机器学习:正则化

目录
当将我们的算法应用到某些特定的机器学习应用时,会遇到过拟合(over-fitting)的问题,可能会导致它们效果很差。这样就可以正则化的知识来解答,正则化就是改善或者减少过度拟合问题的方法。

几乎拟合每个训练样本,在训练样本中虽然准确率很高,但模型泛化能力差,往往在测试集上预测准确率较低。那么怎么解决这种问题?通过正则化(regularization)提高模型的泛化能力,减少过拟合现象。
总结

定义:能够提高模型在test上的准确率,能够提高模型的泛化能力所做的任何改动,我们都可以称之为正则化。
基于数据的正则化方法
- 深度模型的表现很大程度上依赖于训练数据,我们可以对训练数据D进行一些转换处理得到一个有助于提高模型泛化能力的新的数据集DR。其中转换操作一方面可以通过改变更有利于模型学习的数据的分布;另一方面通过生成更大的训练样本集,加强模型的泛化能力。这两种处理方法都是独立的,也可以两者都结合。总体来说,这两种方式都是通过对输入进行一个变量转换得到,这种转换,我们定义如下:

- 通过转换参数变量θ来产生新的数据,例如常见的data augmentation,对输入或者隐层特征进行变化。若参数变量θ是确定的,则经过转换后的数据保持不变,若是一个随机的参数,则可以产生一个更大的数据集。而常见的对数据进行转换的方法如下:
- data augmentation通过对输入或者隐层特征进行转换,从而获得一个更大的数据集,提高模型在训练样本较少情况下的效果。对原始数据集中(xi,ti)∈D每个样本,通过转换函数,进行样本扩增操作 (Tθ(xi),ti)∼Q,可以获得一个更大的新的数据集Q来模型训练。
- dropout目的是防止模型过拟合,若模型复杂,在训练数据不足的情况下,模型会过拟合训练样本,泛化能力差。dropout通过随机丢弃一部分神经元节点(特征检测器),让模型变简单,防止模型过拟合。
基于optimization进行正则化
