C生万物 | 窥探数组设计的种种陷阱

💻一维数组的创建和初始化
1、数组的创建
数组是一组相同类型元素的集合。
数组的创建方式:
type_t arr_name [const_n];
//type_t 是指数组的元素类型
//const_n 是一个常量表达式,用来指定数组的大小
- 首先来看看我们如何去创建数组。对于整型、字符型、浮点型的数据我们都可以进行创建,[]内的数字便是这个数组的大小,表示这个数组中可以存放多少元素。
- 当然除了数字也可以是一个表达式
int a1[5];
char a2[6];
float a3[7];
double a4[4 + 4]; //也可以是一个表达式
- 虽然指定数组大小可以是一个常量,但不可以是一个变量。就如下面这种情况而言,我们自己去输入一个值去指定
int n = 0;
scanf("%d", &n);
int arr[n];
==为什么不可以呢?==
- 其实这种写法是可以的,因为在C99中引入了
变长数组的概念 - 变长数组支持数组的大小使用变量来指定。但是不要混淆了变长数组不是数组的长度可以变化,而是数组的大小可以用变量来指定

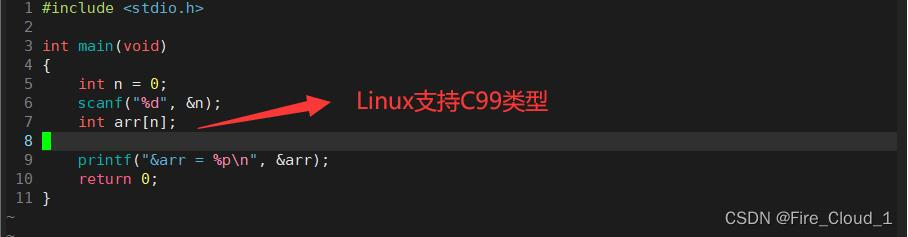
- 可以看到,在VS2019,VS2022中,我们使用这种变长数组的形式会报错,但是在Linux底下运行就不会报错,可见Linux是支持C99类型的
2、数组的初始化
讲完了数组该如何去创建,接下去我们来谈谈数组该如何初始化
首先要来辨析一下初始化和赋值的区别。万不可以混淆
int n = 0; //初始化
int m;
m = 0; //赋值
接下去就来看看数组的初始化
- [x] 首先是整型数组
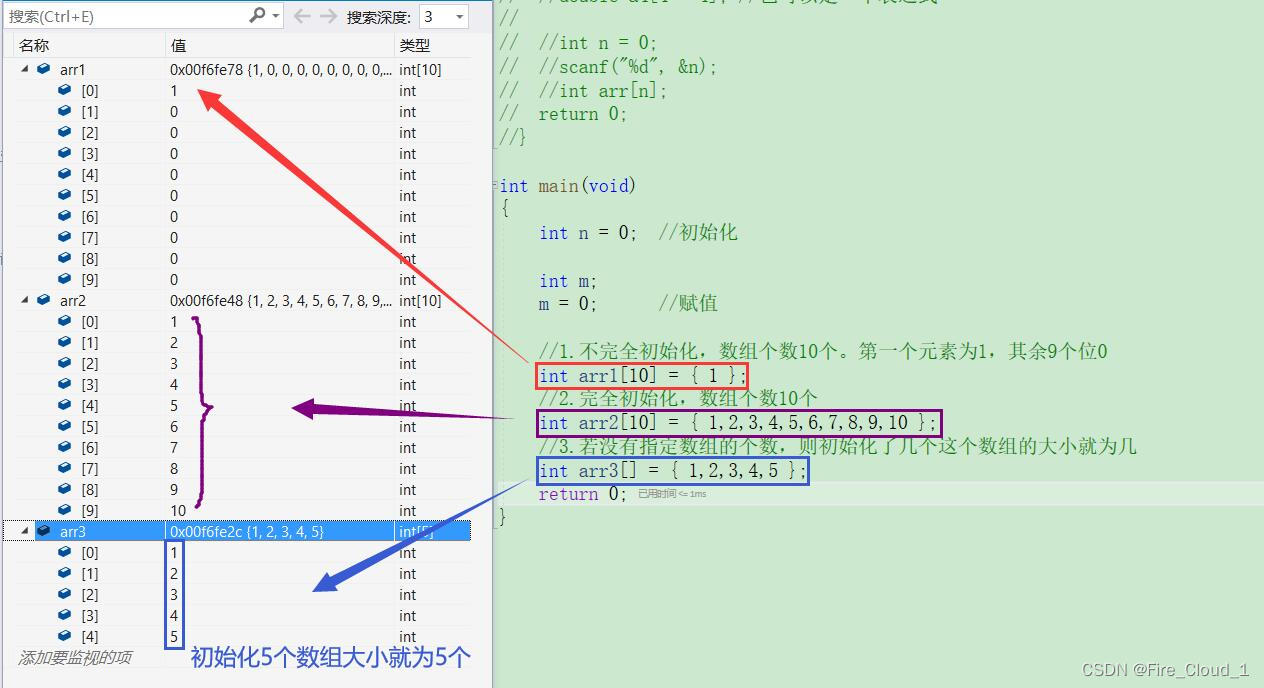
//1.不完全初始化,数组个数10个。第一个元素为1,其余9个位0
int arr1[10] = { 1 };
//2.完全初始化,数组个数10个
int arr2[10] = { 1,2,3,4,5,6,7,8,9,10 };
//3.若没有指定数组的个数,则初始化了几个这个数组的大小就为几
int arr3[] = { 1,2,3,4,5 };
可以通过DeBug调试来观察一下
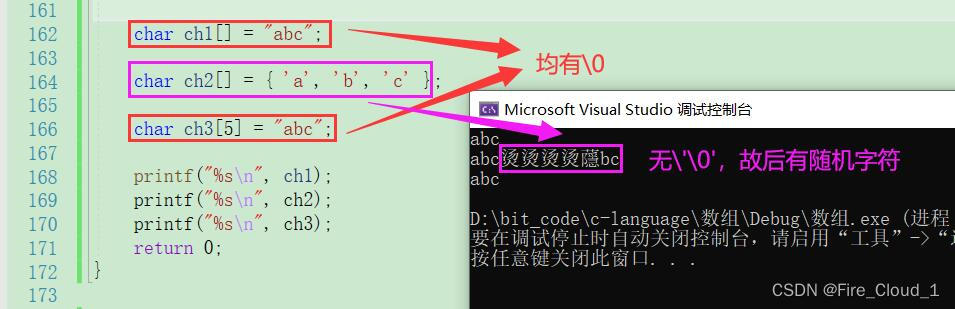
- [x] 然后是字符数组
//1.数组大小为4,初始化四位,abc + '\0'
char ch1[] = "abc";
//2.数组大小为3,初始化前三位,abc
