机器学习--多层感知机、卷积神经网络、循环神经网络

目录
一、多层感知机
手工提取特征(用人的知识进行) --> 神经网络来提取特征。
神经网络(可能更懂机器学习)来提取 可能对后面的线性或softmax回归可能会更好一些。
用神经网络的好处在于 不用费心思去想 提取的数据特征是否会被模型喜欢,
但是计算量和数量都比手工提取的数量级要大很多。
可以使用不同神经网络的架构来更有效的提取特征。
- 多层感知机
- 卷积神经网络(CNN)
- 循环神经网络(RNN)
- Transformers【最近兴起的】
线性方法到多层感知机
稠密层(全连接层或线性层)有可学习的参数W,
b,计算 y=Wx+b
线性回归可以看成是,有1个输出的全连接层
softmax回归可以看成是,有m个输出加上softmax操作子
怎么变成一个多层感知机
想做到非线性的话,可以使用多个全连接层;但是简单的叠加在一起还是线性的,所以要加入非线性的东西在里面,也就是激活函数;
这里有些超参数:需要选用多少个隐藏层,隐藏层的输出大小;
简单的代码实现
使用自定义
(1)实现一个具有单隐藏层的多层感知机,它包含256个隐藏单元,
- 这里的输入、输出是数据决定的,256是调参自己决定的,取了一个在784和10之间的数。
- W初始了一个随机的,它的行数是输入的个数784,列数是256,偏差是0;
(2)实现ReLu 激活函数,求最大值,
# 实现 ReLu 激活函数
def relu(X):
a = torch.zeros_like(X) # 数据类型、形状都一样,但是值全为 0
return torch.max(X,a)(3)实现模型
# 实现模型
def net(X):
#print("X.shape:",X.shape)
X = X.reshape((-1, num_inputs)) # 拉成二维矩阵,-1为自适应的批量大小,num_inputs=784
#print("X.shape:",X.shape)
H = relu(X @ W1 + b1) # 矩阵乘法:x为784,w为784x256,b1为256长的向量
#print("H.shape:",H.shape)
#print("W2.shape:",W2.shape)
return (H @ W2 + b2)(4)训练模型,多层感知机的训练过程与softmax回归的训练过程完全一样
# 损失
loss = nn.CrossEntropyLoss() # 交叉熵损失
# 多层感知机的训练过程与softmax回归的训练过程完全一样
num_epochs ,lr = 30, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)在没有隐藏层之前,我们的损失大概是0.4,精度大概是0.8,有了隐藏层之后,我们这里图上的损失是比0.4低一些的,精度没有发生太多变化。
可以看到这个现象,多层感知机使得损失确实往下降了,因为我的模型更大了,所以拟合的更好了,所以损失在下降。但是精度没有发生太多变化,之后再来探讨这个问题。
二、卷积神经网络
全连接层 过渡到 卷积层:
用MLP训练ImageNet(300*300的图片有1000个类),MLP有1个隐藏层,隐藏层的输出有1万(输入大概为9万输出是一千,随机取了个中间值1万),这样的话模型就有10亿个参数可供学习。
这是因为全连接层的输出对所有的输入做加权和,而且每个输出的权重是不一样的,即导致学习的参数特别多。
解决方案:看看做图片分类的时候,有什么先验信息可以使用,使得我们设计神经网络的时候,可以将这个先验知识放进去。
在图片中识别一个物体,有两个原则可以使用
- Translation invariance(做变换时它不会变):需要识别的目标在一幅图的一个地方换到另一个地方,不会发生太多的变化
- Locality(本地性):识别一个物体不需要看比较远的像素(像素以及其周围的像素相关性比较高)
卷积神经网络:
- Locality(本地性):在卷积层中,一个输出只使用一个k*k输入的一个窗口 的图片【全连接层是整张图每个像素进行学习;而卷积层是一个在k*k窗口内对图片进行学习】
- Translation invariance(平移不变性):如果在一个地方有已经学习好的权重,将它移到另一个地方依然能够识别
- 卷积层可学习参数的个数不再与输出和输入的大小相关,只跟窗口大小k相关【只用在k*k的窗口内做加权和,且每个输出都重用这个窗口】
- 这个k*k的窗口叫做 卷积核(kernel或kernel weight),通常被训练用于识别图片的一个模式(可以说是图片中的某些特征)【根据数据模型会选取不一样的模式出来】【通常会使用不同的通道(选很多组的数据得到一个多通道的输出),这样可以学习不同类型的模式】
