人工智能知识图谱之信息抽取:基于Labelstudio的UIE半监督深度学习的智能标注方案(云端版),提效。

基于Label studio实现UIE信息抽取智能标注方案,提升标注效率!
项目链接见文末
-
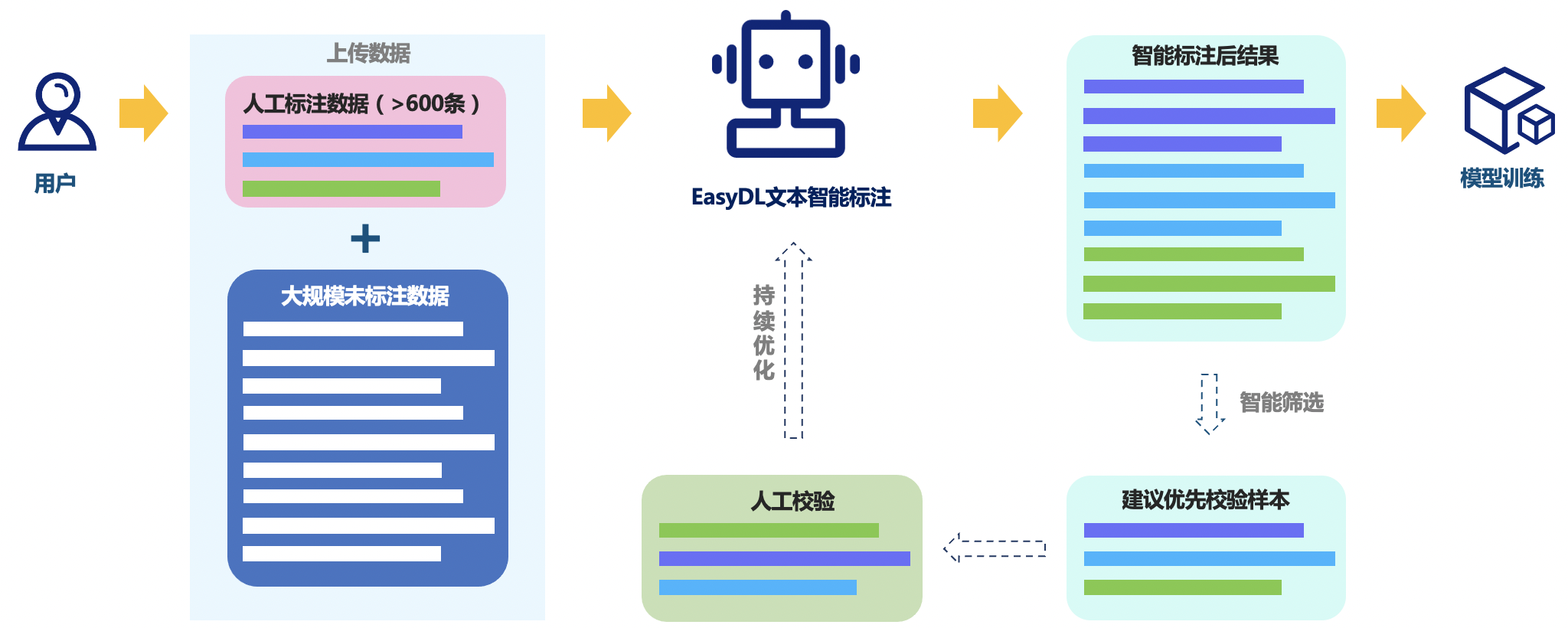
人工标注的缺点主要有以下几点:
- 产能低:人工标注需要大量的人力物力投入,且标注速度慢,产能低,无法满足大规模标注的需求。
- 受限条件多:人工标注受到人力、物力、时间等条件的限制,无法适应所有的标注场景,尤其是一些复杂的标注任务。
- 易受主观因素影响:人工标注受到人为因素的影响,如标注人员的专业素养、标注态度、主观判断等,易受到人为误差的干扰,导致标注结果不准确。
- 难以满足个性化需求:人工标注无法满足所有标注场景和个性化需求,无法精确地标注出所有的关键信息,需要使用者自行选择和判断。
-
相比之下,智能标注的优势主要包括:
- 效率更高:智能标注可以自动化地进行标注,能够快速地生成标注结果,减少了人工标注所需的时间和精力,提高了标注效率。
- 精度更高:智能标注采用了先进的人工智能技术,能够对图像进行深度学习和处理,能够生成更加准确和精细的标注结果,特别是对于一些细节和特征的标注,手动标注往往存在误差较大的问题。
- 自动纠错:智能标注可以自动检测标注结果中的错误,并进行自动修正,能够有效地避免标注错误带来的影响,提高了标注的准确性。
- 灵活性更强:智能标注可以根据不同的应用场景和需求,生成不同类型的标注结果,能够满足用户的多样化需求,提高了标注的适用性。
总之,智能标注相对于人工标注有着更高的效率、更高的精度、更强的灵活性和更好的适用性,可以更好地满足用户的需求。
自然语言处理信息抽取智能标注方案包括以下几种:
-
基于规则的标注方案:通过编写一系列规则来识别文本中的实体、关系等信息,并将其标注。
- 基于规则的标注方案是一种传统的方法,它需要人工编写规则来识别文本中的实体、关系等信息,并将其标注。
- 这种方法的优点是易于理解和实现,但缺点是需要大量的人工工作,并且规则难以覆盖所有情况。
-
基于机器学习的标注方案:通过训练模型来自动识别文本中的实体、关系等信息,并将其标注。
- 基于机器学习的标注方案是一种自动化的方法,它使用已经标注好的数据集训练模型,并使用模型来自动标注文本中的实体、关系等信息。
- 这种方法的优点是可以处理大量的数据,并且可以自适应地调整模型,但缺点是需要大量的标注数据和计算资源,并且模型的性能受到标注数据的质量和数量的限制。
-
基于深度学习的标注方案:通过使用深度学习模型来自动识别文本中的实体、关系等信息,并将其标注。
- 基于深度学习的标注方案是一种最新的方法,它使用深度学习模型来自动从文本中提取实体、关系等信息,并将其标注。
- 这种方法的优点是可以处理大量的数据,并且具有较高的准确性,但缺点是需要大量的标注数据和计算资源,并且模型的训练和调试需要专业的知识和技能。
-
基于半监督学习的标注方案:通过使用少量的手工标注数据和大量的未标注数据来训练模型,从而实现自动标注。
- 基于半监督学习的标注方案是一种利用少量的手工标注数据和大量的未标注数据来训练模型的方法。
- 这种方法的优点是可以利用未标注数据来提高模型的性能,但缺点是需要大量的未标注数据和计算资源,并且模型的性能受到标注数据的质量
-
基于远程监督的标注方案:利用已知的知识库来自动标注文本中的实体、关系等信息,从而减少手工标注的工作量。
本次项目主要讲解的是基于半监督深度学习的标注方案。
1.UIE-base预训练模型进行命名实体识别
from pprint import pprint
from paddlenlp import Taskflow
schema = ['地名', '人名', '组织', '时间', '产品', '价格', '天气']
ie = Taskflow('information_extraction', schema=schema)
pprint(ie("2K 与 Gearbox Software 宣布,《小缇娜的奇幻之地》将于 6 月 24 日凌晨 1 点登录 Steam,此前 PC 平台为 Epic 限时独占。在限定期间内,Steam 玩家可以在 Steam 入手《小缇娜的奇幻之地》,并在 2022 年 7 月 8 日前享有获得黄金英雄铠甲包。"))
[2023-03-27 16:11:00,527] [ INFO] - Downloading model_state.pdparams from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base_v1.0/model_state.pdparams
100%|██████████| 450M/450M [00:45<00:00, 10.4MB/s]
[2023-03-27 16:11:46,996] [ INFO] - Downloading model_config.json from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/model_config.json
100%|██████████| 377/377 [00:00<00:00, 309kB/s]
[2023-03-27 16:11:47,074] [ INFO] - Downloading vocab.txt from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/vocab.txt
100%|██████████| 182k/182k [00:00<00:00, 1.27MB/s]
[2023-03-27 16:11:47,292] [ INFO] - Downloading special_tokens_map.json from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/special_tokens_map.json
100%|██████████| 112/112 [00:00<00:00, 99.6kB/s]
[2023-03-27 16:11:47,364] [ INFO] - Downloading tokenizer_config.json from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/tokenizer_config.json
100%|██████████| 172/172 [00:00<00:00, 192kB/s]
W0327 16:11:47.478449 273 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0327 16:11:47.481654 273 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2023-03-27 16:11:50,518] [ INFO] - Converting to the inference model cost a little time.
[2023-03-27 16:11:57,379] [ INFO] - The inference model save in the path:/home/aistudio/.paddlenlp/taskflow/information_extraction/uie-base/static/inference
[2023-03-27 16:11:59,489] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load '/home/aistudio/.paddlenlp/taskflow/information_extraction/uie-base'.