char ch2[] = { 'a', 'b', 'c' };
- 对于字符数组来说,若是以字符串的形式进行初始化,则默认在最后加上一个
\0;若是以单个字符的形式初始化,则数组大小即为初始化的字符个数
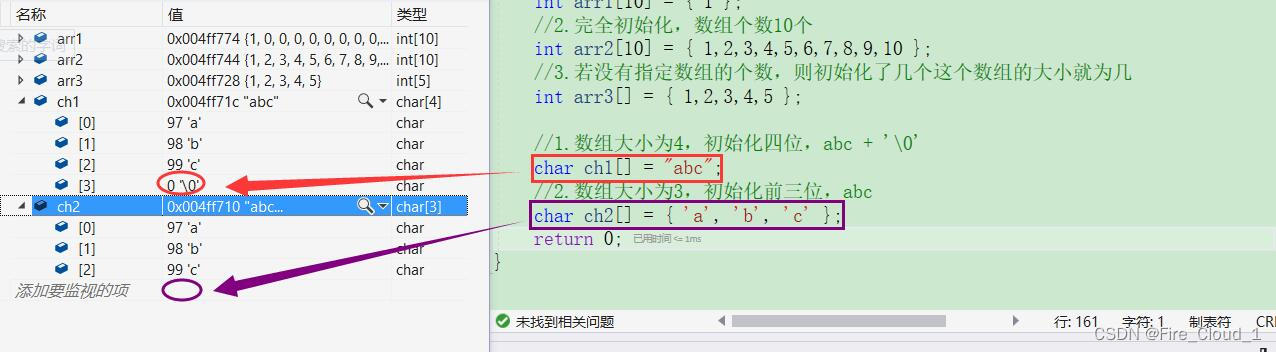
==这里再做一个区分==
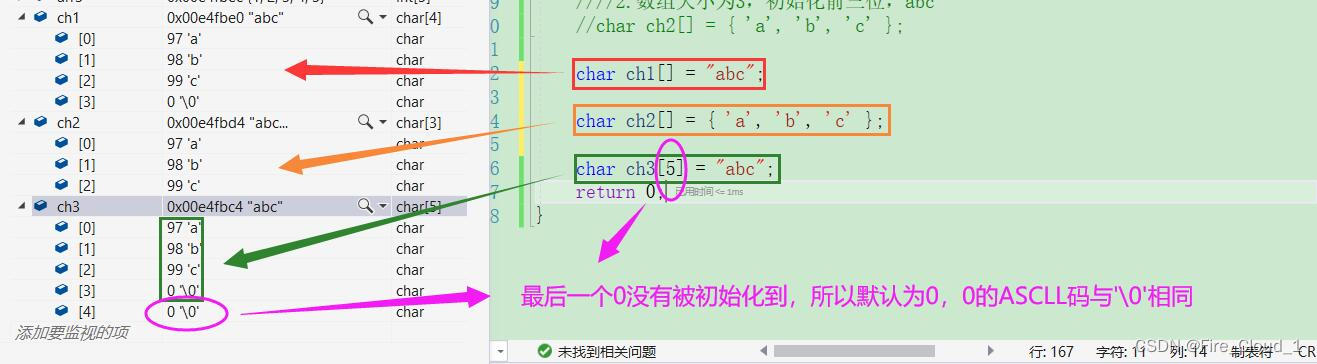
- 除了DeBug之外,我们还可以将其打印出来看看
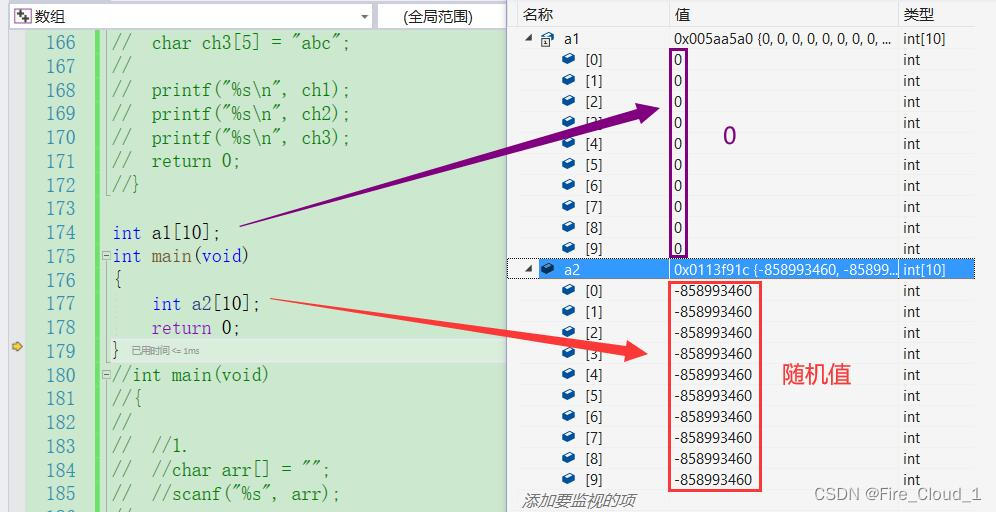
📚 拓展:数组作为局部变量不初始化内容默认为【随机值】;数组作为全局变量不初始化内容默认为【0】
- 可以看到,数组a1为中的内容均为0,;数组a2中的内容均为随机值
3、一维数组的使用
初始化好了,那这个数组就可以使用了,我们来用用看🗡
对于数组的使用我们之前介绍了一个操作符: [],下标引用操作符。它其实就数组访问的操作符
- 那我们就可以通过这个操作符来访问数组中的内容
int main(void)
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10};
for (int i = 0; i < 10; ++i)
{
printf("%d ", arr[i]);
}
return 0;
}
- 上面这种对于循环中要访问的数组个数已经写死了,如果修改一下数组的元素个数,那循环的结束条件就也要修改了,此时我们就可以考虑使用到
sizeof()去首先计算出数组的大小
int main(void)
{
int arr[20] = { 1,2,3,4,5,6,7,8,9,10,11,12};
int sz = sizeof(arr) / sizeof(int);
int i = 0;
for (int i = 0; i < sz; ++i)
{
printf("%d ", arr[i]);
//arr[i]表示在访问数组中的一个元素,因此可以使用变量【C99】
}
return 0;
}
==那有些同学可能会问这个arr[]括号里面不是不可以写变量吗,上面还说到了VS不支持C99?==
- 答:这一块的话千万不要混淆了,我们现在的
arr[i]是在访问数组中的元素,上面说到不可以使用这个【变长数组】是在我们定义数组的期间,不可以去使用,这里已经在访问数组元素了是不受影响的
小结:
- 数组是使用下标来访问的,下标是从0开始
- 数组的大小可以通过计算得到
4、 一维数组在内存中的存储
想知道这个一维数组在内存中是如何存储的嘛,那就看看这一小节吧
