机器学习--方差和偏差、Bagging、Boosting、Stacking


目录
一、方差和偏差
在统计学习中我们通常会使用方差和偏差来衡量一个模型,
- 偏差:训练到的模型与真实模型之间的区别(图中蓝点与加号之间的距离);
- 方差:每次学习的模型之间差别有多大;

![]()
图中【中间的加号指的是我们要学的真实模型的地方,圆圈是可容忍的区域,蓝色的圆指的是训练的模型得出的结果,蓝色的点的个数代表了所训练模型的个数】
- 如果所有训练的模型都在大圆内 且 与加号离得很近的话,我们可以认为模型有低偏差和低方差;
- 如果所有训练的模型没有在大圆内,那么可以说它的偏差很大;但是每一个蓝点之间差别没有那么大,就表示说方差是比较小的;
- 虽然每个蓝点基本都落到了大圆中,但是每个蓝点的距离比较大;这样偏差比较低,但是方差很大;
- 最差的一个情况是:每个蓝点既不落在大圆内且每次训练的不一样(之间的距离很大);即方差和偏差都是很大的
我们需要的是低偏差和低方差,这样会是比较好的模型,若出现其他三种情况的话,要考虑用其他方法使得方差和偏差都降低。
数学定义
假设每次采样都是从有噪声ε的函数f(x)中采样数据用于学习f_hat
通过学习使得f_hat与 真实的f 尽可能的相近(这是个回归问题可以用最小MSE(均方误差)来实现)
我们学习到之后需要通过 泛化误差 来衡量它;在统计学习中,我们想通过学习来使得模型能泛化到没有学习过的样本,所以我们需要优先优化 [y-f(x)_hat]^2 的期望值 = 偏差^2 + 方差 +噪声^2

![]()
对公式的解释

- 刚开始模型过于简单可能学不到真实数据所要表达的内容,这时的偏差的平方会很大,随着模型的逐渐复杂,模型可能可以学到所想表达的信息,所以偏差的平方逐渐变小;
- 随着模型变得越来越复杂,能够拟合的东西就越大,这样模型可能会过多的关注于噪音(数据还是那些数据 数据复杂度低),所以方差会变得越来越大;
- 泛化误差 = 数据本身的噪音,但是数据本身没有变化,应该是个常数;但是加上了偏差和方差,最后就会导致最后的泛化误差曲线就会跟图中的蓝线一样
- 跟之前讲过的下图有关。
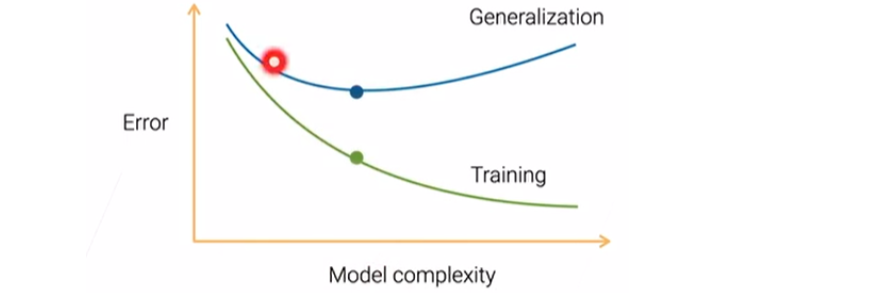
训练误差往往会跟偏差相关(偏差越小,模型就越容易拟合到数据上);图上两条线的差距可以说是方差在起作用。
减小偏差、方差、噪声
任务是减小泛化误差,那我们需要减小偏差、方差、噪声
- 减小偏差:偏差很大,说明模型复杂度可能不够,可以使用一个模型复杂度高一点的模型(在神经网络中可以 增加层数 增加隐藏层单元个数(宽度));也可使用【Boosting;Stacking】
- 减小方差:方差太大可能代表你的模型过于复杂,我们可以是用一个简单点的模型,或者是使用正则化(使用L2,L1正则项,限制住每个模型能够学习的范围);也可使用【Bagging;Stacking】
- 降低噪声:在统计学习中,这个是不可以降低的误差,但是在真实的场景,这是来自于数据采集,可以通过更精确的数据采集,更干净的数据来使得噪声降低
- 集成学习:使用多个模型来提升性能【上面提到的Boosting;Stacking;Bagging; 后面的小节会说】
总结
- 在统计学习中,我们可以把泛化误差分解为 偏差、误差和噪声三项;
- 集成学习能够将多个模型组合起来来降低偏差和。
二、Bagging
做bagging的时候,每次训练n个模型(base learners),但是每个模型都是独立并行训练的,在得到n个模型之后,
- 如果是回归问题,会把每一个模型的输出做平均就得到了bagging出来的效果
- 如果是做分类的话,这样每一个模型都会输出一个类别,然后会用这些输出做投票选最多的(这个叫Majority voting)
每个模型的训练是通过bootstrap采样得到的训练集上训练的
- 什么是bootstrap采样?假设训练集有m个样本,每一次训练base learner的时候,随机采样m个样本,每次采样我们会将这个样本放回去,可能有些样本会重复,如果有n个模型要这样训练,就重复n次
- 大概是有1-1/e ≈63%的概率会被采样到,就是说可能有37%的样本是没有采样出来的,可以用这个来做验证集,这个也叫做 out of bag。
代码实现
随机森林使用决策树来做base learner;
使用随机森林时的常用技术,在bootstrap样本时还会每次随机采样一些特征出来,但在这个地方就不会去采样重复的类出来,因为重复的类没有太大的意义;这样做主要的好处是随机采样之后可以避免一定的过拟合,而且能够增加每一棵决策树之间的差异性;
在右边的曲线图中,我们可以知道,随着learner的数量增加,模型的误差是逐渐减小的。但是泛化误差的曲线不会往上升,这是因为我们降低了方差但没使得偏差更大,这也就改善了泛化误差中三项其中的一项,但没增加另外两项。
bagging什么时候会变好
bagging主要下降的是方差,在统计上采样1次和采样n次取平均,它的均值是不会发生变化的就bias是不会发生变化的,唯一下降的是方差,采样的越多,方差相对来说变得越小。
方差什么时候下降的比较快,方差比较大的时候下降的相关比较好。
那什么时候方差大呢,方差比较大的模型我们叫做unstable的模型;以回归来举例子,真实的是f ,base learner是h,bagging之后 对每个学到的base learner的预测值取个均值 就会得到预测值f_hat;因为期望的平方会小于方差,所以h(x)与f(x)差别很大的时候,bagging的效果比较好。
也就是说,在base learner没那么稳定的时候,它对于下降方差的效果会好。
不稳定的learner
决策树不是一个稳定的learner,因为数据一旦发生变化,选取的特征然后选取特征的哪个值都会不一样,分支会不一样,故其不稳定;
线性回归比较稳定,数据的较小的变化,对模型不会有太大的影响 。
 总结
总结

