机器学习实战系列[一]:工业蒸汽量预测(最新版本上篇)含数据探索特征工程等

机器学习实战系列[一]:工业蒸汽量预测
- 背景介绍
火力发电的基本原理是:燃料在燃烧时加热水生成蒸汽,蒸汽压力推动汽轮机旋转,然后汽轮机带动发电机旋转,产生电能。在这一系列的能量转化中,影响发电效率的核心是锅炉的燃烧效率,即燃料燃烧加热水产生高温高压蒸汽。锅炉的燃烧效率的影响因素很多,包括锅炉的可调参数,如燃烧给量,一二次风,引风,返料风,给水水量;以及锅炉的工况,比如锅炉床温、床压,炉膛温度、压力,过热器的温度等。
- 相关描述
经脱敏后的锅炉传感器采集的数据(采集频率是分钟级别),根据锅炉的工况,预测产生的蒸汽量。
- 数据说明
数据分成训练数据(train.txt)和测试数据(test.txt),其中字段”V0”-“V37”,这38个字段是作为特征变量,”target”作为目标变量。选手利用训练数据训练出模型,预测测试数据的目标变量,排名结果依据预测结果的MSE(mean square error)。
- 结果评估
预测结果以mean square error作为评判标准。
原项目链接:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc
1.数据探索性分析
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
# 下载需要用到的数据集
!wget http://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/Industrial_Steam_Forecast/zhengqi_test.txt
!wget http://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/Industrial_Steam_Forecast/zhengqi_train.txt
# **读取数据文件**
# 使用Pandas库`read_csv()`函数进行数据读取,分割符为‘\t’
train_data_file = "./zhengqi_train.txt"
test_data_file = "./zhengqi_test.txt"
train_data = pd.read_csv(train_data_file, sep='\t', encoding='utf-8')
test_data = pd.read_csv(test_data_file, sep='\t', encoding='utf-8')
1.1 查看数据信息
#查看特征变量信息
train_data.info()
此训练集数据共有2888个样本,数据中有V0-V37共计38个特征变量,变量类型都为数值类型,所有数据特征没有缺失值数据;
数据字段由于采用了脱敏处理,删除了特征数据的具体含义;target字段为标签变量
```python
test_data.info()
测试集数据共有1925个样本,数据中有V0-V37共计38个特征变量,变量类型都为数值类型
# 查看数据统计信息
train_data.describe()
test_data.describe()
上面数据显示了数据的统计信息,例如样本数,数据的均值mean,标准差std,最小值,最大值等
# 查看数据字段信息
train_data.head()
上面显示训练集前5条数据的基本信息,可以看到数据都是浮点型数据,数据都是数值型连续型特征
test_data.head()
1.2 可视化探索数据
fig = plt.figure(figsize=(4, 6)) # 指定绘图对象宽度和高度
sns.boxplot(train_data['V0'],orient="v", width=0.5)
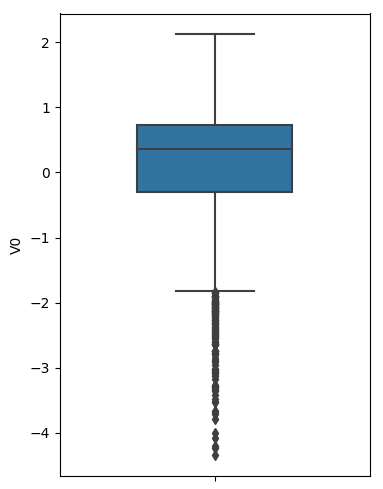
# 画箱式图
# column = train_data.columns.tolist()[:39] # 列表头
# fig = plt.figure(figsize=(20, 40)) # 指定绘图对象宽度和高度
# for i in range(38):
# plt.subplot(13, 3, i + 1) # 13行3列子图
# sns.boxplot(train_data[column[i]], orient="v", width=0.5) # 箱式图
# plt.ylabel(column[i], fontsize=8)
# plt.show()
#箱图自行打开
查看数据分布图
- 查看特征变量‘V0’的数据分布直方图,并绘制Q-Q图查看数据是否近似于正态分布
plt.figure(figsize=(10,5))
ax=plt.subplot(1,2,1)
sns.distplot(train_data['V0'],fit=stats.norm)
ax=plt.subplot(1,2,2)
res = stats.probplot(train_data['V0'], plot=plt)
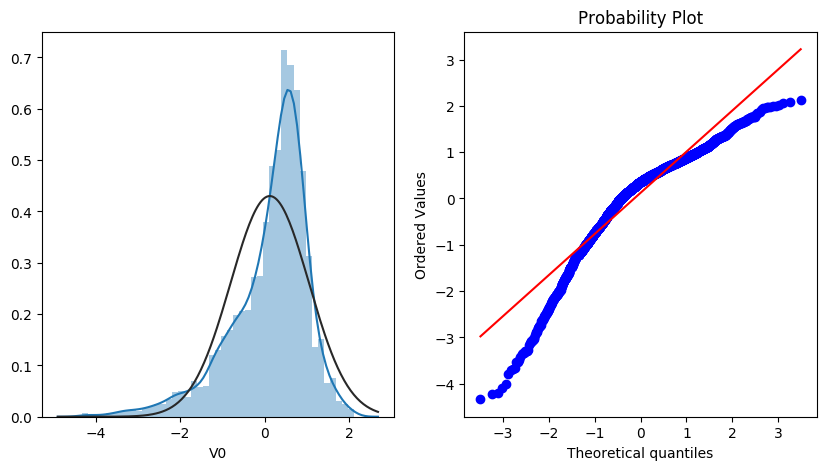
查看查看所有数据的直方图和Q-Q图,查看训练集的数据是否近似于正态分布
# train_cols = 6
# train_rows = len(train_data.columns)
# plt.figure(figsize=(4*train_cols,4*train_rows))
# i=0
# for col in train_data.columns:
# i+=1
# ax=plt.subplot(train_rows,train_cols,i)
# sns.distplot(train_data[col],fit=stats.norm)
# i+=1
# ax=plt.subplot(train_rows,train_cols,i)
# res = stats.probplot(train_data[col], plot=plt)
# plt.show()
#QQ图自行打开
由上面的数据分布图信息可以看出,很多特征变量(如’V1’,‘V9’,‘V24’,'V28’等)的数据分布不是正态的,数据并不跟随对角线,后续可以使用数据变换对数据进行转换。
对比同一特征变量‘V0’下,训练集数据和测试集数据的分布情况,查看数据分布是否一致
ax = sns.kdeplot(train_data['V0'], color="Red", shade=True)