- 要想知道数组是如何在内存中存放的,那就要将每一个元素的地址打印出来观察一下
int main(void)
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10};
int sz = sizeof(arr) / sizeof(int);
for (int i = 0; i < sz; ++i)
{
printf("&arr[%d] = %p\n", i, &arr[i]);
}
return 0;
}
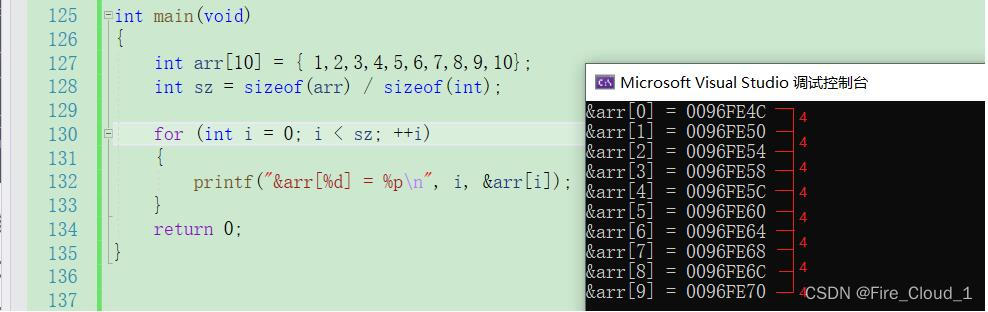
- 可以看到,对于每一个数组元素之间,在内存中都是差了4个字节,因为整型是4个字节
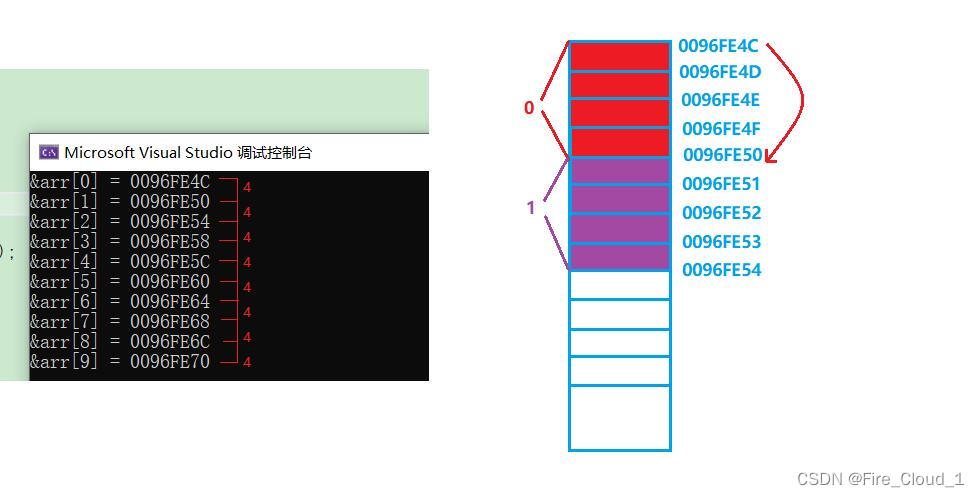
- 然后你再去仔细观察的话就看看出这个内存地址上面是
低地址,下面是高地址,因为它们都是局部变量,都是在main函数的栈帧中开辟的,所以它们都是存放在栈中的 - 对于【栈】来说是向下生长的,也就是从低地址向高地址生长,所以越往下开辟空间这个地址快就会越大。如果你对这些不了解的话可以看看我的这篇文章——> C生万物 | 反汇编深挖【函数栈帧】的创建和销毁
小结:
- 一维数组在内存中是连续存放的
- 随着数组下标的增长,地址是由低到高变化的
💻二维数组的创建和初始化
讲完一维数组,接下去我们来讲讲二维数组,它能以一个矩阵的形式来存储数据
1、二维数组的创建
- 首席那来看一下各种数据类型的二维数组创建
int main(void)
{
int arr1[3][4]; //整型二维数组
double arr2[3][5]; //字符型二维数组
float arr3[4][5]; //浮点型二维数组
return 0;
}
2、二维数组的初始化
- 创建完后,那还要对其对其进行初始化。可以看到我默认初始化了五个元素之后,因为这个二维数组的是三行四列的,所以第五个元素自动归位第二行的第一个元素
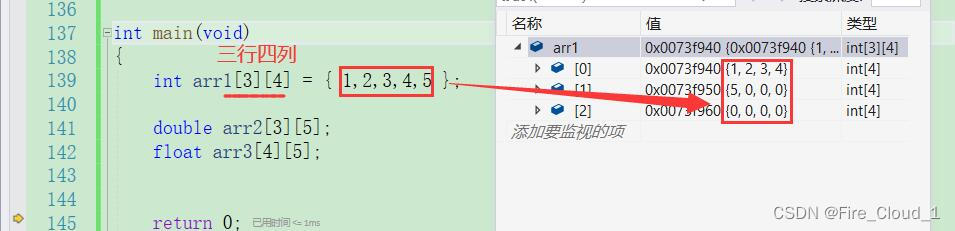
- 不仅如此,我们还可以指定初始化每一行的元素,一行表示一个大括号,只需要在大括号里为每一行也加上花括号即可,然后在括号里写上这一行要初始化的数据

接下去讲重点了,注意看❗❗❗
对于二维数组在初始化的时候可以省略行,但是不可以省略列我们可以到VS中来观察一下

- 可以看到,对于【全部省略】、【省略列】都是不可以的,唯独将列加上便可以了。所以我们在写二维数组的时候绝对不要省略列
- [x] 问:为何不能省略列呢?
