机器学习:基于神经网络对用户评论情感分析预测

机器学习:基于神经网络对用户评论情感分析预测
作者:AOAIYI
作者简介:Python领域新星作者、多项比赛获奖者:AOAIYI首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
@TOC
一、实验前言
ChatGPT自2022年11月发布以来,我基本上每天都在使用。我主要关注它的逻辑推理能力,而不仅仅是它拥有哪些知识。我认为,逻辑推理能力对判断一个模型是否达到了类似人的思维水平更重要。
针对当下全民关注ChatGPT的火爆现象,业界有一种较高的呼声是,它正在带动AI(人工智能)新一轮发展浪潮的看法。在张祥雨看来,引发AI新一轮浪潮的不止是ChatGPT——它只是大模型技术的一种应用,近几年自然语言大模型方面呈现跨越式发展的核心逻辑在于规模化效应。简单来说就是,在AI模型里,可以通过不断地增加数据、增加模型大小来实现性能的持续提升。
“ChatGPT科研价值更大”
自深度学习(Deep Learning)提出十几年来,业界很多人认为规模化效应“到头了”,因为随着模型的增大和数据量的增多,模型的收益逐渐递减,即所谓的“边际效应递减”——越增加数据,收益就越来越不明显,性价比就越低。张祥雨指出,这两年,在自然语言处理大模型上却出现了一个不同的现象,即当模型的参数量、训练数据量达到千亿量级时,模型的高级思维能力突然出现了跨越式的增长,这一增长是过去从来没有发现过的。现在大概在千亿量级这个参数“关口”,数据和模型量稍微增加一些,模型突然出现了原来不曾有的推理能力,还激发了一些之前往往被认为只有人类才有的能力,如思维链能力。当然,这背后还有诸如代码预训练等许多技术,共同推动了AI的跨越式发展。
我认为,目前以ChatGPT为代表的AIGC(利用人工智能技术来生成内容),包括它背后的大模型的意义,不仅仅是在落地本身,在我看来它的科研价值可能更大。”张祥雨分析道, 科研价值主要体现在研究人类智能如何产生。从技术角度来看,AI大模型的设计和训练过程并没有专门针对智能做特殊的设计。它的逻辑推理、思维链、reasoning的能力,是研究人员通过大幅增加参数量、增加训练数据量的过程中突然激发出来的,这个现象是非同寻常的。其实这和生物的进化包括人类的进化史也是非常像的。这种突然产生的智能背后不是靠专门的设计,是模型自然而然所形成的。(源于网络)
二、实验原理
神经网络模型的思想来源于模仿人类大脑思考的方式。神经元是神经系统最基本的结构和功能单位,分为突起和细胞体两部分。突起作用是接受冲动并传递给细胞体,细胞体整合输入的信息并传出。
人类大脑在思考时,神经元会接受外部的刺激,当传入的冲动使神经元的电位超过阈值时,神经元就会从抑制转向兴奋,并将信号向下一个神经元传导。神经网络的思想是通过构造人造神经元的方式模拟这一过程。