ax = sns.kdeplot(test_data['V0'], color="Blue", shade=True)
ax.set_xlabel('V0')
ax.set_ylabel("Frequency")
ax = ax.legend(["train","test"])
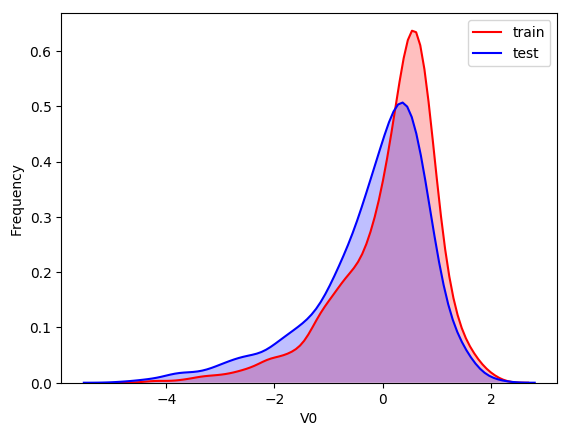
查看所有特征变量下,训练集数据和测试集数据的分布情况,分析并寻找出数据分布不一致的特征变量。
# dist_cols = 6
# dist_rows = len(test_data.columns)
# plt.figure(figsize=(4*dist_cols,4*dist_rows))
# i=1
# for col in test_data.columns:
# ax=plt.subplot(dist_rows,dist_cols,i)
# ax = sns.kdeplot(train_data[col], color="Red", shade=True)
# ax = sns.kdeplot(test_data[col], color="Blue", shade=True)
# ax.set_xlabel(col)
# ax.set_ylabel("Frequency")
# ax = ax.legend(["train","test"])
# i+=1
# plt.show()
#自行打开
查看特征’V5’, ‘V17’, ‘V28’, ‘V22’, ‘V11’, 'V9’数据的数据分布
drop_col = 6
drop_row = 1
plt.figure(figsize=(5*drop_col,5*drop_row))
i=1
for col in ["V5","V9","V11","V17","V22","V28"]:
ax =plt.subplot(drop_row,drop_col,i)
ax = sns.kdeplot(train_data[col], color="Red", shade=True)
ax = sns.kdeplot(test_data[col], color="Blue", shade=True)
ax.set_xlabel(col)
ax.set_ylabel("Frequency")
ax = ax.legend(["train","test"])
i+=1
plt.show()

由上图的数据分布可以看到特征’V5’,‘V9’,‘V11’,‘V17’,‘V22’,‘V28’ 训练集数据与测试集数据分布不一致,会导致模型泛化能力差,采用删除此类特征方法。
drop_columns = ['V5','V9','V11','V17','V22','V28']
# 合并训练集和测试集数据,并可视化训练集和测试集数据特征分布图
可视化线性回归关系
- 查看特征变量‘V0’与’target’变量的线性回归关系
fcols = 2
frows = 1
plt.figure(figsize=(8,4))
ax=plt.subplot(1,2,1)
sns.regplot(x='V0', y='target', data=train_data, ax=ax,
scatter_kws={'marker':'.','s':3,'alpha':0.3},
line_kws={'color':'k'});
plt.xlabel('V0')
plt.ylabel('target')
ax=plt.subplot(1,2,2)
sns.distplot(train_data['V0'].dropna())
plt.xlabel('V0')
plt.show()
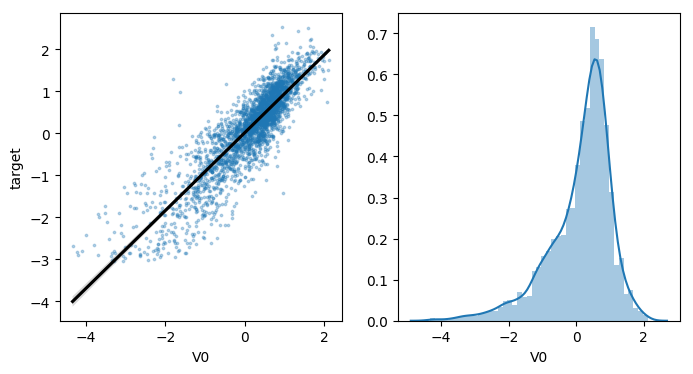
1.2.2 查看变量间线性回归关系
# fcols = 6
# frows = len(test_data.columns)
# plt.figure(figsize=(5*fcols,4*frows))
# i=0
# for col in test_data.columns:
# i+=1
# ax=plt.subplot(frows,fcols,i)
# sns.regplot(x=col, y='target', data=train_data, ax=ax,
# scatter_kws={'marker':'.','s':3,'alpha':0.3},
# line_kws={'color':'k'});
# plt.xlabel(col)
# plt.ylabel('target')
# i+=1
# ax=plt.subplot(frows,fcols,i)
# sns.distplot(train_data[col].dropna())
# plt.xlabel(col)
#已注释图片生成,自行打开
1.2.2 查看特征变量的相关性
data_train1 = train_data.drop(['V5','V9','V11','V17','V22','V28'],axis=1)
train_corr = data_train1.corr()
train_corr
# 画出相关性热力图
ax = plt.subplots(figsize=(20, 16))#调整画布大小
ax = sns.heatmap(train_corr, vmax=.8, square=True, annot=True)#画热力图 annot=True 显示系数
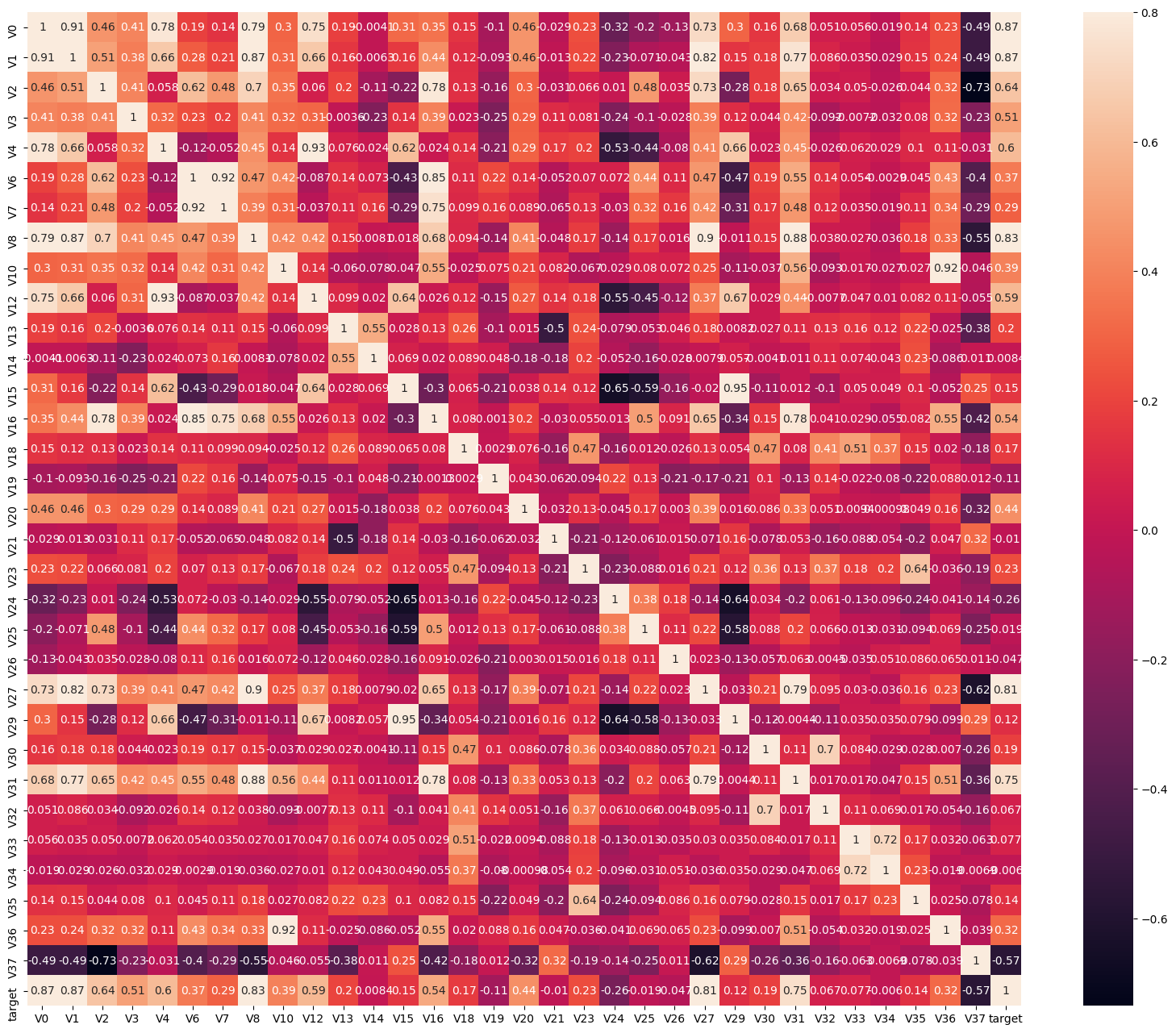
# 找出相关程度
data_train1 = train_data.drop(['V5','V9','V11','V17','V22','V28'],axis=1)
plt.figure(figsize=(20, 16)) # 指定绘图对象宽度和高度
colnm = data_train1.columns.tolist() # 列表头
mcorr = data_train1[colnm].corr(method="spearman") # 相关系数矩阵,即给出了任意两个变量之间的相关系数
mask = np.zeros_like(mcorr, dtype=np.bool) # 构造与mcorr同维数矩阵 为bool型
mask[np.triu_indices_from(mask)] = True # 角分线右侧为True
cmap = sns.diverging_palette(220, 10, as_cmap=True) # 返回matplotlib colormap对象