- 通过对模型参数的初始化,让模型一开始有个好的状态。目前最常见的对参数的初始化方法是从一个已知的数据分布中采样(例如正态分布等)初始化模型参数,有利于减缓深层网络导致的梯度消失或者梯度爆炸问题。另外一种方法是通过在相同领域上的数据集做=pre-training得到的模型参数初始化fine-tuning中的模型。用pre-training的模型参数初始化模型,通常可以加快模型收敛,而且可以学习到一些基础特征。另外一种方法课程学习 (curriculum learning)也称作warm-start methods,核心思想是模仿人类学习的特点,先学简单,再学较难的,会更有利于学习。所以在机器学习中,先学习简单的样本,再学习较困难的样本,能够提高模型的表现。比如在神经网络中的warmup策略,在最开始的steps中,先以小的学习率学习,再逐渐上升,如下表示:
- 其中i 是当前的step,n 代表warmup阶段的所有steps,比如在bert中设置为占整个训练steps的10分之一。在warmup阶段,学习率是慢慢上升的,但还是比我们的初始化学习率低。避免模型在一开始由于学习率过大,模型对mini-batch过拟合,导致后期很难再纠正过来,等稍微平稳了,就可以用大的学习率进行加快学习,这样能够保持深层模型学习的稳定性。
基于正则化项
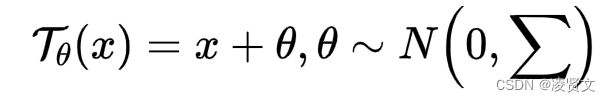
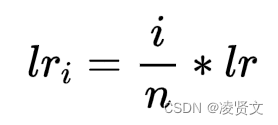
通过在损失函数中增加正则化项,实现正则化目的。损失函数主要是保证模型的输出和目标label一致性,而加入的正则化项是独立于label标签,可以对数据的先验知识进行建模,如果数据是稀疏的或者服从某种分布,我们可以在损失函数中加入这种先验知识限制,提高模型的效果。
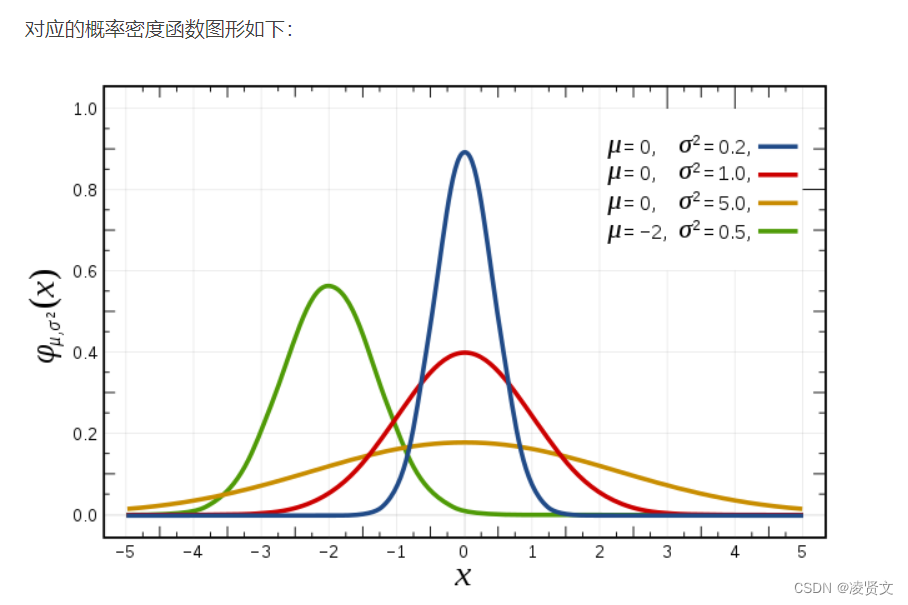
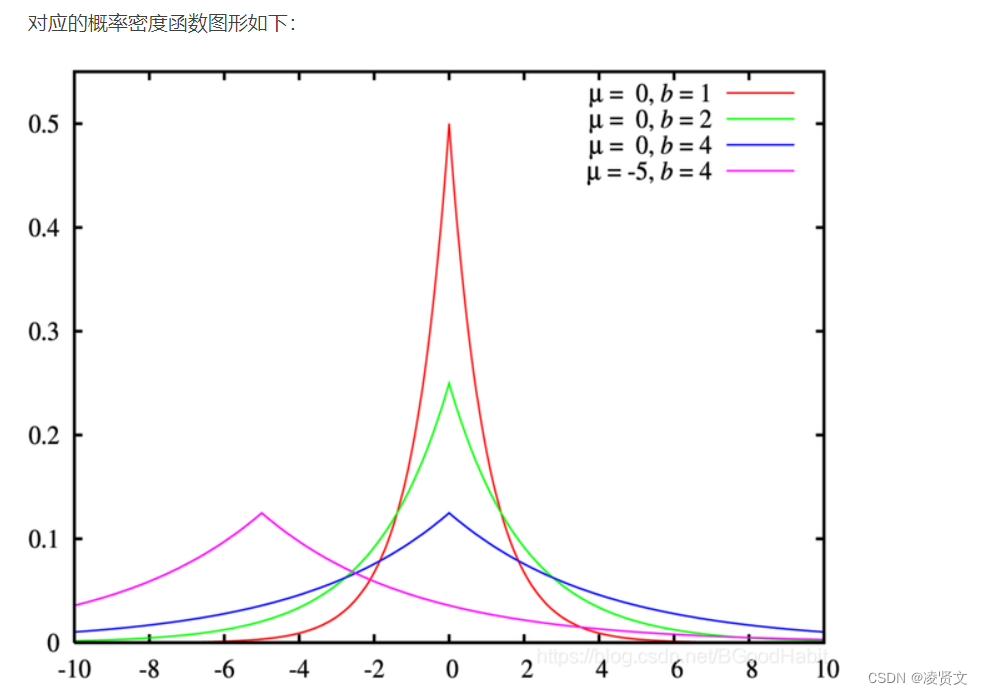
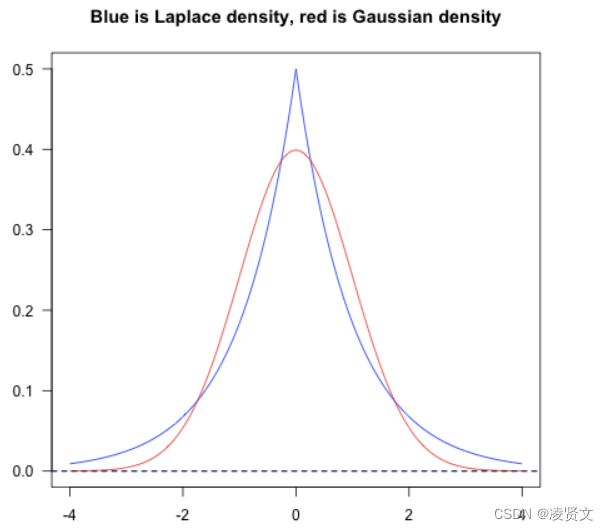
从贝叶斯角度理解,L2正则化其实是加入了数据的先验知识,认为权重参数服从高斯先验分布,所以在损失函数中加入这样的先验知识,让模型表现更好。在损失函数中加入这样一个惩罚项,让模型的权重参数服从拉普拉斯分布,若权重参数离分布的中心值较远,则对应的概率越小,产生的损失loss就会大,起到惩罚的作用。L1正则化可以让模型更加稀疏,简化模型的效果,进而防止模型过拟合。



