深度学习基础入门篇[六(1)]:模型调优:注意力机制[多头注意力、自注意力],正则化[L1、L2,Dropout]

深度学习基础入门篇[六(1)]:模型调优:注意力机制[多头注意力、自注意力],正则化【L1、L2,Dropout,Drop Connect】等
1.注意力机制
在深度学习领域,模型往往需要接收和处理大量的数据,然而在特定的某个时刻,往往只有少部分的某些数据是重要的,这种情况就非常适合Attention机制发光发热。
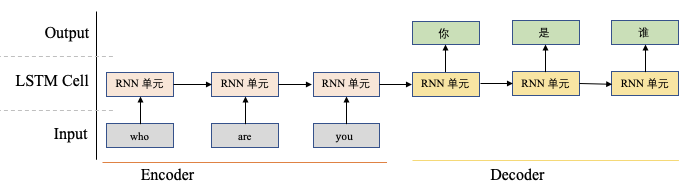
举个例子,图2展示了一个机器翻译的结果,在这个例子中,我们想将”who are you”翻译为”你是谁”,传统的模型处理方式是一个seq-to-seq的模型,其包含一个encoder端和一个decoder端,其中encoder端对”who are you”进行编码,然后将整句话的信息传递给decoder端,由decoder解码出”我是谁”。在这个过程中,decoder是逐字解码的,在每次解码的过程中,如果接收信息过多,可能会导致模型的内部混乱,从而导致错误结果的出现。我们可以使用Attention机制来解决这个问题,从图2可以看到,在生成”你”的时候和单词”you”关系比较大,和”who are”关系不大,所以我们更希望在这个过程中能够使用Attention机制,将更多注意力放到”you”上,而不要太多关注”who are”,从而提高整体模型的表现。
Attention机制自提出以来,出现了很多不同Attention应用方式,但大道是共同的,均是将模型的注意力聚焦在重要的事情上。本文后续将选择一些经典或常用的Attention机制展开讨论。
备注:在深度学习领域,无意识的显著性注意力更加常见。
1.1 用机器翻译任务带你看Attention机制的计算
单独地去讲Attention机制会有些抽象,也有些枯燥,所以我们不妨以机器翻译任务为例,通过讲解Attention机制在机器翻译任务中的应用方式,来了解Attention机制的使用。
什么是机器翻译任务?以中译英为例,机器翻译是将一串中文语句翻译为对应的英文语句,如图1所示。
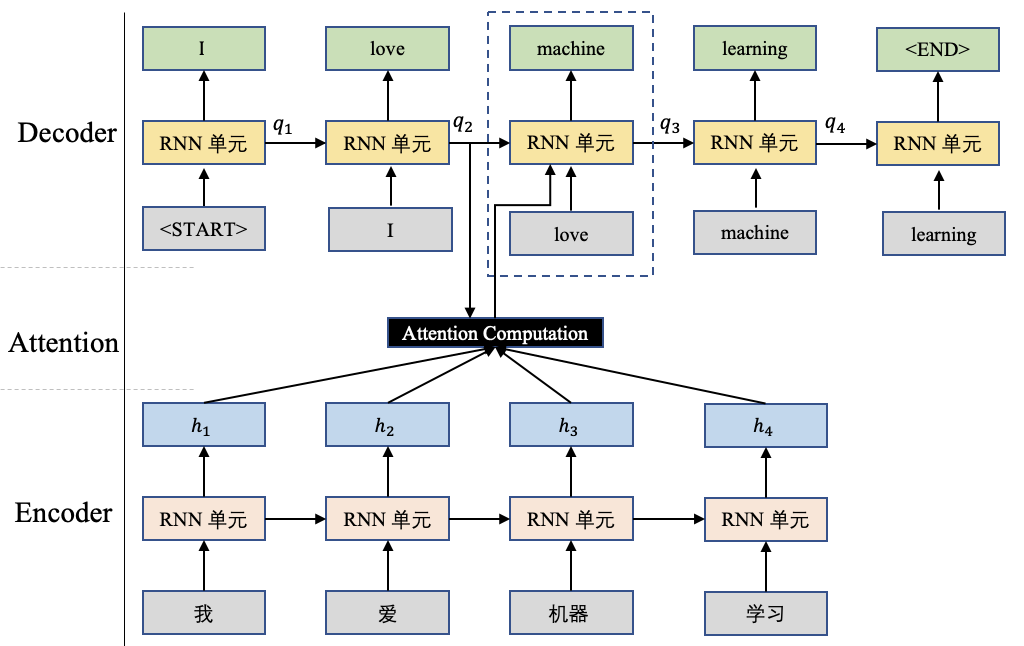
图1展示了一种经典的机器翻译结构Seq-to-Seq,并且向其中添加了Attention计算。Seq-to-Seq结构包含两个部分:Encoder和Decoder。其中Encoder用于将中文语句进行编码,这些编码后续将提供给Decoder进行使用;Decoder将根据Encoder的数据进行解码。我们还是以图1为例详细解释一下Decoder的解码过程。
更明确的讲,图1展示的是生成单词”machine”时的计算方式。首先将前一个时刻的输出状态 和Encoder的输出 进行Attention计算,得到一个当前时刻的 context,用公式可以这样组织:
我们来解释一下,这里的 表示注意力打分函数,它是个标量,其大小描述了当前时刻在这些Encoder的结果上的关注程度,这个函数在后边会展开讨论。然后用softmax对这个结果进行归一化,最后使用加权评价获得当前时刻的上下文向量 context。这个context可以解释为:截止到当前已经有了”I love”,在此基础上下一个时刻应该更加关注源中文语句的那些内容。这就是关于Attention机制的一个完整计算。
最后,将这个context和上个时刻的输出”love”进行融合作为当前时刻RNN单元的输入。
图1中采用了继续融合上一步的输出结果,例如上述描述中融合了”love”,在有些实现中,并没有融入这个上一步的输出,默认 中已经携带了”love”的信息,这也是合理的。
1.2 注意力机制的正式引入
前边我们通过机器翻译任务介绍了Attention机制的整体计算。但是还有点小尾巴没有展开,就是那个注意力打分函数的计算,现在我们将来讨论这个事情。但在讲这个函数之前,我们先来对上边的Attention机制的计算做个总结,图2详细地描述了Attention机制的计算原理。
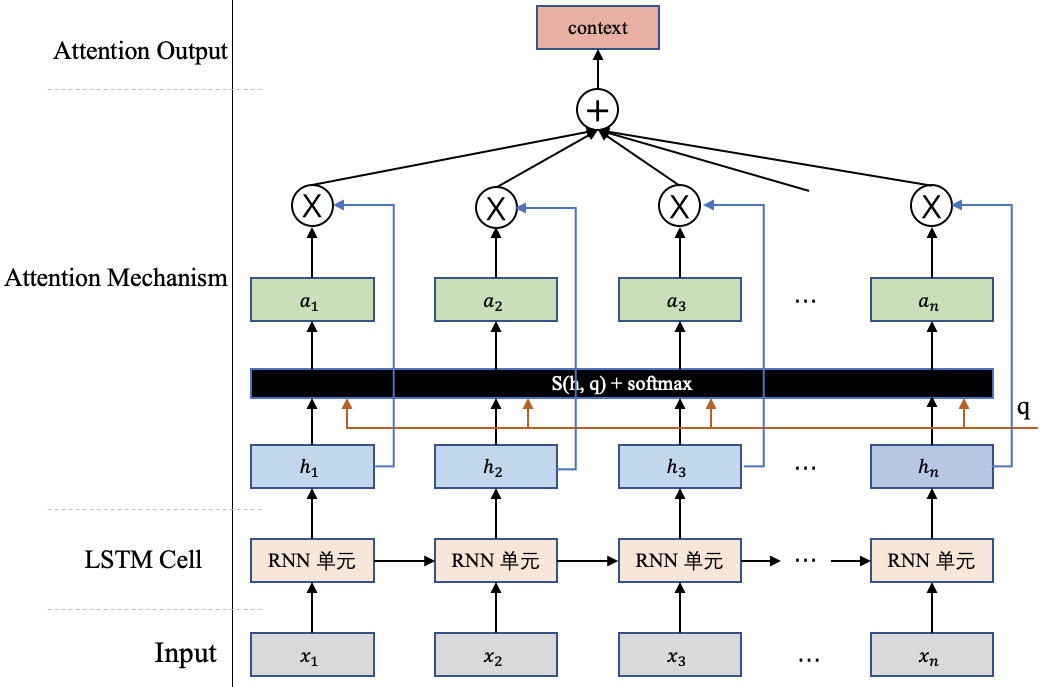