g = sns.heatmap(mcorr, mask=mask, cmap=cmap, square=True, annot=True, fmt='0.2f') # 热力图(看两两相似度)
plt.show()
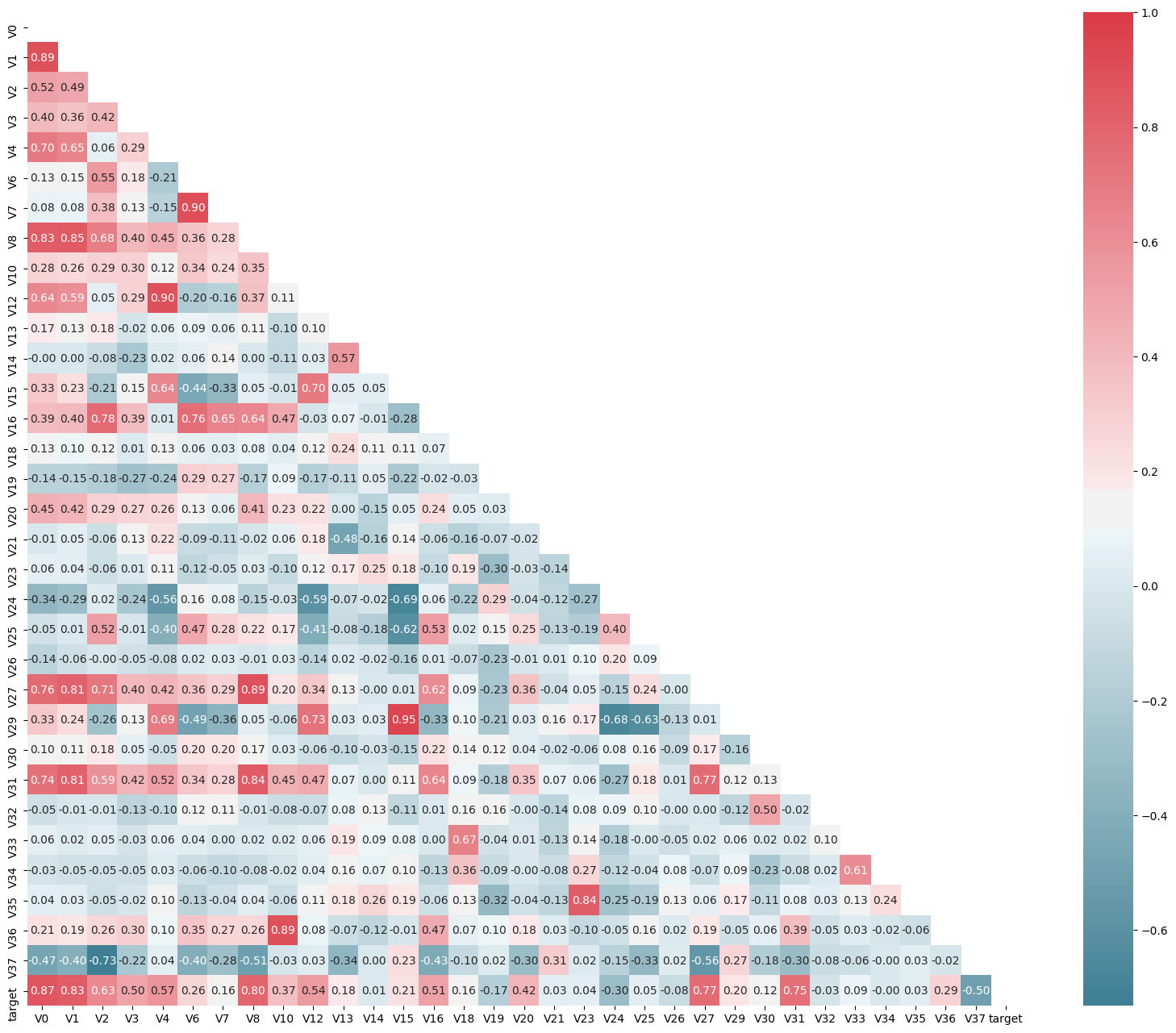
上图为所有特征变量和target变量两两之间的相关系数,由此可以看出各个特征变量V0-V37之间的相关性以及特征变量V0-V37与target的相关性。
1.2.3 查找重要变量
查找出特征变量和target变量相关系数大于0.5的特征变量
#寻找K个最相关的特征信息
k = 10 # number of variables for heatmap
cols = train_corr.nlargest(k, 'target')['target'].index
cm = np.corrcoef(train_data[cols].values.T)
hm = plt.subplots(figsize=(10, 10))#调整画布大小
#hm = sns.heatmap(cm, cbar=True, annot=True, square=True)
#g = sns.heatmap(train_data[cols].corr(),annot=True,square=True,cmap="RdYlGn")
hm = sns.heatmap(train_data[cols].corr(),annot=True,square=True)
plt.show()
threshold = 0.5
corrmat = train_data.corr()
top_corr_features = corrmat.index[abs(corrmat["target"])>threshold]
plt.figure(figsize=(10,10))
g = sns.heatmap(train_data[top_corr_features].corr(),annot=True,cmap="RdYlGn")
drop_columns.clear()
drop_columns = ['V5','V9','V11','V17','V22','V28']
# Threshold for removing correlated variables
threshold = 0.5
# Absolute value correlation matrix
corr_matrix = data_train1.corr().abs()
drop_col=corr_matrix[corr_matrix["target"]<threshold].index
#data_all.drop(drop_col, axis=1, inplace=True)
由于’V14’, ‘V21’, ‘V25’, ‘V26’, ‘V32’, ‘V33’, 'V34’特征的相关系数值小于0.5,故认为这些特征与最终的预测target值不相关,删除这些特征变量;
#merge train_set and test_set
train_x = train_data.drop(['target'], axis=1)
#data_all=pd.concat([train_data,test_data],axis=0,ignore_index=True)
data_all = pd.concat([train_x,test_data])
data_all.drop(drop_columns,axis=1,inplace=True)
#View data
data_all.head()
# normalise numeric columns
cols_numeric=list(data_all.columns)
def scale_minmax(col):
return (col-col.min())/(col.max()-col.min())
data_all[cols_numeric] = data_all[cols_numeric].apply(scale_minmax,axis=0)
data_all[cols_numeric].describe()
#col_data_process = cols_numeric.append('target')
train_data_process = train_data[cols_numeric]
train_data_process = train_data_process[cols_numeric].apply(scale_minmax,axis=0)
test_data_process = test_data[cols_numeric]
test_data_process = test_data_process[cols_numeric].apply(scale_minmax,axis=0)
cols_numeric_left = cols_numeric[0:13]
cols_numeric_right = cols_numeric[13:]
## Check effect of Box-Cox transforms on distributions of continuous variables
train_data_process = pd.concat([train_data_process, train_data['target']], axis=1)
fcols = 6
frows = len(cols_numeric_left)
plt.figure(figsize=(4*fcols,4*frows))
i=0
for var in cols_numeric_left:
dat = train_data_process[[var, 'target']].dropna()
i+=1
plt.subplot(frows,fcols,i)
sns.distplot(dat[var] , fit=stats.norm);
plt.title(var+' Original')
plt.xlabel('')
i+=1
plt.subplot(frows,fcols,i)
_=stats.probplot(dat[var], plot=plt)
plt.title('skew='+'{:.4f}'.format(stats.skew(dat[var])))
plt.xlabel('')
plt.ylabel('')
i+=1
plt.subplot(frows,fcols,i)
