基于Labelstudio的UIE半监督智能标注方案(本地版),赶快用起来

基于Labelstudio的UIE半监督智能标注方案(本地版)
更多技术细节参考上一篇项目,本篇主要侧重本地端链路走通教学,提速提效:
基于Labelstudio的UIE半监督深度学习的智能标注方案(云端版),提效
更多内容参考文末码源
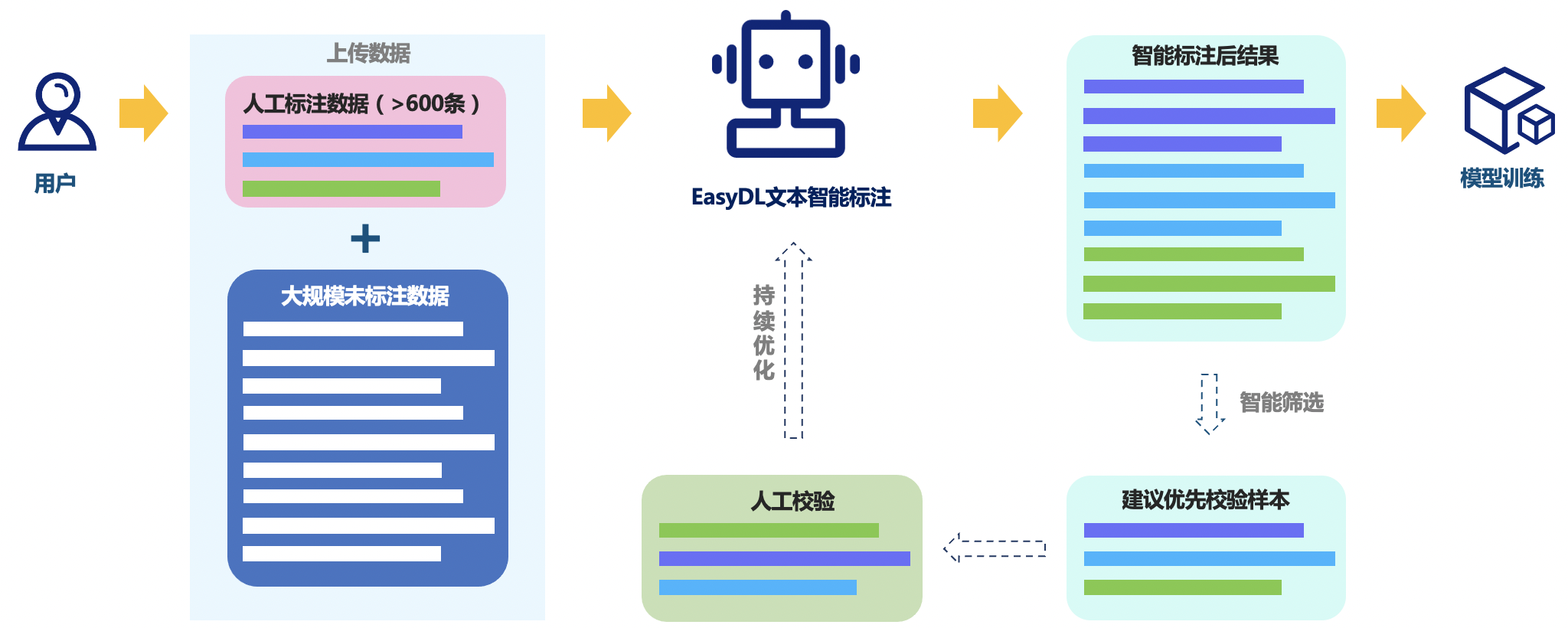
自然语言处理信息抽取智能标注方案包括以下几种:
基于规则的标注方案:通过编写一系列规则来识别文本中的实体、关系等信息,并将其标注。
- 基于规则的标注方案是一种传统的方法,它需要人工编写规则来识别文本中的实体、关系等信息,并将其标注。
- 这种方法的优点是易于理解和实现,但缺点是需要大量的人工工作,并且规则难以覆盖所有情况。
基于机器学习的标注方案:通过训练模型来自动识别文本中的实体、关系等信息,并将其标注。
- 基于机器学习的标注方案是一种自动化的方法,它使用已经标注好的数据集训练模型,并使用模型来自动标注文本中的实体、关系等信息。
- 这种方法的优点是可以处理大量的数据,并且可以自适应地调整模型,但缺点是需要大量的标注数据和计算资源,并且模型的性能受到标注数据的质量和数量的限制。
基于深度学习的标注方案:通过使用深度学习模型来自动识别文本中的实体、关系等信息,并将其标注。
- 基于深度学习的标注方案是一种最新的方法,它使用深度学习模型来自动从文本中提取实体、关系等信息,并将其标注。
- 这种方法的优点是可以处理大量的数据,并且具有较高的准确性,但缺点是需要大量的标注数据和计算资源,并且模型的训练和调试需要专业的知识和技能。
基于半监督学习的标注方案:通过使用少量的手工标注数据和大量的未标注数据来训练模型,从而实现自动标注。
- 基于半监督学习的标注方案是一种利用少量的手工标注数据和大量的未标注数据来训练模型的方法。
- 这种方法的优点是可以利用未标注数据来提高模型的性能,但缺点是需要大量的未标注数据和计算资源,并且模型的性能受到标注数据的质量
基于远程监督的标注方案:利用已知的知识库来自动标注文本中的实体、关系等信息,从而减少手工标注的工作量。
本次项目主要讲解的是基于半监督深度学习的标注方案。
1.智能标注本地版 Machine Learning 集成教学
1.1 本地启动 Label Studio
安装label-studio:
#创建名为label_studio的虚拟环境(示例的Python版本为3.8)
conda create -n labelstudio python=3.8
#激活虚拟环境
conda activate labelstudio
#pip安装label-studio (version=1.7.2)
pip install label-studio==1.7.2
1.2 启动 Machine Learning Backend
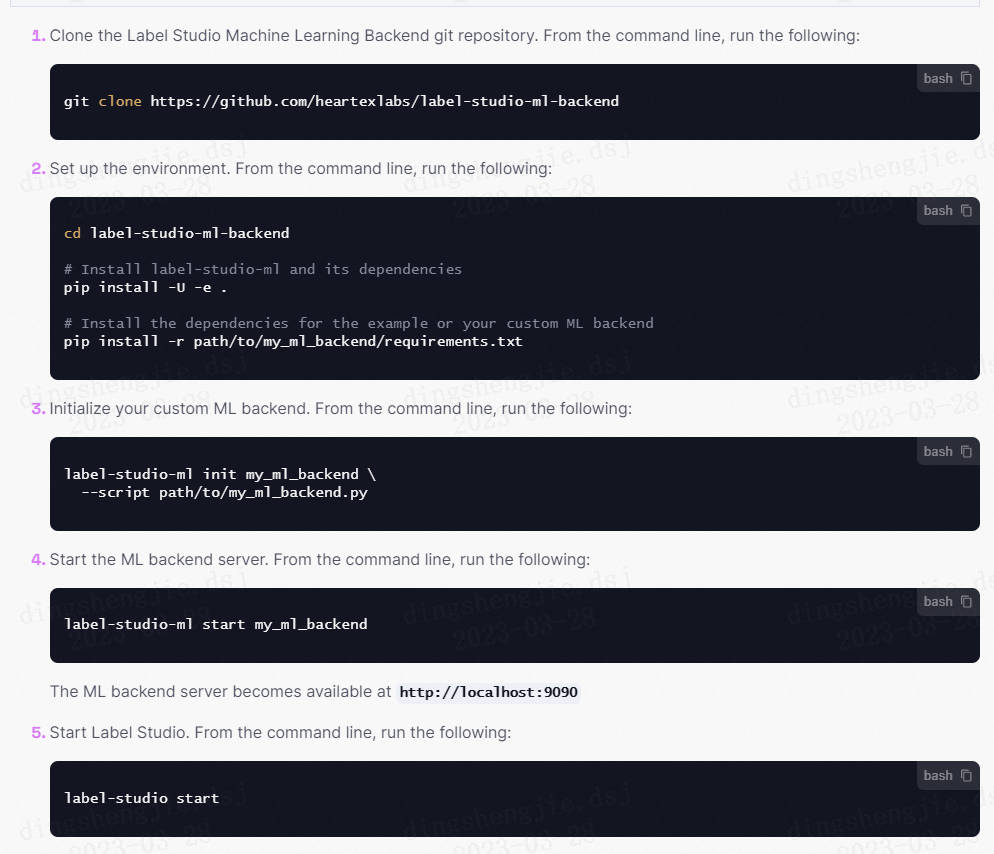
在终端中依次执行下列命令:
#安装label-studio机器学习后端,dirname为放代码的文件夹路径
cd dirname
git clone https://github.com/heartexlabs/label-studio-ml-backend
#安装label-studio及其依赖
cd label-studio-ml-backend
pip install -U -e .