假设现在我们要对一组输入 使用Attention机制计算重要的内容,这里往往需要一个查询向量 q(这个向量往往和你做的任务有关,比如机器翻译中用到的那个 ) ,然后通过一个打分函数计算查询向量 q和每个输入 之间的相关性,得出一个分数。接下来使用softmax对这些分数进行归一化,归一化后的结果便是查询向量 q在各个输入 上的注意力分布 ,其中每一项数值和原始的输入 一一对应。以 为例,相关计算公式如下:
最后根据这些注意力分布可以去有选择性的从输入信息 H中提取信息,这里比较常用的信息提取方式,是一种”软性”的信息提取(图2展示的就是一种”软性”注意力),即根据注意力分布对输入信息进行加权求和,最终的这个结果 context体现了模型当前应该关注的内容:
现在我们来解决之前一直没有展开的小尾巴-打分函数,它可以使用以下几种方式来计算:
加性模型:
点积模型:
缩放点积模型:
双线性模型:
以上公式中的参数 W、U和v均是可学习的参数矩阵或向量,D为输入向量的维度。下边我们来分析一下这些分数计算方式的差别。
加性模型引入了可学习的参数,将查询向量 q和原始输入向量 h映射到不同的向量空间后进行计算打分,显然相较于加性模型,点积模型具有更好的计算效率。
另外,当输入向量的维度比较高的时候,点积模型通常有比较大的方差,从而导致Softmax函数的梯度会比较小。因此缩放点积模型通过除以一个平方根项来平滑分数数值,也相当于平滑最终的注意力分布,缓解这个问题。
最后,双线性模型可以重塑为 ,即分别对查询向量 q 和原始输入向量 h进行线性变换之后,再计算点积。相比点积模型,双线性模型在计算相似度时引入了非对称性。
1.3 注意力机制相关变体
1.3.1 硬性注意力机制
在经典注意力机制章节我们使用了一种软性注意力的方式进行Attention机制,它通过注意力分布来加权求和融合各个输入向量。而硬性注意力(Hard Attention)机制则不是采用这种方式,它是根据注意力分布选择输入向量中的一个作为输出。这里有两种选择方式:
选择注意力分布中,分数最大的那一项对应的输入向量作为Attention机制的输出。
根据注意力分布进行随机采样,采样结果作为Attention机制的输出。
硬性注意力通过以上两种方式选择Attention的输出,这会使得最终的损失函数与注意力分布之间的函数关系不可导,导致无法使用反向传播算法训练模型,硬性注意力通常需要使用强化学习来进行训练。因此,一般深度学习算法会使用软性注意力的方式进行计算,
1.3.2键值对注意力机制¶
假设我们的输入信息不再是前边所提到的 ,而是更为一般的键值对(key-value pair)形式 ,相关的查询向量仍然为 q。这种模式下,一般会使用查询向量 q和相应的键 进行计算注意力权值 。
当计算出在输入数据上的注意力分布之后,利用注意力分布和键值对中的对应值进行加权融合计算:
显然,当键值相同的情况下 ,键值对注意力就退化成了普通的经典注意力机制。
1.3.3. 多头注意力机制
多头注意力(Multi-Head Attention)是利用多个查询向量 ,并行地从输入信息 中选取多组信息。在查询过程中,每个查询向量 qi 将会关注输入信息的不同部分,即从不同的角度上去分析当前的输入信息。
假设 代表第 i 各查询向量 与第 j个输入信息 的注意力权重, contexti代表由查询向量 计算得出的Attention输出向量。其计算方式为:
最终将所有查询向量的结果进行拼接作为最终的结果:
公式里的 ⊕表示向量拼接操作。
1.4 自注意力机制
在前边所讲的内容中,我们会使用一个查询向量 q和对应的输入 进行attention计算,这里的查询向量q往往和任务相关,比如基于Seq-to-Seq的机器翻译任务中,这个查询向量q.可以是Decoder端前个时刻的输出状态向量,如图1所示。
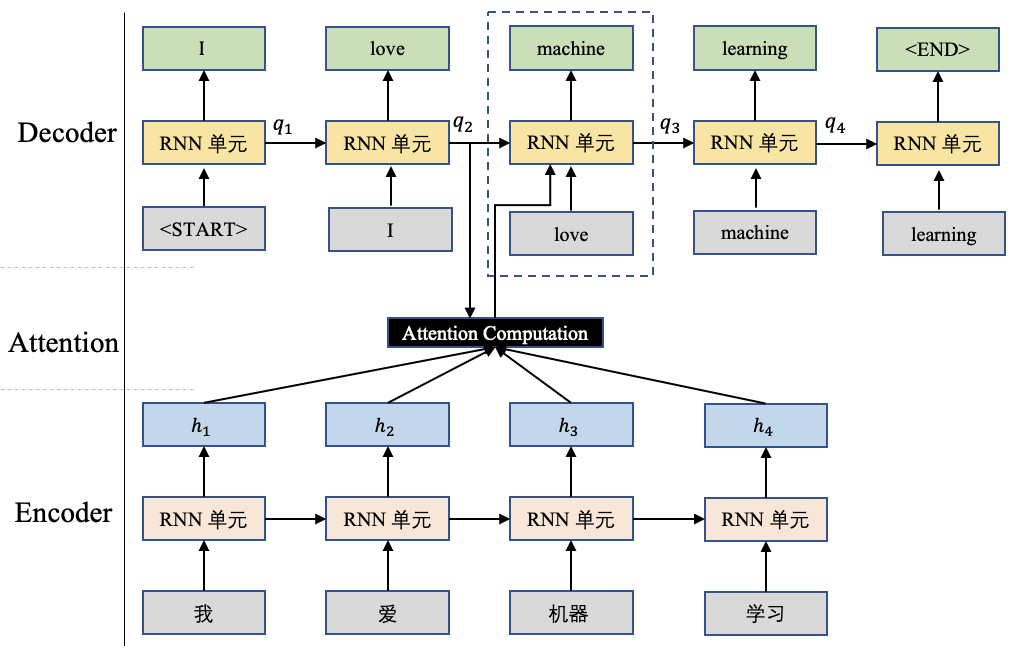
然而在自注意力机制(self-Attention)中,这里的查询向量也可以使用输入信息进行生成,而不是选择一个上述任务相关的查询向量。相当于模型读到输入信息后,根据输入信息本身决定当前最重要的信息。