bagging就是训练多个模型,每个模型就是通过在训练数据中通过bootstrap采样训练而来;
bootstrap就是每一次用m个样本,随机在训练数据中采样m个样本,且会放回继续采样
bagging的主要效果是能够降低方差,特别是当整个用来做bagging的模型是不稳定的模型的时候效果最佳(随机森林)。
三、Boosting
boosting 它是说将多个弱一点的模型(偏差比较大)组合起来变成强一点的模型(偏差比较小),主要是为了去降低偏差而不是方差【Bagging 把多个不那么稳定的模型把它们放在一起得到一个相对稳定的模型】
Boosting是要按顺序的学习【bagging是每个模型是独立的】
具体的做法:每一次在第i步的时候,会训练一个弱模型h i,然后去评估一下它的误差εt;然后根据当前的误差εt重新采样一下,使得接下来的模型h i+1会去关注那些预测不正确的样本;
比较著名的样例:AdaBoost,Gradient boosting
Gradient boosting
假设在时间 t 时训练好的模型时Ht(x),时间1时H1(x)=0
- 在残差上训练新的模型ht【残差指在m个样本中样本本身 特征不发生变化,标号变了 实际标号减去预测的标号(也就是后面说的拟合不够的差值)】
- 时间1时 是在原始的样本上进行训练,但是在之后的时间内,都是把当前时刻boosting的模型去拟合 拟合不够的那个差值
- 然后将ht * η(学习率)加进当前整个boosting出来的模型,变成下一个时刻boosting出来的模型【η是作为一个正则项,boosting中叫收缩】(当然η可以为1,但是这样很容易过拟合)。
- 残差实际上等价于 MSE作为损失函数时 损失函数L对函数H做负梯度。
为什么会讲gradient boosting?是因为其他的boosting 函数可以换到gradient boosting的框架里面(取决于要怎么去选损失函数L)
gradient boosting 的代码实现
class GradientBoosting:
def __init__(self, base_learner, n_learners, learning_rate):
self.learners = [clone(base_learner) for _ in range(n_learners)]
self.lr = learning_rate
def fit(self, X, y):
residual = y.copy()
for learner in self.learners:
learner.fit(X, residual)
residual -= self.lr * learner.predict(X)
def predict(self,X):
preds = [learner.predict(X) for learner in self.learners]
return np.array(preds).sum(axis=0) * self.lrgradient boosting的效果
- 用决策树作为weak learner(Gradient boosting 很容易 过拟合,所以我们需要对它做些正则化,需要用一个弱的模型来做)
- 但是决策树是一个强模型,我们需要限制树的最高层数,也可以随机采样一些特征(列)
- 在GBDT中模型没有过拟合(每一个小模型确实比较弱,学习率也定的比较低),当weak learner、学习率 控制得比较好的时候,它的过拟合现象没那么严重
- GBDT需要顺序训练,在大的训练集上会比较吃亏,所以会用一些加速算法如:XGBoost,lightGBM。
总结