#(可选) 安装label-studio中examples运行所需的requirements
pip install -r label_studio_ml/examples/requirements.txt
创建与启动模型:定义模型
在使用label-studio后端之前,要先定义好自己的训练模型,模型的定义需要继承自label-studio指定的类,具体可参考第四节。
创建后端模型:按照要求创建好的模型文件的路径假设为/Users/kyrol/Desktop/my_ml_backend.py,终端中执行以下命令:
# 初始化自定义机器学习后端
label-studio-ml init my_ml_backend --script /Users/kyrol/Desktop/my_ml_backend.py
#命令执行完毕会在当前文件夹下创建名为 my_ml_backend 的文件夹, 里面放有 my_ml_backend.py, _wsgi.py 等内容。
#其中,_wsgi.py是要运行的python 主文件,可以查看里面内容。注意:同时需要把依赖文件放入my_ml_backend.py文件夹。
# 开启机器学习后端服务
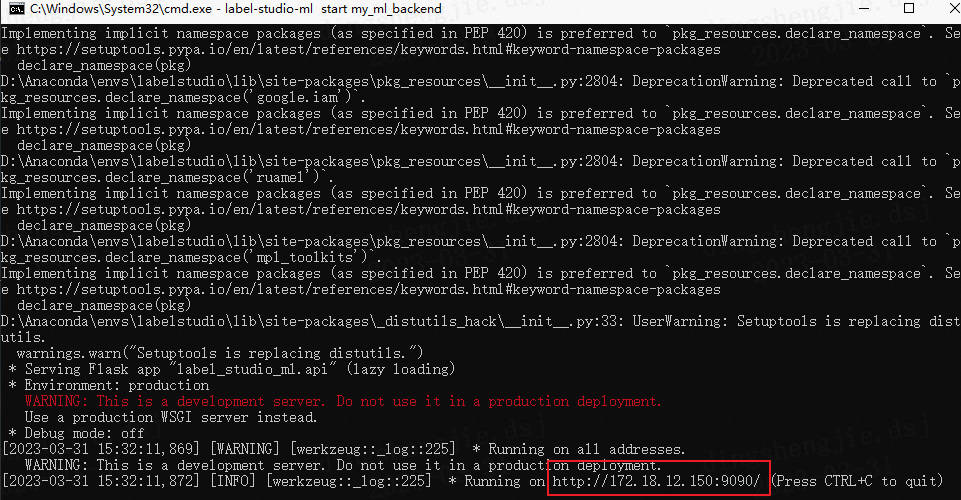
label-studio-ml start my_ml_backend
成功启动后,在终端中可以看到 ML 后端的 URL。
1.3 模型配置与训练
开启可视化窗口,再开启一个终端窗口,首先,激活conda对应的环境;然后,cd 到label-studio代码所在路径;然后,执行以下终端命令,启动可视化的窗口:
在启动自定义机器学习后端之后,就可以将其添加到 Label Studio 项目中。
具体步骤如下:
配置训练数据文件
- 根据不同的任务配置不同的标签,在settings中点击Labeling Interface, 配置项目标签,具体可参考官网。
训练模型
- 创建一个project
- 点击 setting
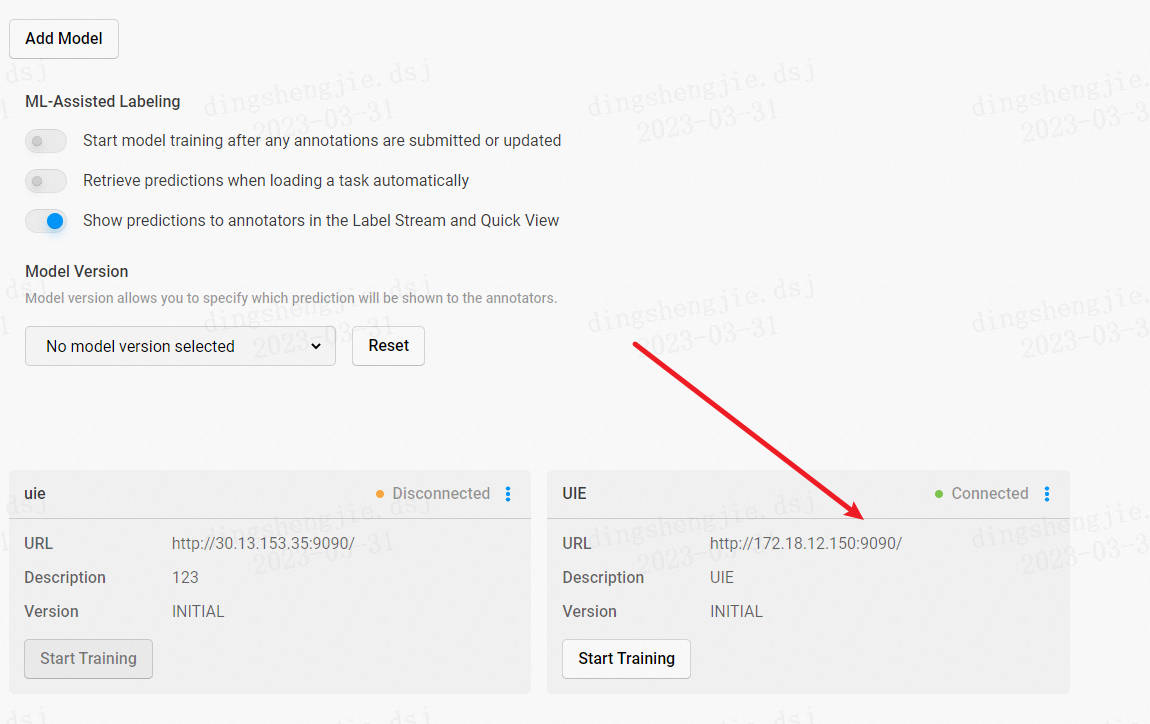
- 点击 Machine Learning
- 配置模型训练端口,导入模型
训练后的模型会保存在 my_ml_backend 文件夹中以数字命名的文件夹内。
具体步骤如下所示:
- 点击 Settings - Machine Learning - Add Model
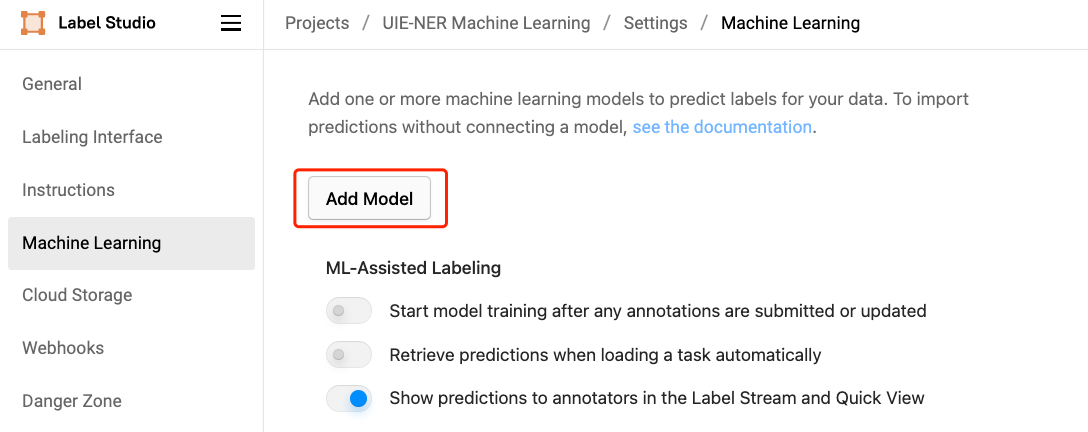
- 填入标题、ML 后端的 URL、描述(可选)等内容
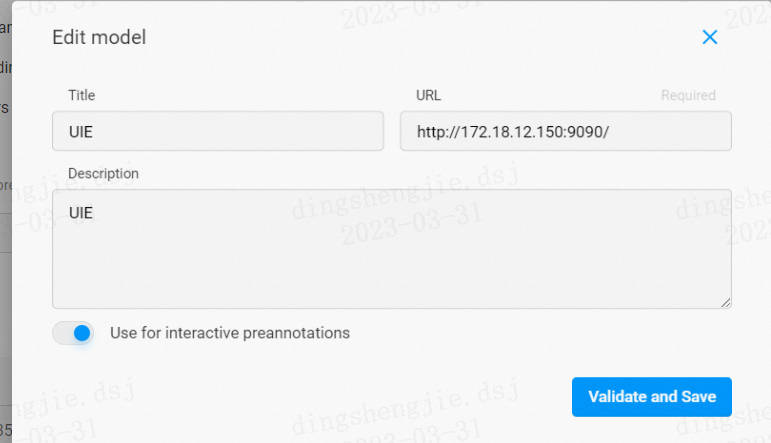
选择 Use for interactive preannotations 打开交互式预注释功能(可选)
点击 Validate and Save
1.3 获取交互式预注释
若要使用交互式预注释功能,需在添加 ML Backend 时打开 Use for interactive preannotations 选项。如未打开,可点击 Edit 进行编辑。然后随便点击一个数据,label studio 就会悄悄运行刚才的 ml backend 生成新的标注了。
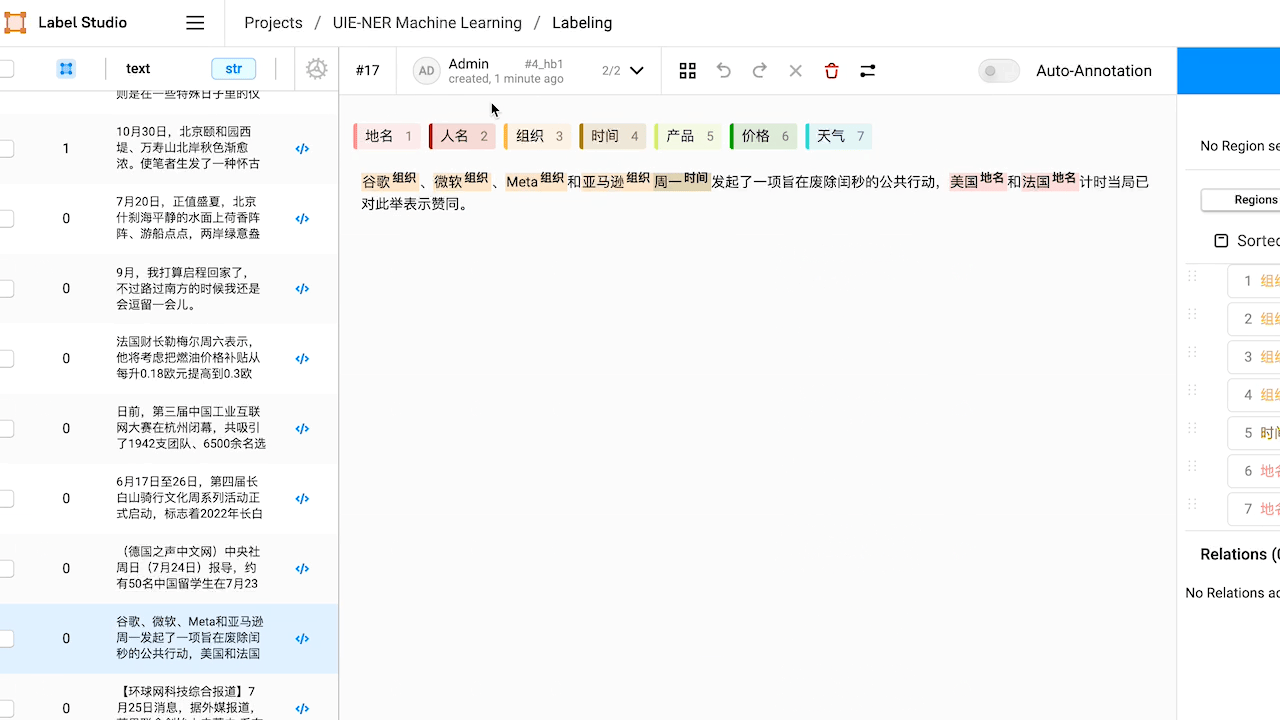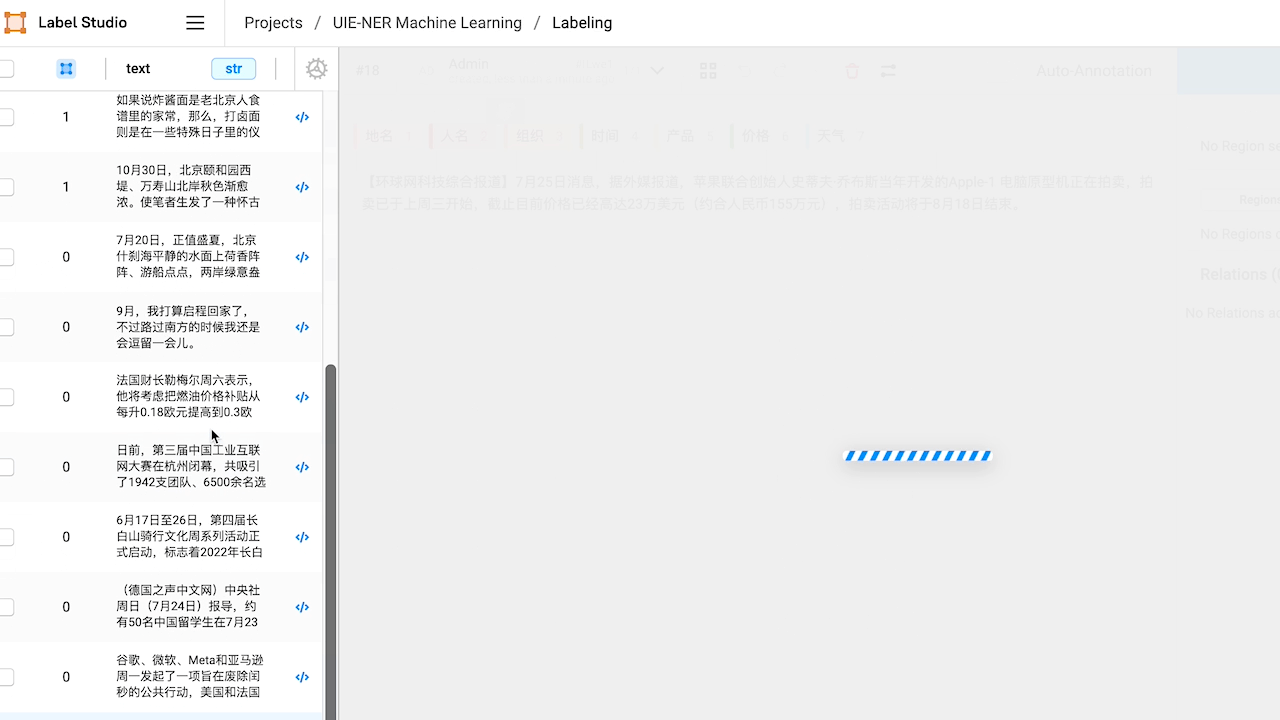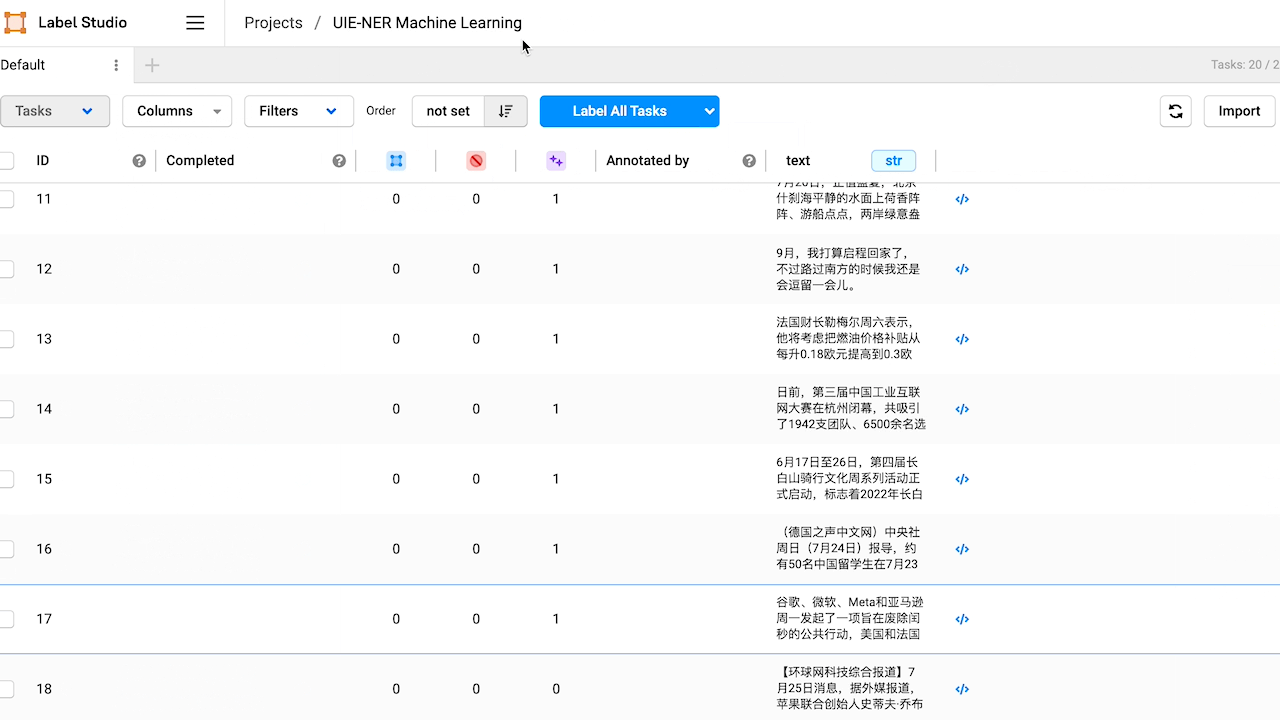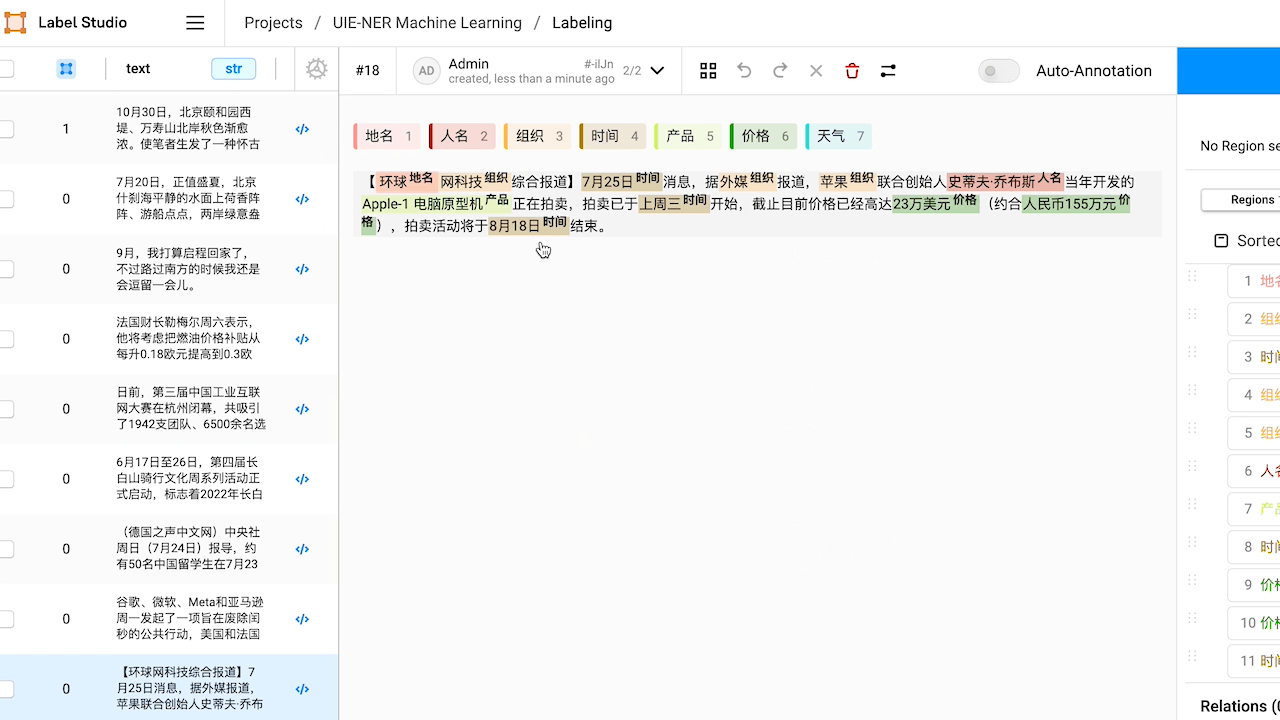
查看预标注好的数据,如有必要,对标注进行修改。
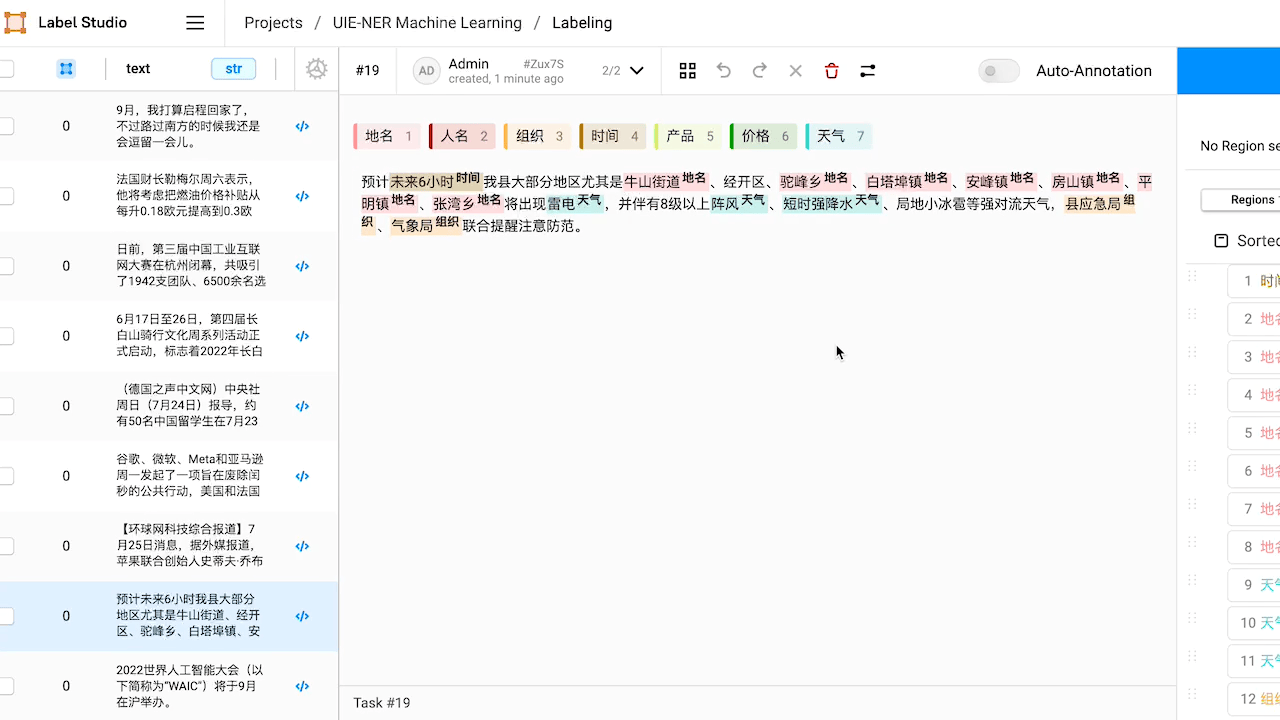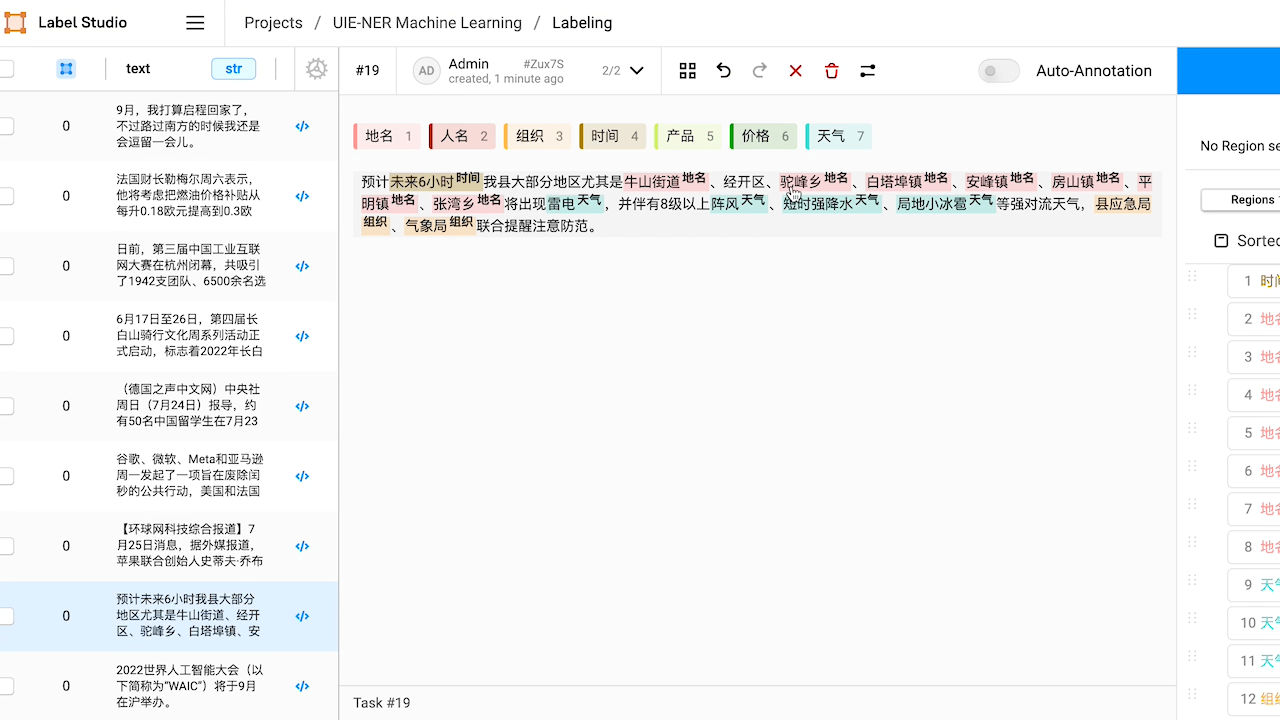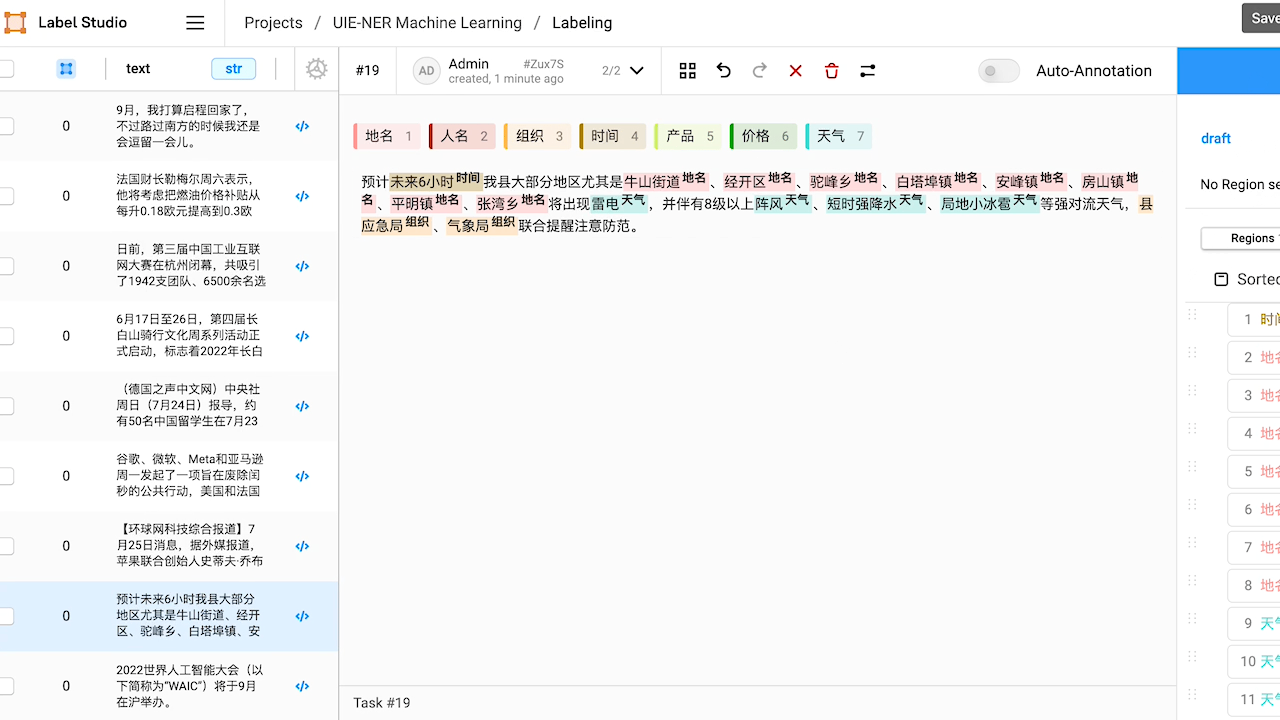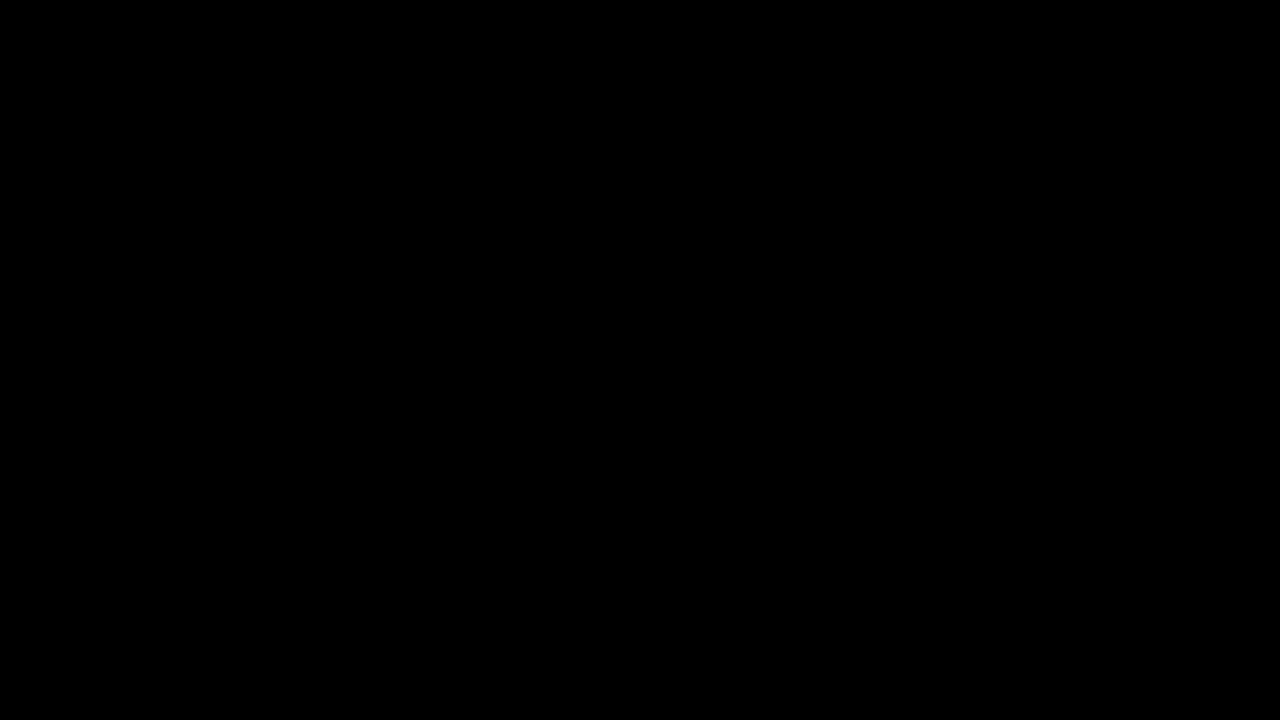




本例中,预标注的结果中『NBA』没有被识别出来,手动添加实体将其标注为『组织』。
本例中,预标注的结果中将『人名』实体『三月』错标注为『时间』实体,手动进行修改。
修改完成后,或预标注的结果已经符合预期,点击 Submit 提交标注结果。
1.4 智能标注(自动再训练模型)
在标注了至少一项任务之后,就可以开始训练模型了。
点击 Settings - Machine Learning - Start Training 开始训练。
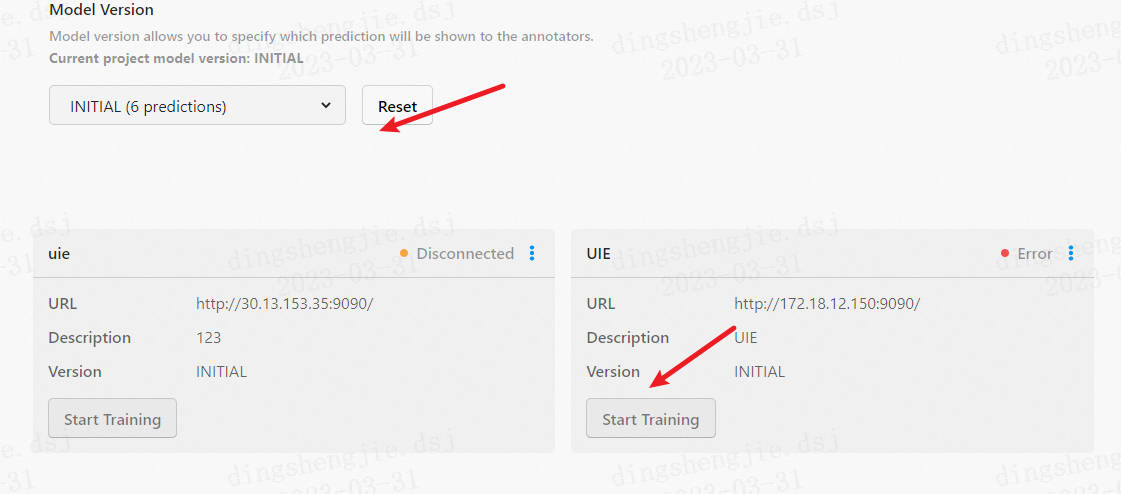
动态图为引用方便展示这个流程。
**然后返回启动 label-studio-ml-backend 的窗口可以看到训练的流程启动了。 **
2.UIE-base预训练模型进行命名实体识别
from pprint import pprint
from paddlenlp import Taskflow
schema = ['地名', '人名', '组织', '时间', '产品', '价格', '天气']
ie = Taskflow('information_extraction', schema=schema)
pprint(ie("2K 与 Gearbox Software 宣布,《小缇娜的奇幻之地》将于 6 月 24 日凌晨 1 点登录 Steam,此前 PC 平台为 Epic 限时独占。在限定期间内,Steam 玩家可以在 Steam 入手《小缇娜的奇幻之地》,并在 2022 年 7 月 8 日前享有获得黄金英雄铠甲包。"))
[{'产品': [{'end': 35,
'probability': 0.8595664902550801,
'start': 25,
'text': '《小缇娜的奇幻之地》'}],
'地名': [{'end': 34,
'probability': 0.30077351606695757,
'start': 26,
'text': '小缇娜的奇幻之地'},
{'end': 117,
'probability': 0.5250433327469182,
'start': 109,
'text': '小缇娜的奇幻之地'}],
'时间': [{'end': 52,
'probability': 0.8796518890642702,
'start': 38,