plt.plot(dat[var], dat['target'],'.',alpha=0.5)
plt.title('corr='+'{:.2f}'.format(np.corrcoef(dat[var], dat['target'])[0][1]))
i+=1
plt.subplot(frows,fcols,i)
trans_var, lambda_var = stats.boxcox(dat[var].dropna()+1)
trans_var = scale_minmax(trans_var)
sns.distplot(trans_var , fit=stats.norm);
plt.title(var+' Tramsformed')
plt.xlabel('')
i+=1
plt.subplot(frows,fcols,i)
_=stats.probplot(trans_var, plot=plt)
plt.title('skew='+'{:.4f}'.format(stats.skew(trans_var)))
plt.xlabel('')
plt.ylabel('')
i+=1
plt.subplot(frows,fcols,i)
plt.plot(trans_var, dat['target'],'.',alpha=0.5)
plt.title('corr='+'{:.2f}'.format(np.corrcoef(trans_var,dat['target'])[0][1]))
# ## Check effect of Box-Cox transforms on distributions of continuous variables
#已注释图片生成,自行打开
# fcols = 6
# frows = len(cols_numeric_right)
# plt.figure(figsize=(4*fcols,4*frows))
# i=0
# for var in cols_numeric_right:
# dat = train_data_process[[var, 'target']].dropna()
# i+=1
# plt.subplot(frows,fcols,i)
# sns.distplot(dat[var] , fit=stats.norm);
# plt.title(var+' Original')
# plt.xlabel('')
# i+=1
# plt.subplot(frows,fcols,i)
# _=stats.probplot(dat[var], plot=plt)
# plt.title('skew='+'{:.4f}'.format(stats.skew(dat[var])))
# plt.xlabel('')
# plt.ylabel('')
# i+=1
# plt.subplot(frows,fcols,i)
# plt.plot(dat[var], dat['target'],'.',alpha=0.5)
# plt.title('corr='+'{:.2f}'.format(np.corrcoef(dat[var], dat['target'])[0][1]))
# i+=1
# plt.subplot(frows,fcols,i)
# trans_var, lambda_var = stats.boxcox(dat[var].dropna()+1)
# trans_var = scale_minmax(trans_var)
# sns.distplot(trans_var , fit=stats.norm);
# plt.title(var+' Tramsformed')
# plt.xlabel('')
# i+=1
# plt.subplot(frows,fcols,i)
# _=stats.probplot(trans_var, plot=plt)
# plt.title('skew='+'{:.4f}'.format(stats.skew(trans_var)))
# plt.xlabel('')
# plt.ylabel('')
# i+=1
# plt.subplot(frows,fcols,i)
# plt.plot(trans_var, dat['target'],'.',alpha=0.5)
# plt.title('corr='+'{:.2f}'.format(np.corrcoef(trans_var,dat['target'])[0][1]))
2.数据特征工程
2.1数据预处理和特征处理
# 导入数据分析工具包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
# 读取数据
train_data_file = "./zhengqi_train.txt"
test_data_file = "./zhengqi_test.txt"
train_data = pd.read_csv(train_data_file, sep='\t', encoding='utf-8')
test_data = pd.read_csv(test_data_file, sep='\t', encoding='utf-8')
train_data.describe()
#数据总览
2.1.1 异常值分析
#异常值分析
plt.figure(figsize=(18, 10))
plt.boxplot(x=train_data.values,labels=train_data.columns)
plt.hlines([-7.5, 7.5], 0, 40, colors='r')
plt.show()
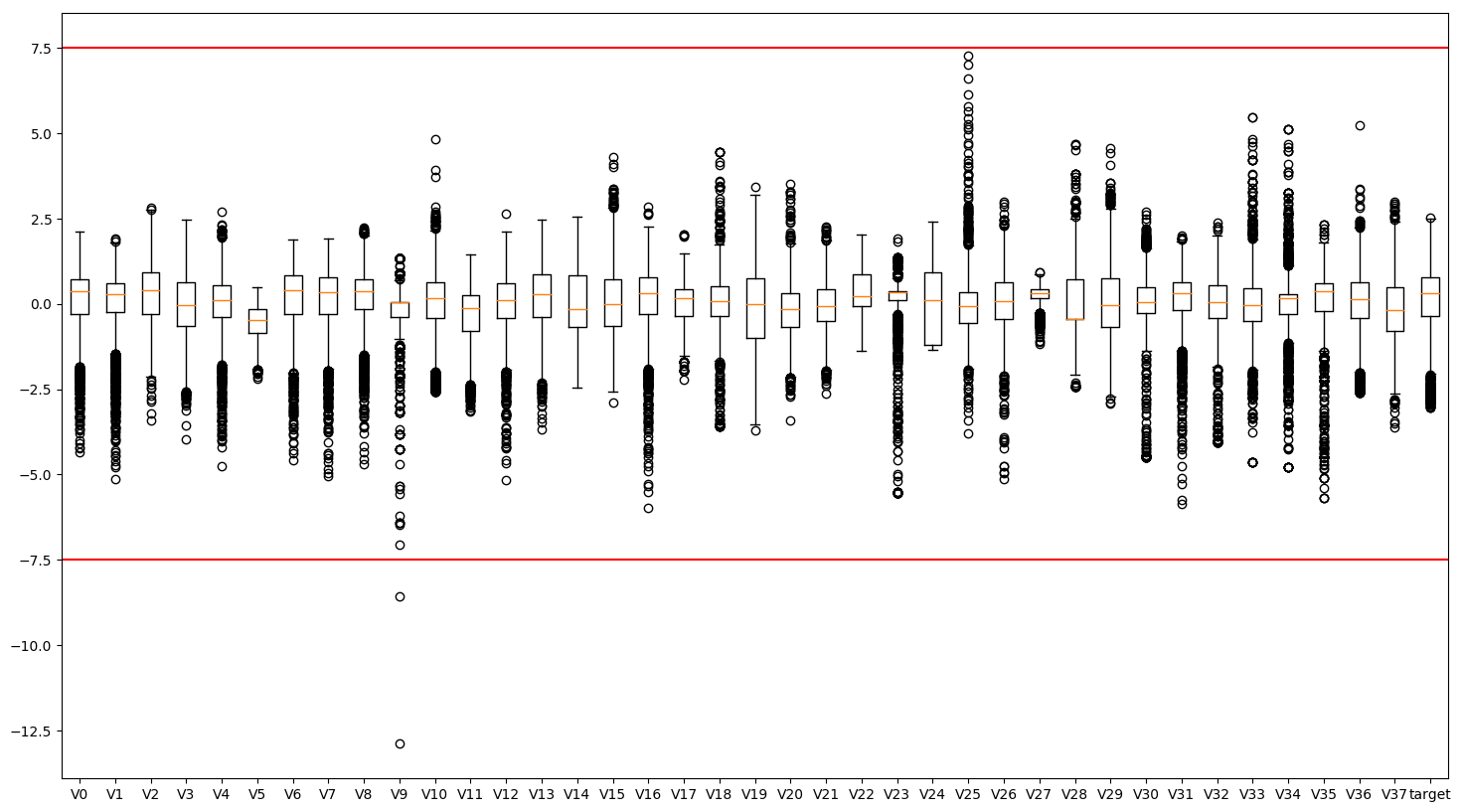
## 删除异常值
train_data = train_data[train_data['V9']>-7.5]
train_data.describe()
2.1.2 归一化处理
from sklearn import preprocessing
features_columns = [col for col in train_data.columns if col not in ['target']]
min_max_scaler = preprocessing.MinMaxScaler()
min_max_scaler = min_max_scaler.fit(train_data[features_columns])