[{'产品': [{'end': 35,
'probability': 0.8595664902550801,
'start': 25,
'text': '《小缇娜的奇幻之地》'}],
'地名': [{'end': 34,
'probability': 0.30077351606695757,
'start': 26,
'text': '小缇娜的奇幻之地'},
{'end': 117,
'probability': 0.5250433327469182,
'start': 109,
'text': '小缇娜的奇幻之地'}],
'时间': [{'end': 52,
'probability': 0.8796518890642702,
'start': 38,
'text': '6 月 24 日凌晨 1 点'}],
'组织': [{'end': 2,
'probability': 0.6914450625760651,
'start': 0,
'text': '2K'},
{'end': 93,
'probability': 0.5971815528872604,
'start': 88,
'text': 'Steam'},
{'end': 75,
'probability': 0.5844303540013343,
'start': 71,
'text': 'Epic'},
{'end': 105,
'probability': 0.45620707081511114,
'start': 100,
'text': 'Steam'},
{'end': 60,
'probability': 0.5683007420326334,
'start': 55,
'text': 'Steam'},
{'end': 21,
'probability': 0.6797917390407271,
'start': 5,
'text': 'Gearbox Software'}]}]
pprint(ie("近日,量子计算专家、ACM计算奖得主Scott Aaronson通过博客宣布,将于本周离开得克萨斯大学奥斯汀分校(UT Austin)一年,并加盟人工智能研究公司OpenAI。"))
[{'人名': [{'end': 23,
'probability': 0.664236391748247,
'start': 18,
'text': 'Scott'},
{'end': 32,
'probability': 0.479811241610971,
'start': 24,
'text': 'Aaronson'}],
'时间': [{'end': 43,
'probability': 0.8424644728072508,
'start': 41,
'text': '本周'}],
'组织': [{'end': 87,
'probability': 0.5550909248934985,
'start': 81,
'text': 'OpenAI'}]}]
使用默认模型 uie-base 进行命名实体识别,效果还不错,大多数的命名实体被识别出来了,但依然存在部分实体未被识别出,部分文本被误识别等问题。比如 “Scott Aaronson” 被识别为了两个人名,比如 “得克萨斯大学奥斯汀分校” 没有被识别出来。为提升识别效果,将通过标注少量数据对模型进行微调。
2.基于Label Studio的数据标注

在将智能标注前,先讲解手动标注,通过手动标注后才会感知到智能标注的提效和交互性。
由于AI studio不支持在线标注,这里大家在本地端进行标注,标注完毕后上传数据集即可
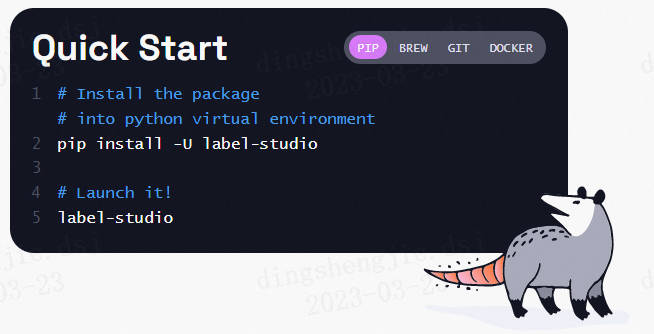
2.1 Label Studio安装
以下标注示例用到的环境配置:
- Python 3.8+
- label-studio == 1.7.1
- paddleocr >= 2.6.0.1
在终端(terminal)使用pip安装label-studio:
pip install label-studio==1.7.1
安装完成后,运行以下命令行:
label-studio start
在浏览器打开http://localhost:8080/,输入用户名和密码登录,开始使用label-studio进行标注。
2.2 实体抽取任务标注
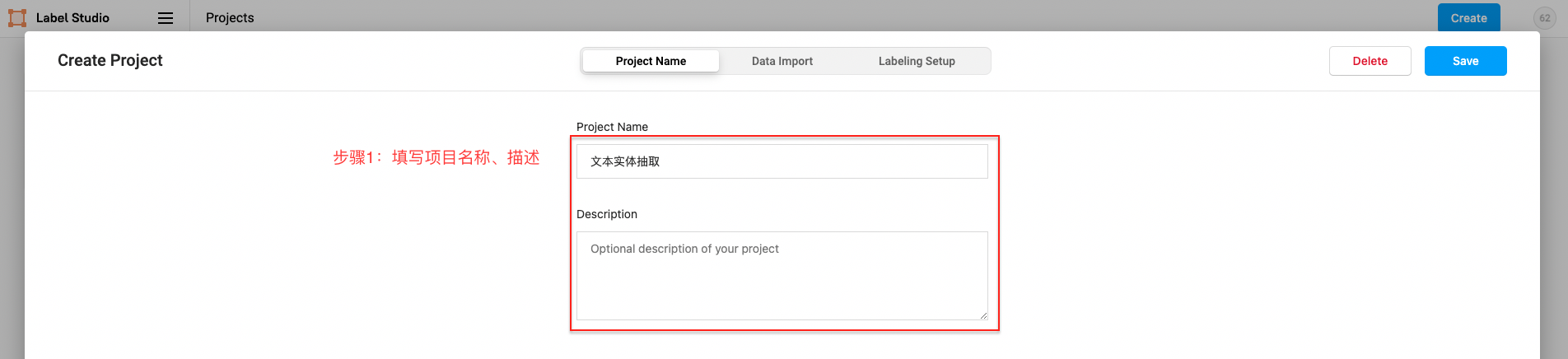
- 项目创建
点击创建(Create)开始创建一个新的项目,填写项目名称、描述,然后选择Object Detection with Bounding Boxes。
填写项目名称、描述
- 命名实体识别任务选择
-
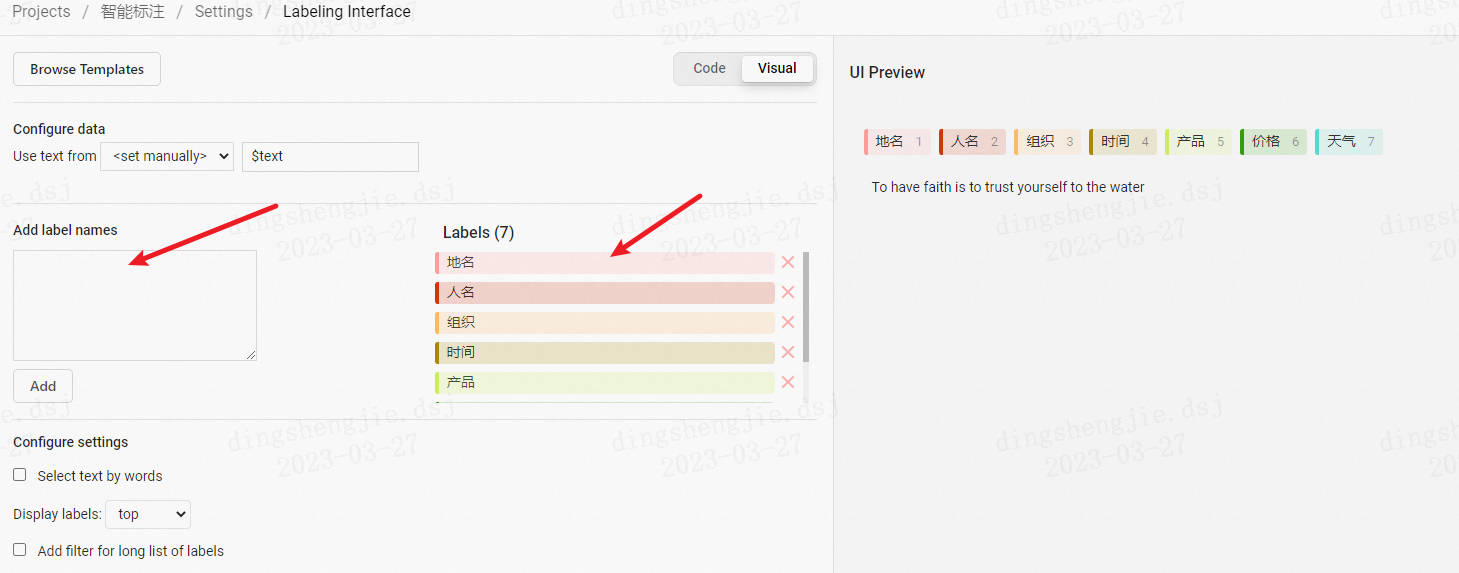
添加标签(也可跳过后续在Setting/Labeling Interface中配置)

-
数据上传
先从本地上传txt格式文件,选择List of tasks,然后选择导入本项目。
-
实体抽取标注

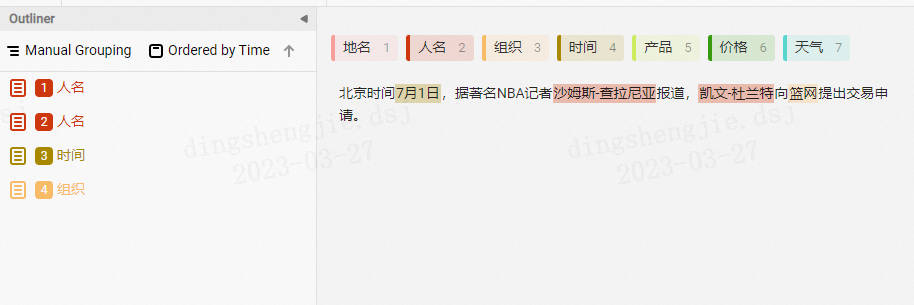
- 数据导出
勾选已标注文本ID,选择导出的文件类型为JSON,导出数据:

3. 模型微调
3.1 数据转换
在终端中执行以下脚本,将 label studio 导出的数据文件格式转换成 doccano 导出的数据文件格式。
python labelstudio2doccano.py --labelstudio_file dataset/label-studio.json
参数说明:
- labelstudio_file: label studio 的导出文件路径(仅支持 JSON 格式)。
- doccano_file: doccano 格式的数据文件保存路径,默认为 “doccano_ext.jsonl”。
- task_type: 任务类型,可选有抽取(“ext”)和分类(“cls”)两种类型的任务,默认为 “ext”。
!python doccano.py \
--doccano_file dataset/doccano_ext.jsonl \
--task_type "ext" \
--save_dir ./data \
--splits 0.8 0.2 0
[2023-03-27 16:43:33,438] [ INFO] - Converting doccano data...