答:列决定了一行有几个元素,几行是由行数来决定的。行数可以不知道,但是列数必须知道,要告诉编译器你这一行有多少元素。这其实和数据库中的字段值挺像的。因为字段值是可以用来确定这个表的结构
3、二维数组的使用
初始化好了,我们来用用看,将一个二维数组打印在屏幕上
for (int i = 0; i < 3; ++i)
{
for (int j = 0; j < 4; ++j)
{
printf("%d ", arr1[i][j]);
}
printf("\n");
}

-
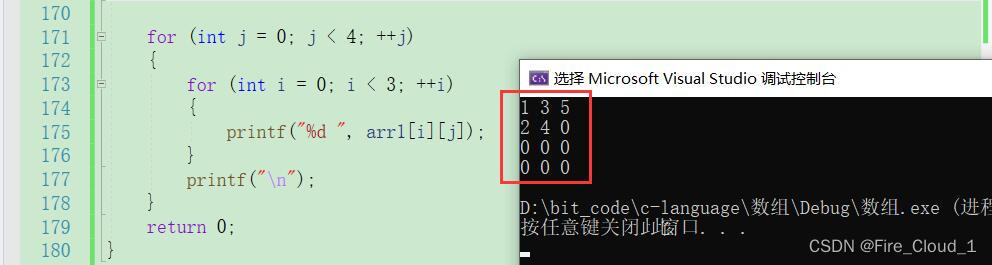
上面这种打印形式就是根据一行一行来打印的

-
我们还可以一列一列来打印,

for (int j = 0; j < 4; ++j)
{
for (int i = 0; i < 3; ++i)
{
printf("%d ", arr1[i][j]);
}
printf("\n");
}

4、二维数组在内存中的存储
然后来说说对于二维数组在内存中是如何存储的
for (int i = 0; i < 3; ++i)
{
for (int j = 0; j < 4; ++j)
{
printf("&arr[%d][%d] = %p\n", i, j, &arr1[i][j]);
}
printf("\n");
}

- 可以看到,对于二维数组来说,不难看出它在内存中是连续的,而且对于上一行的末尾元素和下一行的首元素之间的地址关系,也是呈现连续的,所以我们也可以将这个二维数组看成是一个
1行12列的一维数组
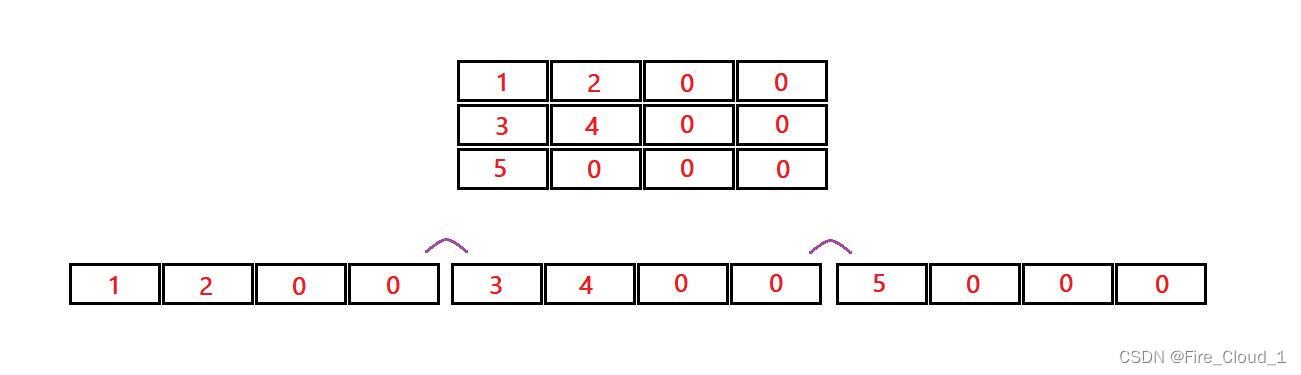
有一点正好在这里说明,因为我们下面要讲到首元素地址
- 对于一个数组的数组名来说就是这个数组的首元素地址,我们可以根据一个数组的首元素地址来访问到这个数组,然后就可以访问到这个数组中的所有内容【这一块涉及指针,本文会提及一些】
- 对于这个二维数组来说,因为它一行就是一个一维数组,因此我们就可以说
arr[1]是第一行的首元素地址arr[2]是第二行的首元素地址arr[3]是第三行的首元素地址
- 然后便可以根据每一行的首元素地址的偏移量访问到这行的所有内容
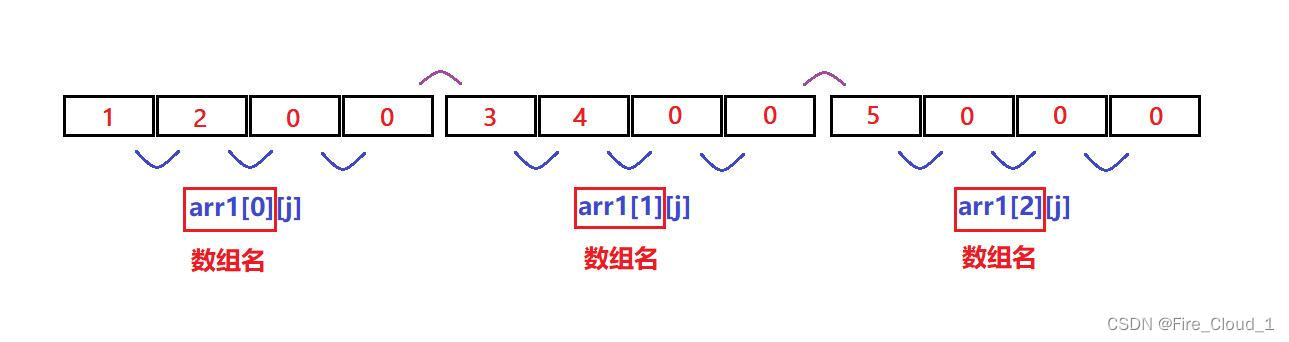
🈲数组越界
接下去我要讲得是非常重要的内容,无论是大神还是小白,都可能会犯这样错误。但是程序出现问题
❌经典错误1:边界值考虑不当导致越界访问
int main(void)
{
int arr[3][4] = { 1,2,3,4,5,6,7,8,9,10,11,12 };
for (int i = 0; i < 3; ++i)
{
for (int j = 0; j < 5; ++j)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
return 0;
}
- 可以看到,对于每一行的内部访问,从
0~4会依次访问五个元素,但是每一行只有四个元素;我刚才说过对于二维数组来说其实就相当于是一个一维数组 - 因此当本行访问完后就会去访问下一行的第一个元素。然后第二行又从下标为0的位置开始访问,==到了最后一行的时候,没有再下一行可以访问了,那第五个访问到的也就是一个随机值==