train_data_scaler = min_max_scaler.transform(train_data[features_columns])
test_data_scaler = min_max_scaler.transform(test_data[features_columns])
train_data_scaler = pd.DataFrame(train_data_scaler)
train_data_scaler.columns = features_columns
test_data_scaler = pd.DataFrame(test_data_scaler)
test_data_scaler.columns = features_columns
train_data_scaler['target'] = train_data['target']
train_data_scaler.describe()
test_data_scaler.describe()
#查看数据集情况
dist_cols = 6
dist_rows = len(test_data_scaler.columns)
plt.figure(figsize=(4*dist_cols,4*dist_rows))
for i, col in enumerate(test_data_scaler.columns):
ax=plt.subplot(dist_rows,dist_cols,i+1)
ax = sns.kdeplot(train_data_scaler[col], color="Red", shade=True)
ax = sns.kdeplot(test_data_scaler[col], color="Blue", shade=True)
ax.set_xlabel(col)
ax.set_ylabel("Frequency")
ax = ax.legend(["train","test"])
# plt.show()
#已注释图片生成,自行打开
查看特征’V5’, ‘V17’, ‘V28’, ‘V22’, ‘V11’, 'V9’数据的数据分布
drop_col = 6
drop_row = 1
plt.figure(figsize=(5*drop_col,5*drop_row))
for i, col in enumerate(["V5","V9","V11","V17","V22","V28"]):
ax =plt.subplot(drop_row,drop_col,i+1)
ax = sns.kdeplot(train_data_scaler[col], color="Red", shade=True)
ax= sns.kdeplot(test_data_scaler[col], color="Blue", shade=True)
ax.set_xlabel(col)
ax.set_ylabel("Frequency")
ax = ax.legend(["train","test"])
plt.show()
这几个特征下,训练集的数据和测试集的数据分布不一致,会影响模型的泛化能力,故删除这些特征
3.1.3 特征相关性
plt.figure(figsize=(20, 16))
column = train_data_scaler.columns.tolist()
mcorr = train_data_scaler[column].corr(method="spearman")
mask = np.zeros_like(mcorr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
cmap = sns.diverging_palette(220, 10, as_cmap=True)
g = sns.heatmap(mcorr, mask=mask, cmap=cmap, square=True, annot=True, fmt='0.2f')
plt.show()
2.2 特征降维
mcorr=mcorr.abs()
numerical_corr=mcorr[mcorr['target']>0.1]['target']
print(numerical_corr.sort_values(ascending=False))
index0 = numerical_corr.sort_values(ascending=False).index
print(train_data_scaler[index0].corr('spearman'))
2.2.1 相关性初筛
features_corr = numerical_corr.sort_values(ascending=False).reset_index()
features_corr.columns = ['features_and_target', 'corr']
features_corr_select = features_corr[features_corr['corr']>0.3] # 筛选出大于相关性大于0.3的特征
print(features_corr_select)
select_features = [col for col in features_corr_select['features_and_target'] if col not in ['target']]
new_train_data_corr_select = train_data_scaler[select_features+['target']]
new_test_data_corr_select = test_data_scaler[select_features]
2.2.2 多重共线性分析
!pip install statsmodels -i https://pypi.tuna.tsinghua.edu.cn/simple
from statsmodels.stats.outliers_influence import variance_inflation_factor #多重共线性方差膨胀因子
#多重共线性
new_numerical=['V0', 'V2', 'V3', 'V4', 'V5', 'V6', 'V10','V11',
'V13', 'V15', 'V16', 'V18', 'V19', 'V20', 'V22','V24','V30', 'V31', 'V37']
X=np.matrix(train_data_scaler[new_numerical])
