【数据挖掘实战】—使用xgboost实现酒店信息消歧

前面我们讲解了数据挖掘思维,也介绍了一些数据挖掘所使用的算法,那么今天我们就从实际情况出发,看看数据挖掘该如何在工作中发挥作用。XGB 算法 我们在前面的章节已经做过一些了解,它是由决策树衍生出来的一种算法,在做实验和工业生产中都有非常好的效果。
项目背景
有一天,酒店的业务人员突然找到我,说希望我们能够提供一个算法服务去为酒店信息做一个自动化的匹配,以通过算法的手段,找到那些确定相同的酒店和确定不同的酒店,这就是一个最基本的需求提案。
理解业务
当用户在马蜂窝打开一家选中的酒店时,不同供应商提供的预订信息会形成一个聚合列表准确地展示给用户。这样做首先避免同样的信息多次展示给用户影响体验,更重要的是帮助用户进行全网酒店实时比价,快速找到性价比最高的供应商,完成消费决策。
遵循着我们前面所学的数据挖掘流程,首先来看下我们的业务需求。
刚一接到上面的需求提案,我或许没有办法立即给出一个结果,由于我本身并不是酒店业务人员,对于酒店业务的具体场景并不了解,所以这个事情能不能做、能够做到什么程度都不太明确,那么接下来我们就要跟业务方进行更加深入的沟通。
酒旅平台接入了大量的供应商,不同供应商会提供很多相同的酒店,但对同一酒店的描述可能会存在差异,比如:
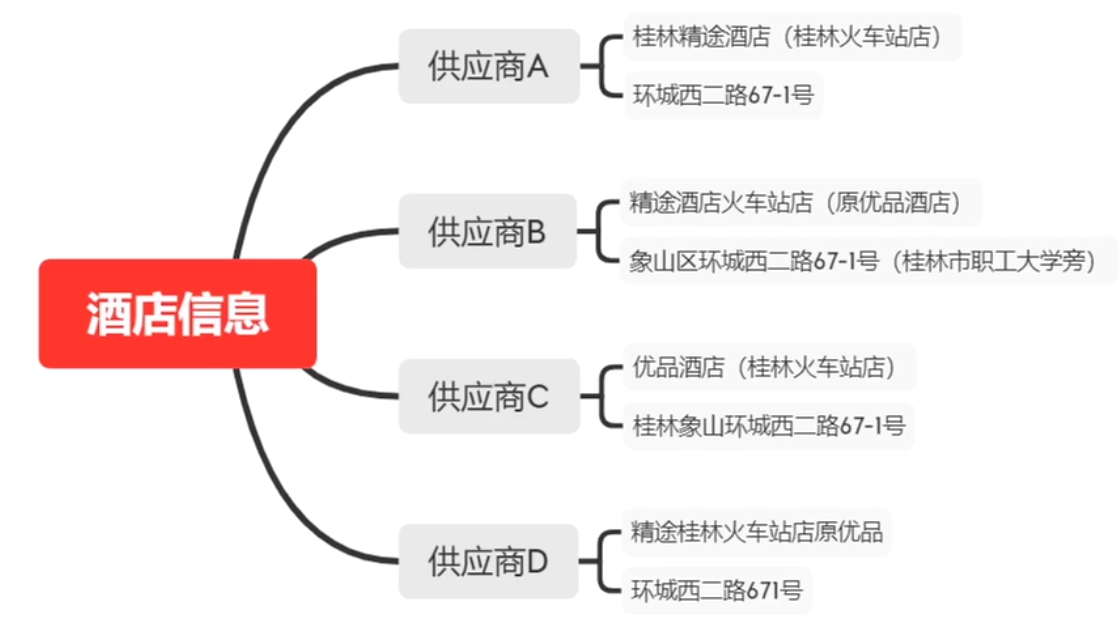
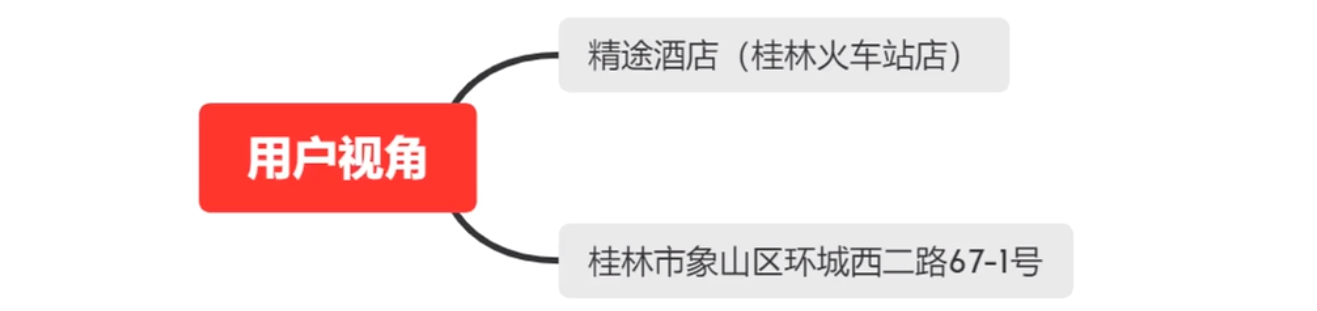
而我们希望在用户视角看到如下图的内容,所以我们要对不同供应商提供的数据进行信息消歧。
在没有使用算法的时候,处理酒店信息主要以一些简单的规则进行匹配,规则的准确率较高,但是只能处理不到 10%的数据,还有 90%多的数据都需要运营人员进行人工对比。人工对文字和图片的内容相对比较敏感,但是对于数值型数据,比如经纬度却很难去判断,同时单个人工也很难掌握大量的地理位置信息知识,人工对比的成本之高可想而知。
