秒懂算法 | RIB算法


结合微观行为序列的推荐(recommendation with sequences of micro behaviors, RIB)在物品序列的基础上,加入了对异构行为和停留时间的建模。对异构行为的建模使得模型能够捕捉更加细粒度的用户兴趣,而用户在某个页面上的停留时间则反映了用户对这个页面的感兴趣程度,并且停留时间越长,购买商品的转化率通常也会越高。
01、RIB算法原理
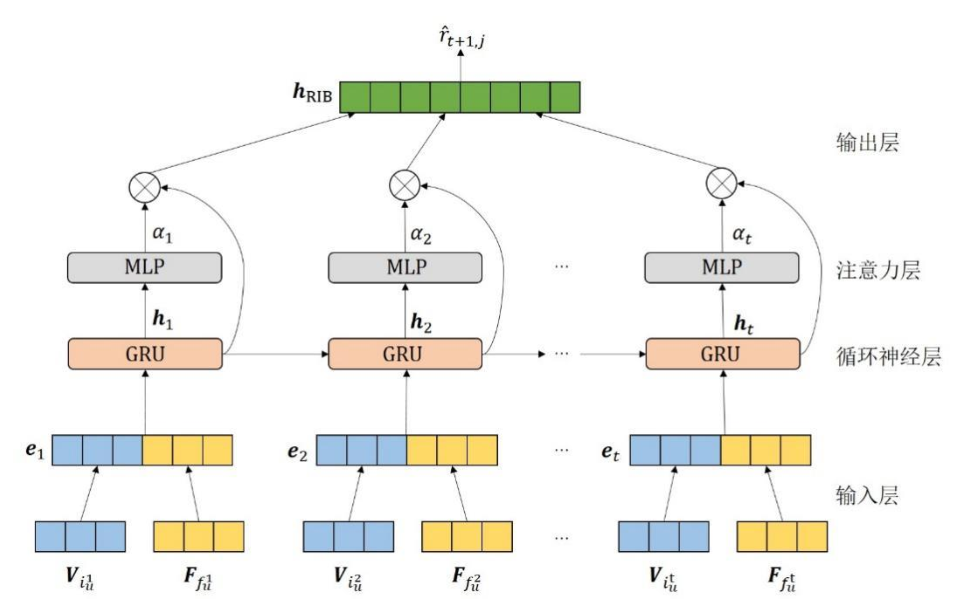
■ 图1 RIB算法的模型结构示意图
RIB算法的模型结构如图1所示,从下往上依次是输入层、循环神经层、注意力层和输出层。输入层将每个物品和其相应的行为分别编码为物品潜在特征和行为潜在特征,并将它们拼接成一个融合了物品信息和行为信息的特征向量。循环神经层将从输入层得到的特征作为输入,使用门控循环网络(GRU)来建模多行为序列,从而得到每个时间步的隐藏状态。将循环神经层每个时间步输出的隐藏状态经过一个注意力层,得到每个时间步的注意力分数。输出层将每个时间步的注意力分数和隐藏状态相乘后相加,最终得到一个能够表示用户异构行为序列的特征向量,并基于这个特征向量来预测用户对物品的偏好。以下介绍RIB算法的具体细节。
在输入层中,对于异构行为序列图片中的每个(物品,行为)对中的物品

和行为,分别使用物品潜在特征

和行为潜在特征

来表示,并使用拼接操作来得到每个时间步t的输入

:

其中,

使用word2vec算法进行初始化
在循环神经层中,比较了长短期记忆网络(long short-term memory, LSTM)和GRU,由于后者具有更加简洁的结构和更快的训练速度,最终选择了GRU作为循环神经层中的主体结构。在时间步t,GRU接收特征向量

和t-1时间步GRU的隐藏状态

作为输入,经过内部的门控结构得到当前的隐藏状态

。GRU内部包含两个门控结构,分别是重置门和更新门,在这里我们列出相应的计算公式:

其中,

都是GRU内部的模型参数。

表示sigmoid激活函数,

分别表示重置门和更新门的输出,

是从GRU内部记忆单元得到的输出,

时间步输出的隐藏状态。
虽然

已经能够表达整个多行为序列的信息,但RIB算法进一步使用了一个注意力层来建模各个微观行为的影响,进而为每个时间步的隐藏状态分配适当的权重。具体来说,注意力层的输入是循环神经层上每个时间步的隐藏状态

,它的输出是相应的注意力权重

:

其中,

,它们都是待训练的模型参数。得到的

代表时间步t隐藏状态

的注意力权重。注意层的重要性有两个方面。首先,它模拟了序列中不同微观行为对推荐的不同影响。其次,基于注意力的算法具有较好的可解释性,因为我们可以通过注意力层分配给每一步的权重来了解算法的工作原理。在输出层,RIB使用加权求和的方式来汇总每个时间步的信息,进而得到输出向量