VIF_list=[variance_inflation_factor(X, i) for i in range(X.shape[1])]
VIF_list
[216.73387180903222,
114.38118723828812,
27.863778129686356,
201.96436579080174,
78.93722825798903,
151.06983667656212,
14.519604941508451,
82.69750284665385,
28.479378440614585,
27.759176471505945,
526.6483470743831,
23.50166642638334,
19.920315849901424,
24.640481765008683,
11.816055964845381,
4.958208708452915,
37.09877416736591,
298.26442986612767,
47.854002539887034]
2.2.3 PCA处理降维
from sklearn.decomposition import PCA #主成分分析法
#PCA方法降维
#保持90%的信息
pca = PCA(n_components=0.9)
new_train_pca_90 = pca.fit_transform(train_data_scaler.iloc[:,0:-1])
new_test_pca_90 = pca.transform(test_data_scaler)
new_train_pca_90 = pd.DataFrame(new_train_pca_90)
new_test_pca_90 = pd.DataFrame(new_test_pca_90)
new_train_pca_90['target'] = train_data_scaler['target']
new_train_pca_90.describe()
train_data_scaler.describe()
#PCA方法降维
#保留16个主成分
pca = PCA(n_components=0.95)
new_train_pca_16 = pca.fit_transform(train_data_scaler.iloc[:,0:-1])
new_test_pca_16 = pca.transform(test_data_scaler)
new_train_pca_16 = pd.DataFrame(new_train_pca_16)
new_test_pca_16 = pd.DataFrame(new_test_pca_16)
new_train_pca_16['target'] = train_data_scaler['target']
new_train_pca_16.describe()
3.模型训练
3.1 回归及相关模型
## 导入相关库
from sklearn.linear_model import LinearRegression #线性回归
from sklearn.neighbors import KNeighborsRegressor #K近邻回归
from sklearn.tree import DecisionTreeRegressor #决策树回归
from sklearn.ensemble import RandomForestRegressor #随机森林回归
from sklearn.svm import SVR #支持向量回归
import lightgbm as lgb #lightGbm模型
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split # 切分数据
from sklearn.metrics import mean_squared_error #评价指标
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
## 切分训练数据和线下验证数据
#采用 pca 保留16维特征的数据
new_train_pca_16 = new_train_pca_16.fillna(0)
train = new_train_pca_16[new_test_pca_16.columns]
target = new_train_pca_16['target']
# 切分数据 训练数据80% 验证数据20%
train_data,test_data,train_target,test_target=train_test_split(train,target,test_size=0.2,random_state=0)
3.1.1 多元线性回归模型
clf = LinearRegression()
clf.fit(train_data, train_target)
score = mean_squared_error(test_target, clf.predict(test_data))
print("LinearRegression: ", score)
train_score = []
test_score = []
# 给予不同的数据量,查看模型的学习效果
for i in range(10, len(train_data)+1, 10):
lin_reg = LinearRegression()
lin_reg.fit(train_data[:i], train_target[:i])
# LinearRegression().fit(X_train[:i], y_train[:i])
# 查看模型的预测情况:两种,模型基于训练数据集预测的情况(可以理解为模型拟合训练数据集的情况),模型基于测试数据集预测的情况
# 此处使用 lin_reg.predict(X_train[:i]),为训练模型的全部数据集
y_train_predict = lin_reg.predict(train_data[:i])
train_score.append(mean_squared_error(train_target[:i], y_train_predict))
y_test_predict = lin_reg.predict(test_data)
test_score.append(mean_squared_error(test_target, y_test_predict))
# np.sqrt(train_score):将列表 train_score 中的数开平方
plt.plot([i for i in range(1, len(train_score)+1)], train_score, label='train')