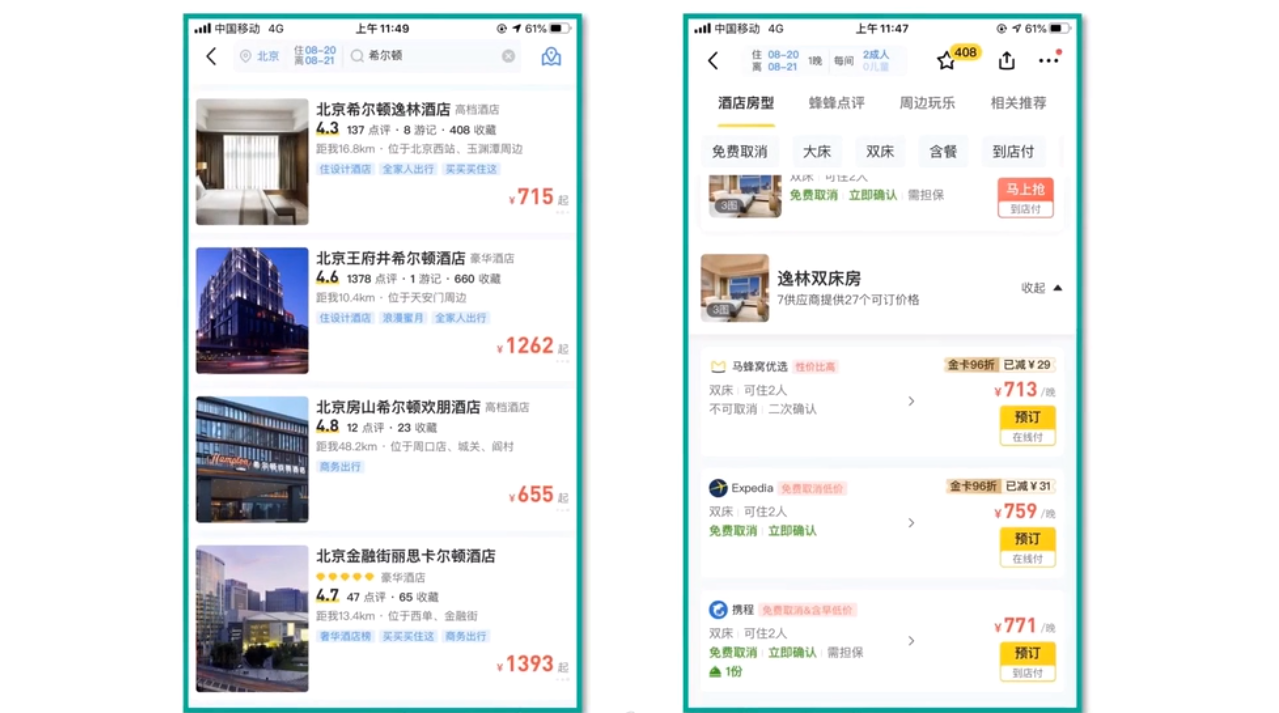
下图是对不同供应商的酒店进行聚合后的效果,不同供应商的报价都在同一页面进行展示,用户在预定时更加方便。
理解数据
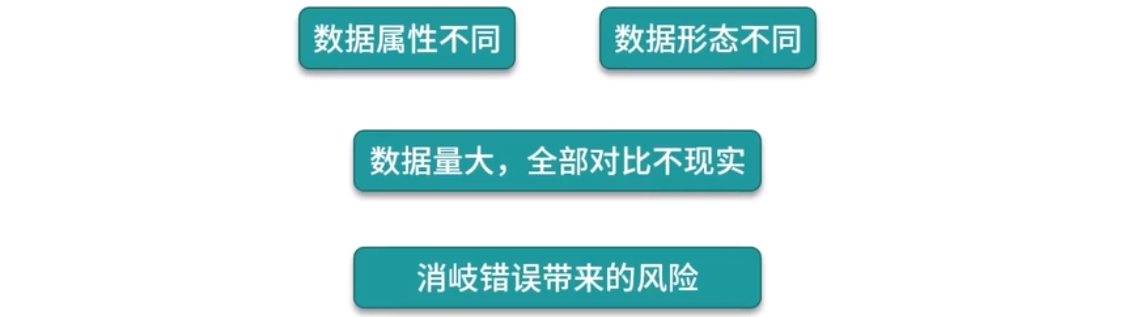
经过上面的沟通,我们已经大致了解了要解决的问题以及业务的背景是什么样子的。接下来,还要结合我们的数据来进行分析,以确定我们的问题是否能够得到解决。在查看数据的时候,我们发现了这样一些问题:
数据属性不同: 由于有很多家供应商,他们提供的数据也各有特色。比如一些国内的供应商只提供了中文酒店名称,一些国外的供应商只提供了英文的酒店名称,而有些供应商会提供中英双语的名称;有些供应商会提供酒店的邮箱,有些供应商的数据里则没有这个字段。他们提供的数据属性存在很大的差异,这会影响到我们的特征处理。
数据形态不同: 除了属性,数据的形态也有很多区别。有些供应商提供的国外酒店名称是当地的语言,比如日语,韩语,泰语等;有些供应商提供的名称中的数字可能是繁体数字,而有些提供的是罗马数字,有些是阿拉伯数字;有些供应商提供的描述是经过抽取的标签化描述,而有些提供的描述是酒店自己提供的大篇幅文字。这些字段虽然相同,但是内部存在着很大的差异,在做算法的时候也会产生很大的影响。
数据量大,全部对比不现实: 在我们的数据库中,已经存在了数百万的酒店数据,而每一家供应商又会提供那么大一份数据。如果新数据要和库中的所有数据逐条进行对比,这是一个非常大的工程量,在处理时效上将无法完成要求。所以我们还需要更进一步沟通,以确定算法如何与业务进行结合,更好地发挥作用。
消歧错误带来的风险: 对比一开始给出的例子,如果此时有一条数据是“桂林精品酒店(桂林火车站店),地址为环城西路 67 号”,这与上面的信息极其相似,如果我们在计算时恰好把这个数据也定义为与上面是同一家酒店,但实际上这是不同的两家酒店, 如果用户订了第一个酒店,但是实际上下单的是第二家,当他去到第一家酒店入住发现找不到时候,用户的体验可想而知了。
