【云驻共创】DTSE Tech Talk 技术直播 NO.18:统计信息大揭秘,SQL执行优化之密钥

SQL 执行的指导思想是什么? SQL 执行计划的正确依赖选择依赖于什么?统计信息为什么在 SQL 执行中起到关键性的作用?如何才能自动化收集统计信息?让 一起了解 SQL 执行优化的核心底座。
统计信息在数据库当中是很重要的一个东西,华为云高斯GaussDB在这方面做持续的耕耘和持续的一个改进,在统计一些方面做了新的尝试和想法,已经在内部客户当中去推广和试用。今天主要分享一些基本功能和玩法
这次分享主要包含三部分内容,第一部分先介绍统计信息相关的一些知识,统计器到底是什么,统计器是如何被使用,如何被生成的,如何被使用的。
第二部分介绍统计信息究竟是如何收集的,如何做到自动收集。
第三部分是在使用这个统计信息收集的时候遇到的一些常见的问题。
1. 统计信息简单介绍
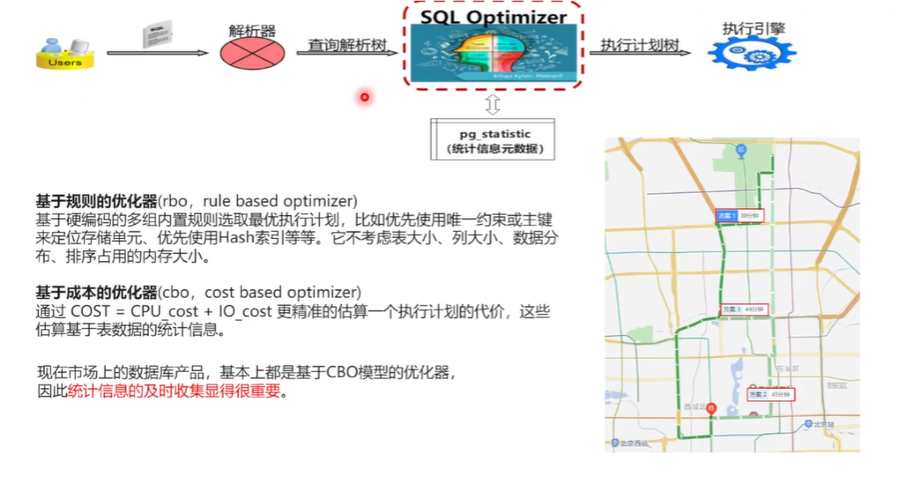
SQL 语句的执行,它这个整个过程当中都发生了什么?第一步就是 的用户业务在发送一个 SQL 语句到数据库,它首先是要经过解析器,通过词法分析,语法分析生成一个语法树,拿到了语法树以后,把它交给这个 SQL 的优化器,根据语法树看你要是做要查询哪些表, 要想得要得到什么样的结果。 开始做这个内部的各种执行路径的一些计算,从当中选择一条最优的一个执行路径,生成一个执行计划,把这个执行计划交给这个执行引擎来生成一个查询结果。这个过程就很像 在这个出行打车当中去选择这个出行路径一样。
优化器以前是有一种叫基于规则的优化器,它就类似于以前在没有智能手机之前,拿着纸质地图去出行一样,只有具体的一些规则,就是从哪到哪,哪个路径最短,就只能就是这样去选择。它没有路况信息,也不知道哪个路发生了拥堵,哪个路是不是有这个事故发生, 这个选择就是只是基于一些最简单的规则,就是一个试试看有没有唯一索引,有没有这个主键, 优先选择这个索引来看。但是它由于没有收集这个统计信息, 它没有办法考虑大表大小,现在的优化器都是基于成本的优化器就类似于现在这个地图 APP 进行打车一样,它是根据实时路况以及司机的些数据, 就知道了这个路是不是哪些路段有拥堵发生,哪些路段有事故发生,从而 得到了一体,从而就会得到一个最优的一个执行路径。相对于优在优化期里面也是很差不多的一个东西。
优化器先进行这个列上的这个统计信息收集,知道了这个表大小,知道了列宽,知道了这些数据以后, 开始进行每条执行路径的成本的一个估算。数据库里面首先就是估算成本分两方面,一个是 CPU 的一个代价的估算,一个是 IO 代价的一个估算。基于这个统计信息进行每一条路径的一个代价计算,从而选择一个最终最优的。 现在的税务产品基本上全都是基于成本的优化器,这个优化器模型统计信息的收集也显得很重要,就像打车一样,如果没有这个实时路况信息,那出行就会造成很大的一个麻烦。

接下来看一下统计信息在思维语句当中的一个这个层次关系,因为 进行数据库操作都使用SQL 语言,它也是一个结构化查询语言,它是一个高度的,并且是非过程化的一个编程语言。用户是在这个高层次进行数据结构上的一个操作,用户只需要关心我需要干什么就行了,不需要关心具体你怎么干。 像这个路径的一些选取代价的一个估算,具体做什么样的操作,如何去排序,如何去进行数据扫描,这些完全都是由数据库内部自动完成的。既然是由于数据库内部自动完成了,因为 有很多不同的路径去选择,不同的操作方式去选择,那如何选择一个最优的?就是一个问题。
它分三个层面,第一个层面就是先进行一些统计信息的一个收集,它是基于这个随机采样的随机采集一些部分数据来生成这个统计信息。有了这个统计信息以后, 根据 SQL 语句里面要查询哪些表要做关联, 在这些算子上进行代价的一个估算,每条路径都这样去算代价,算完以后生成代价最小执行计划,作为最终的这个计划去执行。 统计信息是生成所最优执行计划的一个前提。
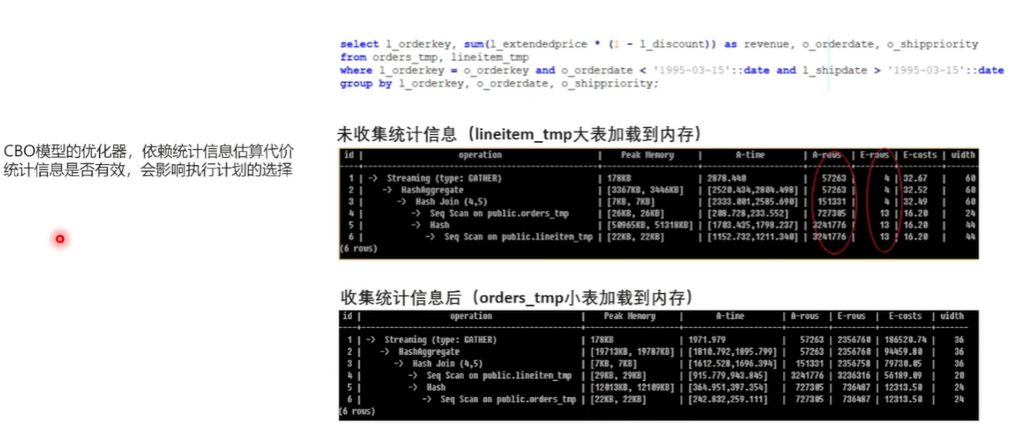
先举一个例子, 这是一个是TBC的一个查询语句, 它做两个表的关联,一个是 order 表,一个是 line item 表的一个关联。在没有收集统计信息的一个情况下,这个是生成的一个计划,首先就是这个是对两个表进行扫描,这个 Lion item 表是是在下面,它是先把这个 Line item 表,它实际上是一个比较大的一个表,占的条数要比这个 order 表要大很多。这个没有收统计信息的时候,这个它把这个大表放到了加载到了这个内存, 执行耗时是 2878 毫秒。
收集完统计信息之后,再看这个执行计划,order 表就在最下面了,把它加载到内存,就把这个小表加载到了这个内存,执行时间是 1971 毫秒, 有了统计信息之后, 正确地把小表这个加载到了内存,得到了一个更优的一个执行性能。 在基于代价估算的这优化启模型当中,统计信息会直接影响到这个执行计划的一个选择。
 知道了统计信息对于优化器很重要,那么统计信息它是如何被优化器使用的?
知道了统计信息对于优化器很重要,那么统计信息它是如何被优化器使用的?