100%|████████████████████████████████████████| 40/40 [00:00<00:00, 29794.38it/s]
[2023-03-27 16:43:33,440] [ INFO] - Adding negative samples for first stage prompt...
100%|███████████████████████████████████████| 40/40 [00:00<00:00, 118650.75it/s]
[2023-03-27 16:43:33,441] [ INFO] - Converting doccano data...
100%|████████████████████████████████████████| 10/10 [00:00<00:00, 38095.40it/s]
[2023-03-27 16:43:33,442] [ INFO] - Adding negative samples for first stage prompt...
100%|███████████████████████████████████████| 10/10 [00:00<00:00, 130257.89it/s]
[2023-03-27 16:43:33,442] [ INFO] - Converting doccano data...
0it [00:00, ?it/s]
[2023-03-27 16:43:33,442] [ INFO] - Adding negative samples for first stage prompt...
0it [00:00, ?it/s]
[2023-03-27 16:43:33,444] [ INFO] - Save 274 examples to ./data/train.txt.
[2023-03-27 16:43:33,445] [ INFO] - Save 70 examples to ./data/dev.txt.
[2023-03-27 16:43:33,445] [ INFO] - Save 0 examples to ./data/test.txt.
[2023-03-27 16:43:33,445] [ INFO] - Finished! It takes 0.01 seconds
参数说明:
- doccano_file: doccano 格式的数据标注文件路径。
- task_type: 选择任务类型,可选有抽取(“ext”)和分类(“cls”)两种类型的任务。
- save_dir: 训练数据的保存目录,默认存储在 data 目录下。
- negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为 5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。
- splits: 划分数据集时训练集、验证集、测试集所占的比例。默认为 [0.8, 0.1, 0.1] 。
- options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为 [“正向”, “负向”]。
- prompt_prefix: 声明分类任务的 prompt 前缀信息,该参数只对分类类型任务有效。默认为 “情感倾向”。
- is_shuffle: 是否对数据集进行随机打散,默认为 True。
- seed: 随机种子,默认为 1000。
- separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度级分类任务有效。默认为 “##”。
注:
- 每次执行 doccano.py 脚本,将会覆盖已有的同名数据文件。
3.2 Finetune
在终端中执行以下脚本进行模型微调。
# 然后在终端中执行以下脚本,对 doccano 格式的数据文件进行处理,执行后会在 /home/data 目录下生成训练/验证/测试集文件。
!python finetune.py \
--train_path "./data/train.txt" \
--dev_path "./data/dev.txt" \
--save_dir "./checkpoint" \
--learning_rate 1e-5 \
--batch_size 32 \
--max_seq_len 512 \
--num_epochs 100 \
--model "uie-base" \
--seed 1000 \
--logging_steps 100 \
--valid_steps 100 \
--device "gpu"
[2023-03-27 16:47:58,806] [ INFO] - Downloading resource files...
[2023-03-27 16:47:58,810] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'uie-base'.
W0327 16:47:58.836591 13399 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0327 16:47:58.839186 13399 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
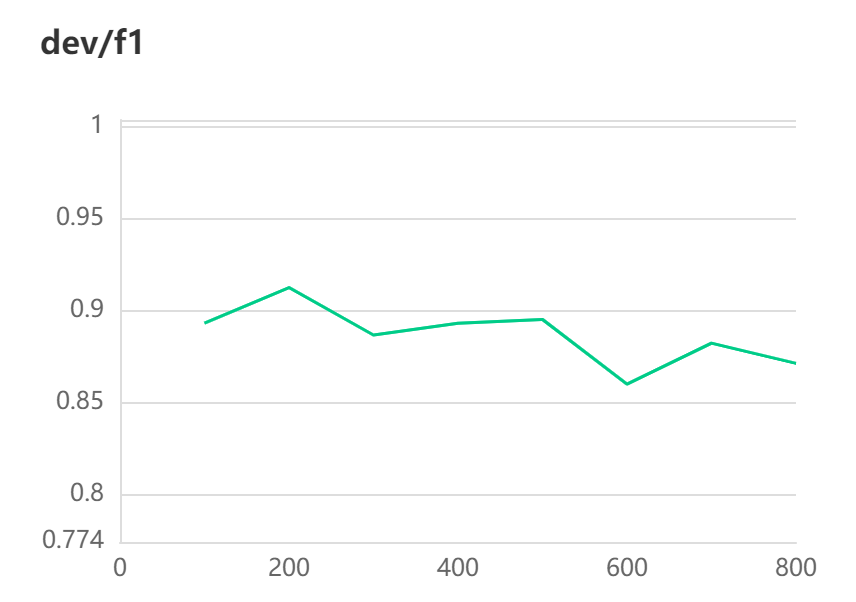
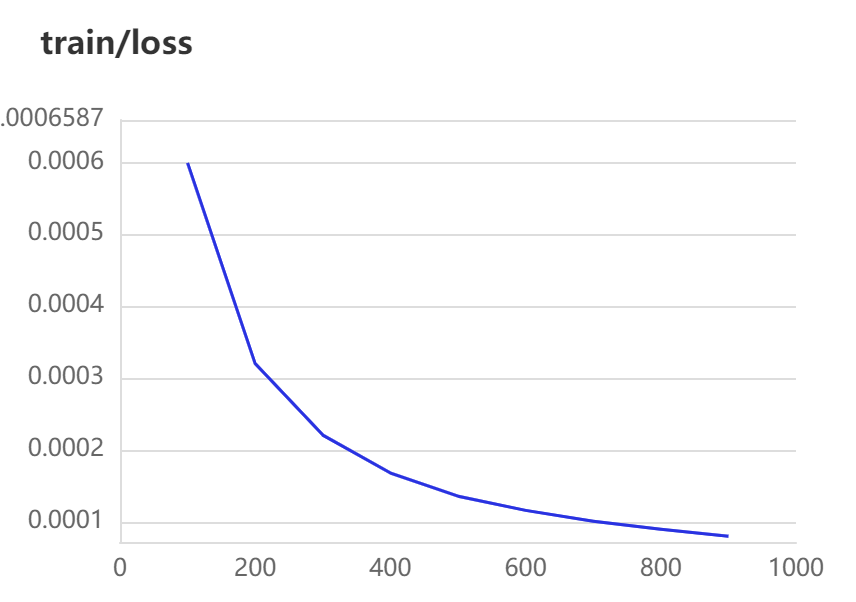
[2023-03-27 16:48:30,349] [ INFO] - global step 100, epoch: 12, loss: 0.00060, speed: 3.46 step/s
[2023-03-27 16:48:30,794] [ INFO] - Evaluation precision: 0.93878, recall: 0.85185, F1: 0.89320
[2023-03-27 16:48:30,794] [ INFO] - best F1 performence has been updated: 0.00000 --> 0.89320
[2023-03-27 16:48:58,054] [ INFO] - global step 200, epoch: 23, loss: 0.00032, speed: 3.82 step/s
[2023-03-27 16:48:58,500] [ INFO] - Evaluation precision: 0.95918, recall: 0.87037, F1: 0.91262
[2023-03-27 16:48:58,500] [ INFO] - best F1 performence has been updated: 0.89320 --> 0.91262
[2023-03-27 16:49:25,664] [ INFO] - global step 300, epoch: 34, loss: 0.00022, speed: 3.83 step/s
[2023-03-27 16:49:26,107] [ INFO] - Evaluation precision: 0.90385, recall: 0.87037, F1: 0.88679
[2023-03-27 16:49:52,155] [ INFO] - global step 400, epoch: 45, loss: 0.00017, speed: 3.84 step/s
[2023-03-27 16:49:52,601] [ INFO] - Evaluation precision: 0.93878, recall: 0.85185, F1: 0.89320
[2023-03-27 16:50:18,632] [ INFO] - global step 500, epoch: 56, loss: 0.00014, speed: 3.84 step/s
[2023-03-27 16:50:19,075] [ INFO] - Evaluation precision: 0.92157, recall: 0.87037, F1: 0.89524
[2023-03-27 16:50:45,077] [ INFO] - global step 600, epoch: 67, loss: 0.00012, speed: 3.85 step/s
[2023-03-27 16:50:45,523] [ INFO] - Evaluation precision: 0.93478, recall: 0.79630, F1: 0.86000
[2023-03-27 16:51:11,546] [ INFO] - global step 700, epoch: 78, loss: 0.00010, speed: 3.84 step/s
[2023-03-27 16:51:11,987] [ INFO] - Evaluation precision: 0.93750, recall: 0.83333, F1: 0.88235
[2023-03-27 16:51:38,013] [ INFO] - global step 800, epoch: 89, loss: 0.00009, speed: 3.84 step/s
[2023-03-27 16:51:38,457] [ INFO] - Evaluation precision: 0.93617, recall: 0.81481, F1: 0.87129
[2023-03-27 16:52:04,361] [ INFO] - global step 900, epoch: 100, loss: 0.00008, speed: 3.86 step/s
[2023-03-27 16:52:04,808] [ INFO] - Evaluation precision: 0.95745, recall: 0.83333, F1: 0.89109
结果展示:
参数说明:
- train_path: 训练集文件路径。
- dev_path: 验证集文件路径。
- save_dir: 模型存储路径,默认为 “./checkpoint”。
- learning_rate: 学习率,默认为 1e-5。
- batch_size: 批处理大小,请结合机器情况进行调整,默认为 16。
- max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为 512。
- num_epochs: 训练轮数,默认为 100。
- model: 选择模型,程序会基于选择的模型进行模型微调,可选有 “uie-base”, “uie-medium”, “uie-mini”, “uie-micro” 和 “uie-nano”,默认为 “uie-base”。
- seed: 随机种子,默认为 1000。
- logging_steps: 日志打印的间隔 steps 数,默认为 10。
- valid_steps: evaluate 的间隔 steps 数,默认为 100。
- device: 选用什么设备进行训练,可选 “cpu” 或 “gpu”。
- init_from_ckpt: 初始化模型参数的路径,可从断点处继续训练。
3.3 模型评估
在终端中执行以下脚本进行模型评估。
输出示例:
参数说明:
- model_path: 进行评估的模型文件夹路径,路径下需包含模型权重文件 model_state.pdparams 及配置文件 model_config.json。
- test_path: 进行评估的测试集文件。
- batch_size: 批处理大小,请结合机器情况进行调整,默认为 16。
- max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为 512。
- debug: 是否开启 debug 模式对每个正例类别分别进行评估,该模式仅用于模型调试,默认关闭。
debug 模式输出示例:
!python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/dev.txt \
--batch_size 16 \
--max_seq_len 512
[2023-03-27 16:56:21,832] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'.