代码实现
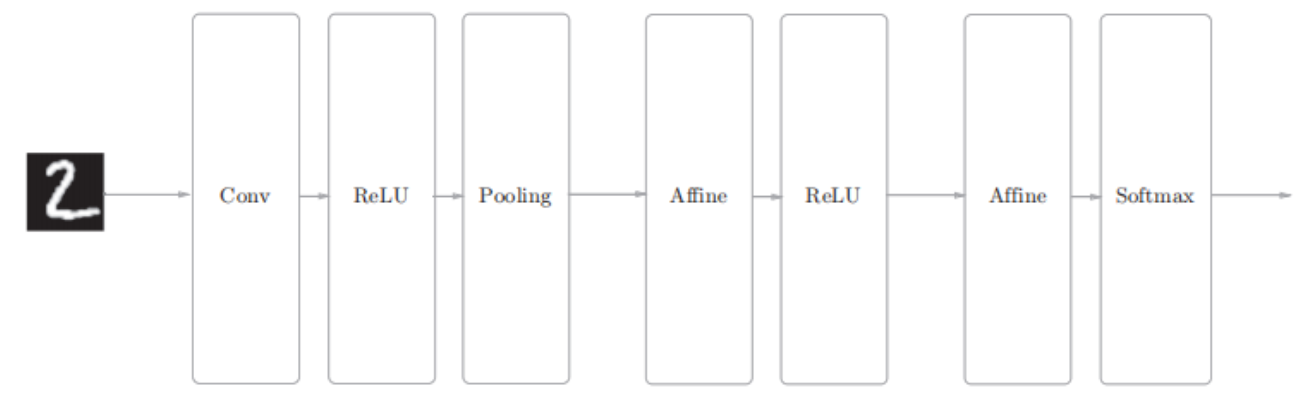
网络的构成是“Convolution - ReLU - Pooling -Affine - ReLU - Affine - Softmax”,我们将它实现为名为SimpleConvNet的类。
该网络的参数
• input_dim―输入数据的维度:(通道,高,长)
• conv_param―卷积层的超参数(字典)。
字典的关键字如下:
filter_num―滤波器的数量
filter_size―滤波器的大小
stride―步幅
pad―填充
• hidden_size―隐藏层(全连接)的神经元数量
• output_size―输出层(全连接)的神经元数量
• weitght_int_std―初始化时权重的标准差
卷积层的超参数通过名为conv_param的字典传入。我们设想它会
像{‘filter_num’:30,‘filter_size’:5, ‘pad’:0, ‘stride’:1}。
这个CNN网络的初始化分为三个部分。
第一部分:取出初始化传入卷积层的超参数,并计算卷积层的输出大小
class SimpleConvNet:
def __init__(self, input_dim=(1, 28, 28),
conv_param={'filter_num':30, 'filter_size':5,'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2) *(conv_output_size/2))
第二部分:权重参数的初始化,包括第一层卷积层和两个全连接层的权重和偏置。分别为W1、b1、w2、b2、w3、b3
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
第三步:生成对应的层,向有序字典(OrderedDict)的layers中添加层。只有最后的SoftmaxWithLoss层被添加到别的变量lastLayer
# 生成层
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxWithLoss()
以上就是SimpleConvNet的初始化中进行的处理。每一层的单独的具体实现已经在前面文中提到,为构建一个简单的CNN网络,每一层各司其职。
像这样进行初始化后,进行推理的predict方法和求损失函数的loss方法调用如下。
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
"""求损失函数
参数x是输入数据、t是教师标签
"""
y = self.predict(x)
return self.last_layer.forward(y, t)
predict方法从头开始依次调用已添加的层,并将结果传递给下一层。
def gradient(self, x, t):
"""求梯度(误差反向传播法)
Parameters
----------
x : 输入数据
t : 教师标签
Returns
-------
具有各层的梯度的字典变量
grads['W1']、grads['W2']、...是各层的权重
grads['b1']、grads['b2']、...是各层的偏置
"""
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 设定
grads = {}
grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db
grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
因为每一层的误差正向传播和反向传播已经在各层实现,也就是forward()和backward()方法,只需要依次调用每一层的方法即可,最后将每一层中各个权重参数的梯度保存到grads字典中。
simple_convnet类如下
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import pickle
import numpy as np
from collections import OrderedDict
from common.layers import *
from common.gradient import numerical_gradient
class SimpleConvNet:
"""简单的ConvNet
conv - relu - pool - affine - relu - affine - softmax
Parameters
----------