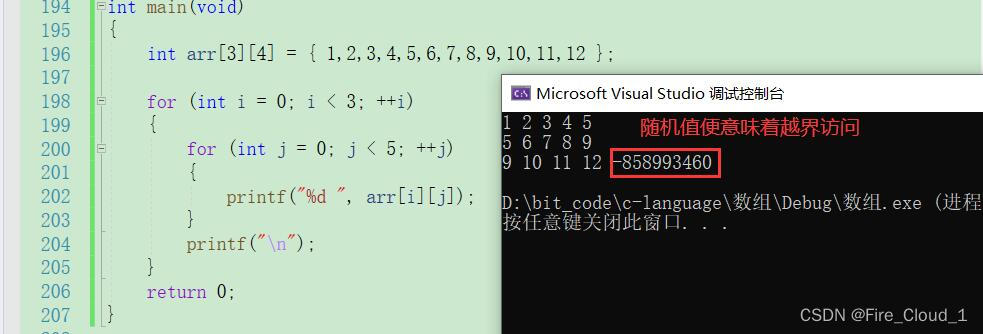
- 可以通过图示看一下在内存中是如何进行访问的

❌经典错误2:数组大小不足以承载输入的字符数
char arr[] = "";
scanf("%s", arr);
printf("%s\n", arr);
- 首先观察
arr[]并没有指定数组的大小,因此数组大小由初始化的字符个数决定。但是可以看到这里只初始化了一个空字符,也就相当于只有一个\0,那么这个数组的大小即为1。所以当我scanf输入一个长度大于1的字符串时,其实就会造成数组越界的问题【arr数组周围的堆栈被破坏即为数组越界】
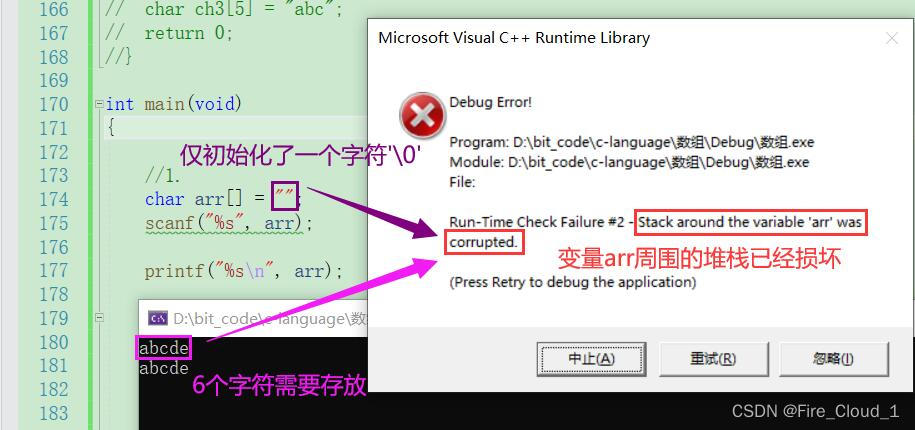
int arr1[] = { 0 };
for (int i = 0; i < 10; ++i)
{
arr1[i] = i;
}
- 对于下面这个问题其实也是一样,这个整型数组的大小为初始化内容的大小,但是下面却做了一步操作是将从
0~10这个范围内的数据都放入arr数组中,仅放入一个是没问题的,但若是再放的话就不行了,便会导致数组越界的问题
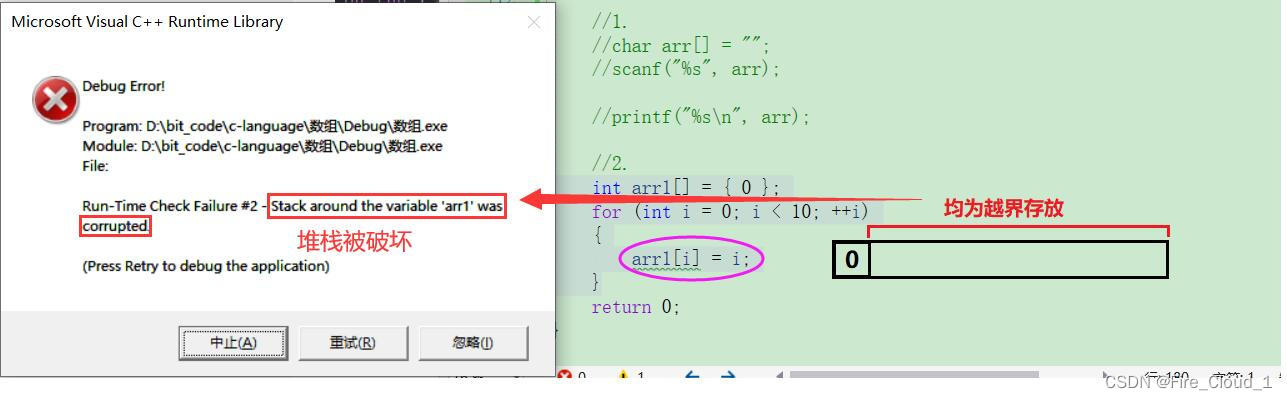
那有同学就就问为什么对于数组越界编译器察觉不了呢,因为编译器并不是探测仪,并不是所有的BGU它都可以抓得到,就像警察一样并不是每个小偷它都可以抓得到,这样应该是很形象了
数组作为函数参数【⭐】
1、冒泡排序函数的错误设计【初探】
对于冒泡排序来说,如果有不懂的可以看看我的这篇文章 ——> 十大排序超硬核八万字详解🦌
- 然后让我们来看看错误的冒泡排序
void PrintArray(int* a, int n)
{
for (int i = 0; i < n; ++i)
{
printf("%d ", a[i]);
}
printf("\n");
}
void BubbleSort(int a[10])
{
int n = sizeof(a) / sizeof(a[0]);
for (int i = 0; i < n - 1; ++i)
{
for (int j = 0; j < n - 1 - i; ++j)
{
if (a[j] > a[j + 1])
{
int t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
}
}
}
}
int main(void)
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
PrintArray(arr, sz);
BubbleSort(arr);
PrintArray(arr, sz);
return 0;
}
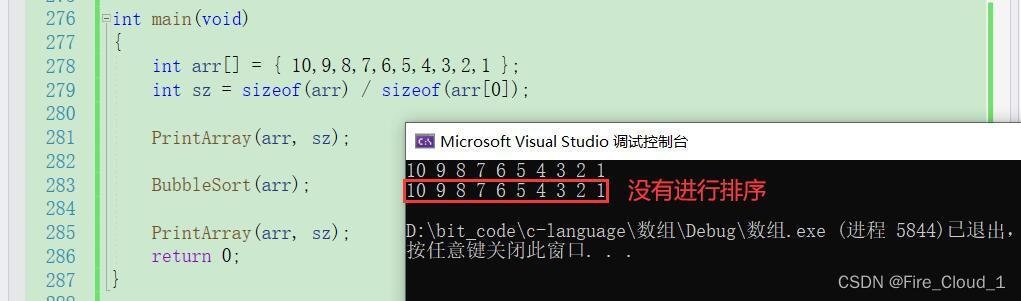
- 为什么会发生这样的情况呢,我们通过DeBug来调试看看
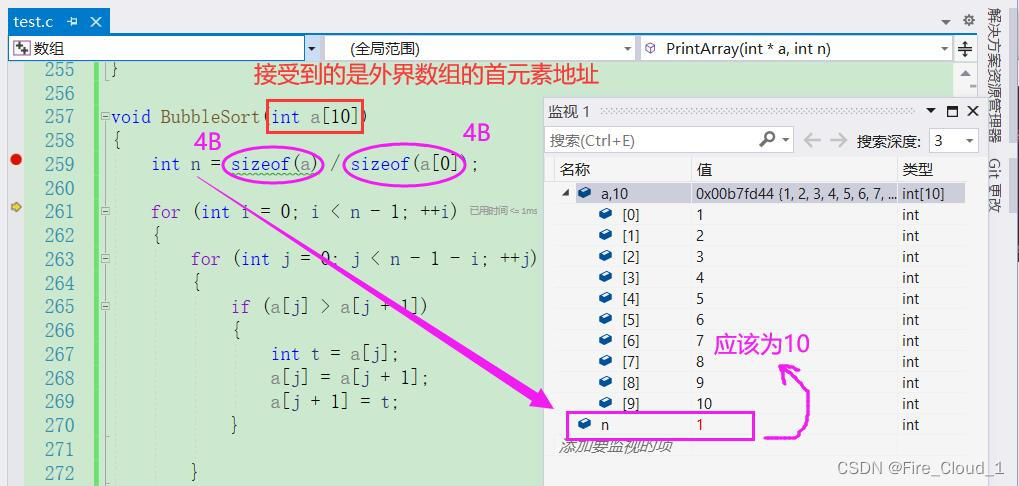
想知道上面的n算出来为什么是1吗,在下一小节将会揭晓👇
2、数组名意味着什么?