先看一下统计信息都包含哪些东西。统计信息分两个层面,一个是表级的统计信息,一个是列级的一个统计信息。表级是描述表的一些大小,具体的有real pages 就是表在磁盘当中占用的这个物理的页面数,还有就是 real tuples 就是表的实际的数据条数。这样就知道表的一个规模。列级统计信息它包含很多值,比较典型的就是这 4 个值。第一个就是叫distinct,就是唯一值的个数,就是把这一列进行去重以后,最终剩的剩下的唯一值的一个个数有多少个。还有就是空值的一个占比。
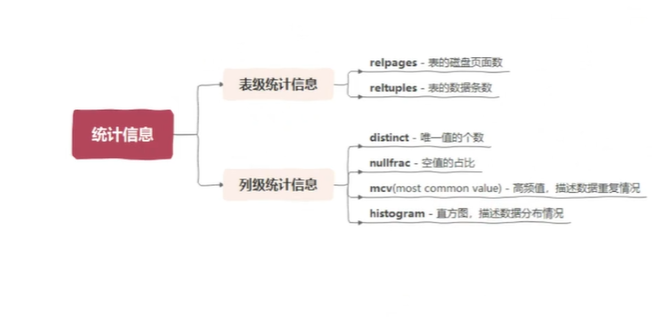 最重要的是下面的两个,一个叫MCV,就是 most 的 common value,就是 把它叫做高频值,就是主要是它描述这个数据的一个重复情况。简单说就是要看一下这个列当中重复最多的数都有哪些。还有一个就是直方图,直方图用于来描述数据的一个分布情况,生成方式就进行数据采集以后,按一定的步长去打点,抽出一些按步长去抽出一些数据来。有了这些基本的统计信息以后,优化器就是拿一些这些信息来进行这个 SQL 代价的一个估算。
最重要的是下面的两个,一个叫MCV,就是 most 的 common value,就是 把它叫做高频值,就是主要是它描述这个数据的一个重复情况。简单说就是要看一下这个列当中重复最多的数都有哪些。还有一个就是直方图,直方图用于来描述数据的一个分布情况,生成方式就进行数据采集以后,按一定的步长去打点,抽出一些按步长去抽出一些数据来。有了这些基本的统计信息以后,优化器就是拿一些这些信息来进行这个 SQL 代价的一个估算。
接下来 看一下优化器到底是如何去使用这些东西的。
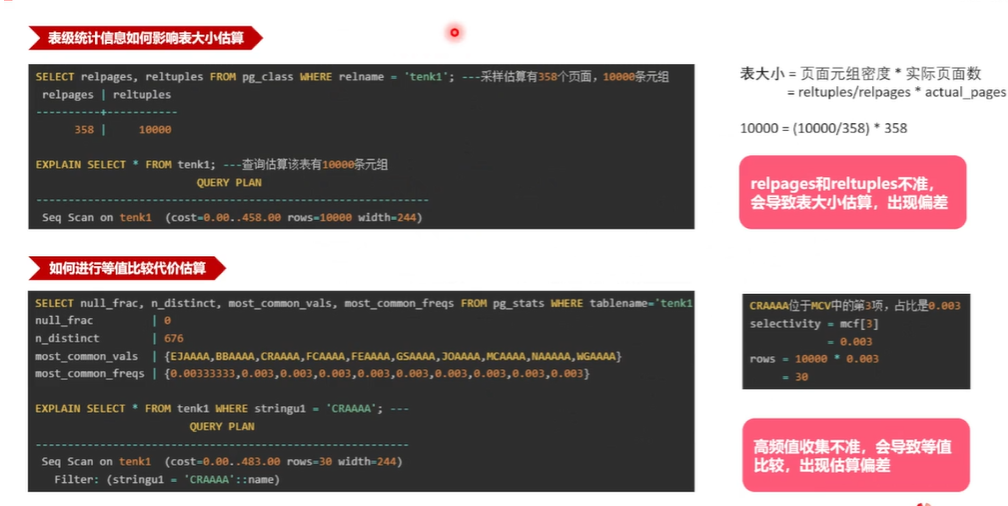
第一个要看表集的统计信息是如何影响表大小估算的,刚才已经看了表集的统计信息,描述了这个表的数据规模,其实主要有这个页面数和条数这两个。比如说做一个查询叫 select sharing from 这个表,看一下它的查询计划, sequence scan 进行一些数据扫描,它估算出来的条数也是1万,和这个1万是相等的,但它实际是怎么计算的?就是它是在统计机器生成的时候,用这个条数乘以这个除以这个物理的页面数,把它就叫做页面的元组密度,就是平均每个页面大概有多少条数据。
为什么要乘以实际的页面数?就是因为生成统计信息以后,这个数据可能还会再变,这个表的页面可能还在增加,那么进行代价估算的时候,是基于前一步生成的这个统计信息, 就是拿前一步是这个元组密度乘以实际的页面数来估算出当前的一个大概的表大小,就是通过这样计算刚好也得到了是这个1万条。 如果这个原组页面密度估算得不准,那么它就会影响到这 表大小的一个估算会出现一个偏差。
接下来 看进行如何进行等值比较的一个估算。
等值比较就是用这个 SQL 语句,从这个表去查询这个 string 1的这个值,等于这个 CRA这个值,看它有这个多少条。打出来这个计划,也是因为这上面没有索引,先走的是顺序扫描,估算出来这个值是有 30 条,那么这个 30 怎么来的?就是基于上面的这个统计信息,这个是 查询出来的这个 MCV 也叫高频值的一个统计信息,它包含两方面的一个内容,第一方面就是这个 most common value 就是具体的值。
 第二组就是每一个值的出现的一个频率, 每个值有出现的品类不一样,那再查这个 c r a ,进行等值比较,其实找到 c r a 在这个 个位置,它出现的这个频率是 0. 003, 后面进行估算的时,首先找到这个 MCF 是 3 的位置是 0. 003,拿它再去乘以上一步估算的这个表的这个大小,乘以1万。
第二组就是每一个值的出现的一个频率, 每个值有出现的品类不一样,那再查这个 c r a ,进行等值比较,其实找到 c r a 在这个 个位置,它出现的这个频率是 0. 003, 后面进行估算的时,首先找到这个 MCF 是 3 的位置是 0. 003,拿它再去乘以上一步估算的这个表的这个大小,乘以1万。
最终得到这个30,就估算出这个数据,在这个表中大概有 30 条,也很简单,就是它是完全是基于这个统计信息的一一个状态来估算的这个表大小,如果这个高频值收集得不准的话,那就会直接导致条数估算的一个偏差。
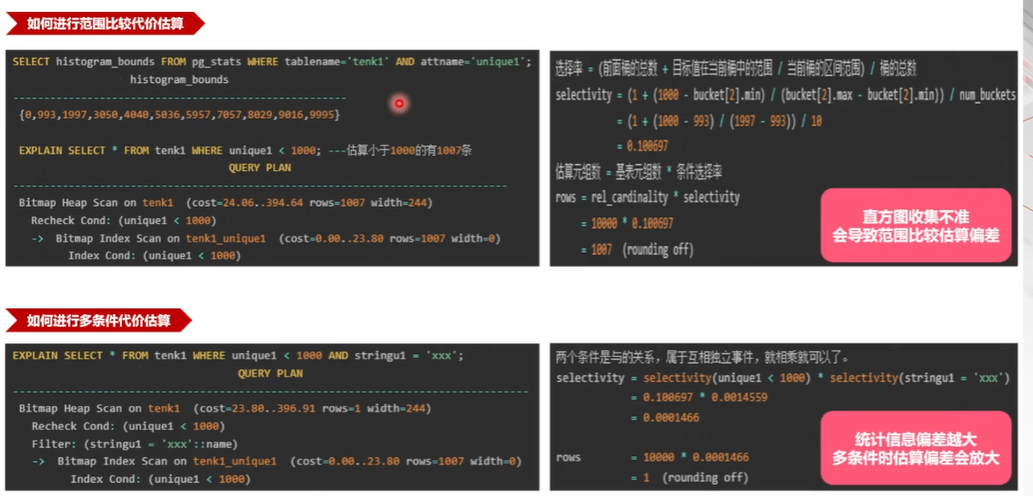
接下来看一下范围比较,有了表大小, 有了等值比较,来看一下范围比较,它就用到了刚才说的另外一个统计信息,叫直方图。直方图也很简单,它跟 MCV 不一样, MCV 是有值和这个频率,直方图就直接是具体的值了。它的生成方式就是在样本里面, 把机型从小到大排个序, 按一定的步长去打点采集,生成的最终结果就是大概是这个样子,可以看到它的这个数据分布是从 0 到9995,大概是这样, 中间按相同的步长, 有这些值。
当 进行一个范围比较的时候,比如说 查这个表的,这叫 unique e 列,让它小于1000,看它有多少条计算方法,就看这个 1000 在这个哪,在大概是在哪个位置这里第一个是0,第二个是993,第三个是1997, 1000 就落在了 993 和 1997 之间。
那么有了它了,看如何去算小于 1000 的值大概是有多少的一个比例?实际估算的结果是小于 1000 的值们估算出来是有 1007 条,实际估算的时候,这个算法就是在这边也很简单,就是先就是说看这个值在前,在最前面,比如说 0- 993,这是第一个,叫这个桶占了 0- 993,这是完整的一个桶。 在目标值在当前桶中的范围,比如说 993 到 1997 之间,那么小于 1000 的大概占了多大的一个范围? 把这两个进行相加以后,除以一个桶的总数。具体的算法就是因为 0- 993 占了完整的一个桶,就记为一, 用 1000 减去第二个桶的最小值,也就是993, 再除以第二个桶的这个范围,就是 1997 去减去993,也就是说小于 1000 在第二个桶当中它的占的一个比例, 跟前面桶的个数相加,再除以总的桶的个数。
接下来看一下join,就是多表进行关联的时候,又是如何进行这个单价结算的。