(1) 单层神经网络模型
如下图所示,在一个简单的神经网络模型中有两组神经元,一组接收信号,一组输出信号。接受信号的一组通过线性变换和非线性的激活函数转换来修改信号,并传递给下一组。
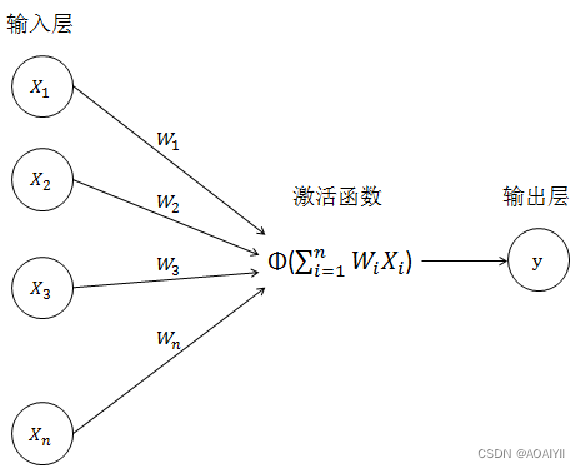
输出层信号的计算分为两步:
第二步:对加权平均后的结果使用激活函数(Activation Function) ϕ(x)进行非线性的转化,计算出输出值:
y=ϕ(y^′)
在神经网络模型中,常用来做非线性转换的激活函数有Sigmoid函数、Tanh函数、Relu函数。
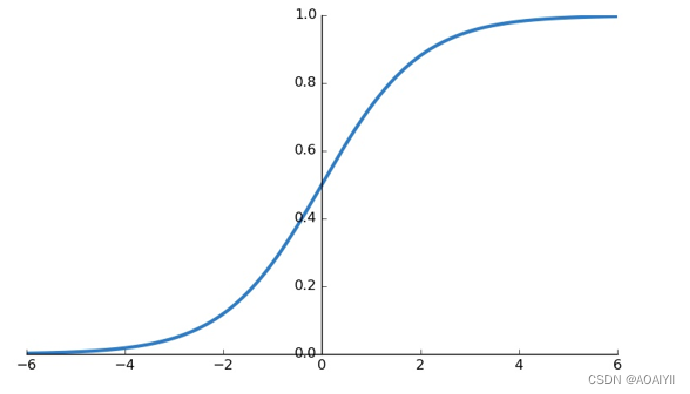
Sigmoid函数:如下图所示,该函数是将取值为(−∞,∞)的数转换到(0,1)之间,可以用来做二分类。其导数 f′(x) 从0开始,很快就又趋近于0,所以在梯度下降时会出现梯度消失;而且sigmoid函数的均值是0.5而非0,不利于下一层的输出。
f(x)=1/1+e^−x
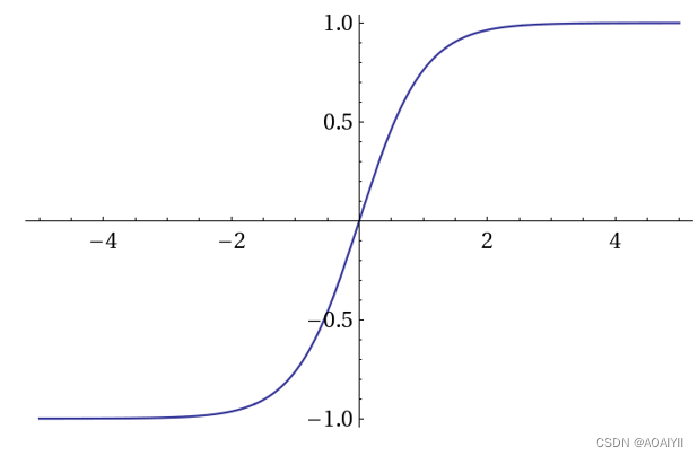
Tanh函数:如右图所示, Tanh函数将取值为(−∞,∞)的数转换到(-1,1)之间。当x很大或者很小的时候,导数 f′(x)也会很接近0,和sigmoid函数有同样的梯度消失的问题。但是tanh函数的均值为0,在这点上弥补了sigmoid函数均值为0.5的缺点。
f(x)=e^x−e^−x/e^x+e^−x
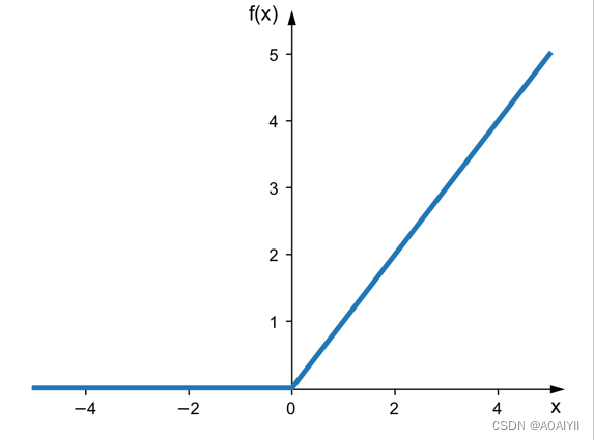
Relu函数:如右图所示, Relu函数是一种分段线性函数,它在输入为正数时弥补了Sigmoid函数以及Tanh函数的梯度消失问题,但是输入为负数时仍然有梯度消失的问题。此外Relu函数的计算速度相对于Sigmoid函数和Tanh函数也较快一些,在实战应用中,Relu函数在神经网络模型中用的相对较广一些。
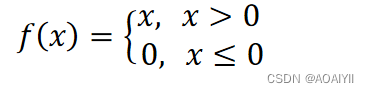
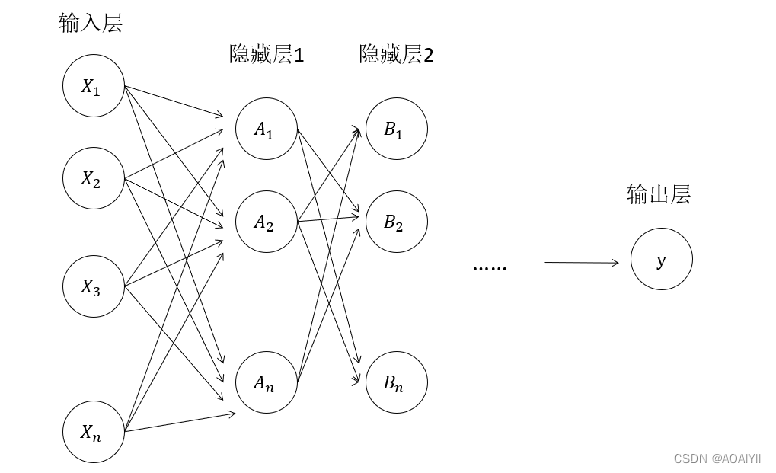
(2) 多层神经网络模型
实际应用中,常常采用如下图所示的多层神经网络,在多层神经网络模型中,输入层和输出层间可以有多层隐藏层,层与层之间互相连接,信号通过线性变换和激活函数的复杂映射,不断地进行传递。
三、实验环境
- Anaconda
- python3.9
- jupyter notebook
四、实验内容
学习神经网络模型,使用jieba分词对用户评论情感数据分析。
五、实验步骤
1.数据读取
1.数据准备