plt.plot([i for i in range(1, len(test_score)+1)], test_score, label='test')
# plt.legend():显示图例(如图形的 label);
plt.legend()
plt.show()
LinearRegression: 0.2642337917628173
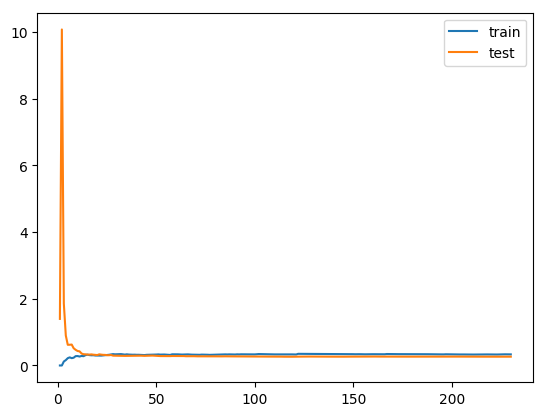
定义绘制模型学习曲线函数
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
print(train_scores_mean)
print(test_scores_mean)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
def plot_learning_curve_old(algo, X_train, X_test, y_train, y_test):
"""绘制学习曲线:只需要传入算法(或实例对象)、X_train、X_test、y_train、y_test"""
"""当使用该函数时传入算法,该算法的变量要进行实例化,如:PolynomialRegression(degree=2),变量 degree 要进行实例化"""
train_score = []
test_score = []
for i in range(10, len(X_train)+1, 10):
algo.fit(X_train[:i], y_train[:i])
y_train_predict = algo.predict(X_train[:i])
train_score.append(mean_squared_error(y_train[:i], y_train_predict))
y_test_predict = algo.predict(X_test)
test_score.append(mean_squared_error(y_test, y_test_predict))
plt.plot([i for i in range(1, len(train_score)+1)],
train_score, label="train")
plt.plot([i for i in range(1, len(test_score)+1)],
test_score, label="test")
plt.legend()
plt.show()
# plot_learning_curve_old(LinearRegression(), train_data, test_data, train_target, test_target)
# 线性回归模型学习曲线
X = train_data.values
y = train_target.values
# 图一
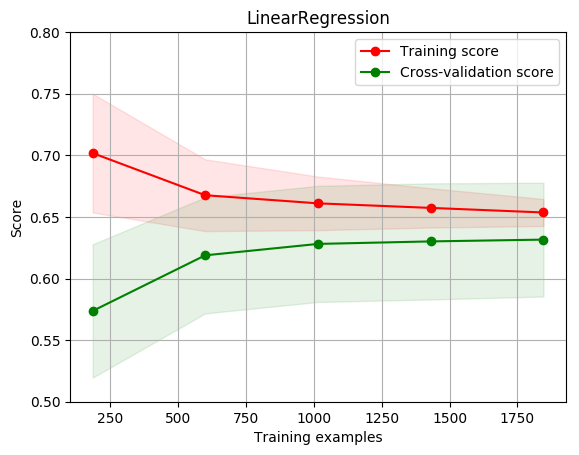
title = r"LinearRegression"
cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0)
estimator = LinearRegression() #建模
plot_learning_curve(estimator, title, X, y, ylim=(0.5, 0.8), cv=cv, n_jobs=1)
[0.70183463 0.66761103 0.66101945 0.65732898 0.65360375]
[0.57364886 0.61882339 0.62809368 0.63012866 0.63158596]
<module 'matplotlib.pyplot' from '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/pyplot.py'>
3.1.2 KNN近邻回归
for i in range(3,10):
clf = KNeighborsRegressor(n_neighbors=i) # 最近三个
clf.fit(train_data, train_target)
score = mean_squared_error(test_target, clf.predict(test_data))
print("KNeighborsRegressor: ", score)
KNeighborsRegressor: 0.27619208861976163
KNeighborsRegressor: 0.2597627823313149
KNeighborsRegressor: 0.2628212724567474
KNeighborsRegressor: 0.26670982271241833
KNeighborsRegressor: 0.2659603905091448
KNeighborsRegressor: 0.26353694644788067
KNeighborsRegressor: 0.2673470579477979
# plot_learning_curve_old(KNeighborsRegressor(n_neighbors=5) , train_data, test_data, train_target, test_target)
# 绘制K近邻回归学习曲线
X = train_data.values
y = train_target.values
# K近邻回归
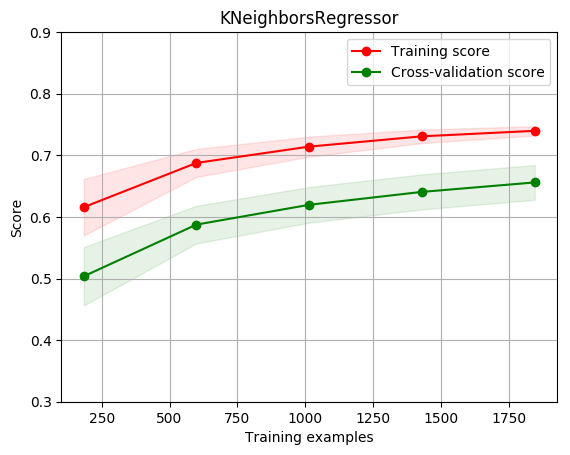
title = r"KNeighborsRegressor"
cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0)
estimator = KNeighborsRegressor(n_neighbors=8) #建模
plot_learning_curve(estimator, title, X, y, ylim=(0.3, 0.9), cv=cv, n_jobs=1)
[0.61581146 0.68763995 0.71414969 0.73084172 0.73976273]
[0.50369207 0.58753672 0.61969929 0.64062459 0.6560054 ]