![]()

L1和L2的异同


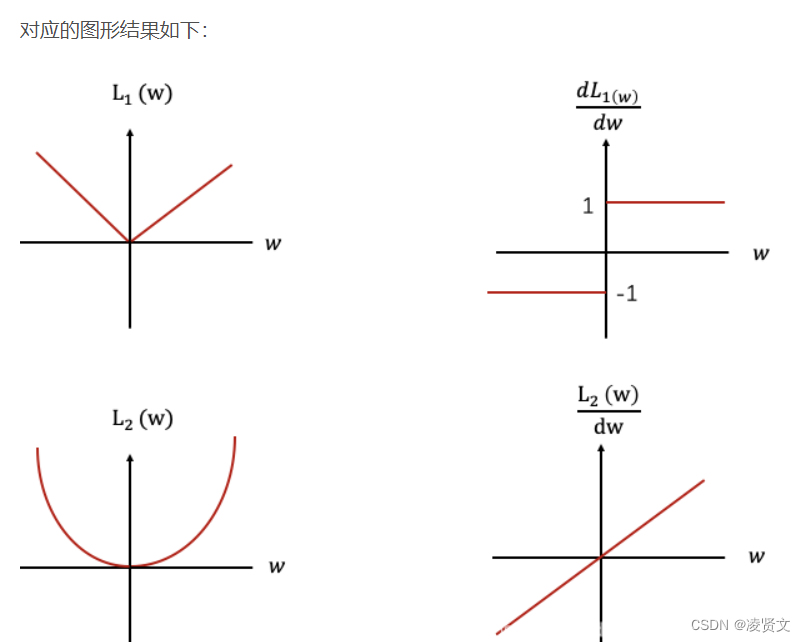
从上面可以看出L1正则化的函数图为左上图,对应的导数图为右上图,可以看出不管L1的大小是多少(只要不为0),梯度都是1或者-1,所以每次更新梯度的时候,参数w会稳步向0前进。而L2函数的导数图如右下图,w越靠近0的时候,梯度也越来越小,所以优化一定步骤后只能让w接近0,很难等于0,但是L1有稳定的梯度,经过一定的迭代步数后很可能变为0,这就是为什么L1正则化比L2正则化可以得到更稀疏的解。
[1] Kukačka J, Golkov V, Cremers D. Regularization for deep learning: A taxonomy[J]. arXiv preprint arXiv:1710.10686, 2017.

- 点赞
- 收藏
- 关注作者
评论(0)