自注意力机制往往采用查询-键-值(Query-Key-Value)的模式,不妨以BERT中的自注意力机制展开讨论,如图2所示。
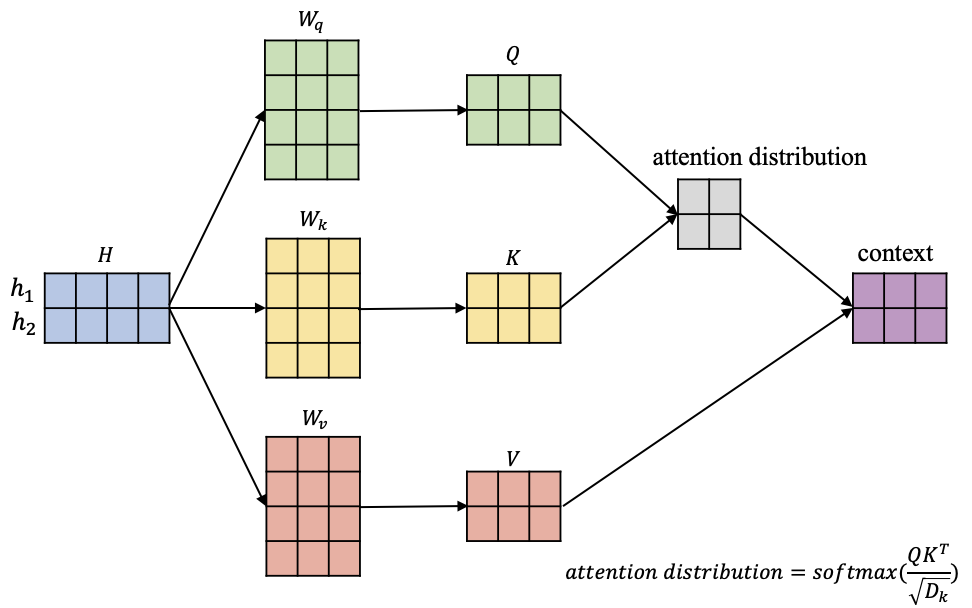
在图2中,输入信息 ,其中蓝色矩阵中每行代表对应一个输入向量,另外图2中有 $W_q,W_k,W_v$3个矩阵,它们负责将输入信息 H依次转换到对应的查询空间 ,键空间 :
获得输入信息在不同空间的表达 Q、 K和 V后,这里不妨以 这个为例,去计算这个位置的一个attention输出向量 ,它代表在这个位置模型应该重点关注的内容,如图3所示。
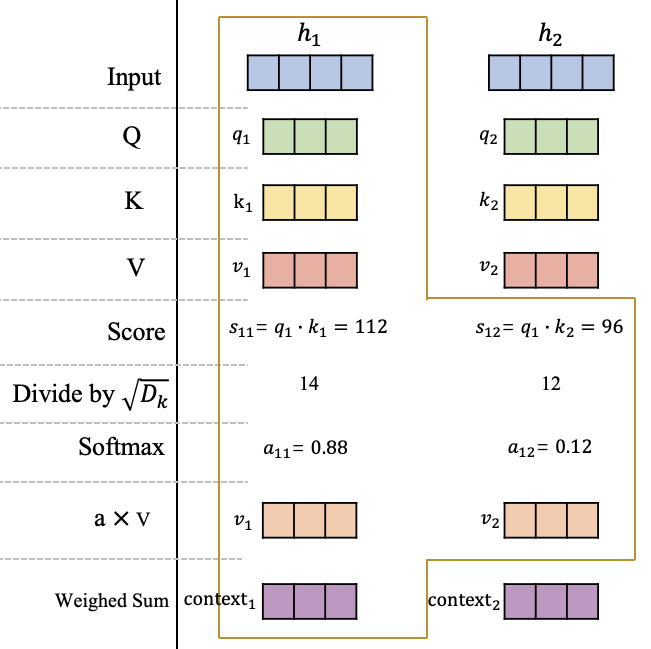
可以看到在获得原始输入 H在查询空间、键空间和值空间的表达 Q、 K和 V后,计算 在 和 的分数 和 ,这里的分数计算采用的是点积操作。然后将分数进行缩放并使用softmax进行归一化,获得在 这个位置的注意力分布: 和 ,它们代表模型当前在 这个位置需要对输入信息 和 的关注程度。最后根据该位置的注意力分布对 和 进行加权平均获得最终h1这个位置的Attention向量 。
同理,你可以获得第2个位置的Attention向量 context2,或者继续扩展输入序列获得更多的 ,原理都是一样的。注意力机制的计算过程:
假设当前有输入信息 ,我们需要使用自注意力机制获取每个位置的输出 。
- 首先,需要将原始输入映射到查询空间Q、键空间K和值空间V,相关计算公式如下:
- 接下来,我们将去计算每个位置的注意力分布,并且将相应结果进行加权求和:
其中 是经过上述点积、缩放后分数值。
- 最后,为了加快计算效率,这里其实可以使用矩阵计算的方式,一次性计算出所有位置的的Attention输出向量:
恭喜,看到这里相信你已经非常清楚自注意力机制的原理了。
2.正则化
当我们向右移时,我们的模型试图从训练数据中很好地学习细节和噪声,这最终导致在看不见的数据上表现不佳。 也就是说,当模型向右移动时,模型的复杂度增加,使得训练误差减小,而测试误差没有减小。如下图所示。
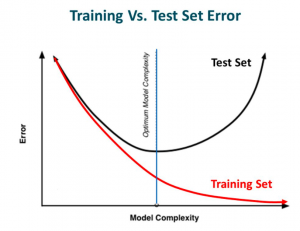
如果你以前建立过神经网络,你就知道它们有多复杂。这使得他们更容易过度拟合。

正则化是一种对学习算法稍加修改以使模型具有更好的泛化能力的技术。这反过来也提高了模型在看不见的数据上的性能。
2.1 正则化如何帮助减少过度拟合
让我们考虑一个神经网络,它对训练数据进行了过度拟合,如下图所示。
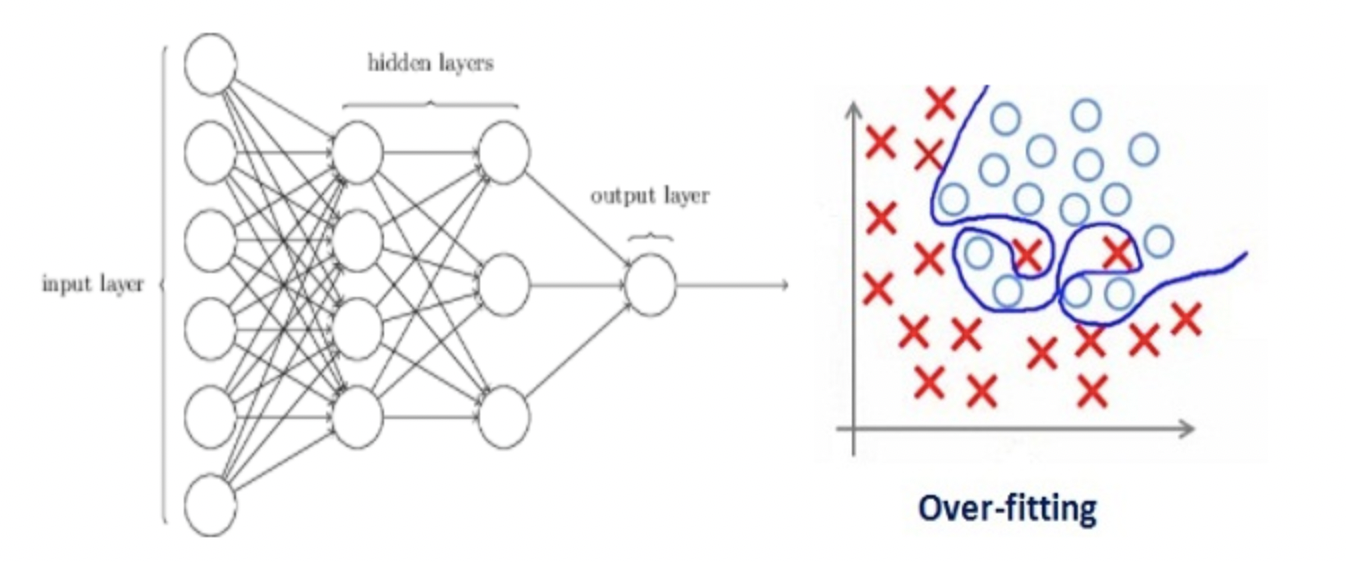
如果你研究过机器学习中正则化的概念,你会有一个公平的想法,正则化惩罚系数。在深度学习中,它实际上惩罚节点的权重矩阵。
假设我们的正则化系数非常高,以至于一些权重矩阵几乎等于零。

这将导致更简单的线性网络和训练数据的轻微欠拟合。
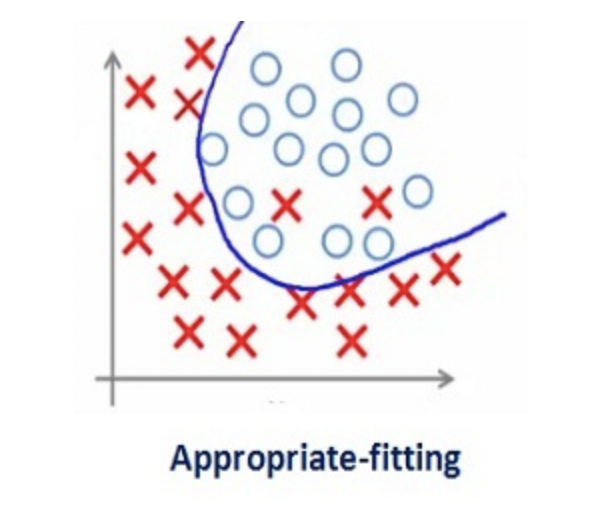
如此大的正则化系数值并不是很有用。我们需要优化正则化系数的值,以获得如下图所示的良好拟合模型。
正则化可以避免算法过拟合,过拟合通常发生在算法学习的输入数据无法反应真实的分布且存在一些噪声的情况。过去数年,研究者提出和开发了多种适合机器学习算法的正则化方法,如数据增强、L2 正则化(权重衰减)、L1 正则化、Dropout、Drop Connect、随机池化和早停等。
除了泛化原因,奥卡姆剃刀原理和贝叶斯估计也都支持着正则化。根据奥卡姆剃刀原理,在所有可能选择的模型中,能很好解释已知数据,并且十分简单的模型才是最好的模型。而从贝叶斯估计的角度来看,正则化项对应于模型的先验概率。
2.2 数据增强
数据增强是提升算法性能、满足深度学习模型对大量数据的需求的重要工具。数据增强通过向训练数据添加转换或扰动来人工增加训练数据集。数据增强技术如水平或垂直翻转图像、裁剪、色彩变换、扩展和旋转通常应用在视觉表象和图像分类中。
关于视觉领域的数据增强的方法详细请参考: 数据增广,后续展开。
2.3 L1 和 L2 正则化