W0327 16:56:21.863559 15278 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0327 16:56:21.866312 15278 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2023-03-27 16:56:27,409] [ INFO] - -----------------------------
[2023-03-27 16:56:27,409] [ INFO] - Class Name: all_classes
[2023-03-27 16:56:27,409] [ INFO] - Evaluation Precision: 0.95918 | Recall: 0.87037 | F1: 0.91262
!python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/dev.txt \
--debug
[2023-03-27 16:56:31,824] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'.
W0327 16:56:31.856709 15361 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0327 16:56:31.859668 15361 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2023-03-27 16:56:37,039] [ INFO] - -----------------------------
[2023-03-27 16:56:37,039] [ INFO] - Class Name: 时间
[2023-03-27 16:56:37,039] [ INFO] - Evaluation Precision: 1.00000 | Recall: 0.90000 | F1: 0.94737
[2023-03-27 16:56:37,092] [ INFO] - -----------------------------
[2023-03-27 16:56:37,092] [ INFO] - Class Name: 地名
[2023-03-27 16:56:37,092] [ INFO] - Evaluation Precision: 0.95833 | Recall: 0.85185 | F1: 0.90196
[2023-03-27 16:56:37,113] [ INFO] - -----------------------------
[2023-03-27 16:56:37,113] [ INFO] - Class Name: 产品
[2023-03-27 16:56:37,113] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2023-03-27 16:56:37,139] [ INFO] - -----------------------------
[2023-03-27 16:56:37,139] [ INFO] - Class Name: 组织
