秒懂算法 | 基于主成分分析法、随机森林算法和SVM算法的人脸识别问题


01、数据集介绍与分析
ORL人脸数据集共包含40个不同人的400张图像,是在1992年4月至1994年4月期间由英国剑桥的Olivetti研究实验室创建。
此数据集下包含40个目录,每个目录下有10张图像,每个目录表示一个不同的人。所有的图像是以PGM格式存储,灰度图,图像大小宽度为92,高度为112。对每一个目录下的图像,这些图像是在不同的时间、不同的光照、不同的面部表情(睁眼/闭眼,微笑/不微笑)和面部细节(戴眼镜/不戴眼镜)环境下采集的。所有的图像是在较暗的均匀背景下拍摄的,拍摄的是正脸(有些带有略微的侧偏)。
数据集链接:
https://pan.baidu.com/s/1hxeo38rJJFstLDG4lg67SA
提取码:8m9i

图1 数据集可视化结果
如图1所示,在该数据集中,每个人有10张照片,这10张照片中,前8张作为训练集,而后2张归为测试集。即可以获得一个408大小的训练集,以及402大小的测试集。人脸识别的任务即为在训练集上训练模型,并预测该照片属于哪一个人。因此,与手写数字相似,都是基于图片的多分类任务。与MNIST手写数字识别任务不同的地方在于,人脸图片比数字图片更为复杂,且训练样本较少,深度学习模型可能会带来过拟合的风险,在这种情况下,本文采取传统方法来进行求解。
首先,为了更好的表征图片中人脸的特性,将使用传统算子(LBP算子)从原始图片中提取特征,再进行PCA降维,最后使用随机森林、GBDT等机器学习模型对特征进行分类学习。在机器学习领域,如何根据任务目标去构造特征是一项非常重要的任务,特征的好坏直接决定了后面分类模型预测结果的上限和下限,而模型的选取相比特征来说差异化并不是非常大,在现实应用中,由于时限等要求不能选取太过复杂的模型,这时候,特征的选择就显得更为重要。
02、LBP算子
LBP是Local Binary Pattern(局部二值模式)的缩写,具有灰度不变性和旋转不变性等显著优点。
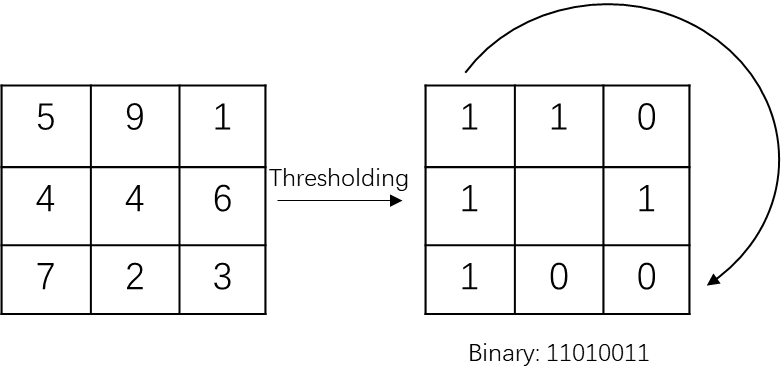
图2 LBP算子计算过程示意图
如图2所示,原始的LBP算子定义为在3 3的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于等于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3 3邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息。需要注意的是,LBP值是按照顺时针方向组成的二进制数。
基本的 LBP算子的最大缺陷在于它只覆盖了一个固定半径范围内的小区域,这显然不能满足不同尺寸和频率纹理的需要。为了适应不同尺度的纹理特征,并达到灰度和旋转不变性的要求,Ojala等对 LBP 算子进行了改进,将 3*3邻域扩展到任意邻域,并用圆形邻域代替了正方形邻域,改进后的 LBP 算子允许在半径为 R 的圆形邻域内有任意多个像素点。从而得到了诸如半径为R的圆形区域内含有P个采样点的LBP算子,称为Extended LBP。
03、提取图片特征
在训练模型之前,首先应完成加载数据集以及提取图片特征的相关函数。如代码清单1所示,首先导入相关的包,以及设置超参数CUT_X和CUT_Y,分别指原图可以在高和宽方向可以被裁减的次数,例如原图大小为11292,高112可以被切分为814,同理宽92可被切分为4*28,该项参数的具体用途将在后文中具体说明。
代码清单1 导入相关库以及超参数设置
from PIL import Image
from sklearn.decomposition import PCA
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import confusion_matrix, precision_score, accuracy_score,recall_score, f1_score
import numpy as np
import cv2
import os
import math
import random
CUT_X = 8
CUT_Y = 4代码清单2中定义了load_data函数,其中ORL_PATH指数据集所在的路径。从路径中读取图片转化为numpy数组,并将图片和标签分别返回,需要注意的是打乱训练集时需要用同一个种子进行打乱,这样可以保证X和y以相同的方式进行打乱。每个人的子文件夹下包含同一人的10张图像,选取前八张作为训练集数据,后两张为测试集数据。
代码清单2 读取数据并进行预处理
def load_data():
ORL_PATH = './orl'
train_X = [] # 训练集
train_y = []
test_X = [] # 测试集
test_y = []
person_dirnames = os.listdir(ORL_PATH)
for dirname in person_dirnames:
for i in range(1, 9):
pic_path = os.path.join(ORL_PATH, dirname, str(i) + '.pgm')
im = np.array(Image.open(pic_path).convert("L")) # 读取文件并转化为灰度图
train_X.append(im)
train_y.append(int(dirname[1:]) - 1)
for i in range(9, 11):
pic_path = os.path.join(ORL_PATH, dirname, str(i) + '.pgm')
im = np.array(Image.open(pic_path).convert("L")) # 读取文件并转化为灰度图
test_X.append(im)
test_y.append(int(dirname[1:]) - 1)
# 同时打乱X和y数据集。
randnum = random.randint(0, 100)
random.seed(randnum)
random.shuffle(train_X)
random.seed(randnum)
random.shuffle(train_y)
print("训练集大小为: {}, 测试集大小为: {}".format(len(train_X), len(test_X)))
return np.array(train_X), np.array(train_y).T, np.array(test_X), np.array(test_y).T如图3所示为LBP提取特征的可视化结果。