L1 和 L2 正则化是最常用的正则化方法。L1 正则化向目标函数添加正则化项,以减少参数的绝对值总和;而 L2 正则化中,添加正则化项的目的在于减少参数平方的总和。根据之前的研究,L1 正则化中的很多参数向量是稀疏向量,因为很多模型导致参数趋近于 0,因此它常用于特征选择设置中。机器学习中最常用的正则化方法是对权重施加 L2 范数约束。
标准正则化代价函数如下:
其中正则化项 R(w) 是:
另一种惩罚权重的绝对值总和的方法是 L1 正则化:
L1 正则化在零点不可微,因此权重以趋近于零的常数因子增长。很多神经网络在权重衰减公式中使用一阶步骤来解决非凸 L1 正则化问题。L1 范数的近似变体是:
另一个正则化方法是混合 L1 和 L2 正则化,即弹性网络罚项。
整个最优化问题从贝叶斯观点来看是一种贝叶斯最大后验估计,其中正则化项对应后验估计中的先验信息,损失函数对应后验估计中的似然函数,两者的乘积即对应贝叶斯最大后验估计的形式
2.3.1贝叶斯推断分析法
针对L1范数和L2范数还有结论:
L1范数相当于给模型参数θ设置一个参数为 的零均值拉普拉斯先验分布
L2范数相当于给模型参数θ设置一个协方差 的零均值高斯先验分布
1.L2范数相当于给模型参数θ设置一个零均值高斯先验分布
以线性模型为例,结论可以推广到任意模型,线性模型方程可以表示为:
其中ϵ表示误差, ,则有:
计算最大后验估计:
最大化上式,去掉负号,统一参数可以转化为:
上式正好是线性回归问题在L2范数的代价函数,故验证了结论。
2.L1范数相当于给模型参数θ设置一个拉普拉斯先验分布
以线性模型为例,结论可以推广到任意模型,同样假设 则有:
最大化上式,去掉负号和统一参数,就变成了最小化:
上式正好是线性回归问题在L1范数正则下的代价函数,故验证了结论。
如果误差符合0均值的高斯分布,那么最大似然估计法的结果就是最小二乘法,这也是为何误差定义经常使用 的原因,因为这个公式是基于概率推导出来的
2.4 Dropout
Dropout指在训练神经网络过程中随机丢掉一部分神经元来减少神经网络复杂度,从而防止过拟合。Dropout实现方法很简单:在每次迭代训练中,以一定概率随机屏蔽每一层中若干神经元,用余下神经元所构成网络来继续训练。
图1 是Dropout示意图,左边是完整的神经网络,右边是应用了Dropout之后的网络结构。应用Dropout之后,会将标了×的神经元从网络中删除,让它们不向后面的层传递信号。在学习过程中,丢弃哪些神经元是随机决定,因此模型不会过度依赖某些神经元,能一定程度上抑制过拟合。
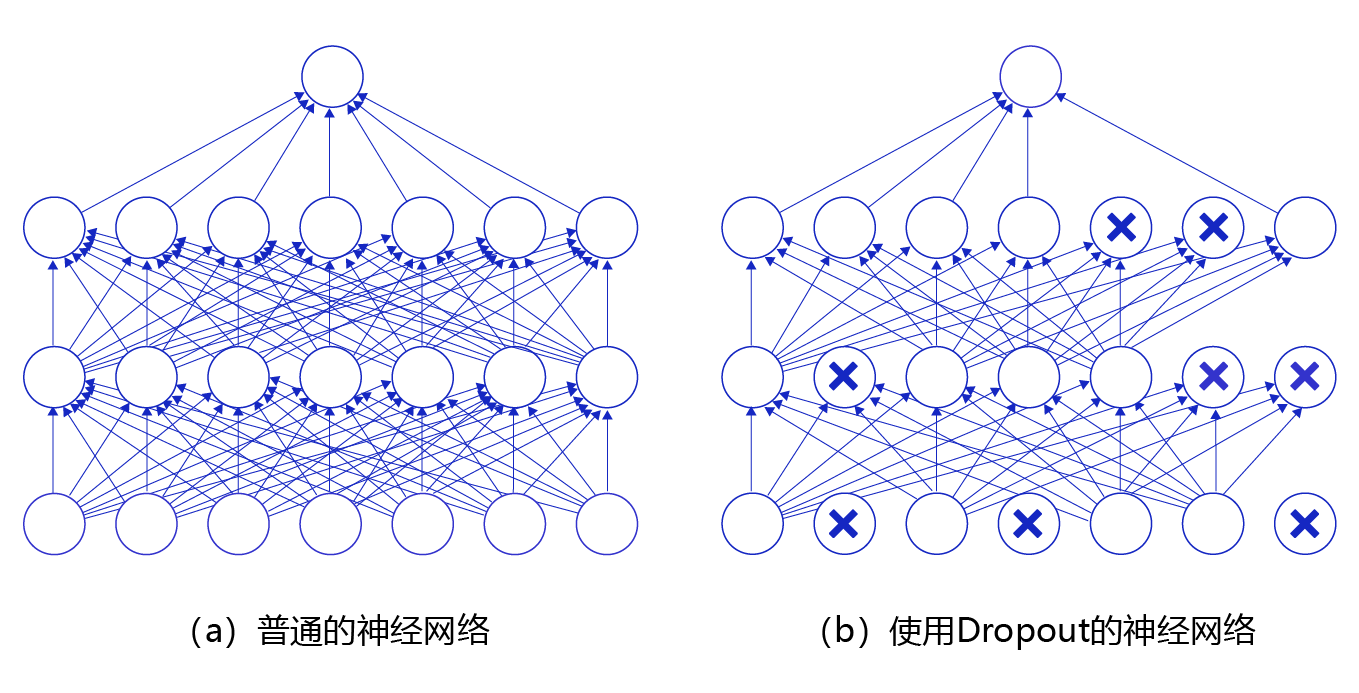
- 应用示例
在预测场景时,会向前传递所有神经元的信号,可能会引出一个新的问题:训练时由于部分神经元被随机丢弃了,输出数据的总大小会变小。比如:计算其L1范数会比不使用Dropout时变小,但是预测时却没有丢弃神经元,这将导致训练和预测时数据的分布不一样。为了解决这个问题,飞桨支持如下两种方法:
- downscale_in_infer
训练时以比例r随机丢弃一部分神经元,不向后传递它们的信号;预测时向后传递所有神经元的信号,但是将每个神经元上的数值乘以 (1−r)。
- upscale_in_train
训练时以比例r随机丢弃一部分神经元,不向后传递它们的信号,但是将那些被保留的神经元上的数值除以 (1−r);预测时向后传递所有神经元的信号,不做任何处理。
已飞桨框架为例:Dropout API中,通过mode参数来指定用哪种方式对神经元进行操作,
paddle.nn.Dropout(p=0.5, axis=None, mode=”upscale_in_train”, name=None)
主要参数如下:
p (float) :将输入节点置为0的概率,即丢弃概率,默认值:0.5。该参数对元素的丢弃概率是针对于每一个元素而言,而不是对所有的元素而言。举例说,假设矩阵内有12个数字,经过概率为0.5的dropout未必一定有6个零。
mode(str) :丢弃法的实现方式,有’downscale_in_infer’和’upscale_in_train’两种,默认是’upscale_in_train’。
# dropout操作
import paddle