通过上面的工作,我们再次与业务方一起确认算法解决方案,我们将提供一个算法服务以计算两条数据是否属于同一家酒店,并给出“是 / 不是 / 无法确定”三种可靠的结果。同时我们的目标设定为提升运营效率,而不是完全解决酒店信息消歧的问题,通过算法与运营人员的结合实现业务目标。
此外,由于中文内容占据了大部分,我们计划先对中文的内容进行处理,而其他语言暂时不做处理,这样以最短的时间先处理收益最高的部分。
准备数据与模型训练
根据上面的理解,我们需要处理的是一个“分类”任务。而我们所能够拿到的数据非常有限,一条数据包含了两个酒店的信息字段:酒店名称、酒店地址、酒店经纬度。因为这三个字段相对比较齐全,在一期项目中能够处理较大范围的内容。
所以在准备数据环节,很重要的一步就是要去构建我们的特征。除此以外还有这两家酒店是否为同一家的标注。
当然第一步,我们要先处理前面提到的数据格式问题,把所有的数字都转换成阿拉伯数字,把所有的繁体字都转换成简体字。
# 过滤掉最后面的英文字符,并进行数字转换(转成阿拉伯数字),大小写转换(转成小写)
def ch2num(self, s):
s = list(s)
num = ['零', '一', '二', '三', '四', '五', '六', '七', '八', '九']
ch_num = ['零', '壹', '贰', '叁', '肆', '伍', '陆', '柒', '捌', '玖']
i, last, flag = len(s)-1, len(s), True
while i > -1:
if s[i] >= u'\u4e00' and s[i] <= u'\u9fa5' and flag:
last = i+1
flag = False
