Java 解析pdf文档内容实战案例

【摘要】 一、应用场景1.首先我个人认为一切的技术都是为了服务实际的业务场景,所以说业务场景很重要,我一般写文章也都是先说明我的业务场景,这样大家也应该会比较容易理解,能知道我们为什么要解析这个pdf文档内容。2.项目上的实际案例是用来解析财务报表(资产负债表,利润表,所得税,增值税报表)的。但是那些报表,因为涉及隐私保密问题,所以我就用的个人银行流水给大家做一个详细的讲解过程。3.咱么既然要解析P...
一、应用场景
1.首先我个人认为一切的技术都是为了服务实际的业务场景,所以说业务场景很重要,我一般写文章也都是先说明我的业务场景,这样大家也应该会比较容易理解,能知道我们为什么要解析这个pdf文档内容。
2.项目上的实际案例是用来解析财务报表(资产负债表,利润表,所得税,增值税报表)的。但是那些报表,因为涉及隐私保密问题,所以我就用的个人银行流水给大家做一个详细的讲解过程。
3.咱么既然要解析PDF文档内容,肯定是想把它解析成格式化数据(JSON)格式的,对吧,这样才能方便我们对数据的一个使用。
二、直接上代码
具体基本每一行,我都有详细的注释说明。
1.先看看我要解析的源文件程序嗑学家_薪资流水.pdf
![]()
上面这个文件是相对比较规整格式的文件,实际情况应该会有许多报表格式不一样,解析出来的有换行之类的,需要特殊处理。
2.maven的pom文件引入依赖包如下:
<!-- pdfbox start -->
<!-- https://mvnrepository.com/artifact/org.apache.pdfbox/pdfbox -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.19</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-tools</artifactId>
<version>2.0.19</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>fontbox</artifactId>
<version>2.0.19</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>jempbox</artifactId>
<version>1.8.16</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>xmpbox</artifactId>
<version>2.0.19</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>preflight</artifactId>
<version>2.0.19</version>
</dependency>
<!-- pdfbox end -->注:我这里还有对PDF文档的其他一些解析,包括html字符串生成PDF文档的实际应用需求,所以我这儿引入的包比较多一点儿,你可以根据自己需求,按需引入依赖包。
三、具体实现代码
3.1下面这个文件是一个完整的Java 类
注:此处我引入了alibaba的JSON解析包,如果您复制过去报错的,可以自行引入需要的包。
package com.xxx.util.pdf;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.io.Writer;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
public class ParsePdfContent {
public static void main(String[] args) {
ParsePdfContent.tqPdfDataToTxt("E:\\www\\temp\\程序嗑学家_薪资流水.pdf", "E:\\www\\temp\\cxkxj_xzls.txt");
}
/**
* 测试解析pdf的文档内容,并将解析内容输出到Txt文档中
* 正式使用时,无需将解析后的内容写入文件,测试时,写入文件是为了方便查看解析后的原始内容
* @param sourcePdfPath 要解析的pdf源文件
* @param outFilePath 解析后的文本内容输出路径
*/
public static void tqPdfDataToTxt(String sourcePdfPath,String outFilePath) {
File file = new File(sourcePdfPath);
if(file.exists()) {
try {
PDDocument doc = PDDocument.load(file);
//正式使用时,此处注释开始--------------
FileOutputStream fos = new FileOutputStream(outFilePath);
Writer writer = new OutputStreamWriter(fos, "UTF-8");
//正式使用时,此处注释结束--------------
PDFTextStripper stripper = new PDFTextStripper();
stripper.setSortByPosition(true);// 排序
stripper.setEndPage(1);//要解析的结束页数,此处我只解析第一页
stripper.setWordSeparator("##");//单元格内容的分隔符号
stripper.setLineSeparator("\n");//行与行之间的分隔符号
String text = stripper.getText(doc);
String[] rows = text.split("\n");
//======从这里开始需要根据自己的实际解析内容做不同的处理start=======
JSONArray list=new JSONArray();//存储解析数据的集合
/**
* startFlag
* 解析内容开始的标志(大白话就是记录从哪一行开始是咱们的有用数据)
* 这里需要先解析一遍并输出到文件,才能具体知道
*/
String startFlag="Balance##Transaction";
String endFlag="1/35";//结束标志
int k=0;//开始获取数据标志
boolean bb_End=false;//报表获取数据结束标志
/**