:

最后,可以通过将输出向量

经过一层全连接层得到对每个物品的预测分数,并应用softmax函数得到一个概率分布

:

其中,

是待学习的参数。最终RIB使用交叉熵损失函数来训练整个模型,最终的损失函数如下:

其中,当且仅当物品j是序列s下一个真实交互的物品时,

。
02、RIB算法实现
在实验的设置方面,对于常见的数据集,可以设置潜在特征向量的维度d=64,学习率0.001,以及dropout率0.5就可以获得比较好的效果。
为了展示更多关于RIB算法的细节,根据自己的理解实现了基于TensorFlow 1.14的代码,并验证了代码的正确性和算法的有效性,下面截取展示RIB中的一些关键代码。
import tensorflow as tf
class RIB:
def __init__(self, emb_size,learning_rate,item_num,seq_len):
'''
:参数 emb_size: 潜在特征向量维度
:参数learning_rate: 学习率
:参数item_num: 物品数
:参数seq_len: 输入序列长度
'''
self.seq_len = seq_len
self.learning_rate = learning_rate
self.emb_size = emb_size
self.hidden_size = emb_size
self.behavior_num = 2
self.item_num=int(item_num)
# 初始化相关的潜在特征,这里使用随机初始化
self.all_embeddings=self.initialize_embeddings()
# 定义RIB模型的输入
self.item_seq = tf.placeholder(tf.int32, [None, seq_len],name='item_seq')
self.len_seq=tf.placeholder(tf.int32, [None],name='len_seq')
self.target= tf.placeholder(tf.int32, [None],name='target')
self.is_training = tf.placeholder(tf.bool, shape=())
self.behavior_seq = tf.placeholder(tf.int32, [None, seq_len])
# 输入层
self.behavior_emb = tf.nn.embedding_lookup(self.all_embeddings['behavior_embeddings'], self.behavior_seq)
self.input_emb=tf.nn.embedding_lookup(self.all_embeddings['item_embeddings'],self.item_seq)
self.new_input_emb = tf.concat([self.input_emb,self.behavior_emb],axis=2)
# 循环神经层
self.gru_out, self.states_hidden= tf.nn.dynamic_rnn(
tf.contrib.rnn.GRUCell(self.emb_size),
self.new_input_emb,
dtype=tf.float32,
sequence_length=self.len_seq,
)
# 注意力层
self.att_net = tf.contrib.layers.fully_connected(self.gru_out, self.hidden_size,activation_fn=tf.nn.tanh, scope="att_net1")
self.att_net = tf.contrib.layers.fully_connected(self.att_net, 1,activation_fn=None, scope="att_net2") # batch,state_len,1
mask = tf.expand_dims(tf.not_equal(self.item_seq, item_num),-1)
paddings = tf.ones_like(self.att_net) * (-2 ** 32 + 1)
self.att_net = tf.where(mask, self.att_net, paddings) # [B, 1, T]
self.att_net = tf.nn.softmax(self.att_net,axis=1)
# 输出层
self.final_state = tf.reduce_sum(self.gru_out * self.att_net,axis=1)
with tf.name_scope("dropout"):
self.final_state = tf.layers.dropout(self.final_state, rate=args.dropout_rate,seed=args.random_seed,training=tf.convert_to_tensor(self.is_training))
self.output = tf.contrib.layers.fully_connected(self.final_state,self.item_num,activation_fn=tf.nn.softmax,scope='fc')
self.loss = tf.keras.losses.sparse_categorical_crossentropy(self.target,self.output)
self.loss = tf.reduce_mean(self.loss)
self.opt = tf.train.AdamOptimizer(self.learning_rate).minimize(self.loss)
def initialize_embeddings(self):
all_embeddings = dict()
item_embeddings= tf.Variable(tf.random_normal([self.item_num, self.hidden_size], 0.0, 0.01),name='item_embeddings')
padding = tf.zeros([1,self.hidden_size],dtype= tf.float32)
item_embeddings = tf.concat([item_embeddings,padding],axis=0)
behavior_embeddings = tf.Variable(tf.random_normal([self.behavior_num, self.hidden_size], 0.0, 0.01),name='behavior_embeddings')
padding = tf.zeros([1,self.hidden_size],dtype= tf.float32)
behavior_embeddings = tf.concat([behavior_embeddings,padding],axis=0)
all_embeddings['item_embeddings']=item_embeddings
all_embeddings['behavior_embeddings'] = behavior_embeddings
return all_embeddings
- 点赞
- 收藏
- 关注作者
评论(0)