- 对于数组名而言,当我们将一个数组作为函数的参数进行传递的时候,传入的仅仅这个数组的
首元素地址,而并不是把整个数组作为参数传递过去,这一点对于编译器来说是做不到的 - 当我们将这个数组的首元素地址传过去之后,形参接收到了,便可以从这个地址向后进行偏移,每次偏移4个字节【4B】,便可以做到访问这个数组中的所有元素
既然是这样的话,就可以说得通了,为什么这个n算出来为1。
- 因为在形参部分并不是接收到的整个数组,而是这个数组的首元素地址,所以
sizeof(a)计算的便是首元素的字节大小,而sizeof(a[0])计算的也是数组中第一个元素的大小。这两个值计算出来都是4B,那么相除便得到了1
既然讲到了数组名这个东西,我就讲一下有关数组名相关的知识点。好做一个区分
① 特殊情况1:sizeof(数组名)
📚 sizeof(数组名)求解的是整个数组的字节大小
- 你觉得使用
sizeof(arr)最后打印出来的结果是多少呢❓
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
printf("%d\n", sizeof(arr));

- 可以看到输出的结果为【40】,我们刚才说到数组名指的是首元素地址,刚才在【冒泡排序】中计算
sizeof(a)得出的结果为4B,但是这个为什么是40B呢 - 你只需要记住
sizeof(数组名)计算的就是整个数组的大小,因为arr数组中有十个元素,一个整型元素占4个字节,所以整个数组的大小即为40B
② 特殊情况2:&数组名
📚 &数组名为整个数组的地址
- 再来看看另外一种情况。对于下面这三种,你认为会是怎样的打印结果呢?
printf("%p\n", &arr[0]);
printf("%p\n", arr);
printf("%p\n", &arr);
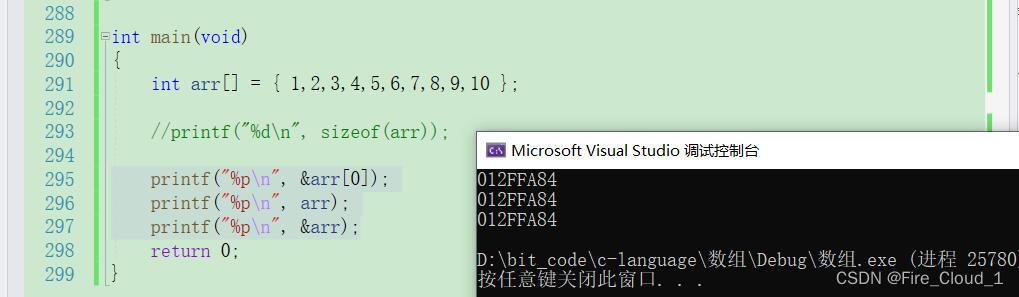
- 可以看到,三个打印出来的结果都是一样的,对于第一个
arr[0]指的是首元素①,&arr[0]指的便是首元素的地址;对于arr来说也是一样为首元素地址 - 而对于&arr来说,指的则是整个数组的地址,它和数组首元素地址是一样的,所以三者地址相同
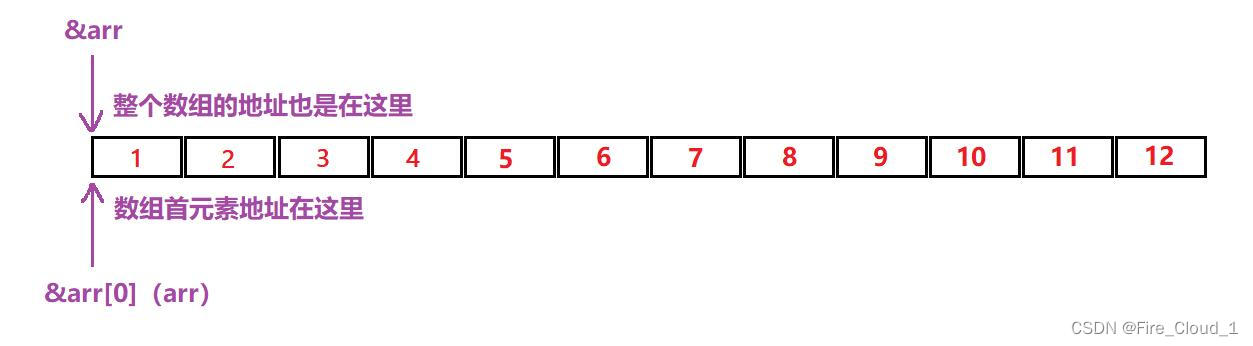
③ 小结
来总结一下上面所说的三种情况
📚 &数组名:数组名表示整个数组。取出的是整个数组的地址
📚 sizeof(数组名):数组名表示整个数组。求解的是整个数组的大小,单位是字节
📚 除此之外见到数组名全部都为该数组的首元素地址
3、冒泡排序函数的改进【再探】
了解了单单出现数组名为首元素地址,我们便可以对上面所写的冒泡排序做一个改进了
- 通过上面的分析可以知晓出错的地方是在数组的个数,所以我们在排序外头计算完再把这个数组的大小传进去就行
- 对于函数传参需要传几个参数,需要传什么参数,这一块相信是很多初学者非常头痛的地方,没有大量的代码练习是做不到那么娴熟,所以一定要==多写多练多思考,勤学勤问勤动脑==
void BubbleSort(int a[10], int n)
BubbleSort(arr, sz);
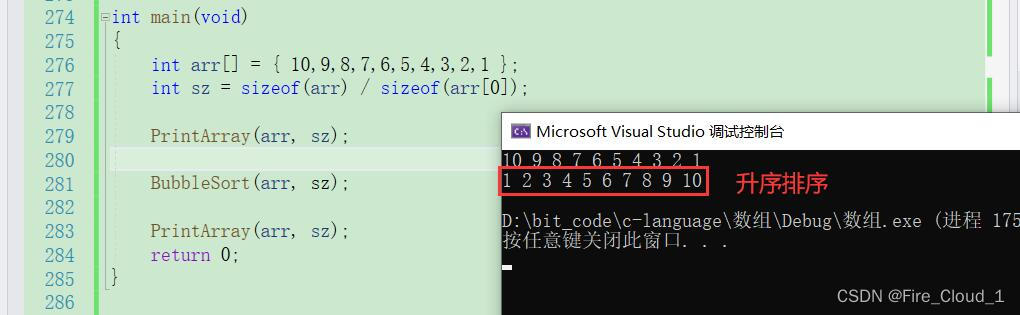
- 可以看到在经过修改之后我们的冒泡排序就成功了,但是这还没完,还可以继续做一个改进👇
4、数组地址与指针(你好,☞指针)
① 数组地址偏移量与指针偏移量
- 首先对于一个数组而言,我们如果可以得到它的首元素地址,然后通过这个地址就可以顺藤摸瓜🍈就可以获取到后面的所有元素
- 但是光这么直接用
arr[0]来访问太累了,不妨我们将数组的首元素地址给到一个指针变量,让它保存下这个地址,然后让它逐步地向后移动。如果对指针还不是很了解的看看这篇文章——> 底层之美,莫过于C【1024,从0开始】先去了解一下什么是指针
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = &arr[0];
- 可以看到,指针变量里面存放着的是数组arr的首元素地址,那我们现在要通过这个指针变量去访问到后面的所有元素该怎么做呢?