现在有两张表,一个是 T1 表,一个 T2 表, 条件 t 表小于等于50, 1 和 2 进行关联,T2 表扫描出来,进行这个进行小于 50 的这个单元,估算出来这个数据条数也是50, 进行关联关联这个 T2 表进行按这个等值关联,它估算出了一条最终 join 出来的结果也是 50 条。这样的话其实要考虑,有两个表,两边的统计信息都要进行一个这个考虑。右边查出来的是这个 T1 表和 T2 表这个控制比例统计信息,进行代价估算的时候,方法就是首先两边的这个数据条数进行一个笛卡尔积的一个相乘, 再乘以这个整体的选择率,也是进行一个组合的一个计算。首先是左边一张表的这个非控制的一个条数,乘以右边表的一个非控制的一个条数,最终乘以这个 根据 detail 值估算的一个选择率,最终得到了这个 50 条。
 这个统计信息重要性 主要 3 这个三个页面来介绍, 得到了就是,这个统计期的调,这个非常重要,统计期也是 SQL 调优的一个前提。好,接下来 看一下这个统计息,究竟是 用了很大的篇幅来铺垫一下这个统计信息的本身的一些东西,主要是为了让大家知道 的一用户在真正使用过程当中, 为什么非要收集统计信息啊?这个统计信息跟业务又不是很相关,花这个好大代价去做这个事情,主要是给大家解释一下这个事情。
这个统计信息重要性 主要 3 这个三个页面来介绍, 得到了就是,这个统计期的调,这个非常重要,统计期也是 SQL 调优的一个前提。好,接下来 看一下这个统计息,究竟是 用了很大的篇幅来铺垫一下这个统计信息的本身的一些东西,主要是为了让大家知道 的一用户在真正使用过程当中, 为什么非要收集统计信息啊?这个统计信息跟业务又不是很相关,花这个好大代价去做这个事情,主要是给大家解释一下这个事情。
好,
2. 统计信息如何收集
接下来看一下统计在这个产品里面是如何进行这个收集的。
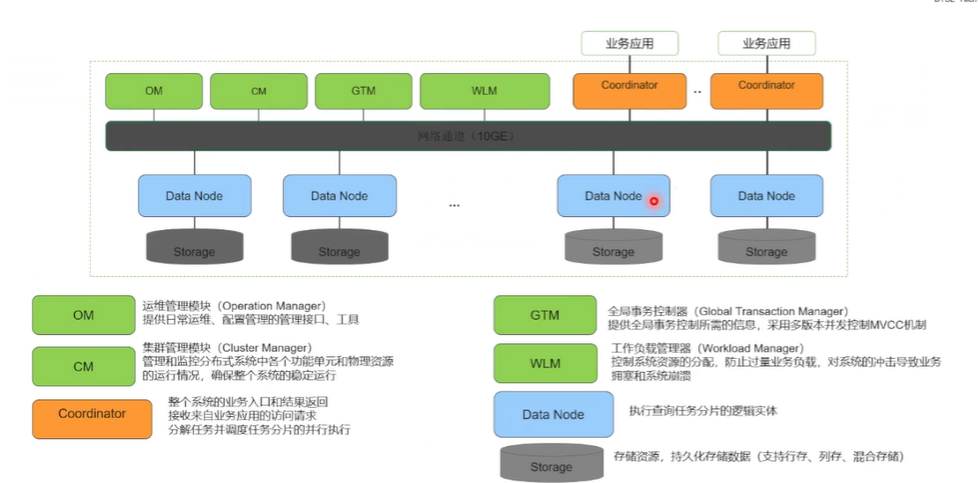
首先 拿一个页面来介绍一下 产品的一个架构, 绿色的节点就是 一些这个管理节点, 不去重点介绍,它主要是 两部分,一个是黄色的节点和这个浅蓝色的一个节点,黄色的节点是 接收 SQL 语句的这个节点, 接受到思科语句, 进行词法分析、语法分析, 生成一个最优的计划,把计划下发到各个这个数据节点。 数据集数据节点真正地去执行,结果返回到这个计算节点,最终再返回给应用的这个业务。
这是如果是复杂的一个场景,复杂 SQL 是这样计算的,如果是一个简单的SQL,比如说这个 SQL 已经确定到,确定根据这个统计信息确定数据落在某一个 DN 上,就可以把这个 SQL 语句直接发到具体的DN,由它进行这个词法分析, 生成最优的计划, 生成结果最终返回。
 统计一分两个层面,第一个层面就是每个数据节点要计算自己的一个统计信息, 每个计算节点要计算一个全技术的统计信息。那么 的 airlines 做样本采集的时候,也就当然也就分了两个阶段。第一个阶段就是 DN 进行这个样本采集,生成自己本地的一个统计信息, 把这些样本发送给 的支线节点,由 来计算全局的一个统计信息。
统计一分两个层面,第一个层面就是每个数据节点要计算自己的一个统计信息, 每个计算节点要计算一个全技术的统计信息。那么 的 airlines 做样本采集的时候,也就当然也就分了两个阶段。第一个阶段就是 DN 进行这个样本采集,生成自己本地的一个统计信息, 把这些样本发送给 的支线节点,由 来计算全局的一个统计信息。
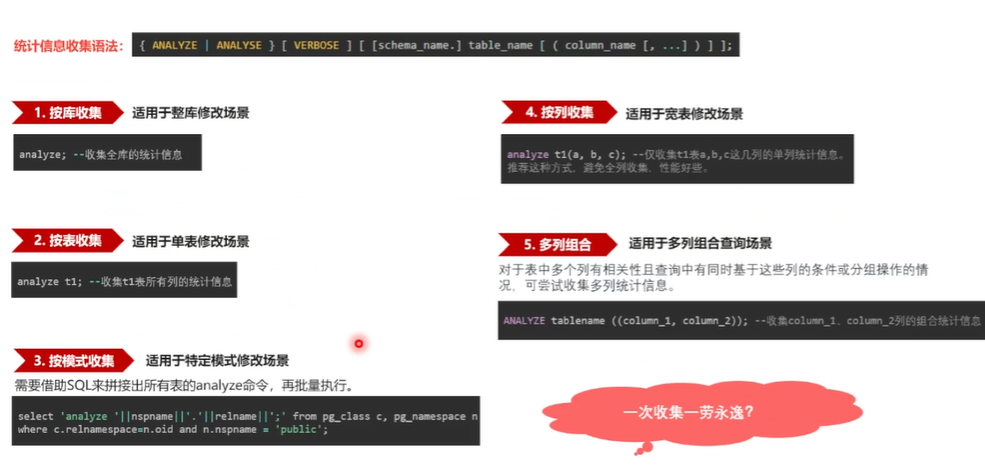
先介绍一下基本的 统计些如是如何收集的。 有这几种方式。第一种方法,第一种方式是按库来收集,它适用于这个整库迁移的这个修改场景,就把所有的表, 整个去收集一遍统计信息,当然这个肯定是耗时最长的。第二就是按表来收集,一张表的来收集这个统计信息。第三种就是按模式来收紧,因为 这个模式是一个逻辑概念, 需要把这个所有表这个模式下面的所有表查出来, 整体地去做这个统计新的一个收集。第四种 可以案例来收集,比如说是一个特别宽的一个表, 并不是所有列都需要进行查询,所有列都要用到, 只需要对个别的列进行收集统计信息就可以了,这样可以提升这个 align 的一个性能。最后就是 一个组合信组合的统计信息一个收集,比如说要进行多列的一起进行查询,一起进行关联,或者说整体多个列进行 out by,这个时候如果通过单列的统计信息估算不准的时候, 就可以进行多列组合的一个统计收集。比如说 把 column 1, column 2 这两个视为一个整体,它整体的去算这个diff、 team 值,m,c, v 这些这些信息,这样的话会比单列估算的会准一点。
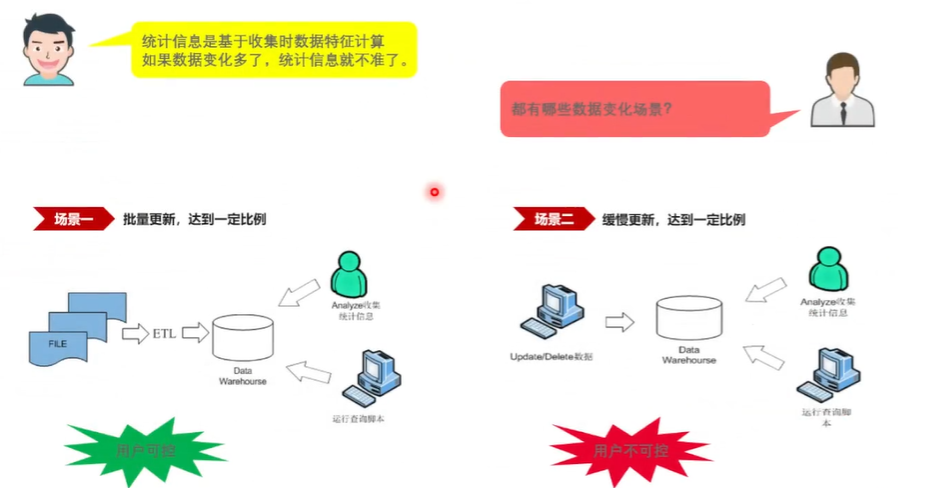
这样同时 要思考一个问题,就是把统计信息收了,是不是收一遍就够了?是不是这个事是不是一劳永逸的一个事情? 接下来看一下这个问题,就是说 统计新是基于这个数据收集时的这个特征计算的,比如说 前面算这个每个页面的这个原总密度的时候,这个密度只是基于当时做统计收集的时候计算的一个密度。
那么后来这个表还在不断地变化,页面增,页面可能在增加, 数据可能做新的插入、新的修改或删除之类的,这个数据可能又在发生了很大一个变化,那么这个时候统计信息显然就肯定不准了,对吧?因为你是基于很早很旧的数据生成的,那么现在数据是新的了,那个统计信息不一定能够代表现在的这个数据特征了。
那从这个,从 这个数据更新场景来看, 可以划分为两个简单的一个场景,第一个场景就是 的批量更新,特别是 的一个数仓场景,做这个 ETL 数据加工的时候,先进行大批量的这个数据导入, 做这个再做这个查询。这个时候 就可以手动的进行这个统计性的一个收集,这个这种场景是用户可控的,因为 自己知道 进行了一个批量的数据的一个变化。
第二场景就是数据是一个缓慢更新的,那 每一次更新可能就是更新一个三五条,那么也因为统计性收集是有一定耗时的, 不可能更新三五条进行,就马上进行统计性的一个收集,那么这种情况那究竟变化多少?进行统计收集,这个是用户不太可控的一个事情,那么基于这个两个场景, 又考虑 如何自动地数据库里面如何自动地收集这个统计信息? 首 支主要支持两种自动收集统计信息的方式,第一种是后台异步线程的一个收集,当然这也是很多产品都支持的一个功能。