2.数据导入
import pandas as pd
df = pd.read_excel(r"C:\Users\XWJ\Desktop\用户评论情感数据.xlsx")
df.head()

2.中文分词
1.jieba库分词实例
import jieba
word = jieba.cut('我爱中国')
for i in word:
print(i)

2.使用.iloc获取数据表信息
df.iloc[0]

3.演示第一条评论的分词效果
import jieba
word = jieba.cut(df.iloc[0]['评论'])
result = ' '.join(word)
print(result)

4.遍历整张表格,对所有评论进行分词
words = []
for i, row in df.iterrows():
word = jieba.cut(row['评论'])
result = ' '.join(word)
words.append(result)
words[0:3]

3.文本向量化
1.使用CountVectorizer()函数对文本向量化(示例)
from sklearn.feature_extraction.text import CountVectorizer
test = ['手机 外观 漂亮', '手机 图片 清晰']
vect = CountVectorizer()
X = vect.fit_transform(test)
X = X.toarray()
words_bag = vect.vocabulary_
print(words_bag)
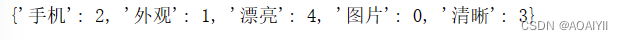
2.使用CountVectorizer()函数对文本向量化(实际应用)
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
X = vect.fit_transform(words)
X = X.toarray()
print(X)

words_bag = vect.vocabulary_
print(words_bag)
查看words_bag数量
len(words_bag)
3.目标变量提取
y = df['评价']
y.head()

4.神经网络模型搭建
1.切分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=1)
2.建立神经网络模型
from sklearn.neural_network import MLPClassifier
mlp =MLPClassifier()
mlp.fit(X_train, y_train)
因为模型运行具有随机性,如果想让每次运行结果一致,可以设置random_state随机参数为任一数字,如MLPClassifier(random_state=123)

输出结果
y_pred = mlp.predict(X_test)
print(y_pred)
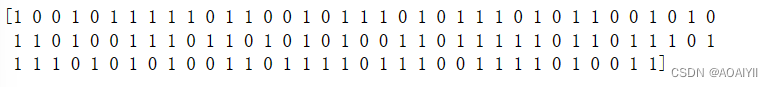
3.获取预测准确度
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
score
准确度:0.9814814814814815
5.模型使用
1.检验模型
comment = input('请输入您对本商品的评价:')
comment = [' '.join(jieba.cut(comment))]
print(comment)
X_try = vect.transform(comment)
y_pred = mlp.predict(X_try.toarray())
print(y_pred)
6.模型对比(朴素贝叶斯模型)
from sklearn.naive_bayes import GaussianNB
nb_clf = GaussianNB()
nb_clf.fit(X_train,y_train)
y_pred = nb_clf.predict(X_test)
print(y_pred)
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
print(score)
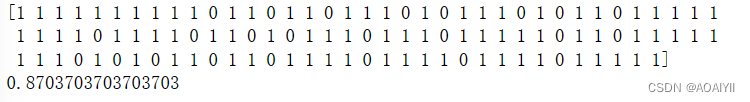
总结
神经网络模型的思想来源于模仿人类大脑思考的方式。神经元是神经系统最基本的结构和功能单位,分为突起和细胞体两部分。突起作用是接受冲动并传递给细胞体,细胞体整合输入的信息并传出。
人类大脑在思考时,神经元会接受外部的刺激,当传入的冲动使神经元的电位超过阈值时,神经元就会从抑制转向兴奋,并将信号向下一个神经元传导。神经网络的思想是通过构造人造神经元的方式模拟这一过程。

- 点赞
- 收藏
- 关注作者
评论(0)