import numpy as np
# 设置随机数种子,这样可以保证每次运行结果一致
np.random.seed(100)
# 创建数据[N, C, H, W],一般对应卷积层的输出
data1 = np.random.rand(2,3,3,3).astype('float32')
# 创建数据[N, K],一般对应全连接层的输出
data2 = np.arange(1,13).reshape([-1, 3]).astype('float32')
# 使用dropout作用在输入数据上
x1 = paddle.to_tensor(data1)
# downgrade_in_infer模式下
drop11 = paddle.nn.Dropout(p = 0.5, mode = 'downscale_in_infer')
droped_train11 = drop11(x1)
# 切换到eval模式。在动态图模式下,使用eval()切换到求值模式,该模式禁用了dropout。
drop11.eval()
droped_eval11 = drop11(x1)
# upscale_in_train模式下
drop12 = paddle.nn.Dropout(p = 0.5, mode = 'upscale_in_train')
droped_train12 = drop12(x1)
# 切换到eval模式
drop12.eval()
droped_eval12 = drop12(x1)
x2 = paddle.to_tensor(data2)
drop21 = paddle.nn.Dropout(p = 0.5, mode = 'downscale_in_infer')
droped_train21 = drop21(x2)
# 切换到eval模式
drop21.eval()
droped_eval21 = drop21(x2)
drop22 = paddle.nn.Dropout(p = 0.5, mode = 'upscale_in_train')
droped_train22 = drop22(x2)
# 切换到eval模式
drop22.eval()
droped_eval22 = drop22(x2)
print('x1 {}, \n droped_train11 \n {}, \n droped_eval11 \n {}'.format(data1, droped_train11.numpy(), droped_eval11.numpy()))
print('x1 {}, \n droped_train12 \n {}, \n droped_eval12 \n {}'.format(data1, droped_train12.numpy(), droped_eval12.numpy()))
print('x2 {}, \n droped_train21 \n {}, \n droped_eval21 \n {}'.format(data2, droped_train21.numpy(), droped_eval21.numpy()))
print('x2 {}, \n droped_train22 \n {}, \n droped_eval22 \n {}'.format(data2, droped_train22.numpy(), droped_eval22.numpy()))
程序运行结果如下:
x1
[[[[0.54340494 0.2783694 0.4245176] [0.84477615 0.00471886 0.12156912] [0.67074907 0.82585275 0.13670659]]
[[0.5750933 0.89132196 0.20920213] [0.18532822 0.10837689 0.21969749] [0.9786238 0.8116832 0.17194101]]
[[0.81622475 0.27407375 0.4317042 ] [0.9400298 0.81764936 0.33611196] [0.17541045 0.37283206 0.00568851]]]