input_size : 输入大小(MNIST的情况下为784)
hidden_size_list : 隐藏层的神经元数量的列表(e.g. [100, 100, 100])
output_size : 输出大小(MNIST的情况下为10)
activation : 'relu' or 'sigmoid'
weight_init_std : 指定权重的标准差(e.g. 0.01)
指定'relu'或'he'的情况下设定“He的初始值”
指定'sigmoid'或'xavier'的情况下设定“Xavier的初始值”
"""
def __init__(self, input_dim=(1, 28, 28),
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2))
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * \
np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * \
np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
# 生成层
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],
conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
"""求损失函数
参数x是输入数据、t是教师标签
"""
y = self.predict(x)
return self.last_layer.forward(y, t)
def accuracy(self, x, t, batch_size=100):
if t.ndim != 1 : t = np.argmax(t, axis=1)
acc = 0.0
for i in range(int(x.shape[0] / batch_size)):
tx = x[i*batch_size:(i+1)*batch_size]
tt = t[i*batch_size:(i+1)*batch_size]
y = self.predict(tx)
y = np.argmax(y, axis=1)
acc += np.sum(y == tt)
return acc / x.shape[0]
def numerical_gradient(self, x, t):
"""求梯度(数值微分)
Parameters
----------
x : 输入数据
t : 教师标签
Returns
-------
具有各层的梯度的字典变量
grads['W1']、grads['W2']、...是各层的权重
grads['b1']、grads['b2']、...是各层的偏置
"""
loss_w = lambda w: self.loss(x, t)
grads = {}
for idx in (1, 2, 3):
grads['W' + str(idx)] = numerical_gradient(loss_w, self.params['W' + str(idx)])
grads['b' + str(idx)] = numerical_gradient(loss_w, self.params['b' + str(idx)])
return grads
def gradient(self, x, t):
"""求梯度(误差反向传播法)
Parameters
----------
x : 输入数据
t : 教师标签
Returns
-------
具有各层的梯度的字典变量
grads['W1']、grads['W2']、...是各层的权重
grads['b1']、grads['b2']、...是各层的偏置
"""
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 设定
grads = {}
grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db
grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
def save_params(self, file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name="params.pkl"):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
for i, key in enumerate(['Conv1', 'Affine1', 'Affine2']):