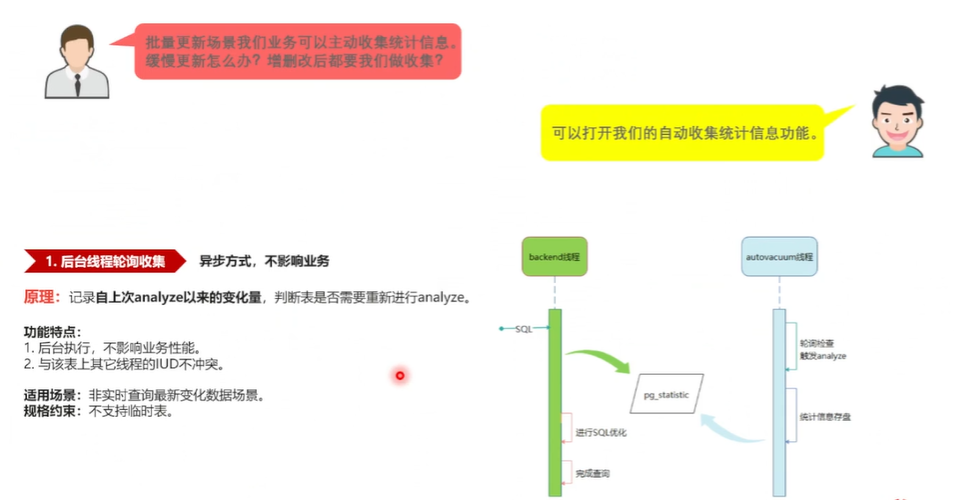 首先是有一个后台, 叫 autovacem 那个作业线程, 去轮询的去检查每张表的数据变化量,看那个数据变化了 默认是10%,如果这个数据量变化了10%,数据修被修改过10%,行以上 就要马上后台自动地做这个统计信息收集。收集完了这个统计信息以后会存入到这个系统表,叫 叫 PG3 这个系统表当中,存入以后,那么查询再来的时候,它就可以从这个系统表拿到最新的这个统计信息来生成 SQL 计划,完成最终的一个查询。这个原理很简单,就是一个后台线程, 轮询地去检查它的功能特点,就是说因为它是后台线程收集的,它收集过程当中还有它整体的一个耗时,是对前台的 SQL 语句是不冲突的,没有影响。而且它在修改系统里边过程当中加的是加锁的时候,与前台业务的增删改查之类的也都不冲突。
首先是有一个后台, 叫 autovacem 那个作业线程, 去轮询的去检查每张表的数据变化量,看那个数据变化了 默认是10%,如果这个数据量变化了10%,数据修被修改过10%,行以上 就要马上后台自动地做这个统计信息收集。收集完了这个统计信息以后会存入到这个系统表,叫 叫 PG3 这个系统表当中,存入以后,那么查询再来的时候,它就可以从这个系统表拿到最新的这个统计信息来生成 SQL 计划,完成最终的一个查询。这个原理很简单,就是一个后台线程, 轮询地去检查它的功能特点,就是说因为它是后台线程收集的,它收集过程当中还有它整体的一个耗时,是对前台的 SQL 语句是不冲突的,没有影响。而且它在修改系统里边过程当中加的是加锁的时候,与前台业务的增删改查之类的也都不冲突。
适用场景就是适用一个非实时的一个数据变化,因为是异步的,它可能实时性会差一些。 规格约束就是它无法支持临时表,那么因为 的临时表必须是这个自己当前会话当中才能查,才能看见这个数据,那么它是后台的一个线程,因为它无法看到数据, 它没有办法对临时表进行的一个统计信息的一个收集。

现在前后面 看一下第二种这个优化器同步收集,既然异步既然的后台收集有这个无法做到实时同步,那么你就有了这个优化器实时收集的这个这种方式。比如说 是一个是有大量的临时表,另外就是 刚, 刚刚插入大批量的一个数据, 马上就要查, 来不及去等这个异步收集马上要查,那么这个时候 统计也肯定是不是最新的, 如何来解决这个问题? 这个功能叫autolize,同时也叫这个动态采样,它是 优化器去准备使用这个统计信息的时候,发现它这个修改量已经超过了这个阈值,或者这个 10% 的一个阈值,认为 这个该重新收集了, 就会马上先收集一遍统计信息,收集完统计信息以后有了最新的, 再生成一个最优的这个执行计划来去用。 说这种情况就保证了不管什么时候,只要去查,就都能得到一个最新的一个统计信息来用。

这种情况其实包含两个,一个是没完全没有统计信息的时候,就直接就触发了,或者是说统计信息已经存在了,但是它已经超过阈值已经失效了, 也会再去收这个统计信息,它的这个功能特点就是说能够一个是能够解决实时性的这个问题,即使你数据是缓慢更新了, 也能得到最新的一个统计信息,它也能支持这个临时表。但是它有一个功能约束,就是这个原理上就说你触优化器来触发这个iOS,那 iOS 这个耗时最终肯定要计算到这个 SQL 语句最终的一个耗时里面。
那这两种自动选择方式 应该选择哪一种?其实 认为它是,就是 把两个功能都开起来,异步的也做, 实时的也做,如果异步后台自动给做了,那么 就减少了这个 airlines 的时间,影响 SQL 语句执行时间的这么一个问题。 它们两个同时开启是达能达到一个最优的一个功能, 自动触发是基于阈值的,那么 看一下自动触发这个阈值是怎么样的。
这个阈值包含两个值,第一个值就是表的最少修改条数,就是这个表至少有多少条才能去收集,主要为了防止这种小表, 频繁地去收集这个东西。第二个值就是百表的这个变化的一个百分比,只有当这个表变化超过百分之多少的时候,再去收集这个统计信息, 可以通过全局的阈值来设置,默认了 是 50 条,再加上这个表的 10% 来作为这个阈值。当然也可以在表集进行设置,因为有些表的数,各个表的数据特征是不一样的,有些表统计信息这个数据变化对统计信息影响比较敏感,这个时候 可以单独地给这张表设置这个不同的这个阈值,那么 在给这个设置阈值了以后,可能就修改了,因为数各个列的数据特征不一样,可能 就改了几条,这个可能导的是统计息就不是那很准了。
 那么这个问题就很被人困扰,这个阈值到底设置多少合适?每张表又不一样, 又有了一个新的一个功能,叫统计新一个推算。比如说 去查询一个数据,这个数据认为其实在表中实际已经存在了,但是它这个数,但是它可能在统计信息当中不存在,在统计信息当中不存在,这个事情就比较可怕了,因为 前面看了 的执行计划完全都是用统计信息当中的一个数据特征来代表全表的一个数据特征。
那么这个问题就很被人困扰,这个阈值到底设置多少合适?每张表又不一样, 又有了一个新的一个功能,叫统计新一个推算。比如说 去查询一个数据,这个数据认为其实在表中实际已经存在了,但是它这个数,但是它可能在统计信息当中不存在,在统计信息当中不存在,这个事情就比较可怕了,因为 前面看了 的执行计划完全都是用统计信息当中的一个数据特征来代表全表的一个数据特征。
如果实际存在,但是统计信息不存在的话,就可能得到一个比较差的一个计划,那么这种场景就是统计一收集不及,其实它就是统计收集不及时,不及时的场景, 就做了一个统计信息推算的一个功能, 基于现有的这个统计信息来估算一个不在统计因存在的当中,不在统计信息中存在数据的一个估算。这样 就有了一个兜底的方式,及时统计信息收集的不及时, 有这个兜底的方式也能得到一个不是很差的一个执行计划,这个是 收集的阈值。 下面 介绍重点介绍一下 那个 highlight 的一个当前能力,也是 做了很多一些新的特性,大概是就是在这张图里面, 分这个 5 个点去介绍。第一个是基本功能,就是一个是它能够按库级、 schema 表级、列级收集统计信息。第二个就是支持多列统计信息。
