【数据挖掘】-模型怎么解决业务需求(五)

我们的目标是业务需求,而数据挖掘产出的结果。
不管是预测型的还是关联型的,都要结合业务场景,融入到业务流程中去。
模型部署本质――回归业务!
模型如何保存?
如何根据业务需求优化?
如何最终上线服务?
模型的保存
模型保存的规范。
存放的位置、名字的定义、模型使用的算法、参数、数据、效果等。
模型的优化
模型训练阶段优化所追求的目标―—效果要尽量好。
模型应用阶段优化所追求的目标――在效果尽量不降低的前提下,适配应用的限制。
时延要求比较高的场景
如果业务应用无法忍受模型的响应时间,需要思考增加机器还是降低模型的复杂度以提高速度。
模型大小要求比较高的场景
期望把人脸识别模型部署到一个摄像装置的小型存储芯片上面,需要考虑降低模型的参数维度等。
离线应用还是在线应用?
如果使用新闻分类的类别标签结果,实时分发到用户App中分类模型需要部署成在线的应用服务以实时响应新的内容请求。
如果只需要对一批已有的新闻数据进行分类处理,之后只使用这些结果模型离线运行,把存储的新闻处理完,或者每隔一段时间去处理新的数据。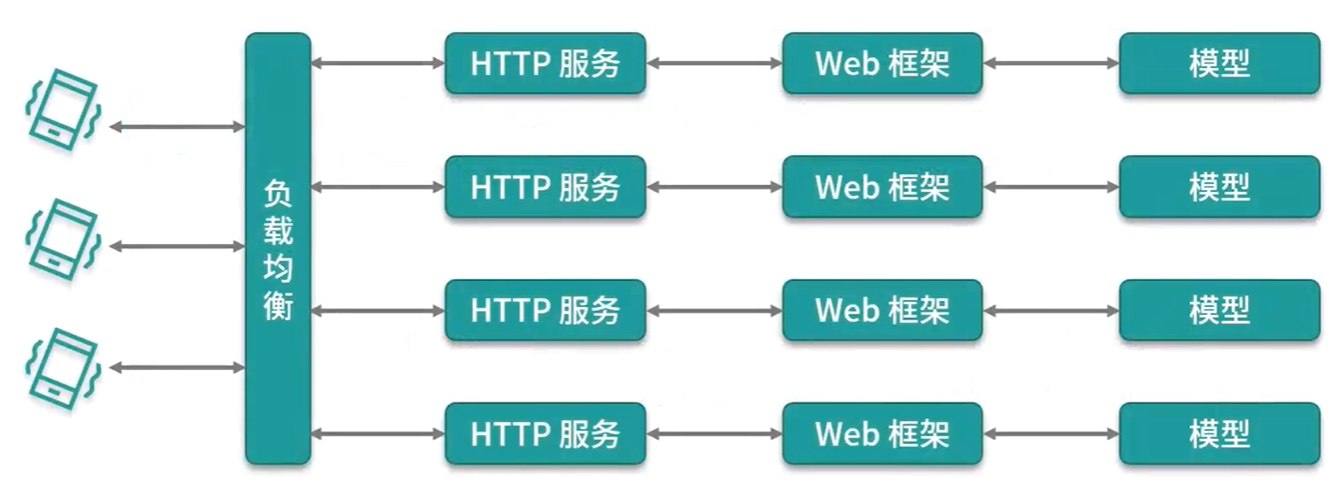
在线应用
一个简单部署方案

记录项目经历,学会总结和反思
从项目的需求发起,到数据准备,再到模型训练、评估、上线,这些环节都遇到了什么样的问题,我们解决了什么问题,又有哪些问题尚未解决,在时间等条件充裕的情况下还可以做哪些尝试。
多考虑一点,如何适合更多场景
我们的数据挖掘模型或结果能不能做成统一的服务,能不能应用在更多的地方
规划一个面向全公司更底层的标签体系架构以应对各种类似的业务。
监控与迭代
为了模型保持良好的效果,需要有一份迭代计划去维护和更新模型。
模型的监控

结果监控
结果监控主要是针对一些具体的指标进行监控。
还可以根据具体产出的结果在业务中的效果进行监控。
- 针对每天新闻的分类标签进行排名统计,来查看每个标签的占比情况与初始数据是否接近。
- 推荐系统中,可以对标签与CTR (点击率预估)的关系进行计算。
- 一些App会主动负反馈,让用户自己选择不喜欢的标签。
人工定期复审
主要针对业务需求准确率的情况进行评估。
查看当前的模型效果是否还满足业务的需求,准确率情况是否有所变化。
跟业务进行沟通评估,确认当前的情况是否需要对模型进行重新训练。
Case收集与样本积累
重新开启
- 准备数据阶段发现数据无法解决业务需求时,要返回去重新讨论业务需求与数据的问题。
- 训练模型阶段发现数据与模型无法匹配,或者如果要更换其他模型时,要回到准备数据环节。
- 模型评估的时候发现效果达不到预期可能要回到准备数据环节重新处理数据,甚至要回到理解业务阶段。
总结
介绍了一些关于模型保存、模型优化、模型部署的思路。讲解了关于项目总结,乃至模型监控等内容。

- 点赞
- 收藏
- 关注作者
评论(0)