self.layers[key].W = self.params['W' + str(i+1)]
self.layers[key].b = self.params['b' + str(i+1)]
参考:《深度学习入门:基于Python的理论与实现 》斋藤康毅
池化层
卷积层对输入的位置是比较敏感的,任何一个物体在输入中移动时,会导致它对应的输出也会移动。
对位置移动的鲁棒性,提出了pooling layer(池化层或汇聚层)【就是每一次去计算k*k窗口的元素的均值(平均汇聚)或最大值(最大汇聚)】
卷积神经网络
- 卷积神经网络就是一个神经网络,将卷积层堆起来,用卷积来抽取图片中的空间信息【不一定要做图片,可以做跟空间信息有关的东西,只要满足本地性和平移不变性】
- 激活层用于每一个卷积层之后,卷积层可以看作是特殊的全连接层,所以卷积层也是线性的,需要激活层
- 卷积层对位置比较敏感,可以用池化层来得到对于位置不是很敏感的输出
- 现代化的CNN有更多的结构化信息【核有多大,通道数有多少,层与层之间是怎么连起来的】在里面,AlexNet, VGG, Inceptions, ResNet, MobileNet,这些模型都会考虑一些设计模式在里面。
三、循环神经网络
从多层感知机过渡到循环神经网络
NLP(自然语言处理)中的经典应用:语言模型(每次给一些词或者是句子里前面那些字然后去预测下一个字是什么);
当然可以用MLP来做:
- 每一次就使用一个最简单的全连接层做一个softmax回归,然后做分类(有多少个词做多少个分类);
- 做第一个(例子里的hello预测world)预测还好,但是在下一个词是只看到了上一个时刻的词没有看到之前时刻的词(world这个词没有看到hello)
- 如果我们在world之前可以加上hello这个词,但是长度会发生变化(全连接的输入项是不能发生变化的,如果是在one-hot里加上去的话,则表现不出时序性)
用RNN来做:
前部分是跟之前的是一样的,但要怎么把上一个时刻的信息弄出来呢?上一个全连接层的输出还没有进入softmax,这里面可能包含了hello的信息,将这个值复制一遍,让它跟world这个词的向量表示放在一起(concat),进而可以预测出!;
上面包含hello的信息的值H叫隐藏状态(Hidden status),之所以叫这个名字,是因为它的信息可以往后走,不管它走多少步H的大小是不发生变换的(取决于上一个全连接层输出的个数);
如果H一直这样走下去的话,它就包含这以前所有它看过的信息。
RNN具体是怎么做的
上图的yt与ht本质上一个东西(在简单的RNN模型里面是这样的,在复杂的版本就可能不是了);
与MLP不同的地方在于加多了一项,这一项为上一个时刻的输出作为这一个时刻的输入再乘上个可学习参数Whh;
现在常用的RNN层:
- 相对来说复杂一点,带有门的RNN如LSTM和GRU,它们会在里面会做一些很细微的控制(信息流是怎么流的)。
- 忘掉输入:在算 yt 的时候,想要抑制掉 xt(可能xt对 结果的表示 没有那么重要 介词、符号之类的);用 可以学习权重权重 来控制这个输入是否需要抑制
- 忘掉过去关注现在:新的句子(段落)开始、过去的信息很久很.久的信息跟现在没有太大的关系了,也用 可以学习权重 来控制这个输入是否需要抑制。
代码实现
1、PyTorch API实现
1)实现单向、单层RNN
首先实例化对象single_rnn,然后调用随机函数torch.randn生成输入,最后将生成的输入作为single_rnn的输入,并且得到输出和最后时刻状态。
single_rnn = nn.RNN(4, 3, 1, batch_first=True)
input = torch.randn(1, 2, 4) # bs * sl * fs
output, h_n = single_rnn(input)
print(output)
print(h_n)
2)实现双向、单层RNN
首先实例化对象bidirectional_rnn,在这里需要加上bidirectional=True即可实现双向RNN,然后给bidirectional_rnn输入,得到输出和最后时刻状态。
bidirectional_rnn = nn.RNN(4, 3, 1, batch_first=True, bidirectional=True)
bi_output, bi_h_n = bidirectional_rnn(input)
print(bi_output)
print(bi_h_n)
3)比较单向、单层RNN和双向、单层RNN
print(output.shape)
print(bi_output.shape)
print(h_n.shape)