'text': '6 月 24 日凌晨 1 点'}],
'组织': [{'end': 2,
'probability': 0.6914450625760651,
'start': 0,
'text': '2K'},
{'end': 93,
'probability': 0.5971815528872604,
'start': 88,
'text': 'Steam'},
{'end': 75,
'probability': 0.5844303540013343,
'start': 71,
'text': 'Epic'},
{'end': 105,
'probability': 0.45620707081511114,
'start': 100,
'text': 'Steam'},
{'end': 60,
'probability': 0.5683007420326334,
'start': 55,
'text': 'Steam'},
{'end': 21,
'probability': 0.6797917390407271,
'start': 5,
'text': 'Gearbox Software'}]}]
pprint(ie("近日,量子计算专家、ACM计算奖得主Scott Aaronson通过博客宣布,将于本周离开得克萨斯大学奥斯汀分校(UT Austin)一年,并加盟人工智能研究公司OpenAI。"))
[{'人名': [{'end': 23,
'probability': 0.664236391748247,
'start': 18,
'text': 'Scott'},
{'end': 32,
'probability': 0.479811241610971,
'start': 24,
'text': 'Aaronson'}],
'时间': [{'end': 43,
'probability': 0.8424644728072508,
'start': 41,
'text': '本周'}],
'组织': [{'end': 87,
'probability': 0.5550909248934985,
'start': 81,
'text': 'OpenAI'}]}]
使用默认模型 uie-base 进行命名实体识别,效果还不错,大多数的命名实体被识别出来了,但依然存在部分实体未被识别出,部分文本被误识别等问题。比如 “Scott Aaronson” 被识别为了两个人名,比如 “得克萨斯大学奥斯汀分校” 没有被识别出来。为提升识别效果,将通过标注少量数据对模型进行微调。
3.模型微调
在终端中执行以下脚本,将 label studio 导出的数据文件格式转换成 doccano 导出的数据文件格式。
python labelstudio2doccano.py --labelstudio_file dataset/label-studio.json
参数说明:
- labelstudio_file: label studio 的导出文件路径(仅支持 JSON 格式)。
- doccano_file: doccano 格式的数据文件保存路径,默认为 “doccano_ext.jsonl”。
- task_type: 任务类型,可选有抽取(“ext”)和分类(“cls”)两种类型的任务,默认为 “ext”。
!python doccano.py \
--doccano_file dataset/doccano_ext.jsonl \
--task_type "ext" \
--save_dir ./data \
--splits 0.8 0.2 0
参数说明:
- doccano_file: doccano 格式的数据标注文件路径。
- task_type: 选择任务类型,可选有抽取(“ext”)和分类(“cls”)两种类型的任务。
- save_dir: 训练数据的保存目录,默认存储在 data 目录下。
- negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为 5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。
- splits: 划分数据集时训练集、验证集、测试集所占的比例。默认为 [0.8, 0.1, 0.1] 。
- options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为 [“正向”, “负向”]。
- prompt_prefix: 声明分类任务的 prompt 前缀信息,该参数只对分类类型任务有效。默认为 “情感倾向”。
- is_shuffle: 是否对数据集进行随机打散,默认为 True。
- seed: 随机种子,默认为 1000。
- separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度级分类任务有效。默认为 “##”。
注:
- 每次执行 doccano.py 脚本,将会覆盖已有的同名数据文件。
3.1 Finetune
在终端中执行以下脚本进行模型微调。
# 然后在终端中执行以下脚本,对 doccano 格式的数据文件进行处理,执行后会在 /home/data 目录下生成训练/验证/测试集文件。
!python finetune.py \
--train_path "./data/train.txt" \
--dev_path "./data/dev.txt" \
--save_dir "./checkpoint" \
--learning_rate 1e-5 \
--batch_size 32 \
--max_seq_len 512 \
--num_epochs 100 \
--model "uie-base" \
--seed 1000 \
--logging_steps 100 \
--valid_steps 100 \
--device "gpu"
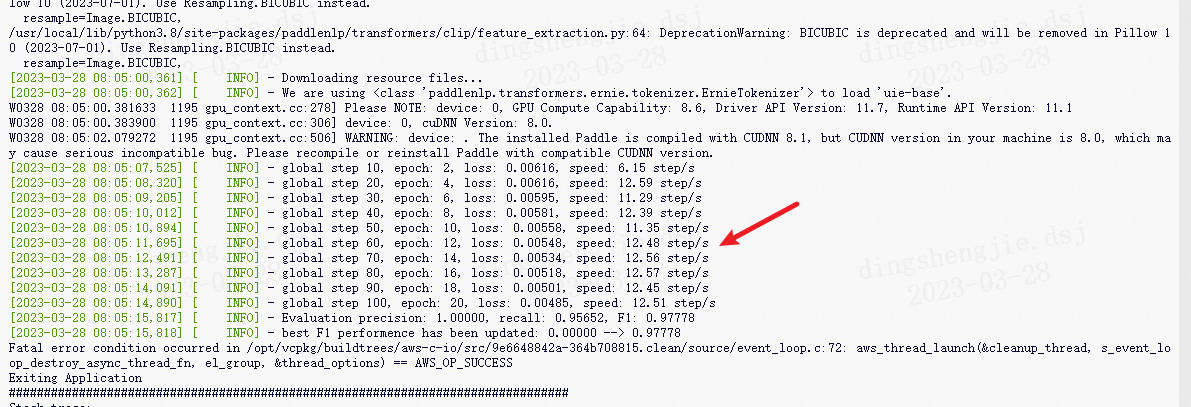
[2023-03-31 16:14:53,465] [ INFO] - global step 600, epoch: 67, loss: 0.00012, speed: 3.76 step/s