第三个就是 支持统计信息的一个导入导出, 可以做统计信息的一个备份还原,还有支持统计信息的一个锁定。当然这个是为什么要统计信息锁定?就是 在有些这个比较极端的一个场景, 有一些这个客户, 认为 这个就是 的这个查询性能很敏感,希望 能百分百地给 保持稳定。同时 也认为这个数据基本是不变化的,就是数据再怎么修改,这个数据特征是不会变化的,那 就不希望去频繁地收集这个统计信息,毕竟统计信息是基于采样的,这次采样的数据跟下一次采样的数据有可能会有偏差,那计算出来的统计信息也会有一点点的一个波动,就是 对这种波动比较敏感,不希望有这种波动。
那么这个时候就可以先按比较高的比例来收集一下这个统计信息, 把统计息进行锁定,这样统计信息永远是稳定的,那么它生成的这个计划也永远是稳定的,不存在这个计划跳变的这个情况。但是这个有一个大前提,就是一定要知道数据不管怎么变,对统计信息影响不大的情况, 可以去启用这个功能。
第二个就是 的收集方式, 已经介绍了, 支持手动收集,支持两种自动的收集,后台的收集和这个实前台实时动态采样的一个收集。 刚才说的一些各种参数也支持,一个是支持系统级的配置,另外也支持表级的一个配置,都可以主表的进行细粒度进行配置。第三方面就是准确性, 统计息最终 是要得到一个比较准的一个统计信息, 在这方面 就从三个点进行了一些问题的一个公关。第一个就是采样大小, 可以按表大小自适应的去采集一个样本, 可以设定一个百分比,一个表去采集多少,百分之多少的数据作为为作为这个样本来生成这个统计信息。第二个就是 的采样模型, 支持了这个多种采样模型,可以在表采样大小不变的情况下得到一个更优的一个统计信息的一个质量。第三个就是计算模型,就是这个统计息可以把它放到内存里面计算,也可以把放把它放到这个临时采样表里面计算,那么数据量小的情况下放到内存里面计算是最合适的,那数据量比较大的时候放到临时采样表里面方式是也能才能得到一个最优的一个性能, 可以有一个参数可以让自适应地去选择。
第四个就是可靠性方面,因为 从刚之前介绍的一个架构图里面知道 有,是 是多 CN 的一个架构,就是 支持多个计算节点,多个计算节点都去接收 4 个语句来支撑 的作业。那么既然多个计算节点,那么大家是不是各自生成各自的统计信息呢?其这样代价就比较大。其实 做的时候是哪个节点触发了这个统计信息的一个收集, 收集完以后把最终的这个收集结果去同步给其 的这个计算节点。那么这样就带来一个问题,如果有其 阶段节点故障了,那 应该怎么办?是不是 就不同步了?还是就不收集了? 的方法是说如果有其 资源故障了, 就这个统计信息就不同步了,但是一旦其 这个节点恢复了, 再进行这个表查询的时候,就把这个,再把这个统计也推送给其 的这个计算节点。
还支持这个负载均衡的一个场景,既然 是支持的是一个多 CN 架构,那么就有可能发生 读写不在同一个计算节点,在 在这个计算节点写这个计算节点有了这个修改的一个计数的一个情况,那么 跑到另外一个计算节点去查询这种异步场景,那另外一个计算节点没有这个数据修改情况, 也不知道这个表修改了多少,也没有办法判断这个阈值。
那么它如何触发这个动态采样? 就这种场景 进行了一个修改技术的一个广播,这个节点进行数据有修改,让其 计算节点也能知道,来保证这个不管你是在哪写,在哪读,都能得到一个最优的一个统计信息。最后就是 那个估算增强,也就是说 在这个刚才介绍了,在 数据修改无法达到阈值,你设定阈值还没有达到,但统计信息可能已经失效了,这种情况的一个优化的一个功能,右边是 这个最新版本的一个默认的一个出厂配置参数。前第一部分就是打开 这个后台异步轮询的这个收集方式,第二个就是打开 前台优化器实时动态采样的这种方式,后面就是有 3 个参数,一个是开启了这个计算模式的一个自适应内存放,能放得下 就放内存,内存放不下 就下盘, 保证这个采样率不会因为内存导致采样不足。后面是开启这个统计型归算估算,才得到一个最好的一个随机性的一个函数。
3.统计信息常见问题
接下来 介绍 的这个第三部分,就是 就是统计期有多重要,统计是如何收集的?那么看统计收集过程当中 经常遇到一个哪些的一个问题。第一个就是调整采样率,因为 知道统计器是基于采样的,你样本选的太少生成的这个数据特征不足以描述 全表的一个特征的时候,这个就比较惨了 , 的采样率是一定要恰当,但是也不能全采, 不可能百分百去采集所有数据,这个就相当于做一个查询,就要把全表全扫描一遍,那可能这个时间比产品本身的时间还要长,这个就不算了。
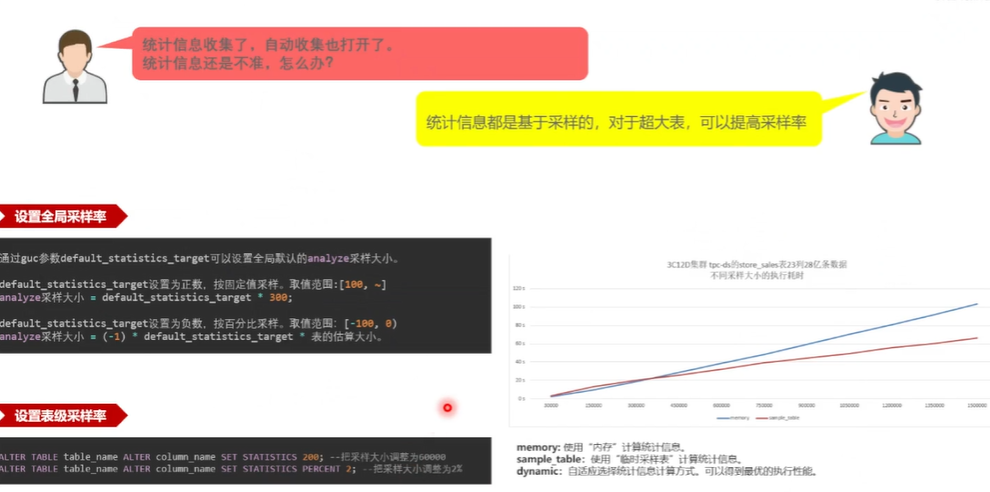 是基于部分采样, 只采集一部分来估算一个统计信息,来进行一个代价估算,那么这就涉及到采样率这个事情,采样率本身也是支持这个全局采样率的一个设置,同时也支持这个表级采样率的一个设置。可能有些表的数据特征难以去抓住, 就可以在表级去把这个单个表的采样率给它调大。
是基于部分采样, 只采集一部分来估算一个统计信息,来进行一个代价估算,那么这就涉及到采样率这个事情,采样率本身也是支持这个全局采样率的一个设置,同时也支持这个表级采样率的一个设置。可能有些表的数据特征难以去抓住, 就可以在表级去把这个单个表的采样率给它调大。
右边是 的一个测试场景, 是基于 3 个计算节点, 12 个数据节点在 TPCDS 的子,而 seal 这个表上它有20,有 23 列 28 一条数据, 看一下它是采用哪一种计算方式,能够得到一个最优的一个执行性能。因为 的这个采样率加大, 就是样板数加大了,你采的多了,计算的多了,那 10 耗时必然就多了。 这个蓝线其实就是基于内存的方式, 看就是横坐标是不同的,这个采样大小,纵坐标是这个耗时蓝线,基本上就是一个完全线性的一个关系,就是你的采样越多, 你的耗时就线性地去增长。 这个红线是 基于这个临时采样表的这个方式得到的一个性能,就是它随着采样的增多,它的一个性能变化比这个蓝线到后面要好很多。
开启自适应的时候,就是前段部分 去采用这个蓝线得到一个最优性能,后面部分 就采用这个临时采样表的方式走这个红线,得到一个最优的一个性能,就是 尽可能地做到了,就是提高采样率的情况下,执行性能增长也不是那么明显。达到这么一个目的, 看一下, 就是 align 的, 执行库当中它其实就是一条命令, 一条命令查询它就这个触发了,那么触发了以后它究竟干了些什么事? 比如说执行慢了,到底慢在哪里?就要看很多时候 就像一个黑盒子一样,不知道 在干啥。这个时候 想了一些办法, 来实时地展现 一些状态,主要是从三个方面。