else:
if s[i] in num:
s[i] = num.index(s[i])
elif s[i] in ch_num:
s[i] = ch_num.index(s[i])
i -= 1
return ''.join(str(it) for it in s[: last]).lower()
名称分词
我们先来举个例子,思考我们该如何对这些酒店名称进行对比,比如:

显而易见地,我们会把这些内容拆解成我们可以处理的更加有信息含量的词汇,即:
7 天--->如家
酒店--->酒店
酒仙桥店--->望京店
所以要想对比准确,我们首先要对这些信息进行精准地分词。经过对大量酒店名称进行分析,我们把酒店名称分为如下结构化字段:
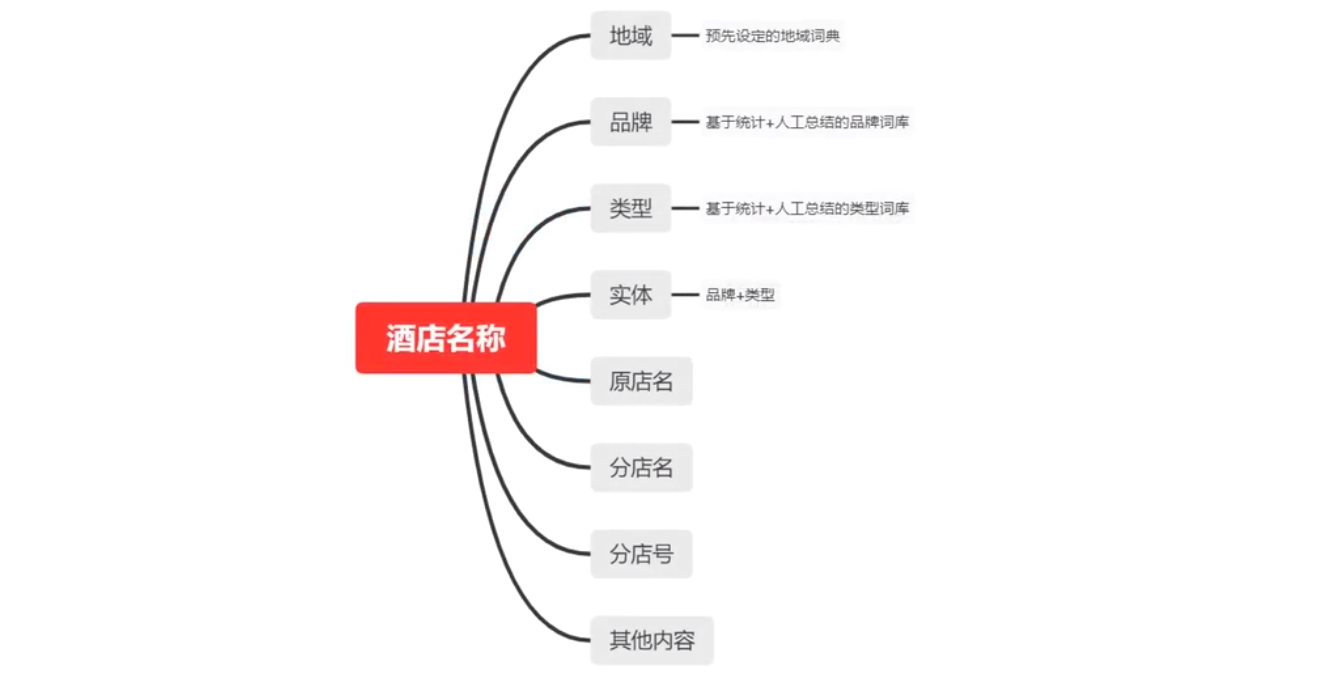
地址分词
在处理地址信息的时候也是按照这种方案,把地址拆解成更加详细、更加细粒度的词汇分别处理。具体分词方式见下图: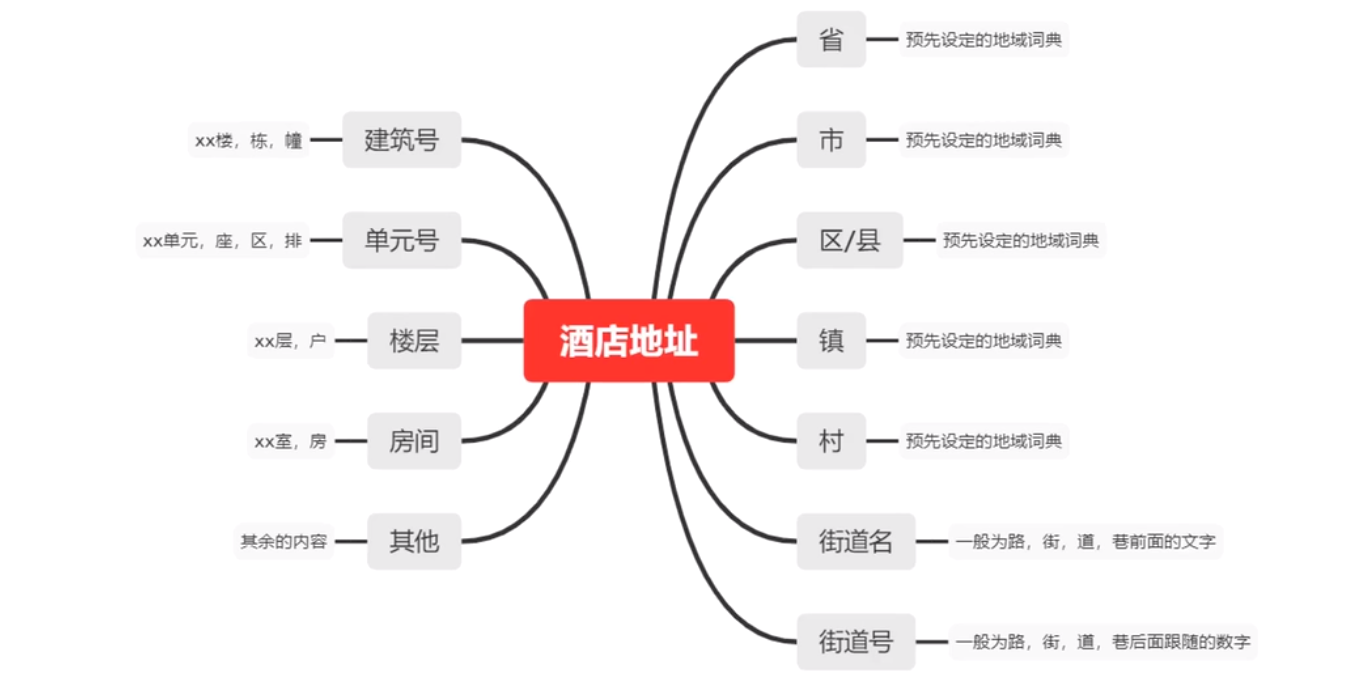
经过了上述分词的细化,我们有了 20 多个维度可以进行对比。当然,使用文字本身是没有办法直接进行对比的,我们还要把文字对比转化成数值类型,这里就要用到距离计算方法了。为了进一步扩展特征维度,我们对每一种特征又加入了三种距离计算方案:Levenshtein 距离、Jaro-Winkler 距离、q-gram距离。
当然距离计算的方案有很多,如果你对距离计算感兴趣,可以在网上查阅相关的资料,在 Python 中有一个开源工具包 Similarity 已经实现了大部分的计算方法。
# 计算Levenshtein距离
def levenshtein_vec(self, item1, item2):
vec = []
dist = Levenshtein()
for i in range(len(item1)):