[2023-03-31 16:14:53,908] [ INFO] - Evaluation precision: 0.93478, recall: 0.79630, F1: 0.86000
[2023-03-31 16:15:20,328] [ INFO] - global step 700, epoch: 78, loss: 0.00010, speed: 3.79 step/s
[2023-03-31 16:15:20,777] [ INFO] - Evaluation precision: 0.93750, recall: 0.83333, F1: 0.88235
[2023-03-31 16:15:46,992] [ INFO] - global step 800, epoch: 89, loss: 0.00009, speed: 3.81 step/s
[2023-03-31 16:15:47,439] [ INFO] - Evaluation precision: 0.91667, recall: 0.81481, F1: 0.86275
[2023-03-31 16:16:13,316] [ INFO] - global step 900, epoch: 100, loss: 0.00008, speed: 3.86 step/s
[2023-03-31 16:16:13,758] [ INFO] - Evaluation precision: 0.95833, recall: 0.85185, F1: 0.90196
结果展示:
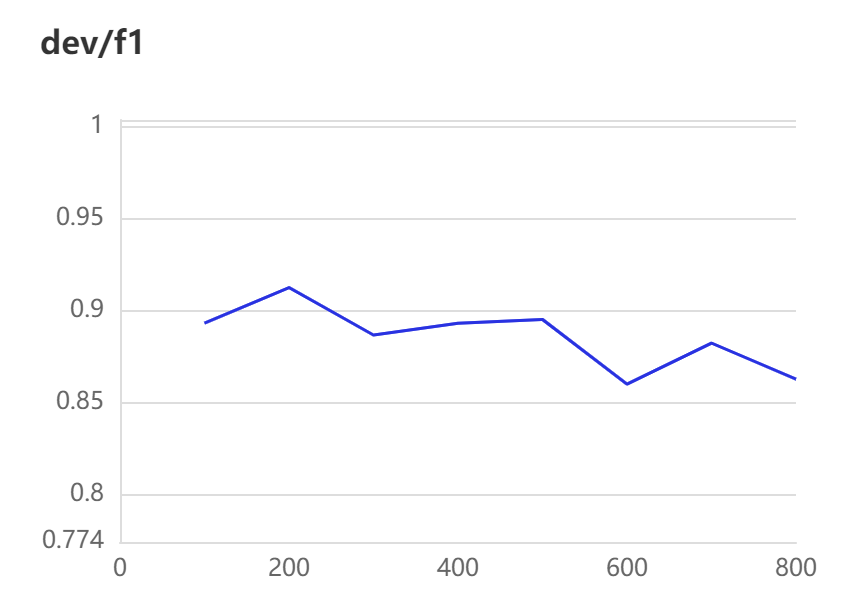
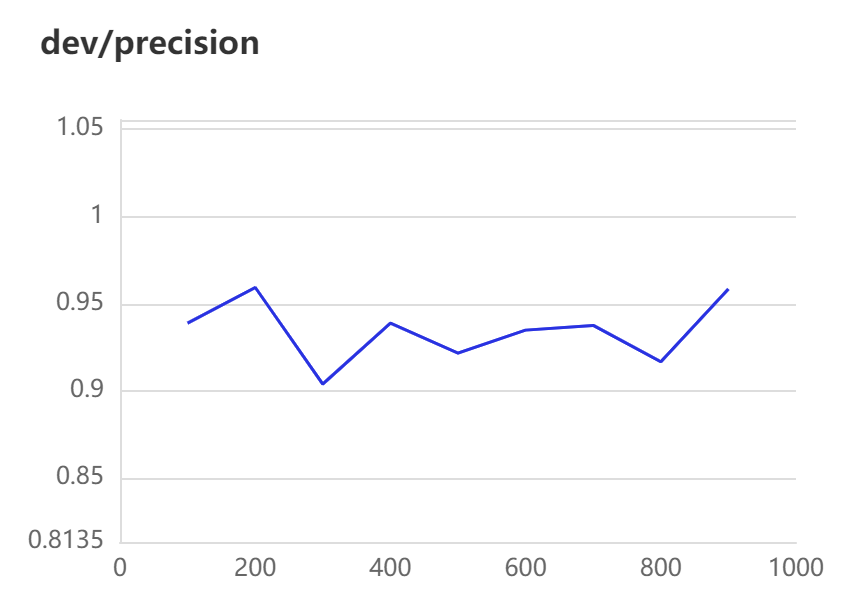
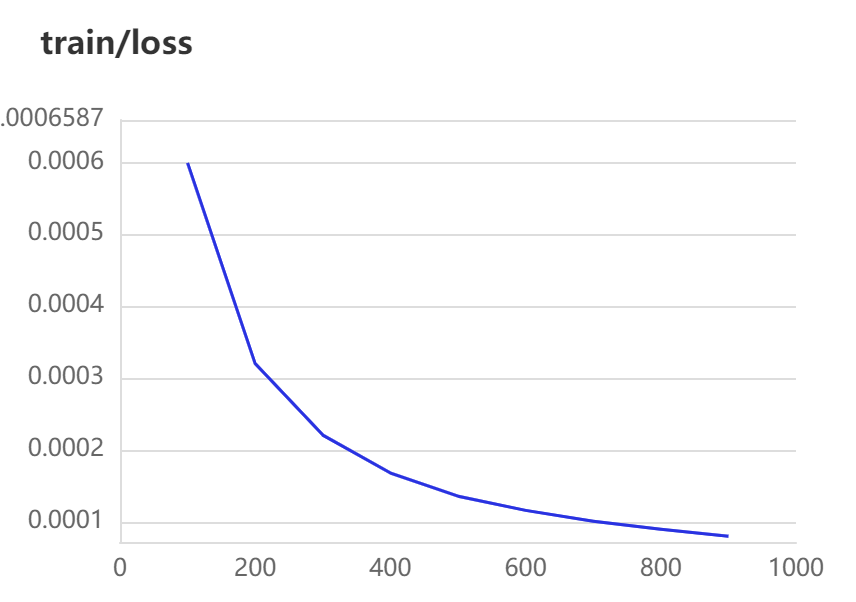
参数说明:
- train_path: 训练集文件路径。
- dev_path: 验证集文件路径。
- save_dir: 模型存储路径,默认为 “./checkpoint”。
- learning_rate: 学习率,默认为 1e-5。
- batch_size: 批处理大小,请结合机器情况进行调整,默认为 16。
- max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为 512。
- num_epochs: 训练轮数,默认为 100。
- model: 选择模型,程序会基于选择的模型进行模型微调,可选有 “uie-base”, “uie-medium”, “uie-mini”, “uie-micro” 和 “uie-nano”,默认为 “uie-base”。
- seed: 随机种子,默认为 1000。
- logging_steps: 日志打印的间隔 steps 数,默认为 10。
- valid_steps: evaluate 的间隔 steps 数,默认为 100。
- device: 选用什么设备进行训练,可选 “cpu” 或 “gpu”。
- init_from_ckpt: 初始化模型参数的路径,可从断点处继续训练。
3.2 模型评估
在终端中执行以下脚本进行模型评估。
输出示例:
参数说明:
- model_path: 进行评估的模型文件夹路径,路径下需包含模型权重文件 model_state.pdparams 及配置文件 model_config.json。
- test_path: 进行评估的测试集文件。
- batch_size: 批处理大小,请结合机器情况进行调整,默认为 16。
- max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为 512。
- debug: 是否开启 debug 模式对每个正例类别分别进行评估,该模式仅用于模型调试,默认关闭。
debug 模式输出示例:
!python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/dev.txt \
--batch_size 16 \
--max_seq_len 512
[2023-03-31 16:16:18,503] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'.
W0331 16:16:18.530714 1666 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0331 16:16:18.533171 1666 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2023-03-31 16:16:24,551] [ INFO] - -----------------------------
[2023-03-31 16:16:24,551] [ INFO] - Class Name: all_classes
[2023-03-31 16:16:24,551] [ INFO] - Evaluation Precision: 0.95918 | Recall: 0.87037 | F1: 0.91262
!python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/dev.txt \
--debug
[2023-03-31 16:16:29,246] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'.
W0331 16:16:29.278601 1707 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0331 16:16:29.281224 1707 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2023-03-31 16:16:34,944] [ INFO] - -----------------------------
[2023-03-31 16:16:34,944] [ INFO] - Class Name: 时间
[2023-03-31 16:16:34,944] [ INFO] - Evaluation Precision: 1.00000 | Recall: 0.90000 | F1: 0.94737