print(bi_h_n.shape)
从输出上来看,单向的RNN维度是1 * 2 * 3,而双向的RNN维度是1 * 2 * 6,原因是双向RNN把forward和backward的结果拼在一起;从最后时刻状态来看,单向的RNN维度是1 * 1 * 3,而双向的RNN维度是2 * 1 * 3,原因是双向RNN在最后时刻有两个层,而单向RNN在最后时刻有一个层。
2、代码逐行实现RNN
1)首先初始一些张量,然后调用正态分布随机初始化一个输入特征序列,以及初始隐含状态(设为0)。
import torch
import torch.nn as nn
bs, T = 2, 3 # 批大小,输入序列长度
input_size, hidden_size = 2, 3 # 输入特征大小,隐含层特征大小
input = torch.randn(bs, T, input_size) # 随机初始化一个输入特征序列
h_prev = torch.zeros(bs, hidden_size) # 初始隐含状态
2)手写一个rnn_forward函数,手动地模拟单向RNN的运算过程,并且与PyTorch RNN API进行比较,验证输出结果。
# step1 调用PyTorch RNN API
rnn = nn.RNN(input_size, hidden_size, batch_first=True)
rnn_output, state_final = rnn(input, h_prev.unsqueeze(0))
print("PyTorch API output:")
print(rnn_output)
print(state_final)
# step2 手写一个rnn_forward函数,实现单向RNN的计算原理
def rnn_forward(input, weight_ih, weight_hh, bias_ih, bias_hh, h_prev):
bs, T, input_size = input.shape
h_dim = weight_ih.shape[0]
h_out = torch.zeros(bs, T, h_dim) # 初始化一个输出(状态)矩阵
for t in range(T):
x = input[:, t, :].unsqueeze(2) # 获取当前时刻输入特征,bs * input_size
w_ih_batch = weight_ih.unsqueeze(0).tile(bs, 1, 1) # bs * h_dim * input_size
w_hh_batch = weight_hh.unsqueeze(0).tile(bs, 1, 1) # bs * h_dim * h_dim
w_times_x = torch.bmm(w_ih_batch, x).squeeze(-1) # bs * h_dim
w_times_h = torch.bmm(w_hh_batch, h_prev.unsqueeze(2)).squeeze(-1) # bs * h_dim
h_prev = torch.tanh(w_times_x + bias_ih + w_times_h + bias_hh)
h_out[:, t, :] = h_prev
return h_out, h_prev.unsqueeze(0)
# 验证rnn_forward的正确性
# for k, v in rnn.named_parameters():
# print(k, v)
custom_rnn_output, custom_state_final = rnn_forward(input, rnn.weight_ih_l0, rnn.weight_hh_l0,
rnn.bias_ih_l0, rnn.bias_hh_l0, h_prev)
print("rnn_forward function output:")
print(custom_rnn_output)
print(custom_state_final)
查看输出结果以及并用torch.allclose验证最后时刻的结果
3)手写一个bidirectional_rnn_forward函数,手动地模拟双向RNN的运算过程,并且与PyTorch RNN API进行比较,验证输出结果。
# step3 手写一个bidirectional_rnn_forward函数,实现双向RNN的计算原理
def bidirectional_rnn_forward(input, weight_ih, weight_hh, bias_ih, bias_hh, h_prev,