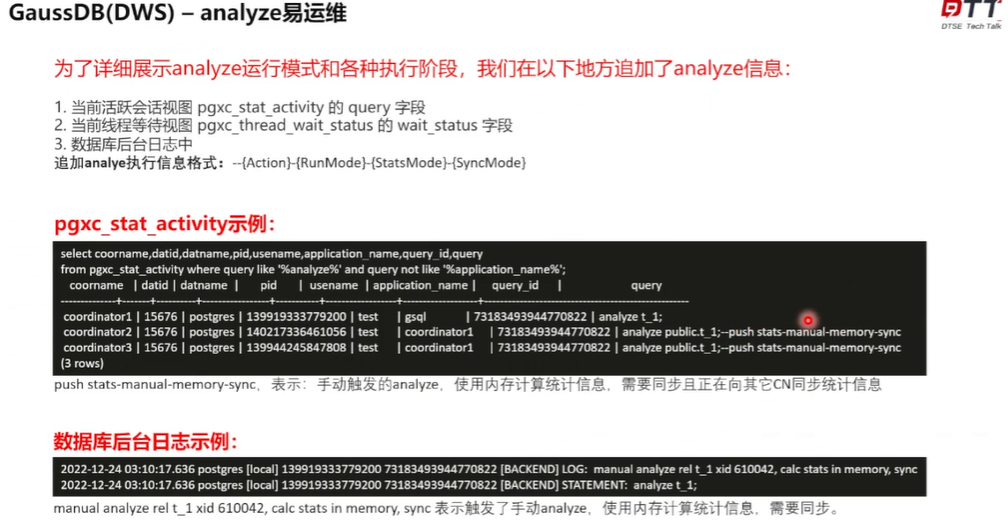 第一个方面就是在 这个查询当前的活跃会话视图的时候,在这个 query 阶段,这个图就是这个例子, 查询当前都有哪些人正在执行哪些 SQL 语句, 在这个 SQL 语句后面通过这个注释的方式标识了一下这个 align 的一些状态。这个基本格式分四部分,第一部分就action,就是它具当前正在干什么。第二部分就是它的运行模式,它是哪一种?到底是手动的,还是后台异步的,还是前台实时的哪种方式?第三种就是统,它就是统计信息计算的方式,它到底是使用内存的方式计算,还是使用这个临时采用表的方式一个计算。第四部分就是它统计信息的一个同步模式,要不要同步给其 的这个 CN 这 4 个格式? 看这个活跃会话视图常用的,查询出来这个例子,那这个 push state 表示它要这个向其 CN 推送这个统计信息,这个 menu 表示它是这个手动触发的这么一个 l s memory 表示它是通过内存来计算这个统计信息。
第一个方面就是在 这个查询当前的活跃会话视图的时候,在这个 query 阶段,这个图就是这个例子, 查询当前都有哪些人正在执行哪些 SQL 语句, 在这个 SQL 语句后面通过这个注释的方式标识了一下这个 align 的一些状态。这个基本格式分四部分,第一部分就action,就是它具当前正在干什么。第二部分就是它的运行模式,它是哪一种?到底是手动的,还是后台异步的,还是前台实时的哪种方式?第三种就是统,它就是统计信息计算的方式,它到底是使用内存的方式计算,还是使用这个临时采用表的方式一个计算。第四部分就是它统计信息的一个同步模式,要不要同步给其 的这个 CN 这 4 个格式? 看这个活跃会话视图常用的,查询出来这个例子,那这个 push state 表示它要这个向其 CN 推送这个统计信息,这个 menu 表示它是这个手动触发的这么一个 l s memory 表示它是通过内存来计算这个统计信息。
 think 表示说 要进行统计信息的一个同步,当然如果发生了其 节点发生 sin 故障的话,这个就会显示成no, think 表示过这个不需要同步这个统一信息。
think 表示说 要进行统计信息的一个同步,当然如果发生了其 节点发生 sin 故障的话,这个就会显示成no, think 表示过这个不需要同步这个统一信息。
那么在做一个 Ms 执行过程当中的时候,就可以实时地去查这个视图,看一下当前的 action 到底是啥,当前到底走到哪一步了?成它正在干什么就可以很清晰明了的一个知道。同时在这个线程等待视图里面,它这个 Whiter setters 这个字段里头, 也完全用了相同的一个格式来展现这个统计信息。比如说 去查询到 计算节点,或 到数据节点上, 去查询这个当前县城正在干什么啊?当前县城为什么就可以通过这个字段来清楚地得知道 Alice 到底来干啥?有了这个实时的一个计算,这个实时的一个日志显示以后, 还有这个数据库后台日志的一个显示,就是说 最终 align 的执行完了以后,它都会在这个后台日志里面打一条消息,告诉 对哪张表做了一个allies,它的一个一些信息是什么样的?比如说这个信息它就是 menu allies real 对这个 T1 这个表做了一个手动的那align,并且它采用一个使用那个内存计算的一个统计信息,并且计算并且对统计信息进行了一个同步。从这个通过上面这种方式 就可以很容易地去做这个维护操作,知道 highlight 的一个影响。
下面还有一个很关键的问题,就是说 怎么判断一个统计息失效了?就是你通过刚才的介绍, 知道统计信息修改超过一定阈值的时候,它超了这个阈值, 就认为它失效了。那,那 用户角度来说 , 用户使用的时候不知道这个阈值, 只知道查询可能 SQL 语语句就慢了,那么 怎么知道是由于这个统计信息未收集,或者这个统计失效导致的?这个跟统计信息跟那个统计信息相关,这个执行计划变差,因为执行计划变差了有很多原因,有可能动态资源的原因,也可能是由于统计信息的原因,还有可能是由于这个估算的原因,都是偏差的。
 那么 怎么识别出来是不是统计信息导致的?其实有三种方式,第一种方式就是说因为 这个 SQL 语句执行过程当中,如果一些执行耗时比较长的语句, 都会记录到了 这个叫税库的字典表里面, 也叫 top SQL,就是进入 to top SQL 里面的语句,一般执行时间比较长,当 拿到这个语句的时候, 可以看这个执行计划,或者说 重新对语句做一个打印一下执行计划如果它显示出了这些信息,这个就是比如说这个的是显示的是 static not select。
那么 怎么识别出来是不是统计信息导致的?其实有三种方式,第一种方式就是说因为 这个 SQL 语句执行过程当中,如果一些执行耗时比较长的语句, 都会记录到了 这个叫税库的字典表里面, 也叫 top SQL,就是进入 to top SQL 里面的语句,一般执行时间比较长,当 拿到这个语句的时候, 可以看这个执行计划,或者说 重新对语句做一个打印一下执行计划如果它显示出了这些信息,这个就是比如说这个的是显示的是 static not select。
 就这张表的整表的统计信息没有收集, 这个是这张表的某一列的统计信息没有收集。还有就是进行多列的时候,多列组合的时候没有收集,还有单列的时候没有收集,就是如果这个表统计没有收集,通过这种方式它就能够很清晰明了地告诉 ,这个是由于没有收集统计信息导致的这个查询的一个劣化。
就这张表的整表的统计信息没有收集, 这个是这张表的某一列的统计信息没有收集。还有就是进行多列的时候,多列组合的时候没有收集,还有单列的时候没有收集,就是如果这个表统计没有收集,通过这种方式它就能够很清晰明了地告诉 ,这个是由于没有收集统计信息导致的这个查询的一个劣化。