[2023-03-31 16:16:34,998] [ INFO] - -----------------------------
[2023-03-31 16:16:34,998] [ INFO] - Class Name: 地名
[2023-03-31 16:16:34,998] [ INFO] - Evaluation Precision: 0.95833 | Recall: 0.85185 | F1: 0.90196
[2023-03-31 16:16:35,022] [ INFO] - -----------------------------
[2023-03-31 16:16:35,022] [ INFO] - Class Name: 产品
[2023-03-31 16:16:35,022] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2023-03-31 16:16:35,048] [ INFO] - -----------------------------
[2023-03-31 16:16:35,048] [ INFO] - Class Name: 组织
[2023-03-31 16:16:35,049] [ INFO] - Evaluation Precision: 1.00000 | Recall: 0.50000 | F1: 0.66667
[2023-03-31 16:16:35,071] [ INFO] - -----------------------------
[2023-03-31 16:16:35,071] [ INFO] - Class Name: 人名
[2023-03-31 16:16:35,071] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2023-03-31 16:16:35,092] [ INFO] - -----------------------------
[2023-03-31 16:16:35,092] [ INFO] - Class Name: 天气
[2023-03-31 16:16:35,092] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2023-03-31 16:16:35,109] [ INFO] - -----------------------------
[2023-03-31 16:16:35,109] [ INFO] - Class Name: 价格
[2023-03-31 16:16:35,109] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
3.3 微调后效果
my_ie = Taskflow("information_extraction", schema=schema, task_path='./checkpoint/model_best') # task_path 指定模型权重文件的路径
pprint(my_ie("2K 与 Gearbox Software 宣布,《小缇娜的奇幻之地》将于 6 月 24 日凌晨 1 点登录 Steam,此前 PC 平台为 Epic 限时独占。在限定期间内,Steam 玩家可以在 Steam 入手《小缇娜的奇幻之地》,并在 2022 年 7 月 8 日前享有获得黄金英雄铠甲包。"))
[2023-03-31 16:16:39,383] [ INFO] - Converting to the inference model cost a little time.
[2023-03-31 16:16:46,661] [ INFO] - The inference model save in the path:./checkpoint/model_best/static/inference
[2023-03-31 16:16:48,783] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'.
[{'产品': [{'end': 118,
'probability': 0.9860396834664122,
'start': 108,
'text': '《小缇娜的奇幻之地》'},
{'end': 35,
'probability': 0.9870830377819004,
'start': 25,
'text': '《小缇娜的奇幻之地》'},
{'end': 148,
'probability': 0.9075236400717301,
'start': 141,
'text': '黄金英雄铠甲包'}],
'时间': [{'end': 52,
'probability': 0.9998017644462607,
'start': 38,
'text': '6 月 24 日凌晨 1 点'},
{'end': 137,
'probability': 0.9875673117430104,
'start': 122,
'text': '2022 年 7 月 8 日前'}],
'组织': [{'end': 2,
'probability': 0.9888051241547942,
'start': 0,
'text': '2K'},
{'end': 93,
'probability': 0.9503029387182096,
'start': 88,
'text': 'Steam'},
{'end': 75,
'probability': 0.9819544449787045,
'start': 71,
'text': 'Epic'},
{'end': 105,
'probability': 0.7914398215948992,
'start': 100,
'text': 'Steam'},
{'end': 60,
'probability': 0.982935890915897,
'start': 55,
'text': 'Steam'},
{'end': 21,
'probability': 0.9994608274841141,
'start': 5,
'text': 'Gearbox Software'}]}]