[2023-03-27 16:56:37,139] [ INFO] - Evaluation Precision: 1.00000 | Recall: 0.50000 | F1: 0.66667
[2023-03-27 16:56:37,161] [ INFO] - -----------------------------
[2023-03-27 16:56:37,161] [ INFO] - Class Name: 人名
[2023-03-27 16:56:37,161] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2023-03-27 16:56:37,181] [ INFO] - -----------------------------
[2023-03-27 16:56:37,181] [ INFO] - Class Name: 天气
[2023-03-27 16:56:37,181] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2023-03-27 16:56:37,198] [ INFO] - -----------------------------
[2023-03-27 16:56:37,198] [ INFO] - Class Name: 价格
[2023-03-27 16:56:37,198] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
3.4 微调后效果
my_ie = Taskflow("information_extraction", schema=schema, task_path='./checkpoint/model_best') # task_path 指定模型权重文件的路径
pprint(my_ie("2K 与 Gearbox Software 宣布,《小缇娜的奇幻之地》将于 6 月 24 日凌晨 1 点登录 Steam,此前 PC 平台为 Epic 限时独占。在限定期间内,Steam 玩家可以在 Steam 入手《小缇娜的奇幻之地》,并在 2022 年 7 月 8 日前享有获得黄金英雄铠甲包。"))
[2023-03-27 16:59:31,064] [ INFO] - Converting to the inference model cost a little time.
[2023-03-27 16:59:38,171] [ INFO] - The inference model save in the path:./checkpoint/model_best/static/inference
[2023-03-27 16:59:40,364] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'.
[{'产品': [{'end': 118,
'probability': 0.9860373472963602,
'start': 108,
'text': '《小缇娜的奇幻之地》'},
{'end': 35,
'probability': 0.9870597349192849,
'start': 25,
'text': '《小缇娜的奇幻之地》'},
{'end': 148,
'probability': 0.9075982731610566,
'start': 141,
'text': '黄金英雄铠甲包'}],