* keys
* 标识字段的key
* date:记账日期
* currency:货币
* amount:交易金额
* balance:联机余额
* transactionType:交易摘要
* counterParty:对手信息
*/
String[] keys= {"date","currency","amount","balance","transactionType","counterParty"};
for (int r=0;r<rows.length;r++) {
/**
* 这里根据自己的解析内容做不同的业务处理
* 我这里总共6列数据
*/
JSONObject rowJson=new JSONObject();
rows[r]=rows[r].replaceAll(" ", "").replaceAll("\r", "");//此处我把每一行的空格和\r去掉
String[] split = rows[r].split("##");
if(k==1&&!bb_End) {//增值税表
if(rows[r].startsWith("本期应补(退)税额##22")||rows[r].startsWith("期末未缴查补税额##38")) {
bb_End=true;
}
//这里我判断是否完全匹配,是防止有换行的,这个需要根据实际情况做不同处理
if(split.length==keys.length) {//完全匹配列数(6)
for (int i=0;i<keys.length;i++) {
rowJson.put(keys[i], split[i]);
}
list.add(rowJson);
continue;
}
if(bb_End) {
break;//结束解析
}
}else {
if(rows[r].startsWith(startFlag)) {
k++;
continue;
}
}
}
//======从这里开始需要根据自己的实际解析内容做不同的处理end=======
//正式使用时,此处注释开始--------------
stripper.writeText(doc, writer);//写入本地文件(测试用)
writer.close();
//正式使用时,此处注释结束--------------
doc.close();
System.out.println("解析后格式化的JSON数据如下:");
System.out.println(JSON.toJSONString(list));
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("======================解析完成============================");
}else {
System.err.println("找不到要解析的pdf文件");
}
}
}3.2上面这个事例代码里面,我不仅把pdf内容输出到了文件内,还做了一个格式化输出的解析。
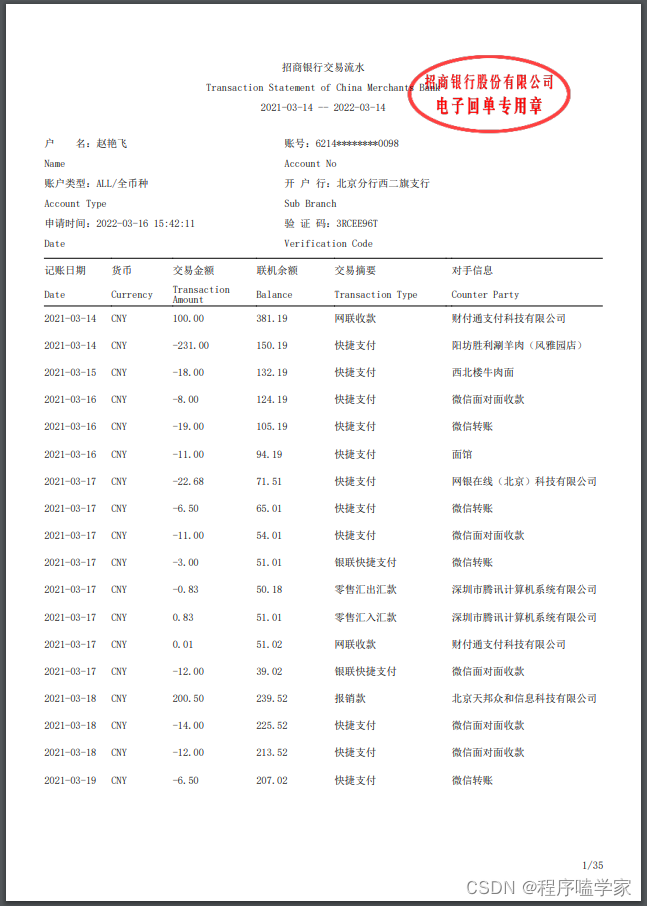
3.3 输出的文件cxkxj_xzls.txt 内容如下:
招商银行交易流水
Transaction Statement of China Merchants Bank
2021-03-14 -- 2022-03-14
户 名:赵艳飞##账号:6214********0098
Name##Account No
账户类型:ALL/全币种##开 户 行:北京分行西二旗支行
Account Type##Sub Branch
申请时间:2022-03-16 15:42:11##验 证 码:3RCEE96T
Date##Verification Code
记账日期##货币##交易金额##联机余额##交易摘要##对手信息
Transaction
Date##Currency
Amount
Balance##Transaction Type##Counter Party
2021-03-14##CNY##100.00##381.19##网联收款##财付通支付科技有限公司
2021-03-14##CNY##-231.00##150.19##快捷支付##阳坊胜利涮羊肉(风雅园店)
2021-03-15##CNY##-18.00##132.19##快捷支付##西北楼牛肉面
2021-03-16##CNY##-8.00##124.19##快捷支付##微信面对面收款
2021-03-16##CNY##-19.00##105.19##快捷支付##微信转账
2021-03-16##CNY##-11.00##94.19##快捷支付##面馆
2021-03-17##CNY##-22.68##71.51##快捷支付##网银在线(北京)科技有限公司
2021-03-17##CNY##-6.50##65.01##快捷支付##微信转账
2021-03-17##CNY##-11.00##54.01##快捷支付##微信面对面收款
2021-03-17##CNY##-3.00##51.01##银联快捷支付##微信转账
2021-03-17##CNY##-0.83##50.18##零售汇出汇款##深圳市腾讯计算机系统有限公司
2021-03-17##CNY##0.83##51.01##零售汇入汇款##深圳市腾讯计算机系统有限公司
2021-03-17##CNY##0.01##51.02##网联收款##财付通支付科技有限公司
2021-03-17##CNY##-12.00##39.02##银联快捷支付##微信面对面收款
2021-03-18##CNY##200.50##239.52##报销款##北京天邦众和信息科技有限公司
2021-03-18##CNY##-14.00##225.52##快捷支付##微信面对面收款
2021-03-18##CNY##-12.00##213.52##快捷支付##微信面对面收款
2021-03-19##CNY##-6.50##207.02##快捷支付##微信转账
1/35
![]()
3.4格式化输出内容就是JSON数组

![]()
四、结语:
小编是一名爱生活,爱代码,爱交朋友的热血青年,希望我们能够共同进步,共同成长。
感觉有帮助的帮小编点个免费的赞吧,如有问题,可以私信或者评论区留言,小编知无不言,言无不尽。
喜欢小编的可以微信搜素:民谣嗑学家
关注我个人公众号,小编平时,除了工作码代码,还是一名业余吉他爱好者,有喜欢的朋友可以一起交流交流。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)