还有就是说 没有得到这些信息,那可能就是统,肯定就是统计信息已经存在了,那存在了以后它可能是会失效,究竟是不是由于失效导致的这个产业计划的劣化?那么 可以也是在这个 TOP 策略 top SQL 里面, 把当时的一个执行计划拿出来看一下, 这个 a rows 就 实际的一个估算,实际执行的一个值跟 事先估算那个值,看它有多大偏差。
如果对一些级表的扫描, 有一个偏差比较大的话,那个是那个,那就说明了这个级表上统计信息确实有些问题,可能就是统一失效了。这个时候 就可以对这个表 重新做一下 align 的收集,看一下,再执行下这个 SQL 是没有变好,这有可能就是因为 align 的不及时导致了这个问题。
那么 可能说,比如说 TOP SQL 没有开,或者 阈值因为阈值设置得比较大, 没有反馈在这个 TOP 诉求里面,那 应该怎么办?就是 可以在这个数据库后台日志里面去看这些信息,当这个统计信没有数这个字比较小,其实跟显示跟左边其实差不多的,就是去查询一个SQL,发现没有统计信息的时候,没有统计可用, 把这个也没有开,或者自动收集也没有开。
这个时候 会把这个没有统计信息的一些,东西记录到 的数据后台,数据库后台那个日志里头,在日志里头 去查找这些 not client 这些关键字,你就可以看到底运行过程当中哪些表是没有收集统计信息导致的。这个 SQL 性能的一个劣化就是通过这个手,通过这些手段 来快速地定位哪些表示因为统计金没有收集导致的。
最后 介绍一下统计信息的经常遇到的一些问题, 只是简单地列了几个,也是问的比较多的,就是说哪些操作需要操作完了以后,到底哪些操作完以后 需要收集统计信息,其实主要是导致数据变化的一些操作,一个是增删改 copy merge,还有就是能够导致数据变化的一些这个 auto table 语句,比如说是 target partition、 exchange partition 或者修改数据的一个类型,这些能够引起数据的类型还有这个数值变化的这些操作完以后都需要重新地收集这个统计信息。
第二个就是 看哪些表缺少统计信,就是哪些表 完全没有收统计信息,那么要有一个叫 p 级 object 的表, 看一下它,因为每次 ally 完成以后, 都会把这个最近一次 align 的时间给记录到这个里面, 就看这个时间有没有,如果这个时间从来都是没有从这去空的,说明这个表从来没有收集过这个统计信息。
还要看哪些表统计性失效了,从本质上来说,看哪些表统原理上来说, 看哪些表统计失效了, 就看那个阈值,就这个表的修改量也没有超过阈值失效。在内部逻辑当中,不管是后台轮询了,还是前台优化器实时同步的同步计算这个东西都是基于这个阈值的,它原理也都是一样,就是表的修改量跟那个阈值进行比较。那么如果要想看这个数据库当中所有表到底哪些没收集的话,如果去一个是先拿到数据修改量,另外就是拿计算出阈值两个进行比较,这个就可以了,但是这样一张表去做可能比较慢,这样 就维护了一个视图,当 这个 实时记录表的这个修改计数,当这个修改计数超过阈值的时候, 就直接在这个表上置了一个状态,那么这个时候 就直接查这个,通过这个系统函数来查这个状态就可以了。就省去了这个计算的一个过程。当它显示这个 need align 的时候,说明这个表就需要收集这个统一信息了,这样的话可以快速地查到整个库到底哪些表。
第四个如何自动收集的?是就是两个两种模式,后台线程,就是后台线程需要打开这个 Autoback 这个参数优化器实时收集的,需要打开这个 auto align 的这个参数。还有就是 经常问到的trunkit, 做完 trunkit 以后,这个表统一期到底是一起删掉了还是没删掉,还是下次能不能用?其实串开的分两种, 经常会被搞混淆。第一个是串开的整表,整表它会整对整体的进行一个数据的一个清理,也会让那个统计信息的一个失,会让统计信息的失效。另外一种叫做 auto table truncate partition, 的 是 truncate 一个partition,这种场景就是它不会改变它,只是它相当于只是做了一个这个分区的数据修改,它的全表的统计信息是不变的。
4. GaussDB智能客服
接下来 介绍一下 一个智能运维,智能回答的一个这么一个功能, PC 端是这么一个这样的一个链接。 同时如果加载了 这个微信公众号的话, 可以在公众号直接问 这个小助手,问 各种这个问题。 可以 通过这个图也可以看到 这个你问各种什么这个锁的问题,锁等级的问题,创建集群的问题。嗯,您只要给 提问, 就会给你自动回答,自动给你找到相关的一个链接的一个介绍。
 后面就是这个产品联系 的一个联系方式, 可以向 的一个智能客服问哪些问题? 一个场景,可以是这个产品相关的一些问题。第二个重要场景是 的一个产一些这个具体的一个技术问题查询的,比如说查询的导入方式、查询规格或者查询功能的一个基本介绍某些特性的一些知识。就是说,比如说 可以通过查 的产品手册来了解这个问题,如果产品手册查起来比较不方便的话,可以直接抛问题给 这个智能客服, 会帮你从产品手册里面得到一个最优的一个结果。 接下来 可以看一下 这个, 通过 PC 端可以得到 这个问题,这个 PC 端链, PC 端的这个链接 可以直接去使用,它可以直接点进去就可以直接发问了。
后面就是这个产品联系 的一个联系方式, 可以向 的一个智能客服问哪些问题? 一个场景,可以是这个产品相关的一些问题。第二个重要场景是 的一个产一些这个具体的一个技术问题查询的,比如说查询的导入方式、查询规格或者查询功能的一个基本介绍某些特性的一些知识。就是说,比如说 可以通过查 的产品手册来了解这个问题,如果产品手册查起来比较不方便的话,可以直接抛问题给 这个智能客服, 会帮你从产品手册里面得到一个最优的一个结果。 接下来 可以看一下 这个, 通过 PC 端可以得到 这个问题,这个 PC 端链, PC 端的这个链接 可以直接去使用,它可以直接点进去就可以直接发问了。

5.Q&A
5.1 align 的自动收集信息用的是什么工具?
align 的本身它是一个内置功能,它不是跟那个其 的用户一个产品可能不太一样, 是一个内置功能,不是用外部工具来实现的,直接在内核里面做了一个收集, 在使用的时候只需要开启那个参数,它就会自动收集了,并不需要单独地去部署一些脚本或者说什么工具之类的一个东西。
5.2统计信息是如何更新采集的?