图3 LBP特征可视化结果
其中minBinary这个辅助函数的实现如代码清单4所示,正是由于minBinary这个函数,LBP特征会有较好的旋转不变性,因为无论图片如何旋转,其min值都不会改变。
代码清单4 LBP旋转不变性实现
# 为了让LBP具有旋转不变性,将二进制串进行旋转。
# 假设一开始得到的LBP特征为10010000,那么将这个二进制特征,
# 按照顺时针方向旋转,可以转化为00001001的形式,这样得到的LBP值是最小的。
# 无论图像怎么旋转,对点提取的二进制特征的最小值是不变的,
# 用最小值作为提取的LBP特征,这样LBP就是旋转不变的了。
def minBinary(pixel):
length = len(pixel)
zero = ''
# range(length)[::-1] 使得i从01234变为43210
for i in range(length)[::-1]:
if pixel[i] == '0':
pixel = pixel[:i]
zero += '0'
else:
return zero + pixel
if len(pixel) == 0:
return '0'提取LBP特征后,如代码清单5所示,将图片分割为84=32个小块,即前面设置的CUT_X和CUT_Y。每个小块统计像素值分别为0-256的数目,最后将32个小区域的统计结果合并,得到最终的特征数目为32256个。
代码清单5 对图片进行切片并统计直方图特征
# 统计直方图
def calHistogram(ImgLBPope, h_num=CUT_X, w_num=CUT_Y):
# 112 = 14 * 8, 92 = 23 * 4
Img = ImgLBPope.reshape(112, 92)
H, w = np.shape(Img)
# 把图像分为8 * 4份
Histogram = np.mat(np.zeros((256, h_num * w_num)))
maskx, masky = H / h_num, w / w_num
for i in range(h_num):
for j in range(w_num):
# 使用掩膜opencv来获得子矩阵直方图
mask = np.zeros(np.shape(Img), np.uint8)
mask[int(i * maskx): int((i + 1) * maskx), int(j * masky):int((j + 1) * masky)] = 255
hist = cv2.calcHist([np.array(Img, np.uint8)], [0], mask, [256], [0, 255])
Histogram[:, i * w_num + j] = np.mat(hist).flatten().T
return Histogram.flatten().T以及将上述函数串联,封装得到总的预处理函数如代码清单6。
代码清单6 提取特征函数
def getfeatures(input_face):
LBPoperator = LBP(input_face) # 获得实验图像的LBP算子 一列是一张图
# 获得实验图像的直方图分布
exHistograms = np.mat(np.zeros((256 * 4 * 8, np.shape(LBPoperator)[1]))) # 256 * 8 * 4行, 图片数目列
for i in range(np.shape(LBPoperator)[1]):
exHistogram = calHistogram(LBPoperator[:, i], 8, 4)
exHistograms[:, i] = exHistogram
exHistograms = exHistograms.transpose()
return exHistograms到目前已经完成了特征提取过程,模型部分就可以调用sklearn库从而简化了代码编写,由于每一张图片最终的特征数目非常大,如果直接用这些特征去训练模型,会降低模型训练的速度,使用PCA算法可以大幅降低特征数目,仅保留关键的信息,如代码清单7所示,编写PCA函数,完成降维过程,其中n_components为降维后保留的特征数目。
代码清单7 使用PCA进行降维
def pca(train_X, test_X, n_components=150):
pca = PCA(n_components=n_components, svd_solver='randomized', whiten=True)
pca.fit(train_X)
train_X_pca = pca.transform(train_X)