[[[0.25242636 0.7956625 0.01525497] [0.5988434 0.6038045 0.10514768] [0.38194343 0.03647606 0.89041156]]
[[0.98092085 0.05994199 0.89054596] [0.5769015 0.7424797 0.63018394] [0.5818422 0.02043913 0.21002658]]
[[0.5446849 0.76911515 0.25069523] [0.2858957 0.8523951 0.9750065 ] [0.8848533 0.35950786 0.59885895]]]]
droped_train11
[[[[0. 0.2783694 0.4245176 ] [0. 0.00471886 0. ] [0. 0.82585275 0. ]]
[[0. 0. 0.20920213] [0.18532822 0.10837689 0. ] [0.9786238 0. 0.17194101]]
[[0.81622475 0.27407375 0. ] [0. 0. 0.33611196] [0.17541045 0.37283206 0.00568851]]]
[[[0.25242636 0. 0. ] [0.5988434 0.6038045 0.10514768] [0.38194343 0. 0.89041156]]
[[0.98092085 0. 0. ] [0.5769015 0.7424797 0. ] [0.5818422 0.02043913 0. ]]
[[0.5446849 0.76911515 0. ] [0. 0.8523951 0.9750065 ] [0. 0.35950786 0.59885895]]]],
droped_eval11
[[[[0.27170247 0.1391847 0.2122588 ] [0.42238808 0.00235943 0.06078456] [0.33537453 0.41292638 0.0683533 ]]
[[0.28754666 0.44566098 0.10460106] [0.09266411 0.05418845 0.10984875] [0.4893119 0.4058416 0.08597051]]
[[0.40811238 0.13703687 0.2158521 ] [0.4700149 0.40882468 0.16805598] [0.08770522 0.18641603 0.00284425]]]
[[[0.12621318 0.39783126 0.00762749] [0.2994217 0.30190226 0.05257384] [0.19097172 0.01823803 0.44520578]]
[[0.49046043 0.02997099 0.44527298] [0.28845075 0.37123984 0.31509197] [0.2909211 0.01021957 0.10501329]]
[[0.27234244 0.38455757 0.12534761] [0.14294785 0.42619756 0.48750326] [0.44242665 0.17975393 0.29942948]]]]
x1
[[[[0.54340494 0.2783694 0.4245176 ] [0.84477615 0.00471886 0.12156912] [0.67074907 0.82585275 0.13670659]]
[[0.5750933 0.89132196 0.20920213] [0.18532822 0.10837689 0.21969749] [0.9786238 0.8116832 0.17194101]]
[[0.81622475 0.27407375 0.4317042 ] [0.9400298 0.81764936 0.33611196] [0.17541045 0.37283206 0.00568851]]]