<module 'matplotlib.pyplot' from '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/pyplot.py'>
3.1.3决策树回归
clf = DecisionTreeRegressor()
clf.fit(train_data, train_target)
score = mean_squared_error(test_target, clf.predict(test_data))
print("DecisionTreeRegressor: ", score)
DecisionTreeRegressor: 0.6405298823529413
# plot_learning_curve_old(DecisionTreeRegressor(), train_data, test_data, train_target, test_target)
X = train_data.values
y = train_target.values
# 决策树回归
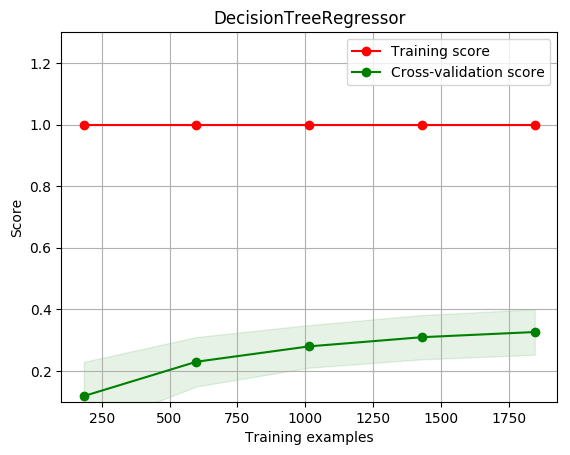
title = r"DecisionTreeRegressor"
cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0)
estimator = DecisionTreeRegressor() #建模
plot_learning_curve(estimator, title, X, y, ylim=(0.1, 1.3), cv=cv, n_jobs=1)
[1. 1. 1. 1. 1.]
[0.11833987 0.22982731 0.2797608 0.30950084 0.32628853]
<module 'matplotlib.pyplot' from '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/pyplot.py'>
3.1.4 随机森林回归
clf = RandomForestRegressor(n_estimators=200) # 200棵树模型
clf.fit(train_data, train_target)
score = mean_squared_error(test_target, clf.predict(test_data))
print("RandomForestRegressor: ", score)
# plot_learning_curve_old(RandomForestRegressor(n_estimators=200), train_data, test_data, train_target, test_target)
RandomForestRegressor: 0.24087959640588236
X = train_data.values
y = train_target.values
# 随机森林
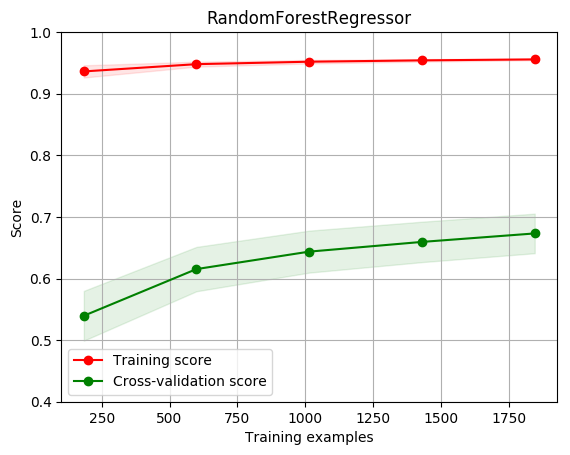
title = r"RandomForestRegressor"
cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0)
estimator = RandomForestRegressor(n_estimators=200) #建模
plot_learning_curve(estimator, title, X, y, ylim=(0.4, 1.0), cv=cv, n_jobs=1)
[0.93619796 0.94798334 0.95197393 0.95415054 0.95570763]
[0.53953995 0.61531165 0.64366926 0.65941678 0.67319725]
<module 'matplotlib.pyplot' from '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/pyplot.py'>
3.1.5 Gradient Boosting
3.1.6 lightgbm回归
# lgb回归模型
clf = lgb.LGBMRegressor(
learning_rate=0.01,
max_depth=-1,
n_estimators=10,
boosting_type='gbdt',
random_state=2019,
objective='regression',
)
# #为了快速展示n_estimators设置较小,实战中请按需设置
# 训练模型
clf.fit(
X=train_data, y=train_target,
eval_metric='MSE',
verbose=50
)
score = mean_squared_error(test_target, clf.predict(test_data))
print("lightGbm: ", score)
lightGbm: 0.906640574789251
X = train_data.values
y = train_target.values
# LGBM
title = r"LGBMRegressor"
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
estimator = lgb.LGBMRegressor(
learning_rate=0.01,
max_depth=-1,
n_estimators=10,
boosting_type='gbdt',
random_state=2019,
objective='regression'
) #建模
plot_learning_curve(estimator, title, X, y, ylim=(0.4, 1.0), cv=cv, n_jobs=1)
#为了快速展示n_estimators设置较小,实战中请按需设置
4.篇中总结
在工业蒸汽量预测上篇中,主要讲解了数据探索性分析:查看变量间相关性以及找出关键变量;数据特征工程对数据精进:异常值处理、归一化处理以及特征降维;在进行归回模型训练涉及主流ML模型:决策树、随机森林,lightgbm等。下一篇中将着重讲解模型验证、特征优化、模型融合等。
原项目链接:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc

- 点赞
- 收藏
- 关注作者
评论(0)