有三种信息采集模式,第一种是手动收集,第二种就是后台线程异步地去那轮询地去检查, 看哪些表有没有收集统计。第三种方式就是 的, 可以简单地叫它动态采样,就是优化器接收到一个思路语句,准备生成执行计划的时候, 看这张表有哪些统计信息没有收集, 来收集这个统计信息。比如说 把自动收集打开以后,基本上 只要去使用, 就会拿得到一个比较最优的一个统计信息, 就可以打开这个参数。除了一个参数打开以后,还要注意一下阈值的配置,因为阈值的这个配置是不是合理?是不是 这个推荐的这个默认的 10% 的这个阈值?
5.3 GausDBs在使用操作后,需要不需要进行统一收集?
Vacom 主要是对表进行一些脏数据的一个整理,进行一些数据页面的一个回收,就是 本身是, 是就是不会去动这个用户数据本身, 只会对一些这个可能会挪动那个数据的存储位置来节省这个空间, 把一些可回收的页面进行一些空间的回收, 说它只是动了数据的位置,并没有动数据本身。
数据等于说做完 Michael 以后, 数据并没有变,也就没有影响这个统计信息的这个这么一个东西。 Ilines 是采样数据, 收集统计信息,只有这个数据有了变化以后才需要做那个Alice。
5.4 高斯 DB 适合哪种操作系统?
怎样从 openEuler迁移到windows?GaussDB 支持很多种操作系统,支持很多种这个 CPU 的平架构也都是支持的,也有 windows 的一个版本从欧拉迁移到windows,如果是数据库的话, 就直接使用 的这个数据迁移工具做这个数据迁移就好,因为它也是这个跨平台数据迁移工具,本身 就是也是这个跨平台的。
5.5 哪些原因会导致统计信息异常?有哪些常用的规避方式?
在 这个实际生产当中,在 没有开启这个自动收集的时候,确实有很多统计信息异常的一个事情,就说没有统计,一个是没有统计信息根本就没有收,如果不开自动收集的话,用户也没有做这个事,有手动收集,有自动收集。
5.6 表级统计息有哪些关键指标?
这表级统计器只要关心表的规模,主要两个点,第一个是表有多少条数据,第二个就是表有在磁盘上有多少个物理页面数,主要是两个指标来关心表集的这个信息,统计信息不足,统计信息不走主键是否有性能问题?。统计这个问的可能不太贴切,就是不是这个SQL语句不没有走上主键是不是有性能问题?这个主要看这个 用哪一列,如果查询到的就是首先如果有主键查询也确实用了主键,看这个也要看这个, 主键是不是能得到一个最优的一个执行性能?这个跟用不用这个主键其实也跟这个统计信息的一个还是有相关的。
因为除了表会生成统计信息以外,索引也会生成统计信息,这个没有特别细说这个事情,就索引本身它 也要知道这个索引的规模,索引它本身有多少条,有多少那个物理页面来算一下,去打开这个索引做这个索引那个扫描会有多大的代价?这也是跟统计性相关的。
都有哪些统计信息,这个统计息本身 都介绍了,有表级的统计信息,还有列级的一个统计信息,表级主要描述表规模,列级主要描述列的数据特征。这个统计信息跟 MySQL 里面指导执行计划的统计有哪些区别?这个区别应该是区别,区别不是太大,因为这个表列都是这些基本的统一,基本的一个统计信息,不同友商之间那个都是差不太多的,可能差异在这个如何收集,如何用最高的性能来收集这个统计器,还有这个收集的极致性,主要差异是在这些方面统计器本身的差异其实是不太大的。
5.7 统计信息是自动默认自动收集的吗?
813 版本是自动收集的,因为 813 版本这个 outline 是默认都是打开的,但是 但是有个问题,就是 以前为了规避这个,为了规避一些问题,把这个阈值调得比较高。如果真正在使用这个 813 版本的时候, 希望这去检查一下这个阈值, 是不是跟 推荐的百分之 10% 那个阈值是不是一样的? 建议最好把它调下来,调成 10% 的这个阈值。
如果表特别大的情况下,如何采集统计息才能保证准确性?这个,这也是一个比较难以回答的一个问题,就是 统计信息本身它是严格依赖于这个数据特征的,并不绝对是那个表特别大, 你需要采样率就必须特别高,并不是这样的,还是跟数据特征有直接的一个关系。比如说举个例子,如果你这个列存储的是一些更多的是枚举类型的值,比如说是一些省份或邮编之类的,就说你不管表多大,都能把那些,基本上都能把这些枚举值给你采全了,这是你在提高采样率,也没有必要。 最好就是找一个比较恰当的,既能采更少的数据,又能得到一个更优的一个准确性。这么一个 通过 这个大量的用户使用,就是 默认的采样率,基本上对所有表差不多是都能够的,但是对一些极端场景确实存在。比如说几百亿条那个大表,采默认是采3万条元组啊。一个3万条元组对于一个几百万大表,可能 感觉差距很大,但是究竟需要不要提高采样率,这个还是要看 那个执行计划本身,就是这个统计信息有没有真正代表这个数据特征,还是要看数据特征本身的。
的那个东西就是不绝对不绝对是大表,一定要提高采样率,但是确实大表的时候容易有统计信息采集采样率不够导致的一个这个问题, 具体问题还是要具体看,觉得还是不要轻易地去提高这个采样率,毕竟它是有代价的。 那个刚才介绍的时候也, 把那个曲线图已经画出来了,你的采样率加大,采样本多了,性能消耗也多了,对系统那个非业务的一个性能影响也就高了, 还是要看一看究竟是什么原因导致的这个统计信息一个不准。 这也是 一个现在比较努力的一个课题,就是 尽可能地找出 这个各种各样的一个数据特征。
5.8 在不提高采样率的时候,不提高采样大小的时候,怎么提高这个统一间的一个准确性?
那么 现在已经做到的就是 支持了很多种数据模,数据的一个采样模型,就是 传统的默认的一个蓄水池的一个模型,后来 又自己优化,而且在列存场景的话, 就自研了一种数据模型都可以做到。这个不提高采,就是尽可能的不提高采样率的情况下,提升那个统计信息那个准确性。当然这个也是一个开放性的一个一个研究方向,确确实确确实是这样。
5.9 可以在什么地方看到统计信息收集的日志?
如果是还有这个线程等待视图,如果是结束之后,有没有收统计信息? 什么时间收的?可以在这个数据后台日志去这个在这个日志里面去找,如果是单纯的想看那个时间,直接查 那个表就可以了。
5.10 统计信息收集是否有自学习功能?
也有这个自学习的这么样一个尝试,但是那个现在还没有落到这个版本里面,还没有这个跟大家见面, 还在一个就今天就尝试了一个功能,效果来看还是不错的。但是究竟最终怎么产品落地,这个还需要继续的去想一想这个事情。
6. 总结
GaussDB是基于华为主导的openGauss生态推出的企业级分布式关系型数据库。该产品具备企业级复杂事务混合负载能力,同时支持分布式事务,同城跨AZ部署,数据0丢失,支持1000+的扩展能力,PB级海量存储。同时拥有云上高可用,高可靠,高安全,弹性伸缩,一键部署,快速备份恢复,监控告警等关键能力,能为企业提供功能全面,稳定可靠,扩展性强,性能优越的企业级数据库服务。统计信息在数据库当中是很重要的一个东西,华为云GaussDB在这方面做持续的耕耘和持续的改进。
本文参与华为云社区【内容共创】活动第22期。
任务17:

- 点赞
- 收藏
- 关注作者
评论(0)