[[[0.25242636 0.7956625 0.01525497] [0.5988434 0.6038045 0.10514768] [0.38194343 0.03647606 0.89041156]]
[[0.98092085 0.05994199 0.89054596] [0.5769015 0.7424797 0.63018394] [0.5818422 0.02043913 0.21002658]]
[[0.5446849 0.76911515 0.25069523] [0.2858957 0.8523951 0.9750065 ] [0.8848533 0.35950786 0.59885895]]]]
droped_train12
[[[[0. 0.5567388 0.8490352 ] [0. 0. 0.24313824] [0. 0. 0. ]]
[[0. 0. 0.41840425] [0.37065643 0. 0. ] [1.9572476 0. 0. ]]
[[0. 0. 0. ] [0. 1.6352987 0.6722239 ] [0.3508209 0. 0.01137702]]]
[[[0. 1.591325 0.03050994] [1.1976868 1.207609 0. ] [0.76388687 0. 1.7808231 ]]
[[0. 0. 0. ] [1.153803 0. 0. ] [1.1636844 0. 0.42005315]]
[[1.0893698 0. 0.50139046] [0.5717914 1.7047902 0. ] [0. 0.7190157 0. ]]]]
droped_eval12
[[[[0.54340494 0.2783694 0.4245176 ] [0.84477615 0.00471886 0.12156912] [0.67074907 0.82585275 0.13670659]]
[[0.5750933 0.89132196 0.20920213] [0.18532822 0.10837689 0.21969749] [0.9786238 0.8116832 0.17194101]]
[[0.81622475 0.27407375 0.4317042 ] [0.9400298 0.81764936 0.33611196] [0.17541045 0.37283206 0.00568851]]]
[[[0.25242636 0.7956625 0.01525497] [0.5988434 0.6038045 0.10514768] [0.38194343 0.03647606 0.89041156]]
[[0.98092085 0.05994199 0.89054596] [0.5769015 0.7424797 0.63018394] [0.5818422 0.02043913 0.21002658]]
[[0.5446849 0.76911515 0.25069523] [0.2858957 0.8523951 0.9750065 ] [0.8848533 0.35950786 0.59885895]]]]
x2
[[ 1. 2. 3.] [ 4. 5. 6.] [ 7. 8. 9.] [10. 11. 12.]],
droped_train21
[[ 1. 2. 3.] [ 4. 5. 6.] [ 0. 0. 9.] [ 0. 11. 0.]]
droped_eval21
[[0.5 1. 1.5] [2. 2.5 3. ] [3.5 4. 4.5] [5. 5.5 6. ]]
x2
[[ 1. 2. 3.] [ 4. 5. 6.] [ 7. 8. 9.] [10. 11. 12.]]
droped_train22
[[ 2. 0. 6.] [ 0. 10. 0.] [14. 16. 18.] [ 0. 22. 24.]]
droped_eval22
[[ 1. 2. 3.] [ 4. 5. 6.] [ 7. 8. 9.] [10. 11. 12.]]