'时间': [{'end': 52,
'probability': 0.9998029564426645,
'start': 38,
'text': '6 月 24 日凌晨 1 点'},
{'end': 137,
'probability': 0.9876786236837809,
'start': 122,
'text': '2022 年 7 月 8 日前'}],
'组织': [{'end': 2, 'probability': 0.988802896329716, 'start': 0, 'text': '2K'},
{'end': 93,
'probability': 0.9500440898664806,
'start': 88,
'text': 'Steam'},
{'end': 75,
'probability': 0.9819772965571794,
'start': 71,
'text': 'Epic'},
{'end': 105,
'probability': 0.7921079762008958,
'start': 100,
'text': 'Steam'},
{'end': 60,
'probability': 0.9829542747088276,
'start': 55,
'text': 'Steam'},
{'end': 21,
'probability': 0.9994613042455924,
'start': 5,
'text': 'Gearbox Software'}]}]
pprint(my_ie("近日,量子计算专家、ACM计算奖得主Scott Aaronson通过博客宣布,将于本周离开得克萨斯大学奥斯汀分校(UT Austin)一年,并加盟人工智能研究公司OpenAI。"))
[{'人名': [{'end': 32,
'probability': 0.9990170436659866,
'start': 18,
'text': 'Scott Aaronson'}],
'时间': [{'end': 2,
'probability': 0.9998477751029782,
'start': 0,
'text': '近日'},
{'end': 43,
'probability': 0.9995671774285029,
'start': 41,
'text': '本周'}],
'组织': [{'end': 66,
'probability': 0.9900270615638647,
'start': 57,
'text': 'UT Austin'},
{'end': 87,
'probability': 0.9993388552686611,
'start': 81,
'text': 'OpenAI'},
{'end': 56,
'probability': 0.9968586409231648,
'start': 45,
'text': '得克萨斯大学奥斯汀分校'},
{'end': 13,
'probability': 0.8437228020724348,
'start': 10,
'text': 'ACM'}]}]
基于 50 条标注数据进行模型微调后,效果有所提升。
4.基于Label Studio的智能标注(含自动训练)
部分效果展示更多详细内容查看链接:
人工智能知识图谱之信息抽取:基于Labelstudio的UIE半监督深度学习的智能标注方案(云端版),提效。
里面有详细代码实现
