Base64编码与Python解码

base64是网络上最常见的用于传输8Bit字节码的编码方式之一,是从二进制到字符的过程,可用于在HTTP环境下传递较长的标识信息。
采用Base64编码具有不可读性,需要解码后才能阅读。
本文是关于base64的加密原理还有如何编写Python脚本进行解密的文章。

Base64编码规则
将原来数据的二进制形式按每六个比特分开,不够6的位,补0
6位比特能表示64个字符
对照base64编码表
将每个六位比特按照base64编码表来表示
网络上通用的base64编码表为
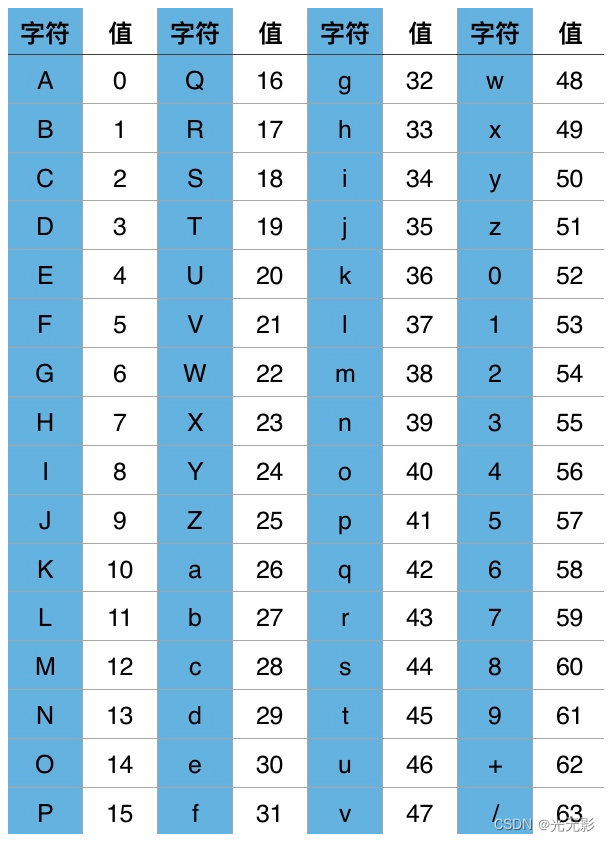
![]()
也可能有自定义的编码表
e.g
MZ1
01001101 01111010 00110001
010011 010111 101000 110001
19 23 40 49
TXox
不整齐补0
我们可以看到家编码表中没有“=”,但是Base64编码经常以“=”结尾,这是为什么呢?
base64编码形成的字符串的字符数必须是4的整数倍,不够的话会用“=”补齐。
python解码base64
import base64
a="6Im+5Lym5Zu+54G1"
print(a.encode())
b=base64.b64decode(a.encode());
print(b.decode())解密结果:
艾伦图灵
有些不能按base64解码:
Invalid base64-encoded string: number of data characters (5) cannot be 1 more than a multiple of 4
decode的作用是将其他编码的字符串转换成unicode编码
encode的作用是将unicode编码转换成其他编码的字符串
Python解码自定义编码表的base64
import base64
str_1 = "ZmxhZ3tiGNXlXjHfaDTzN2FfK3LycRTpc2L9"
str_base = "ABCDEFQRSTUVWXYPGHIJKLMNOZabcdefghijklmnopqrstuvwxyz0123456789+/"
#自定义的编码表
str_zh_base = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
#通用编码表
flag = base64.b64decode(str_1.translate(str.maketrans(str_base,str_zh_base)))
print(flag)
Python字符串前加b_python 字符串前加u r b的意义
1、前加 u
例:u"我是含有中文字符组成的字符串。"
作用:
后面字符串以 格式 进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时出现乱码。
2、字符串前加 r
例:r"\n\n\n\n” # 表示一个普通生字符串 \n\n\n\n,而不表示换行了。
作用:
去掉反斜杠的转移机制。
(特殊字符:即那些,反斜杠加上对应字母,表示对应的特殊含义的,比如最常见的”\n”表示换行,”\t”表示Tab等。 )
应用:
常用于正则表达式,对应着re模块。
3、字符串前加 b
例: response = b'
hello world
' # b' ' 表示这是一个 bytes 对象
作用:
b" "前缀表示:后面字符串是bytes 类型。
网络编程中,服务器和浏览器只认bytes 类型数据。
如:send 函数的参数和 recv 函数的返回值都是 bytes 类型
Unicode和UTF
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
函数
base64.``b64encode(s, altchars=None)对 bytes-like object s 进行 Base64 编码,并返回编码后的
bytes。可选项 altchars 必须是一个长 2 字节的 bytes-like object,它指定了用于替换+和/的字符。这允许应用程序生成 URL 或文件系统安全的 Base64 字符串。默认值是None,使用标准 Base64 字母表。
bytes-like object -- 字节类对象
支持 缓冲协议 并且能导出 C-contiguous 缓冲的对象。这包括所有 bytes、bytearray 和 array.array 对象
bytes.translate(table, /, delete=b'')
bytearray.translate(table, /, delete=b'')
返回原 bytes 或 bytearray 对象的副本,移除其中所有在可选参数 delete 中出现的 bytes,其余 bytes 将通过给定的转换表进行映射,该转换表必须是长度为 256 的 bytes 对象。
你可以使用 bytes.maketrans() 方法来创建转换表。
str.translate(table)
返回原字符串的副本,其中每个字符按给定的转换表进行映射。 转换表必须是一个使用 __getitem__() 来实现索引操作的对象,通常为 mapping 或 sequence。 当以 Unicode 码位序号(整数)为索引时,转换表对象可以做以下任何一种操作:返回 Unicode 序号或字符串,将字符映射为一个或多个字符;返回 None,将字符从结果字符串中删除;或引发 LookupError 异常,将字符映射为其自身。
你可以使用 str.maketrans() 基于不同格式的字符到字符映射来创建一个转换映射表。
另请参阅 codecs 模块以了解定制字符映射的更灵活方式。
static str.maketrans(x[, y[, z]])
此静态方法返回一个可供 str.translate() 使用的转换对照表。
如果只有一个参数,则它必须是一个将 Unicode 码位序号(整数)或字符(长度为 1 的字符串)映射到 Unicode 码位序号、(任意长度的)字符串或 None 的字典。 字符键将会被转换为码位序号。
如果有两个参数,则它们必须是两个长度相等的字符串,并且在结果字典中,x 中每个字符将被映射到 y 中相同位置的字符。 如果有第三个参数,它必须是一个字符串,其中的字符将在结果中被映射到 None。
Python3.10的官方文档
file:///C:/Users/DELL/Desktop/python-3.10.4-docs-html/search.html

- 点赞
- 收藏
- 关注作者
评论(0)