从上面的运行结果可以看到,经过dropout之后,tensor中的某些元素变为了0,这个就是dropout实现的功能,通过随机将输入数据的元素置0,消除减弱了神经元节点间的联合适应性,增强模型的泛化能力。
在程序中,我们将随机失活比率设为0.5,分别使用两种不同的策略进行dropout,并且分别打印训练和评估模式下的网络层输出。其中,数据 x1模拟的是卷积层的输出数据, 数据 x2模拟的是全连接层的输入数据。由于通常情况下,我们会把dropout添加到全连接层后,所以这里针对前一层的输出为 x2的情况为大家进行分析,前一层的输出为 x1的情况也基本类似。
x2定义如下:
将 paddle.nn.Dropout API 中 mode 设置为 ‘downscale_in_infer’ 时,可以观察到在训练模式下,部分元素变为0,其他元素的值并没有发生改变,此时 为:
而在验证模式下,所有的元素都被保留,但是所有元素的值都进行了缩放,缩放的系数为(1−r),即(1−0.5)=0.,此时 x2_eval为:
而将 paddle.nn.Dropout API 中 mode 设置为 ‘upscale_in_train’ 时,可以观察到在训练模式下,部分元素变为0,其他元素的值进行了缩放,缩放的系数为1/1−r,即1/(1−0.5)=2 ,,此时 x2_train为:
而在验证模式下,所有的元素都被保留,且所有元素的值并没有发生改变,此时 x2_eval为:
2.5 Drop Connect
DropConnect也是在ICML2013上发表的另一种减少算法过拟合的正则化策略,是 Dropout 的一般化。在 Drop Connect 的过程中需要将网络架构权重的一个随机选择子集设置为零,取代了在 Dropout 中对每个层随机选择激活函数的子集设置为零的做法。由于每个单元接收来自过去层单元的随机子集的输入,Drop Connect 和 Dropout 都可以获得有限的泛化性能。Drop Connect 和 Dropout 相似的地方在于它涉及在模型中引入稀疏性,不同之处在于它引入的是权重的稀疏性而不是层的输出向量的稀疏性。 对于一个DropConnect层,输出可以写为:
其中r是一个层的输出,v是一个层的输入,W是权重参数,M是编码连接信息的二进制矩阵,其中 。 在训练期间,M中的每个元素都是独立的对样本进行。基本上为每个示例实例化不同的连接。另外,这些偏见在训练中也被掩盖了。
2.5.1 dropout与dropconncet区别
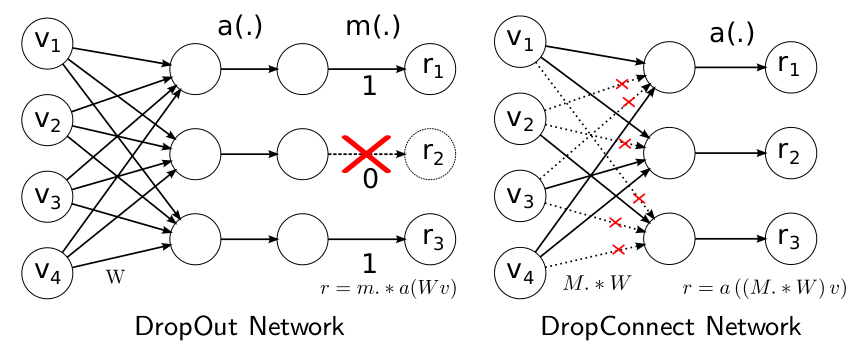
Dropout是随机将隐含层节点的输出清0,针对的是输出。
DropConnect是将节点中的每个与其相连的输入权值以1-p的概率清0;针对的是输入。
2.5.2 DropConnect的训练
使用DropConnect时,需要对每个example, 每个echo都随机sample一个M矩阵(元素值都是0或1, 俗称mask矩阵)。training部分的算法流程如下:

DropConnect只能用于全连接的网络层(和dropout一样),如果网络中用到了卷积,则用patch卷积时的隐层节点是不使用DropConnect的,因此上面的流程里有一个Extract feature步骤,该步骤就是网络前面那些非全连接层的传播过程,比如卷积+pooling.
2.5.3 DropConnect的推理
在Dropout网络中进行inference时,是将所有的权重W都scale一个系数p(作者证明这种近似在某些场合是有问题的)。而在对DropConnect进行推理时,采用的是对每个输入(每个隐含层节点连接有多个输入)的权重进行高斯分布的采样。该高斯分布的均值与方差当然与前面的概率值p有关,满足的高斯分布为:
推理过程如下:

由上面的过程可知,在进行inference时,需要对每个权重都进行sample,所以DropConnect速度会慢些。
根据作者的观点,Dropout和DropConnect都类似模型平均,Dropout是 个模型的平均,而DropConnect是 个模型的平均。(m是向量,M是矩阵,取模表示矩阵或向量中对应元素的个数),从这点上来说,DropConnect模型平均能力更强,因为
2.6 早停法
早停法可以限制模型最小化代价函数所需的训练迭代次数。早停法通常用于防止训练中过度表达的模型泛化性能差。如果迭代次数太少,算法容易欠拟合(方差较小,偏差较大),而迭代次数太多,算法容易过拟合(方差较大,偏差较小)。早停法通过确定迭代次数解决这个问题,不需要对特定值进行手动设置。
提前停止是一种交叉验证的策略,即把一部分训练集保留作为验证集。当看到验证集上的性能变差时,就立即停止模型的训练。
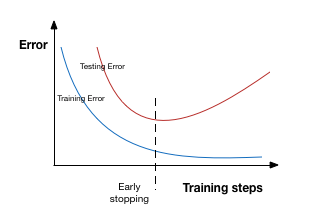
在上图中,我们在虚线处停止模型的训练,因为在此处之后模型会开始在训练数据上过拟合。

- 点赞
- 收藏
- 关注作者
评论(0)