- Boosting是说把n个弱一点的模型组合在一起变成一个比较强的模型,用于降低偏差。
- Gradient boosting 是boosting的一种,每一次弱的模型是去拟合 在标号上的残差,可以认为是每次去拟合给定损失函数的负梯度方向 。
四、Stacking
- stacking 跟之前个begging有一点像的,都是将多个base learner放在一起,来降低方差;
- 但是不同在于stacking的base learner可以有不同的模型类别;stacking的输出是concat起来的(模型种类不一样输出可能不同),然后再做线性的组合就得到最终的输出【begging是在数据上多次训练同样的模型;begging是所有模型的输出做平均或做投票】;
- 每个模型是在原始数据上训练不需要再通过bootstrap 的采样(如果base learner是随机森林的话是已经做了的)
- 竞赛中经常被使用,一般是每一个人训练不一样的模型,甚至是做不一样的特征提取,最后再将结果加起来 。
stacking的效果
stacking中每个模型的表现

直接使用的是AutoGluon的实现
做stacking的时候没有办法保证每一个模型的效果都很好,很多时候需要加入能够提升模型精度的模型。
多层stacking(降低偏差)
将第一层stacking的输出看成是特征送入下一层的stacking中(第二层的输入是基于上一层的输出,离最后的标号很近了,所以下一层训练起来会比较容易),这样可以把没有训练好的地方重新训练;
在这里也会将原始的特征直接与第一层的输出一起送入下一层
多层stacking很容易过拟合(同一份数据又送进去学了一遍)。
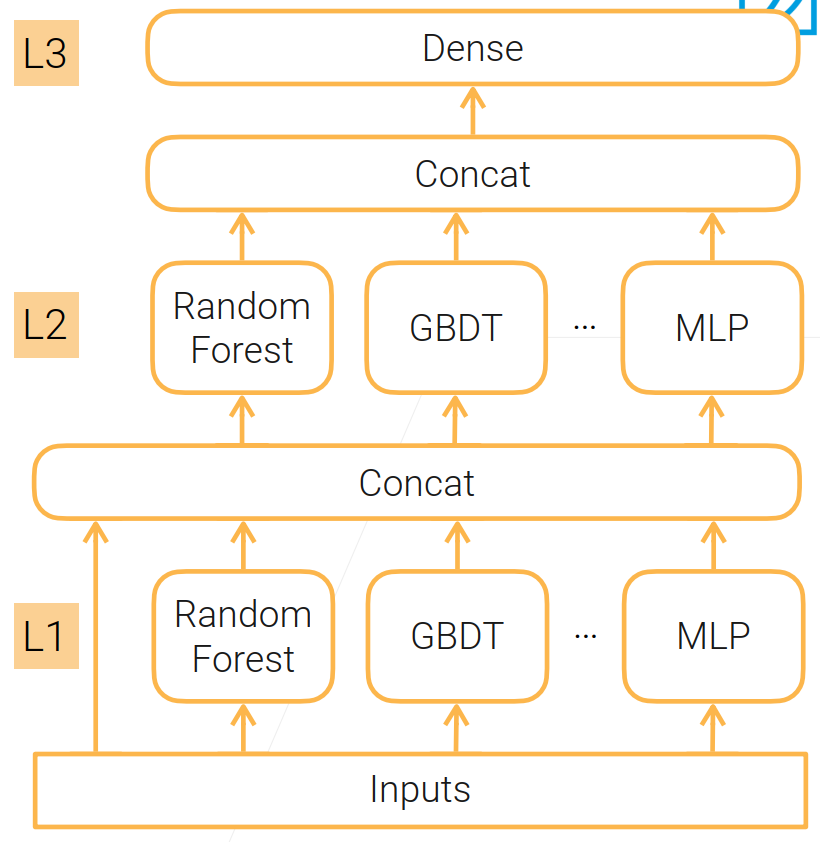
减轻多层stacking的过拟合
最简单的一种做法就是每一层的数据不是同一份数据(将数据集分成两块A、B(2层stacking),然后用A训练第一层模型L1,用L1对B进行预测,把预测的结果加上B本身训练第二层模型L2);
每一次只用了一半的数据比较亏,所以使用重复k折bagging的方法。