vec.append(dist.distance(item1[i], item2[i]))
return vec
def jarowinkler_vec(self, item1, item2):
vec = []
dist = JaroWinkler()
for i in range(len(item1)):
vec.append(dist.similarity(item1[i], item2[i]))
return vec
def qgram_vec(self, item1, item2):
vec = []
dist = QGram(len(item1) if len(item1) <= len(item2) else len(item2))
for i in range(len(item1)):
vec.append(dist.distance(item1[i], item2[i]))
return vec
# 经纬度距离相对特殊 使用haversine距离 专门处理经纬度与物理距离计算的
def haversine(self, item1, item2): # [经度1,纬度1],[经度2,纬度2] (十进制度数)
“”"
Calculate the great circle distance between two points
on the earth (specified in decimal degrees)
“”"
# 将十进制度数转化为弧度
lon1, lat1, lon2, lat2 = map(radians, [float(item1[0]), float(item1[1]), float(item2[0]), float(item2[1])])
# haversine公式
dlon = lon2 - lon1
dlat = lat2 - lat1
a = sin(dlat / 2) ** 2 + cos(lat1) * cos(lat2) * sin(dlon / 2) ** 2
c = 2 * asin(sqrt(a))
r = 6371 # 地球平均半径,单位为公里
return [c * r * 1000]
模型训练与评估
准备好了特征,构建好了特征向量,我们就可以开始训练我们的模型了,到这里想必你已经十分清楚了,接下来就是要对具体的参数进行调节,以达到最佳的效果。当然参数通常已经有一组默认值,即便你不去修改,也能获得还不错的效果。
下面开始我们的模型训练:
完成了模型训练,但是所得到的结果可能并不能符合我们的需求,比如说准确率不够高,或者召回率不够高,这时需要我们仔细分析什么原因导致的这个结果,是我们的特征提取的不够多还是我们的数据不够好?具体原因需要具体分析,但总归会慢慢达到理想的结果。
像我们前面所说的,一个数据挖掘项目从训练到上线可能要经过多次迭代,从数据准备到模型训练再到模型评估,反反复复优化与验证,以使得我们的模型效果与业务需求趋于一致。
由于在我们的业务场景中,对准确率的需求更高,所以最终我们跟业务方达成一致意见:根据我们给出的“是”和“否”的概率值区间来判断是否足够置信,对于置信结果直接进入到合并或者新增环节;对于不那么置信的结果,仍然进入到人工审核环节进行二次校验。
这样,我们的一期工作就告一段落了,经过这个项目成功节省了 60%的运营人力。当然,这个项目还远没有结束,在后面的工作里,仍然在继续优化结果,同时探索诸如英文酒店的消歧工作,使用更多特征与模型来处理细节的场景,这里就不再详细介绍。
总结
在我们的工作中,算法部分往往成了最简单的环节,如何去处理需求、如何去构建特征、如何调整我们的思路才是我想要传达给你的。经过这一次实践,我希望你能够对数据挖掘在实际工作中是如何进行的能够有一定的理解。在后面的博客中,每一个模块也都会有实践课程,到时我再带你一一攻破。

- 点赞
- 收藏
- 关注作者
评论(0)