pprint(my_ie("近日,量子计算专家、ACM计算奖得主Scott Aaronson通过博客宣布,将于本周离开得克萨斯大学奥斯汀分校(UT Austin)一年,并加盟人工智能研究公司OpenAI。"))
[{'人名': [{'end': 32,
'probability': 0.9990193078443497,
'start': 18,
'text': 'Scott Aaronson'}],
'时间': [{'end': 2,
'probability': 0.9998481327061199,
'start': 0,
'text': '近日'},
{'end': 43,
'probability': 0.9995744486620453,
'start': 41,
'text': '本周'}],
'组织': [{'end': 66,
'probability': 0.9900117066000078,
'start': 57,
'text': 'UT Austin'},
{'end': 87,
'probability': 0.9993381402363184,
'start': 81,
'text': 'OpenAI'},
{'end': 56,
'probability': 0.9968616126324434,
'start': 45,
'text': '得克萨斯大学奥斯汀分校'},
{'end': 13,
'probability': 0.8434502340745098,
'start': 10,
'text': 'ACM'}]}]
基于 50 条标注数据进行模型微调后,效果有所提升。
4.智能标注:Machine Learning Backend 编写教学
在基于UIE的命名实体识别的基础上,进一步通过集成 Label Studio 的 Machine Learning Backend 实现交互式预注释和模型训练等功能。
环境安装:
pip install label_studio_ml
pip uninstall attr
完整的 Machine Learning Backend 见 my_ml_backend.py 文件。更多有关自定义机器学习后端编写的内容可参考 Write your own ML backend。
简单来讲,my_ml_backend.py 内主要包含一个继承自 LabelStudioMLBase 的类,其内容可以分为以下三个主要部分:
- init 方法,包含模型的加载和基本配置的初始化
- predict 方法,用于为标注数据生成新的预测结果,其关键参数 tasks 就是 label studio 传递的原始数据
- fit 方法,用于模型的训练,当点击页面上的 Train 按钮时,会调用此方法(具体的位置在下文会提到),其关键参数 annotations 就是 label studio 传递的已经标注了的数据
4.1 init 初始化方法
- 导入依赖库
import numpy as np
import os
import json
from paddlenlp import Taskflow
from label_studio_ml.model import LabelStudioMLBase
- 声明并初始化一个类
首先创建一个类声明,通过继承 LabelStudioMLBase 创建一个与 Label Studio 兼容的 ML 后端服务器。
class MyModel(LabelStudioMLBase):
然后,在 __init__ 方法中定义和初始化需要的变量。LabelStudioMLBase 类提供了以下
- self.label_config: 原始标签配置。
- self.parsed_label_config: 为项目提供结构化的 Label Studio 标签配置。
- self.train_output: 包含之前模型训练运行的结果,与训练调用部分中定义的
fit()方法的输出相同。
如本教程的例子中,标签配置为:
<View>
<Labels name="label" toName="text">
<Label value="地名" background="#FFA39E"/>
<Label value="人名" background="#D4380D"/>
<Label value="组织" background="#FFC069"/>
<Label value="时间" background="#AD8B00"/>
<Label value="产品" background="#D3F261"/>
<Label value="价格" background="#389E0D"/>
<Label value="天气" background="#5CDBD3"/>
</Labels>
<Text name="text" value="$text"/>
</View>
相对应的 parsed_label_config 如下所示:
{
'label': {
'type': 'Labels',
'to_name': ['text'],
'inputs': [{
'type': 'Text',
'value': 'text'
}],
'labels': ['地名', '人名', '组织', '时间', '产品', '价格', '天气'],
'labels_attrs': {
'地名': {
'value': '地名',
'background': '#FFA39E'
},
'人名': {
'value': '人名',
'background': '#D4380D'
},
'组织': {
'value': '组织',
'background': '#FFC069'
},
'时间': {
'value': '时间',
'background': '#AD8B00'
},
'产品': {
'value': '产品',
'background': '#D3F261'
},
'价格': {
'value': '价格',
'background': '#389E0D'
},
'天气': {
'value': '天气',
'background': '#5CDBD3'
}
}
}
}
根据需要从 self.parsed_label_config 变量中提取需要的信息,并通过 PaddleNLP 的 Taskflow 加载用于预标注的模型。
def __init__(self, **kwargs):