weight_ih_reverse, weight_hh_reverse, bias_ih_reverse, bias_hh_reverse, h_prev_reverse):
bs, T, input_size = input.shape
h_dim = weight_ih.shape[0]
h_out = torch.zeros(bs, T, h_dim * 2) # 初始化一个输出(状态)矩阵,注意双向是两倍的特征大小
forward_output = rnn_forward(input, weight_ih, weight_hh, bias_ih, bias_hh, h_prev)[0] # forward layer
backward_output = rnn_forward(torch.flip(input, [1]), weight_ih_reverse, weight_hh_reverse, bias_ih_reverse,
bias_hh_reverse, h_prev_reverse)[0] # backward layer
h_out[:, :, :h_dim] = forward_output
h_out[:, :, h_dim:] = backward_output
return h_out, h_out[:, -1, :].reshape((bs, 2, h_dim)).transpose(0, 1)
# 验证bidirectional_rnn_forward的正确性
bi_rnn = nn.RNN(input_size, hidden_size, batch_first=True, bidirectional=True)
h_prev = torch.zeros(2, bs, hidden_size)
bi_rnn_output, bi_state_final = bi_rnn(input, h_prev)
# for k, v in bi_rnn.named_parameters():
# print(k, v)
custom_bi_rnn_output, custom_bi_state_final = bidirectional_rnn_forward(input, bi_rnn.weight_ih_l0, bi_rnn.weight_hh_l0,
bi_rnn.bias_ih_l0, bi_rnn.bias_hh_l0,
h_prev[0], bi_rnn.weight_ih_l0_reverse,
bi_rnn.weight_hh_l0_reverse,
bi_rnn.bias_ih_l0_reverse,
bi_rnn.bias_hh_l0_reverse, h_prev[1])
print("PyTorch API output:")
print(bi_rnn_output)
print(bi_state_final)
print("bidirectional_rnn_forward function output:")
print(custom_bi_rnn_output)
print(custom_bi_state_final)
查看输出结果以及并用torch.allclose验证最后时刻的结果
print(torch.allclose(bi_state_final, custom_bi_state_final))
拓展一下RNN:
- 一个方向-->两个方向:正向层:将过去时刻的信息放入当前时刻,然后 反向层:时刻t+1的信息往时刻t的方向走【P.S.这里的时刻我觉得不是时间的概念要看成是文本中的词序可能会好理解一点】,最后结合正向层和反向层的信息相结合作为yt
- 把不同的层跟MLP一样累加起来,做成多层RNN
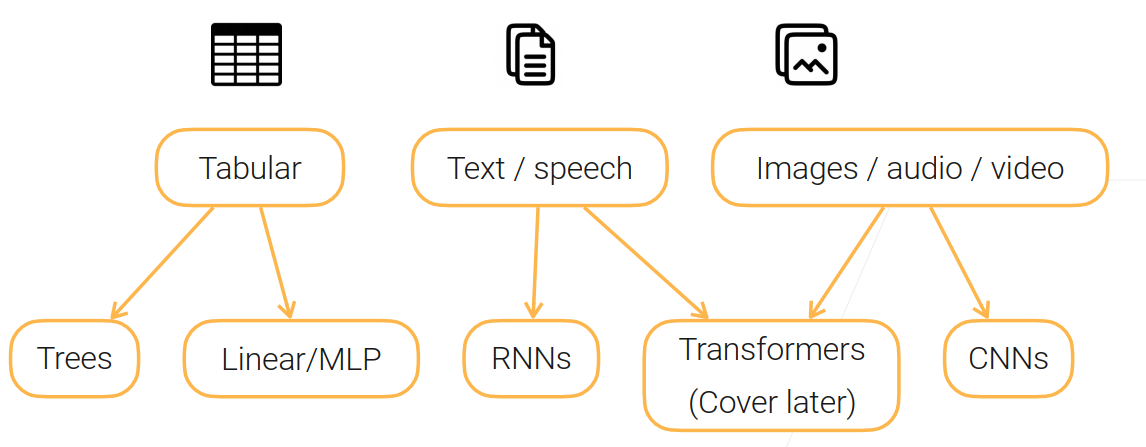
对模型的选择:
- 对表格数据:可以使用树模型、线性模型或者是MLP
- 对于文本(有时序信息):可以使用RNN
- 对于图片、音频、视频(有相似的空间信息):可以用CNN
最近兴起的用 自注意力 做的变形金刚(Transformers)这个模型又能处理有时序信息的东西,又能处理有空间信息的东西 。
![]() 总结
总结
- MLP(多层感知机):就是将多个全连接层堆起来,然后通过激活层来得到非线性的模型
- CNN(卷积神经网络):可以看作是比较特殊的全连接层,其中的卷积层使用了空间上的本地性和平移不变性然后做了一个简化版的全连接层,参数少,更适合处理图片信息;将卷积层和汇聚层(池化层)堆叠起来可以得到一种高效抓取空间信息的模型
- RNN(循环神经网络):可以看作是全连接层在时序上用了过去的信息,放在了现在,在全连接层加了一条额外的边,得到一个循环神经网络,能够作用于有时序信息的数据。

- 点赞
- 收藏
- 关注作者
评论(0)