_糖尿病家族史)
test_df['糖尿病家族史'] = test_df['糖尿病家族史'].map(dict_糖尿病家族史)
train_df['糖尿病家族史'] = train_df['糖尿病家族史'].astype('category')
test_df['糖尿病家族史'] = train_df['糖尿病家族史'].astype('category')
train_df['性别'] = train_df['性别'].astype('category')
test_df['性别'] = train_df['性别'].astype('category')
train_df['年龄'] = 2022 - train_df['出生年份']
test_df['年龄'] = 2022 - test_df['出生年份']
train_df['口服耐糖量测试_diff'] = train_df['口服耐糖量测试'] - train_df.groupby('糖尿病家族史').transform('mean')['口服耐糖量测试']
test_df['口服耐糖量测试_diff'] = test_df['口服耐糖量测试'] - test_df.groupby('糖尿病家族史').transform('mean')['口服耐糖量测试']
# 模型交叉验证
def run_model_cv(model, kf, X_tr, y, X_te, cate_col=None):
train_pred = np.zeros( (len(X_tr), len(np.unique(y))) )
test_pred = np.zeros( (len(X_te), len(np.unique(y))) )
cv_clf = []
for tr_idx, val_idx in kf.split(X_tr, y):
x_tr = X_tr.iloc[tr_idx]; y_tr = y.iloc[tr_idx]
x_val = X_tr.iloc[val_idx]; y_val = y.iloc[val_idx]
call_back = [
lgb.early_stopping(50),
]
eval_set = [(x_val, y_val)]
model.fit(x_tr, y_tr, eval_set=eval_set, callbacks=call_back, verbose=-1)
cv_clf.append(model)
train_pred[val_idx] = model.predict_proba(x_val)
test_pred += model.predict_proba(X_te)
test_pred /= kf.n_splits
return train_pred, test_pred, cv_clf
clf = lgb.LGBMClassifier(
max_depth=3,
n_estimators=4000,
n_jobs=-1,
verbose=-1,
verbosity=-1,
learning_rate=0.1,
)
train_pred, test_pred, cv_clf = run_model_cv(
clf, KFold(n_splits=5),
train_df.drop(['编号', '患有糖尿病标识'], axis=1),
train_df['患有糖尿病标识'],
test_df.drop(['编号'], axis=1),
)
print((train_pred.argmax(1) == train_df['患有糖尿病标识']).mean())
test_df['label'] = test_pred.argmax(1)
test_df.rename({'编号': 'uuid'}, axis=1)[['uuid', 'label']].to_csv('submit.csv', index=None)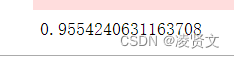
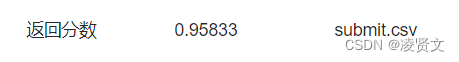
第一次参加数据挖掘的竞赛,很多地方借鉴大佬的,学到了很多,下次努力。

- 点赞
- 收藏
- 关注作者
评论(0)