# don't forget to initialize base class...
super(MyModel, self).__init__(**kwargs)
# print("parsed_label_config:", self.parsed_label_config)
self.from_name, self.info = list(self.parsed_label_config.items())[0]
assert self.info['type'] == 'Labels'
assert self.info['inputs'][0]['type'] == 'Text'
self.to_name = self.info['to_name'][0]
self.value = self.info['inputs'][0]['value']
self.labels = list(self.info['labels'])
self.model = Taskflow("information_extraction", schema=self.labels, task_path= './checkpoint/model_best')
4.2 使用ML Backend predict 预测方法(自动标注)
编写代码覆盖 predict(tasks, **kwargs) 方法。predict() 方法接受 [JSON 格式的 Label Studio 任务]返回预测。此外,还可以包含和自定义可用于主动学习循环的预测分数。
tasks 参数包含了有关要进行预注释的任务的详细信息。具体的 task 格式如下所示:
{
'id': 16,
'data': {
'text': '新华社都柏林6月28日电(记者张琪)第二届“汉语桥”世界小学生中文秀爱尔兰赛区比赛结果日前揭晓,来自都柏林市的小学五年级学生埃拉·戈尔曼获得一等奖。'
},
'meta': {},
'created_at': '2022-07-12T07:05:06.793411Z',
'updated_at': '2022-07-12T07:05:06.793424Z',
'is_labeled': False,
'overlap': 1,
'inner_id': 6,
'total_annotations': 0,
'cancelled_annotations': 0,
'total_predictions': 0,
'project': 2,
'updated_by': None,
'file_upload': 2,
'annotations': [],
'predictions': []
}
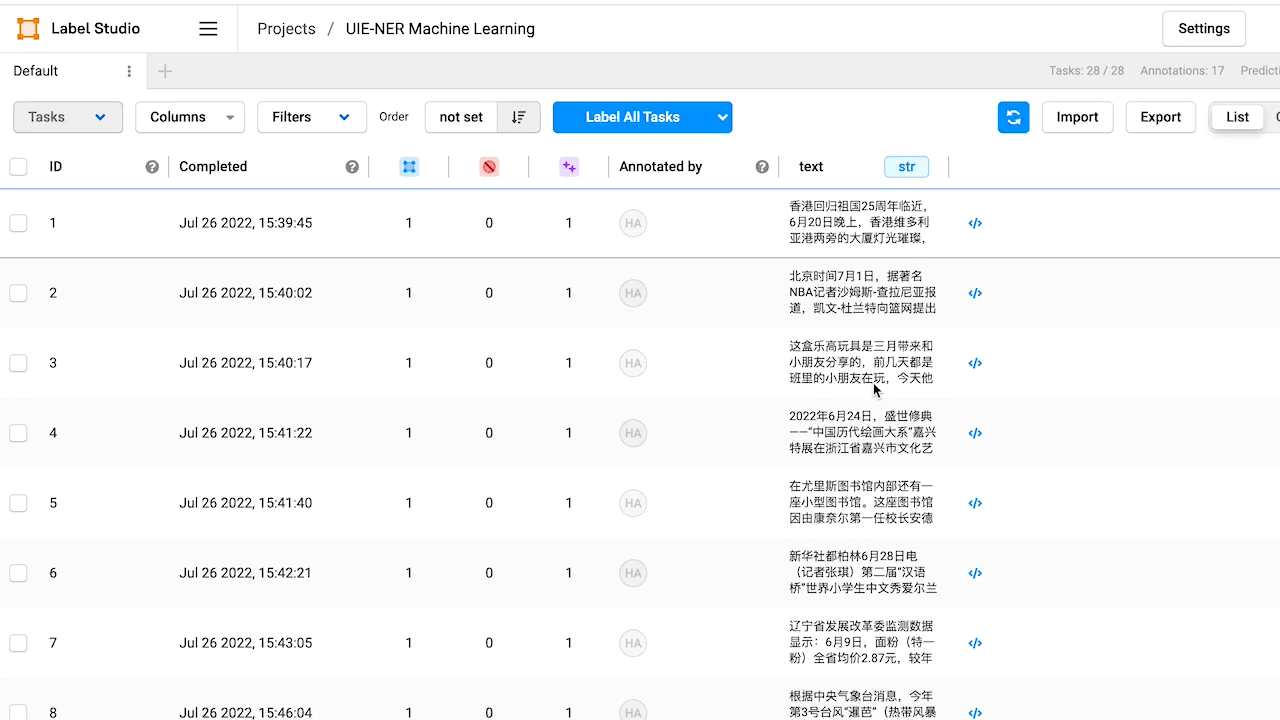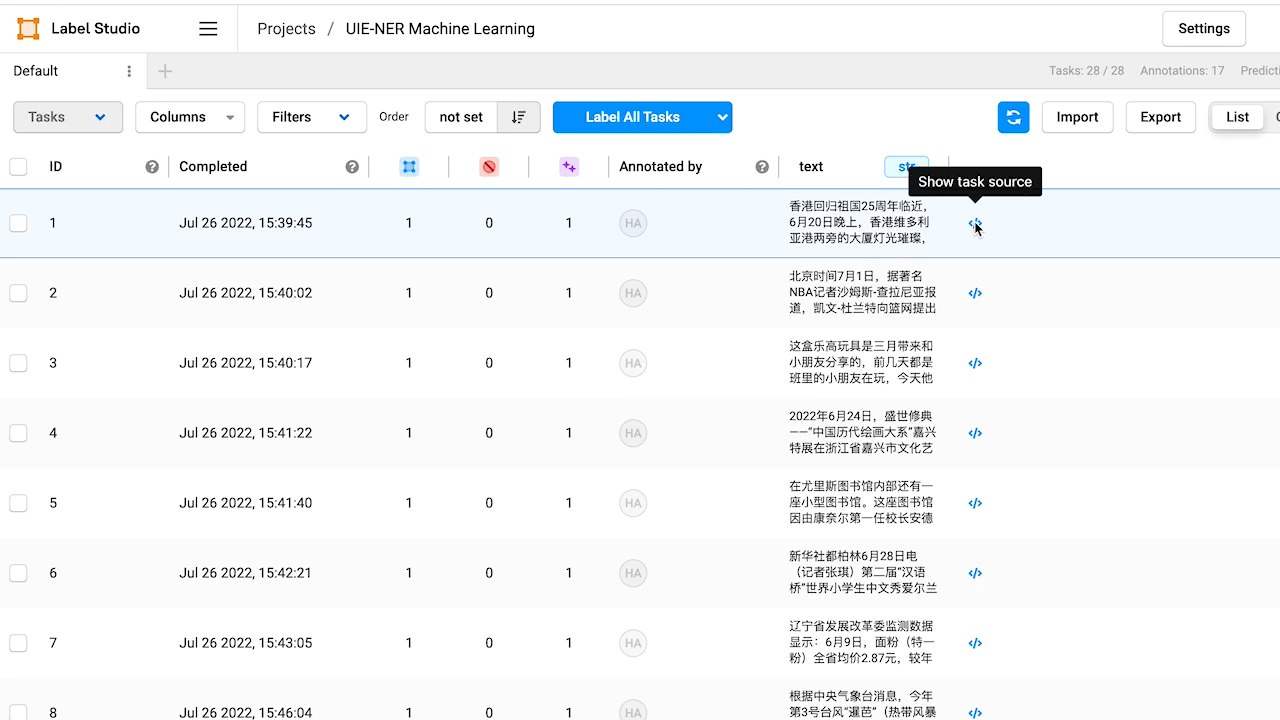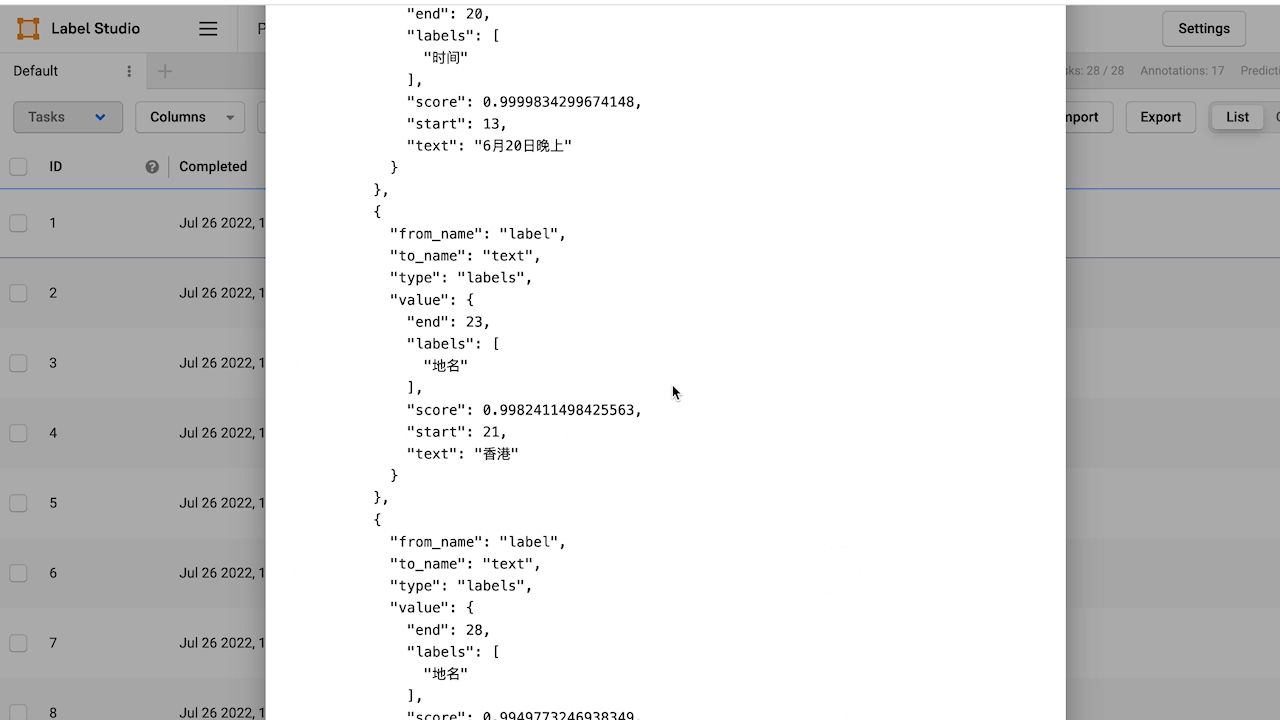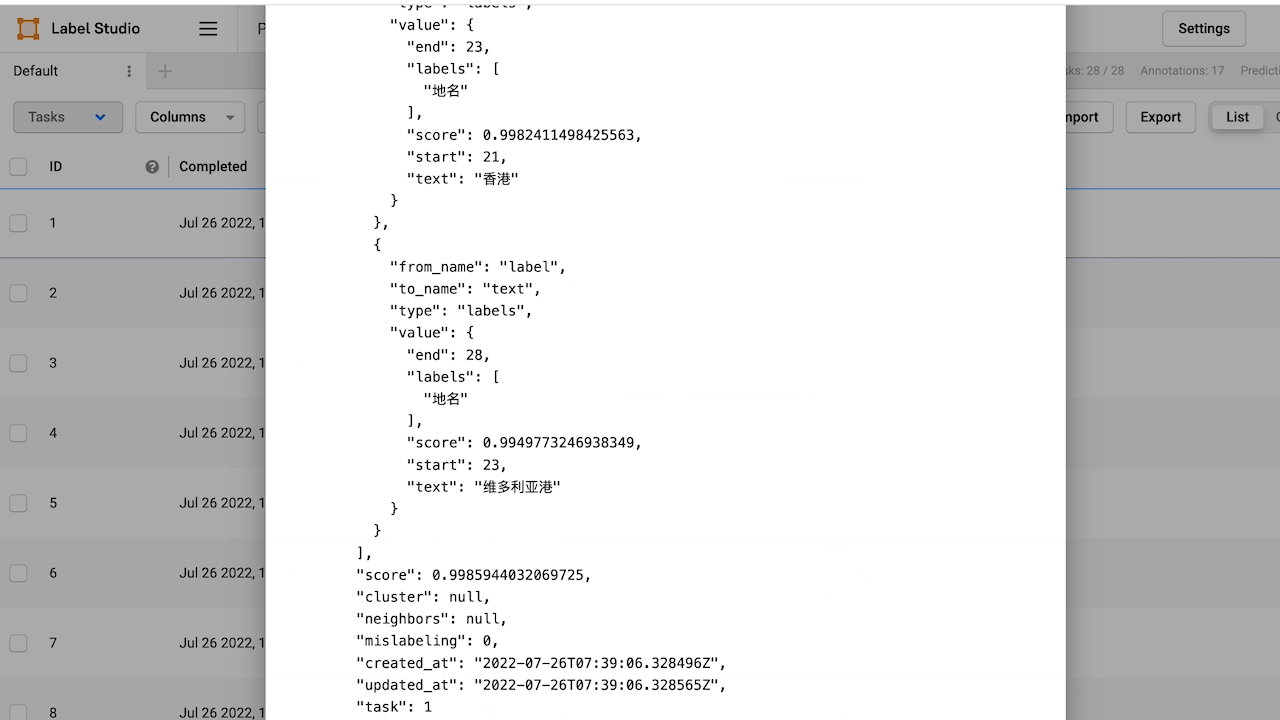
通过 Taskflow 进行预测需要从 ['data']['text'] 字段提取出原始文本,返回的 uie 预测结果格式如下所示:
{
'地名': [{
'text': '爱尔兰',
'start': 34,
'end': 37,
'probability': 0.9999107139090313
}, {
'text': '都柏林市',
'start': 50,
'end': 54,
'probability': 0.9997840536235998
}, {
'text': '都柏林',
'start': 3,
'end': 6,
'probability': 0.9999684097596173
}],
'人名': [{
'text': '埃拉·戈尔曼',
'start': 62,
'end': 68,
'probability': 0.9999879598978225
}, {
'text': '张琪',
'start': 15,
'end': 17,
'probability': 0.9999905824882092
}],
'组织': [{
'text': '新华社',
'start': 0,
'end': 3,
'probability': 0.999975681447097
}],
'时间': [{
'text': '6月28日',
'start': 6,
'end': 11,
'probability': 0.9997071721989244
}, {
'text': '日前',
'start': 43,
'end': 45,
'probability': 0.9999804497706464
}]
}
从 uie 预测结果中提取相应的字段,构成 Label Studio 接受的预注释格式。命名实体识别任务的具体预注释示例可参考 [Import span pre-annotations for text]
更多其他类型任务的具体预注释示例可参考 [Specific examples for pre-annotations]
def predict(self, tasks, **kwargs):
from_name = self.from_name
to_name = self.to_name
model = self.model
predictions = []
for task in tasks:
# print("predict task:", task)
text = task['data'][self.value]
uie = model(text)[0]
# print("uie:", uie)
result = []
scores = []