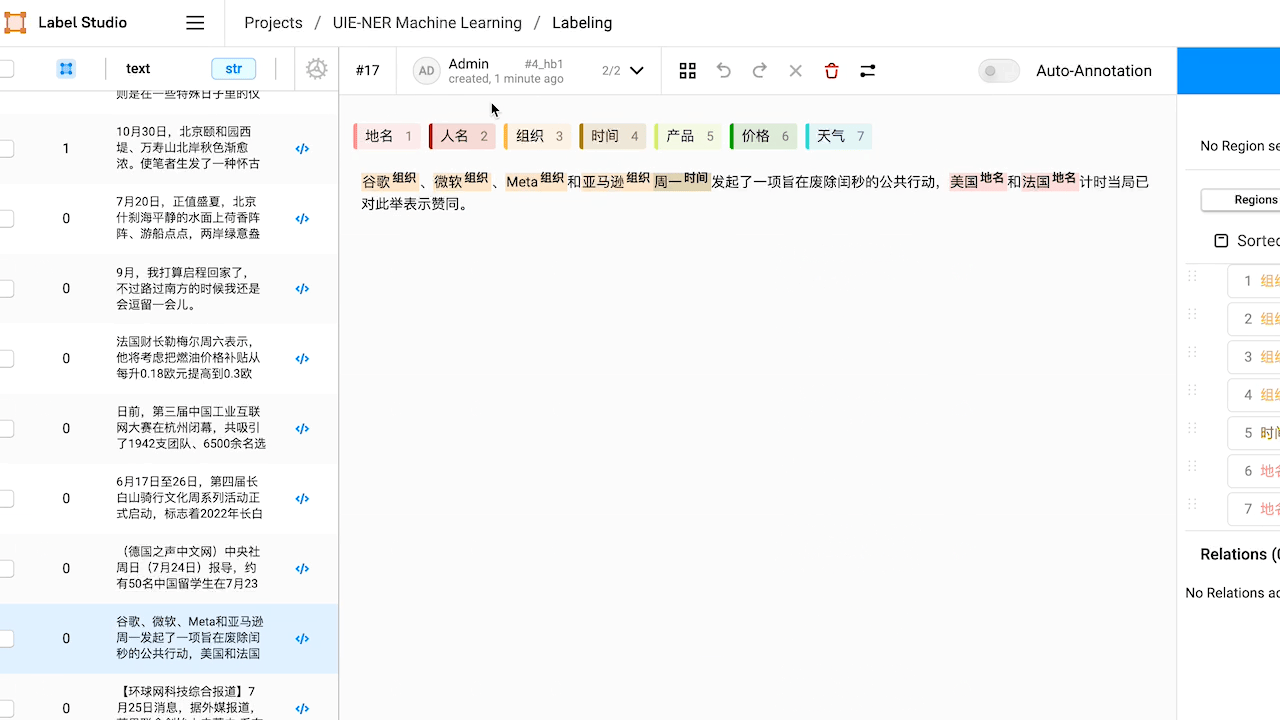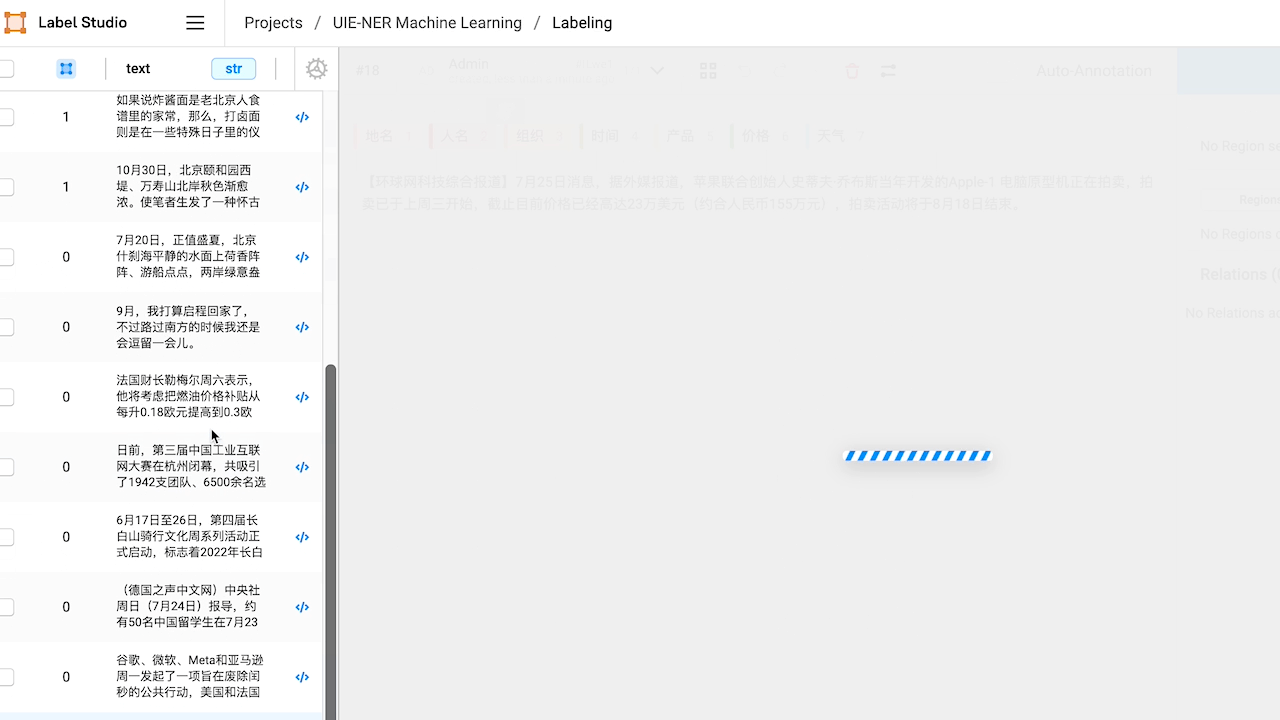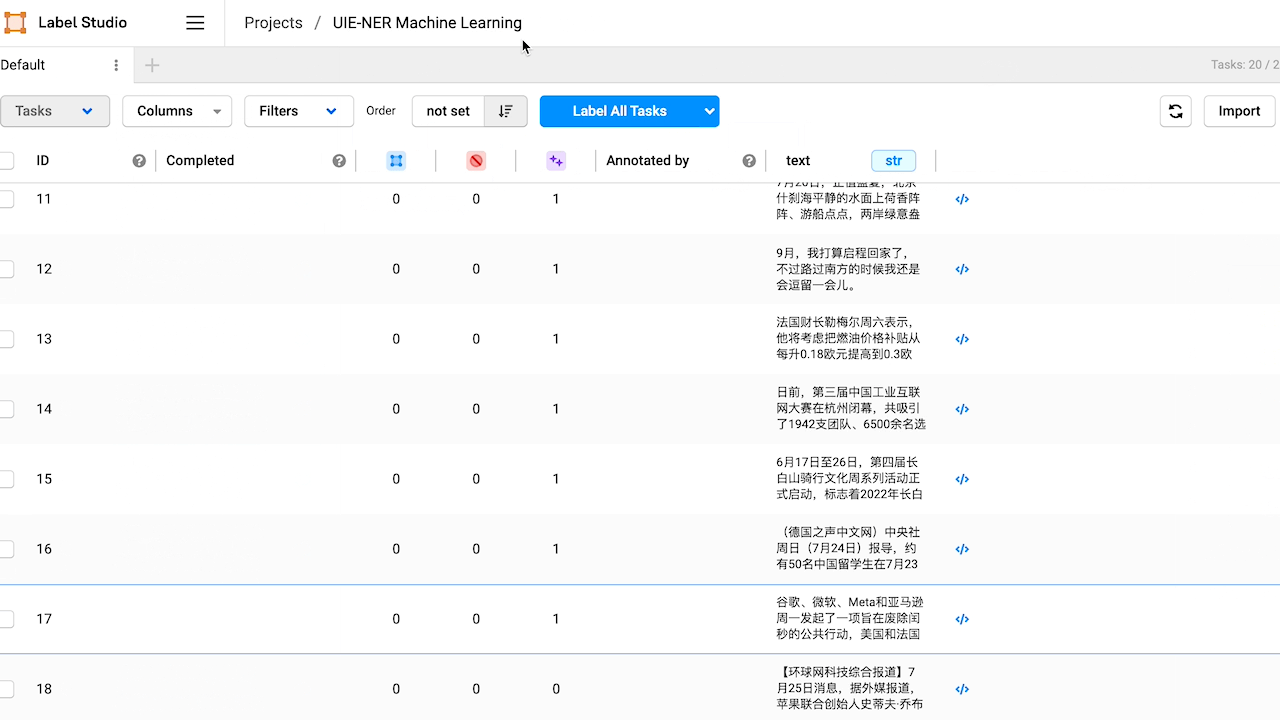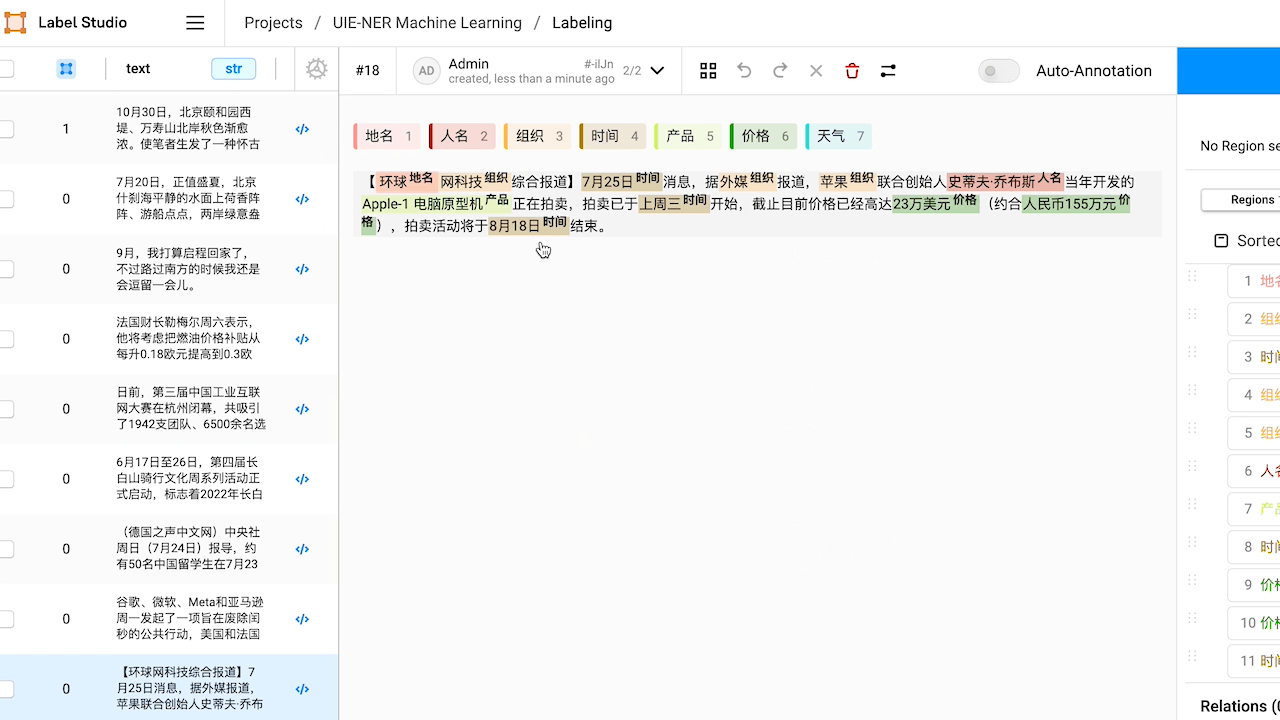
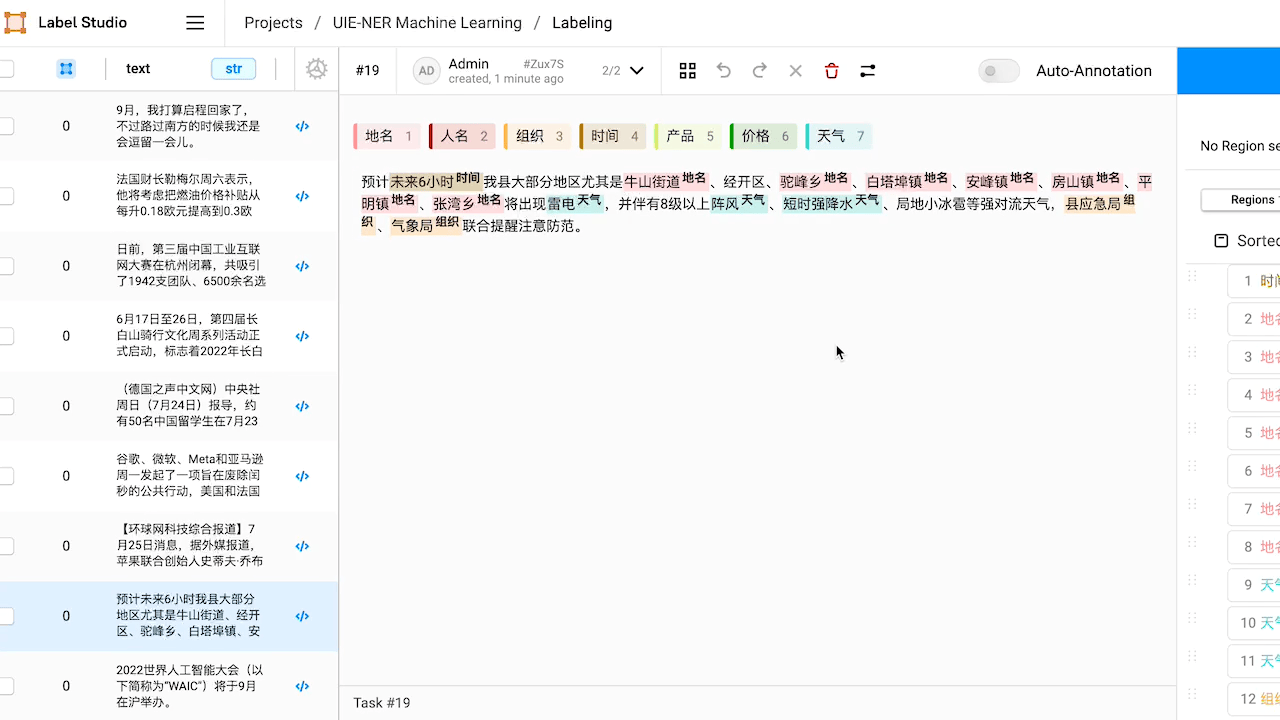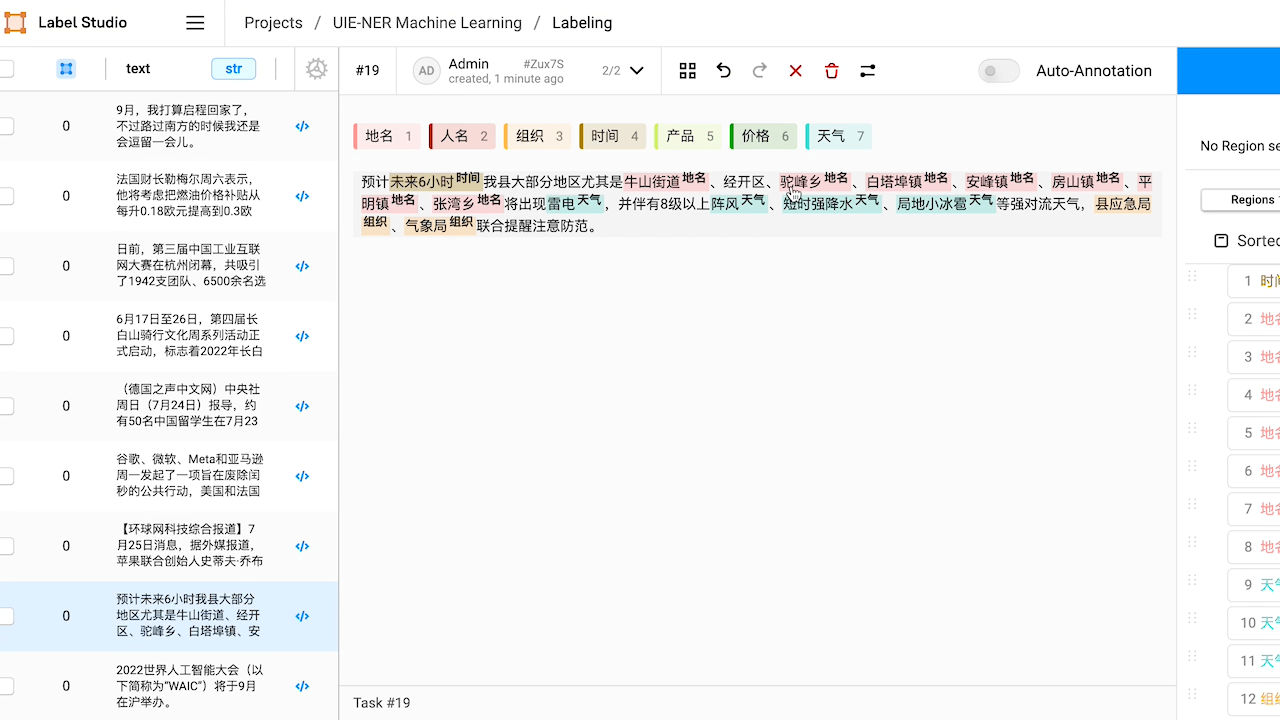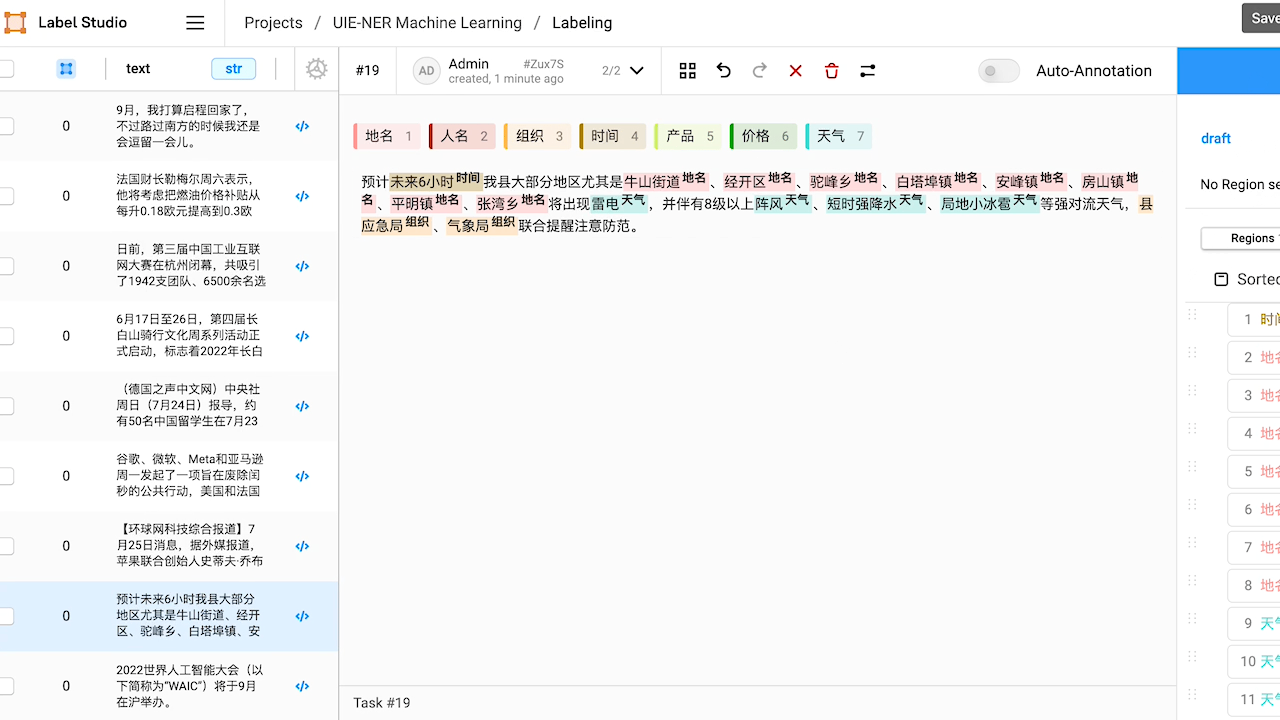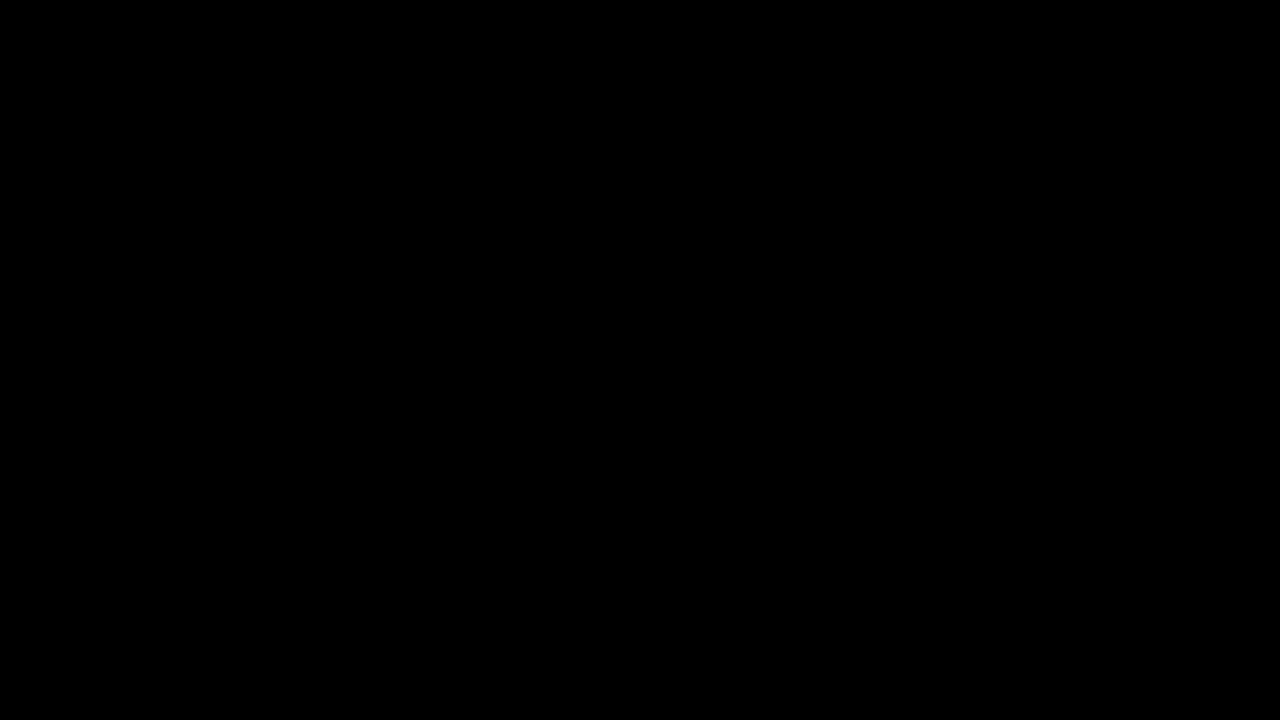
查看预标注好的数据,如有必要,对标注进行修改。


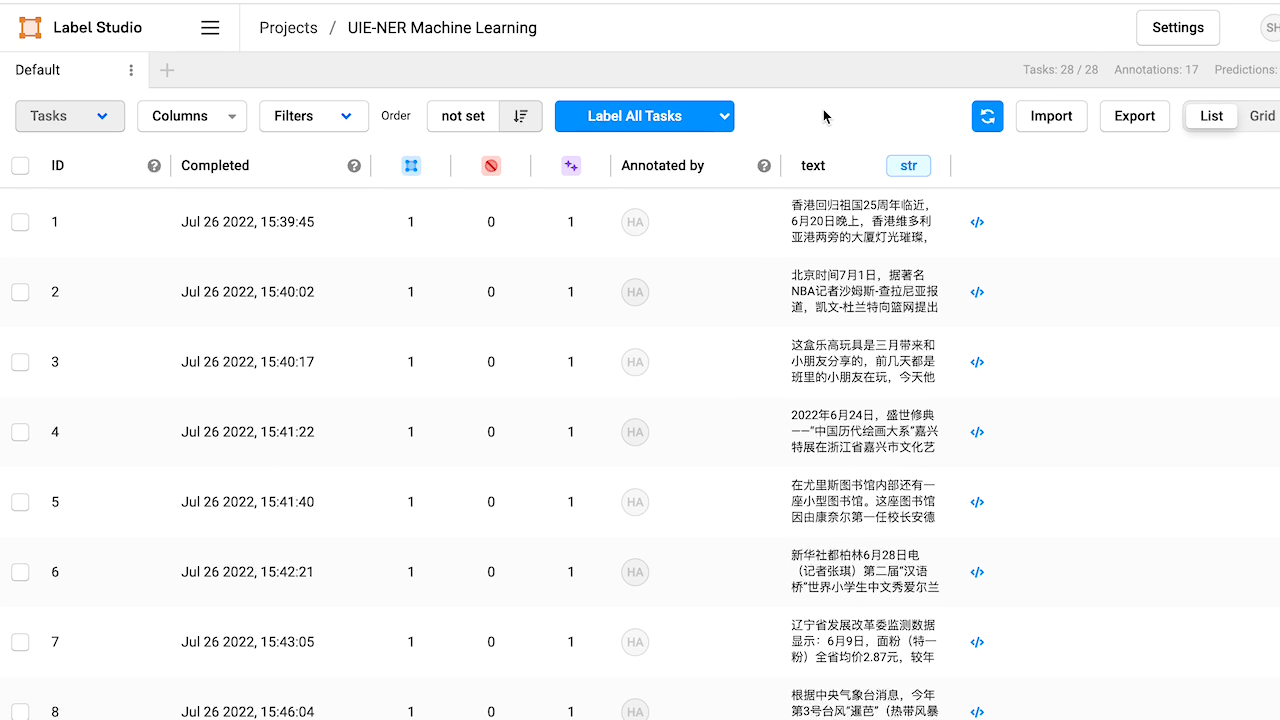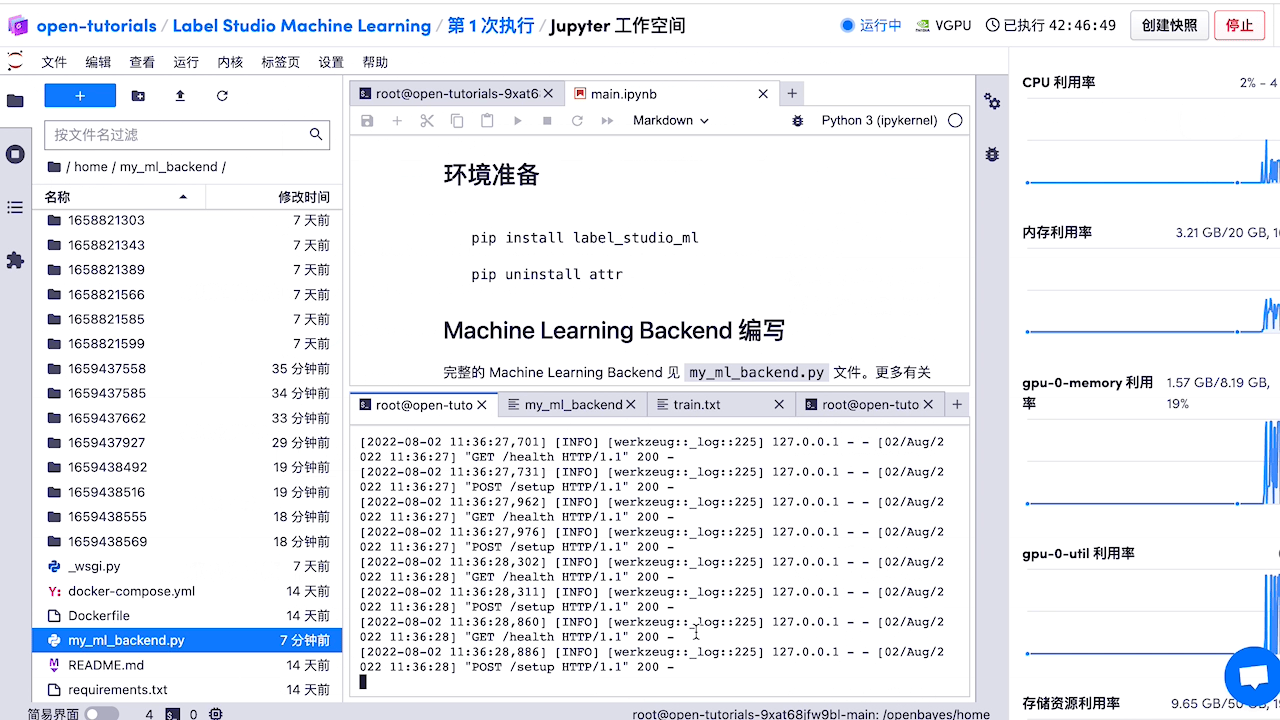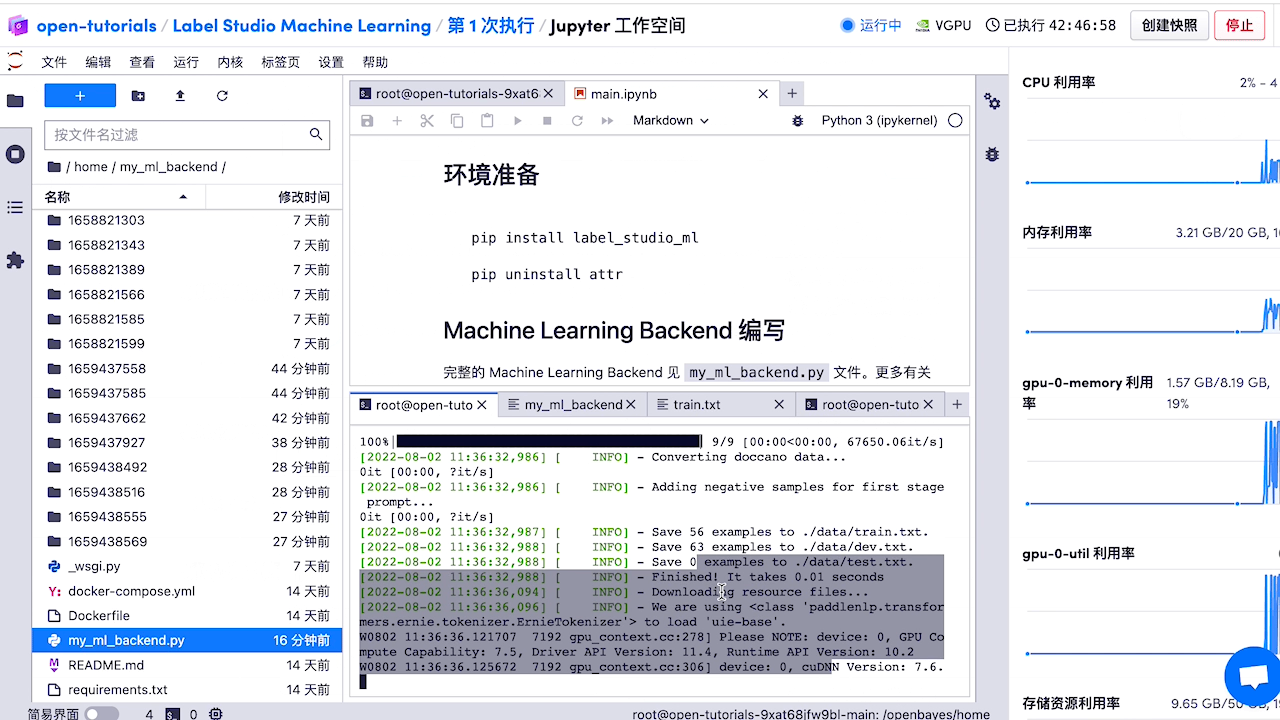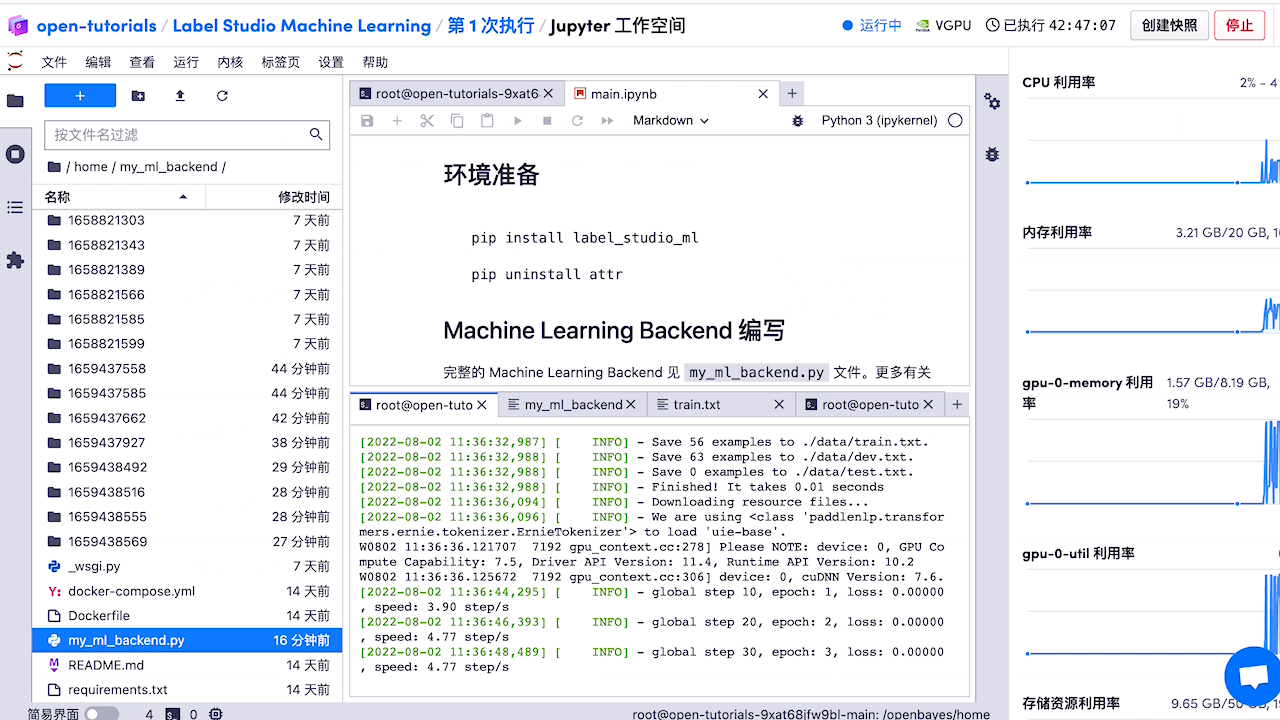
5.模型部署
以下是 UIE Python 端的部署流程,包括环境准备、模型导出和使用示例。
5.1 UIE Python 端的部署流程
-
模型导出
模型训练、压缩时已经自动进行了静态图的导出以及 tokenizer 配置文件保存,保存路径${finetuned_model} 下应该有 .pdimodel、.pdiparams 模型文件可用于推理。 -
模型部署
以下示例展示如何基于 FastDeploy 库完成 UIE 模型完成通用信息抽取任务的 Python 预测部署。先参考 UIE 模型部署安装FastDeploy Python 依赖包。 可通过命令行参数–device以及–backend指定运行在不同的硬件以及推理引擎后端,并使用–model_dir参数指定运行的模型。模型目录为 model_zoo/uie/checkpoint/model_best(用户可按实际情况设置)。
FastDeploy提供各平台预编译库,供开发者直接下载安装使用。当然FastDeploy编译也非常容易,开发者也可根据自身需求编译FastDeploy。
GPU端
为了在GPU上获得最佳的推理性能和稳定性,请先确保机器已正确安装NVIDIA相关驱动和基础软件,确保CUDA >= 11.2,cuDNN >= 8.1.1,并使用以下命令安装所需依赖
python部署比较常规就不展开:参考模型部署
5.2 Serving 服务编写
编写 predictor.py 文件:
-
导入依赖库:除了业务中用到的库之外,需要额外依赖serving。
-
后处理(可选):根据需要对模型返回的结果进行处理,以更好地展示。本教程中通过
format()函数和add_o()函数修改命名实体识别结果的形式。 -
Predictor 类: 不需要继承其他的类,但是至少需要提供
__init__和predict两个接口。- 在
__init__中定义实体抽取结构,通过Taskflow加载模型。 - 在
predict中进行预测,返回后处理的结果。
- 在
class Predictor:
def __init__(self):
self.schema = ['地名', '人名', '组织', '时间', '产品', '价格', '天气']