- 像k折交叉验证一样,将数据集分成k份,每一次在k-1份上训练,再用第k份做验证,这样可以训练k个模型
- 每个模型用这个方法训练了一次 所以每次训练了是k*n个小模型
- 更加昂贵的做法,对上述的做法重复做n次k折交叉验证,这样可以拿到n个预测值,再取平均放入下一层中。
使用多层stacking的效果
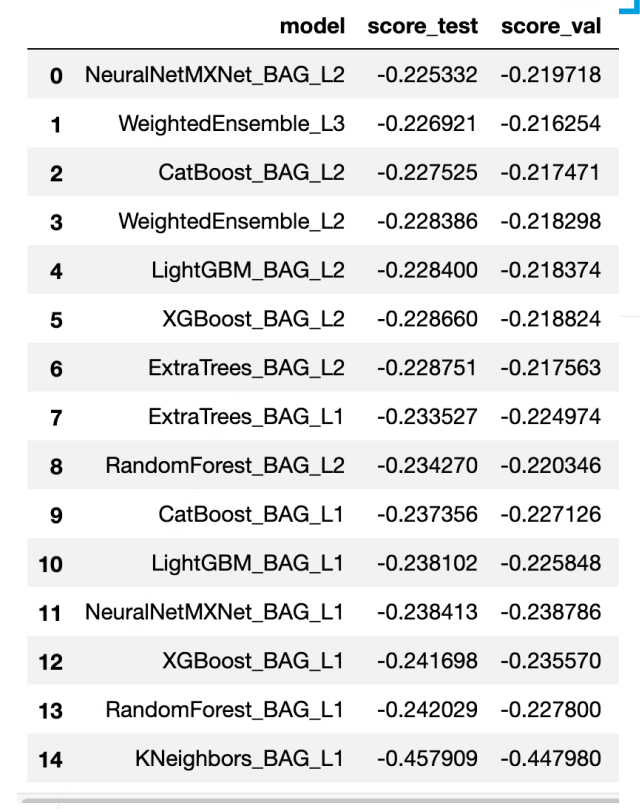
stacking的总结
- stacking就是把多个不同的模型合并起来,用来降低方差,获取多样性;
- 多层stacking能够把多层的模型合并起来,每一层在下一层的基础上,再更好的拟合数据,来降低偏差,但是这样的模型很容易过拟合,需要做大量的工作避免其过拟合(重复的k折bagging,每一层都能在完整的数据集上训练;重复与k折使得训练的数据都不会更上一层的数据混在一起)
- stacking经常在竞赛中被使用,但问题很明显,它需要把多个模型放在一起,相对来说比较贵;关注精度和结果的可以使用它;如果觉得模型太贵了,线上表现太差可以使用蒸馏(可以使得模型变小,但是也尽量保护住了精度)
总结
集成学习就是将多个模型组合起来来降低偏差和方差
- bagging是n个同样的模型做平均,主要目的是降低方差;
- boosting就是几个模型组合起来,主要是降低偏差
- stacking就是将多个不同的模型组合起来,降低方差
- 多层stacking,就是用来降低方差;
- 如果模型有n个的话,bagging,boosting,stacking的计算花销为之前的n倍;
- bagging与stacking的好处在于每个模型基本上可以独立参与训练,所以它们是可以做并行的;boosting是训练好一个模型后再训练一个模型
- 最后k折多层stacking基本上可以讲上面的好处都可以拿到,但是代价也非常明显,假设有 l层 n个模型 做 k折交叉验证 则计算花销是 n*l*k ,如果还要重复多次可以还要翻几倍
- 虽然k折多层staking每一层是顺序的关系,但是一层的里面是并行的。
参考:【斯坦福21秋季:实用机器学习中文版】

- 点赞
- 收藏
- 关注作者
评论(0)