for key in uie:
for item in uie[key]:
result.append({
'from_name': from_name,
'to_name': to_name,
'type': 'labels',
'value': {
'start': item['start'],
'end': item['end'],
'score': item['probability'],
'text': item['text'],
'labels': [key]
}
})
scores.append(item['probability'])
result = sorted(result, key=lambda k: k["value"]["start"])
mean_score = np.mean(scores) if len(scores) > 0 else 0
predictions.append({
'result': result,
# optionally you can include prediction scores that you can use to sort the tasks and do active learning
'score': float(mean_score),
'model_version': 'uie-ner'
})
return predictions
4.3 使用 ML Backend fit 训练方法(根据标注好的数据再次优化训练模型)
基于新注释更新模型。
编写代码覆盖 fit() 方法。fit() 方法接受 [JSON 格式的 Label Studio 注释]并返回任意一个可以存储模型相关信息的 JSON 字典。
def fit(self, annotations, workdir=None, **kwargs):
""" This is where training happens: train your model given list of annotations,
then returns dict with created links and resources
"""
# print("annotations:", annotations)
dataset = convert(annotations)
with open("./doccano_ext.jsonl", "w", encoding="utf-8") as outfile:
for item in dataset:
outline = json.dumps(item, ensure_ascii=False)
outfile.write(outline + "\n")
os.system('python doccano.py \
--doccano_file ./doccano_ext.jsonl \
--task_type "ext" \
--save_dir ./data \
--splits 0.8 0.2 0')
os.system('python finetune.py \
--train_path "./data/train.txt" \
--dev_path "./data/dev.txt" \
--save_dir "./checkpoint" \
--learning_rate 1e-5 \
--batch_size 4 \
--max_seq_len 512 \
--num_epochs 50 \
--model "uie-base" \
--init_from_ckpt "./checkpoint/model_best/model_state.pdparams" \
--seed 1000 \
--logging_steps 10 \
--valid_steps 100 \
--device "gpu"')
return {
'path': workdir
}
6.总结
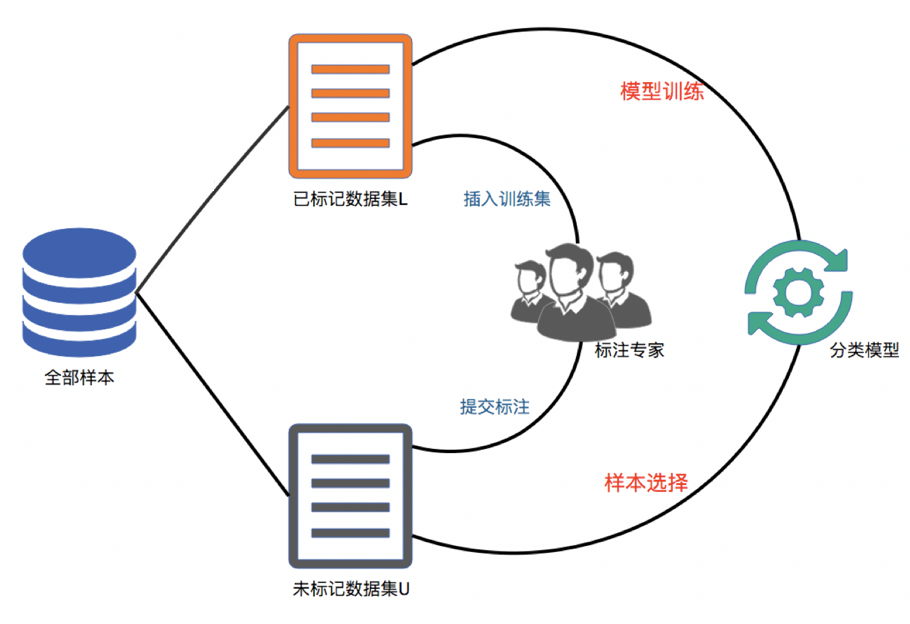
人工标注的缺点主要有以下几点:
- 产能低:人工标注需要大量的人力物力投入,且标注速度慢,产能低,无法满足大规模标注的需求。
- 受限条件多:人工标注受到人力、物力、时间等条件的限制,无法适应所有的标注场景,尤其是一些复杂的标注任务。
- 易受主观因素影响:人工标注受到人为因素的影响,如标注人员的专业素养、标注态度、主观判断等,易受到人为误差的干扰,导致标注结果不准确。
- 难以满足个性化需求:人工标注无法满足所有标注场景和个性化需求,无法精确地标注出所有的关键信息,需要使用者自行选择和判断。
相比之下,智能标注的优势主要包括:
- 效率更高:智能标注可以自动化地进行标注,能够快速地生成标注结果,减少了人工标注所需的时间和精力,提高了标注效率。
- 精度更高:智能标注采用了先进的人工智能技术,能够对图像进行深度学习和处理,能够生成更加准确和精细的标注结果,特别是对于一些细节和特征的标注,手动标注往往存在误差较大的问题。
- 自动纠错:智能标注可以自动检测标注结果中的错误,并进行自动修正,能够有效地避免标注错误带来的影响,提高了标注的准确性。
- 灵活性更强:智能标注可以根据不同的应用场景和需求,生成不同类型的标注结果,能够满足用户的多样化需求,提高了标注的适用性。
总之,智能标注相对于人工标注有着更高的效率、更高的精度、更强的灵活性和更好的适用性,可以更好地满足用户的需求。
6.1 码源
智能标注:基于Labelstudio的UIE半监督深度学习的智能标注方案码源
更多细节参考:人工智能知识图谱之信息抽取:基于Labelstudio的UIE半监督深度学习的智能标注方案(云端版),提效。

- 点赞
- 收藏
- 关注作者
评论(0)