- 首先我们考虑先访问到第二个元素,要访问到一个元素首先考虑找到这个元素所在的地址,
p指针第一个元素所在的地址,那么p + 1便是指向2所在元素的地址,那要访问到这个地址上所在的内容,那就要使用到*这个符号,对这块地址进行解引用*(p + 1),此时就可以访问到2这个元素了。那找3,找4也是一样的,只需要让这个指针向后偏移即可,所以我们可以通过循环去找,访问第i个元素便是*(p + i) - 可能有些同学还是不太理解,没关系,我们通过代码来验证一下
for (int i = 0; i < 10; ++i)
{
printf("%p == %p\n", p + i, &arr[i]);
}
printf("\n");
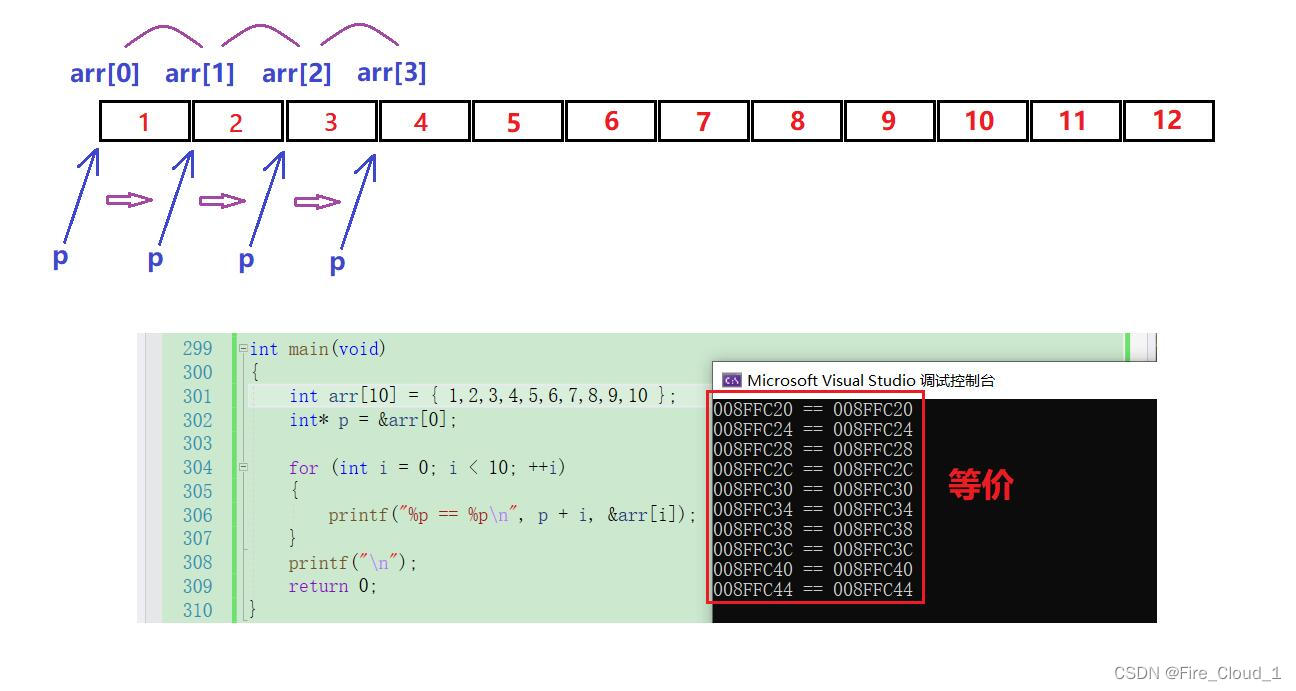
- 可以看到,无论是对于
p + i还是&arr[i],它们每次所访问的地址都是一样的,这其实也就意味着指针变量p在偏移的过程中相当于在代替数组首元素地址向后偏移
有了这些知识作为铺垫,我们就可以去尝试访问数组中的所有内容了
因为一维数组是一块连续的存储空间,所以我们只要得到这个数组的首元素地址。就可以通过p + i这样的方式找到它之后所有元素的地址,并且把他们地址进行解引用便能访问到数组中的所有元素
int main(void)
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = &arr[0];
for (int i = 0; i < 10; ++i)
{
printf("%d ", *(p + i));
}
printf("\n");
return 0;
}

- 可以看到,通过将数组的首元素地址给到指针变量p,然后再使这个指针变量一位一位地向后偏移,每次偏移一个元素即4个字节,第i个元素的地址即为
p + i,而当我们要去访问这个地址的内容时,直接对其进行解引用即可*(p + i),然后便可以看到数组中的十个元素都被打印出来了
② 指针变量与数组名的置换【✔】
- 继续回归我们的【数组名 == 首元素地址】,那不妨
int* p = &arr[0]便可以写成int* p = arr,Ctrl + F5让代码走起来可以看到结果也是一样的
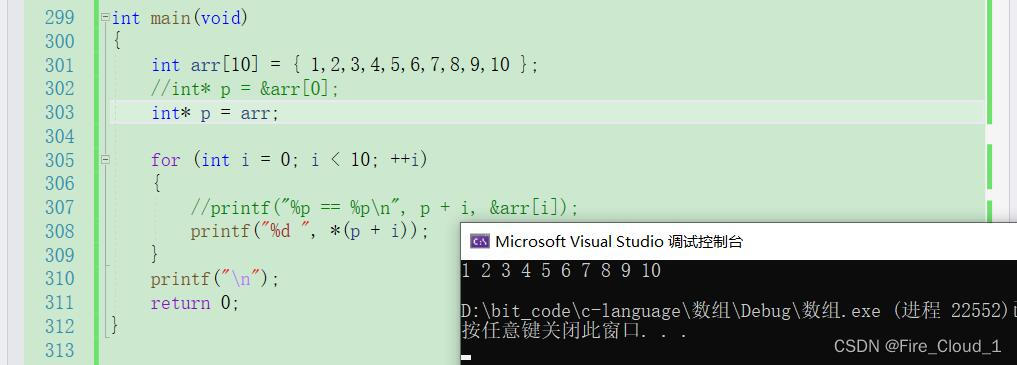
- 那我这么做就相当于是把arr赋给了p,那此时
arr和p也就是一回事,那也可以说【arr <==> p】,所以我们在使用到arr的地方可以换成p,使用到p的地方可以换成arr

- 那这个时候突然就想到一点我们上面在打印数组元素的时候都是使用
arr[i],那此时是不是可以将arr[i]和*(arr + i)做一个联系呢?当然是可以的:smile:
- 因为arr为数组名,数组名表示这个数组的首元素地址。首元素地址向后偏移i个位置之后到达下标为i的那个元素所在的位置,再对其进行解引用就找到下标为i这个地址所对应的元素——这也就是对于【*(arr + i)】的一个解释
- 那对于【arr[i]】又要怎么去解释呢?还记得我一开始讲一维数组的使用时说到