test_X_pca = pca.transform(test_X)
return train_X_pca, test_X_pca04、基于随机森林算法的人脸识别问题
在上文已经完成了特征提取以及预处理相关的函数,接下来使用随机森林算法来完成接下来模型训练以及测试的过程,首先是训练模型的函数,如代码清单8所示,以训练集的特征和标签作为输入,返回训练好的模型。
代码清单8 训练随机森林模型
def train_rf(train_X, train_y):
rf = RandomForestClassifier(n_estimators=200)
rf.fit(train_X, train_y)
return rf以及如代码清单9所示为测试模型的函数,以模型、测试集特征、测试集标签作为输入,计算混淆矩阵以及多分类问题的评价指标。
代码清单9 测试随机森林模型
# 测试模型
def test(model, x_test, y_test):
# 预测结果
y_pre = model.predict(x_test)
# 混淆矩阵
con_matrix = confusion_matrix(y_test, y_pre)
print('confusion_matrix:\n', con_matrix)
print('accuracy:{}'.format(accuracy_score(y_test, y_pre)))
print('precision:{}'.format(precision_score(y_test, y_pre, average='micro')))
print('recall:{}'.format(recall_score(y_test, y_pre, average='micro')))
print('f1-score:{}'.format(f1_score(y_test, y_pre, average='micro')))最后编写main函数如代码清单10所示,将特征提取、PCA降维、模型训练以及测试串联起来。
代码清单10 编写main函数
if __name__ == "__main__":
train_X, train_y, test_X, test_y = load_data()
print("开始提取训练集特征")
feature_train_X = getfeatures(train_X)
print("开始提取测试集特征")
feature_test_X = getfeatures(test_X)
print("PCA降维")
feature_train_X_pca, feature_test_X_pca = pca(feature_train_X, feature_test_X)
model = train_rf(feature_train_X_pca, train_y)
test(model, feature_test_X_pca, test_y)运行脚本,可以得到如下图4所示的输出,至此就完成了基于随机森林的人脸识别问题。

图4 随机森林模型在测试集上的表现结果
05、基于SVM算法的人脸识别问题
如代码清单11所示,定义一个训练SVM模型的函数,与前面训练随机森林函数的参数以及返回值相同。
代码清11 训练SVM模型
# 训练SVM模性
from sklearn import svm
def trainSVM(x_train, y_train):
# SVM生成和训练
clf = svm.SVC(kernel='rbf', probability=True)
clf.fit(x_train, y_train)
return clf同样修改main函数如代码清单12所示。
代码清单12 修改main函数
if __name__ == "__main__":
train_X, train_y, test_X, test_y = load_data()
print("开始提取训练集特征")
feature_train_X = getfeatures(train_X)
print("开始提取测试集特征")
feature_test_X = getfeatures(test_X)
print("PCA降维")
feature_train_X_pca, feature_test_X_pca = pca(feature_train_X, feature_test_X)
model = trainSVM(feature_train_X_pca, train_y)
test(model, feature_test_X_pca, test_y)运行程序可得最终输出如图5所示。

图5 SVM模型在测试集上的表现结果

- 点赞
- 收藏
- 关注作者
评论(0)