self.ie = Taskflow("information_extraction", schema=self.schema, task_path='./checkpoint/model_best')
def predict(self, json):
text = json["input"]
uie = self.ie(text)[0]
result = format(text, uie)
return result
- 运行:启动服务。
if __name__ == '__main__':
serv.run(Predictor)
在项目根目录下已经提供了编写好的 predictor.py 可以直接在后续使用。
# !paddlenlp server server:app --workers 1 --host 0.0.0.0 --port 8189
# !pip install --upgrade paddlenlp
# import json
# import requests
# url = "http://0.0.0.0:8189/taskflow/uie"
# headers = {"Content-Type": "application/json"}
# texts = ["近日,量子计算专家、ACM计算奖得主Scott Aaronson通过博客宣布,将于本周离开得克萨斯大学奥斯汀分校(UT Austin)一年,并加盟人工智能研究公司OpenAI"]
# data = {
# "data": {
# "text": texts,
# }
# }
# r = requests.post(url=url, headers=headers, data=json.dumps(data))
# datas = json.loads(r.text)
# print(datas)
note:部署环节请在本地上调试,更多详情参考:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
6.总结
- Label Studio 所提供的 Machine Learning Backend 提供了一个比较灵活的辅助人工标注的框架,我们通过它确实可以加快 nlp 数据的标注
- Label Studio 的 enterprise 版本提供了 Active Learning 的流程,不过从其描述看这个流程并不完美,尤其是 fit 部分,由于 Label Studio 低估了「Train」所花费的时间,所以每次标注都自动训练的流程可能并不会那么顺滑(会在链接时候等待一段时间)
- 这次项目并没有使用 Label Studio 所提供的「Auto-Annotation」的功能,因为它存在重复标注的问题
- 既然 Label Studio 提供了它的 api 那其实可玩的东西还是很多的,配合 webhook 等内容可能会让这个标注和训练的流程做的更加高效
此外目前使用的UIE码源是前几个版本的,最新官网更新了一些训练升级API,后续再重新优化现有项目。
本人对容器相关技术不太了解,所以在一些容器化技术操作上更多就是借鉴使用了,如有疑问评论区留言即可。
更多详情请参考Label Studio官网:
6.1 项目链接
部分效果展示更多详细内容查看链接:
人工智能知识图谱之信息抽取:基于Labelstudio的UIE半监督深度学习的智能标注方案(云端版),提效。
里面有详细代码实现

- 点赞
- 收藏
- 关注作者
评论(0)