[]是一个数组访问的操作符,那既然是操作符的话就会有操作数,操作数是谁呢?就是【arr】和【i】,那此时当我将arr[i]转换成*(arr + i)的时候,()里面的也就是这两个操作数,根据==加法的交换律==就可以将【arr】和【i】进行一个交换,那也就变成了*(i + arr)。 - [x] 此时就可以去进行一个类推,因为
*(arr +i)可以写成arr[i]<—— ⭐ - [x] 那么
*(i + arr)是否可以写成i[arr]呢 <——⭐
此时我们通过代码来尝试一下,将推测转化为实际
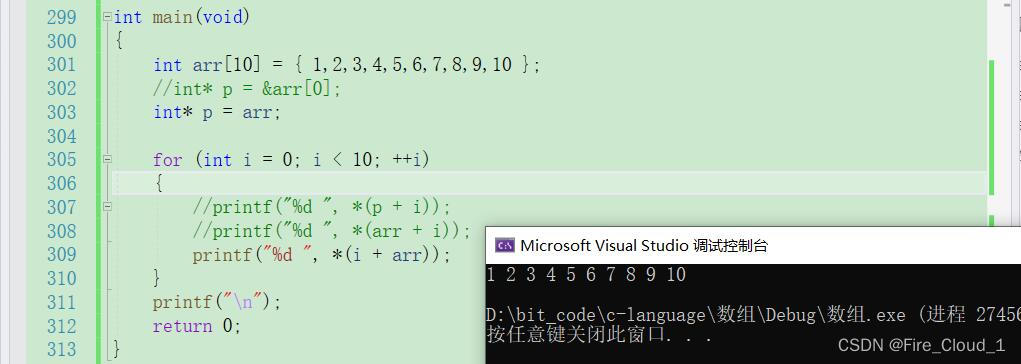
- 可以看到,依旧是可以的w(゚Д゚)==不过这种写法了解一下即可,不是很好理解,也不会用到==
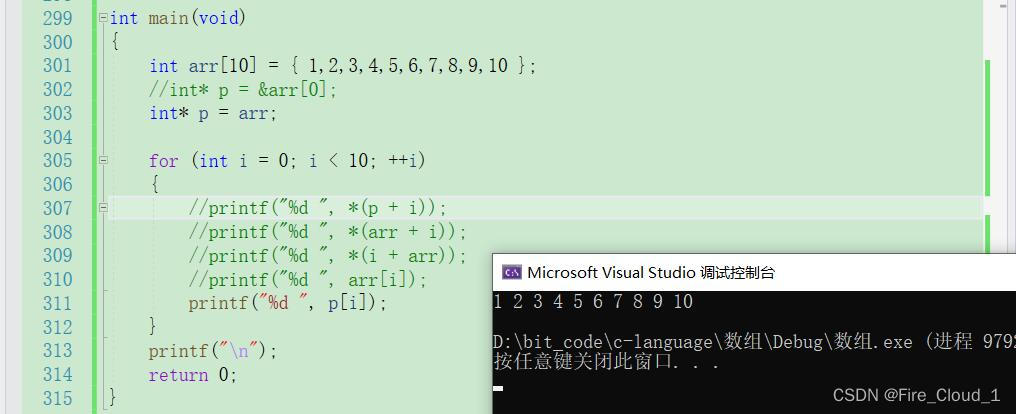
- 刚才有说到
arr和p其实是一回事,那可以写【arr[i]】,是不是也可以写成【p[i]】呢?答案是:当然可以!
③ 小结【柳暗花明又一村】
看完上面的这些,相信你已经晕了(((φ(◎ロ◎;)φ))),不过没有关系,将知识点做个总结就可以很清晰了
arr[i] == *(arr + i) == *(p + i) == p[i]
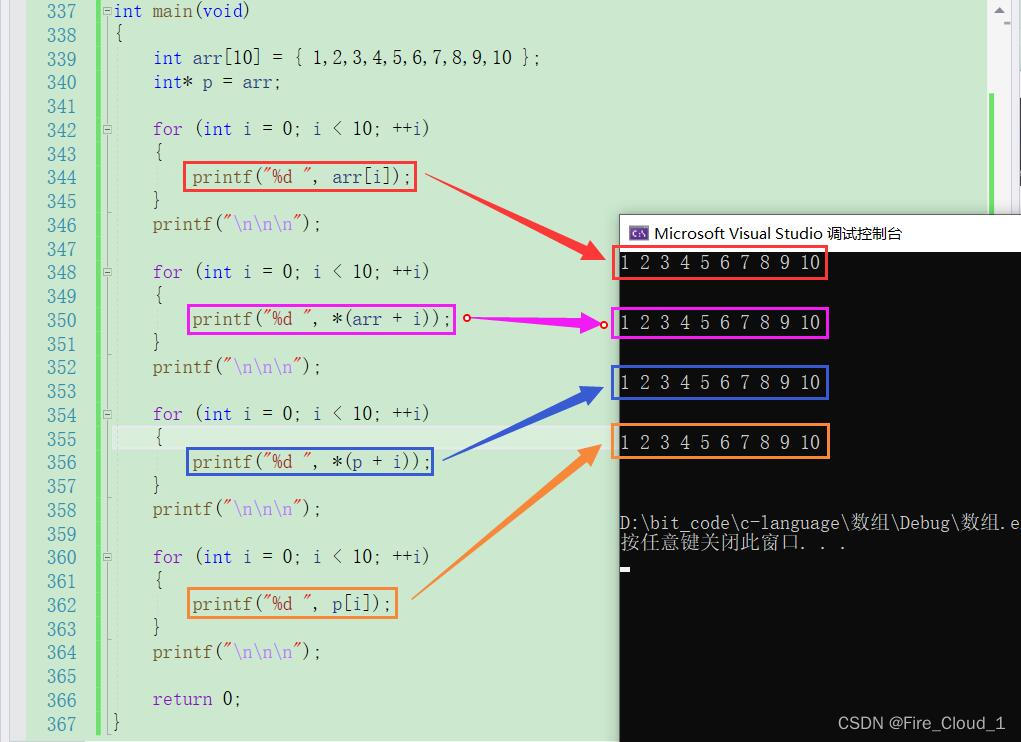
int main(void)
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = arr;
for (int i = 0; i < 10; ++i)
{
printf("%d ", arr[i]);
}
printf("\n\n\n");
for (int i = 0; i < 10; ++i)
{
printf("%d ", *(arr + i));
}
printf("\n\n\n");
for (int i = 0; i < 10; ++i)
{
printf("%d ", *(p + i));
}
printf("\n\n\n");
for (int i = 0; i < 10; ++i)
{
printf("%d ", p[i]);
}
printf("\n\n\n");
return 0;
}
✒总结与提炼
来总结一下本文所讲述的内容
- 在本文中,首先是带大家初步认识了【一维数组】和【二维数组】,清楚它们的一些概念之后,便开始研为何数组在有些时候会产生越界的情况,我们分析了两大类,一类是
边界值的问题,一类则是数组容量不够导致,它们都会导致数组在使用的过程中出现错误 - 最后我们讨论了如何将数组作为函数的参数进行一个传递,以经典的冒泡排序作为案例进行讲解,一步步地说明了在【传参的时候】要注意的事项以及【数组与指针之间的关系】
- 在通过我给大家总结出来的
arr[i] == *(arr + i) == *(p + i) == p[i],是否对数组和指针之间的关系有了进一步的了解呢


- 点赞
- 收藏
- 关注作者
评论(0)