秒懂算法 | 推荐系统常用数据集和验证方法


推荐系统常用数据集和验证方法
01、推荐技术简介
在大数据和人工智能时代,智能推荐系统和技术已经成为电商、资讯、娱乐、教育、旅游和招聘等众多在线服务平台的核心技术、标准配置和重要引擎,用于帮助用户从海量物品中快速地找到他们感兴趣的物品(例如商品、新闻、视频、课程、景点和岗位等),特别是用户不容易发现的长尾物品(tail items),有效地缓解了信息过载(information overload)问题。例如,抖音海外版TikTok推荐算法凭借其精准的视频推荐和有效的新领域拓展等功能,被《麻省理工科技评论》(MIT Technology Review)评为2021年全球十大突破性技术之一。需要说明的是,物品可以是一组物品(例如旅游套餐推荐等),而用户也可以是一群用户(例如户外集体活动推荐等)。同时,有些场景中用户也可以作为“物品”,例如社交平台上的好友推荐等,即给用户推荐有相似兴趣的用户。
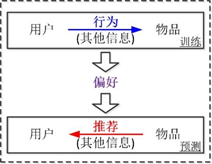
如图1-1所示,在推荐系统中,通过对用户行为和其他信息的建模,相关算法和技术能较为有效地挖掘和学习用户的真实偏好,进而为用户提供精准的个性化推荐服务,这一过程可以简单地概括为“行为→偏好→推荐”。与信息检索中的“查询串→相关性→匹配”相比,至少可以看到两方面的重要区别:
(1)行为 vs. 查询串,前者关注用户与系统的互动,后者侧重用户主动查询的内容;以及
(2)偏好 vs. 相关性,前者关注用户的个性化需求,后者侧重查询串与候选文档(或网页)在内容方面的匹配程度。
在电商、资讯等众多应用场景中,相较于物品的描述、用户的画像和行为的上下文等其他信息,用户行为往往是与用户的偏好最直接相关的,例如,用户购买商品和阅读新闻等的行为较能体现用户的喜好和兴趣。因此,对用户行为数据的建模,受到了学术界和工业界的广泛关注,并且在知名学术期刊和学术会议上发表了大量相关的研究论文(请参见附录1和附录2)。美国国防部(Department of Defense, DoD)也在2014年将一个类似的问题——对人类行为的计算机建模——列为六大颠覆性基础研究领域之一。
在推荐系统领域,科研人员对用户的各种行为数据进行了较为深入的研究,主要包括以下几种类型:
(1)显式反馈,例如用户对物品的1~5分的数值评分(numerical rating)行为和喜欢/不喜欢的二值评分(binary rating)行为,以及点赞(like)等单值行为;
(2)隐式反馈(又称为单类反馈),例如用户对物品的点击(click)、浏览(browse/view/examination)、收藏(collect/favorite)、加入购物车(add-to-cart)和购买(purchase)等行为;
(3)异构反馈,例如同时包含两种或两种以上的显式反馈和/或隐式反馈;以及
(4)序列反馈,例如在隐式反馈中包含时序信息。
需要说明的是,在一个真实的应用中,为了更加准确地学习用户偏好,我们除了需要考虑上述的多类型行为(multi-type behavior),还可以考虑:
(1)多方面行为(multi-aspect behavior),如用户对物品的价格、质量和售后服务等不同方面的反馈;
(2)多粒度行为(multi-granularity behavior),如用户对商品、品牌、商家和品类等不同粒度的反馈;
(3)多模态行为(multi-modal behavior),如文本评论行为和数值反馈行为等;以及
(4)多领域行为(multi-domain behavior),如用户在电商、资讯和社交等不同领域的行为。
02、常用数据集和验证方法
1●常用数据集
1)MovieLens电影评分数据集
MovieLens电影评分数据集是推荐算法研究中最常用的数据集之一,由美国明尼苏达大学(University of Minnesota)的GroupLens研究组收集和发布,包含了多个在不同时间段内收集到的规模各不相同的子数据集,例如,最经典的由943个用户对1682部电影的100,000条评分记录组成的MovieLens 100K数据集(1998年4月发布)、由6040个用户对3952部电影的1,000,209条评分记录组成的MovieLens 1M数据集(2003年2月发布)和由71567个用户对10681部电影的10,000,054条评分记录组成的MovieLens 10M数据集(2009年1月发布),以及较新的在2019年12月发布的MovieLens 25M数据集,等等。考虑到推荐系统数据的稀疏性问题,MovieLens数据集中仅保留了评分记录数不小于20的用户的数据。并且,除了最基本的(用户ID,物品ID,评分,时间戳)信息外,MovieLens数据集还提供了一些用户的基本信息(性别、年龄和职业)和物品的描述信息(电影名、电影类型和上映日期)。
2)Netflix电影评分数据集
Netflix电影评分数据集也是一个推荐算法研究中常用的历史比较悠久的数据集,由电影租赁网站Netflix在2005年底发布,用于Netflix百万美元竞赛,以激励人们设计和开发更好的推荐算法。Netflix数据集中包含了在1998年10月至2005年12月期间,480189个匿名的Netflix用户对17770部电影的99,072,112条评分记录(包含评分日期),并且包含了电影的标题和发行年份信息。
3)Amazon电商评论数据集
美国加州大学圣迭戈分校(University of California, San Diego)的Julian McAuley教授在其个人主页上发布了他的研究团队收集的一些推荐系统数据集,其中有一个从知名电商平台Amazon上收集到的关于商品的评论数据集。Amazon数据集包含了1996年5月至2014年7月期间的约1.4亿条评论数据(每条评论由评分及文字评论等组成),并且给出了一些商品的描述、类别、价格、品牌和图像特征等信息。为了方便研究,研究人员还将原数据集按照商品类别分为24个较小的子数据集,例如,图书数据集、电子产品数据集和电子游戏数据集等。
4)天猫电商多行为数据集
天猫(Tmall)电商多行为数据集[1]是在IJCAI 2015竞赛中发布的,包含了一些天猫用户在“双十一”前6个月的匿名行为日志。一条行为记录对应的信息有:用户ID、物品ID、时间戳和行为类型等等。其中,记录的行为类型包括点击、加入购物车、购买和收藏。Tmall数据集还提供了用户的性别和年龄等信息,以及物品的类别、商家和品牌等信息。
2●验证方法
1)交叉验证法
对于不考虑序列信息的推荐问题,我们可以使用交叉验证法(cross validation)来对模型进行训练和验证,具体方法为:对于一个数据集,将它随机分成k(例如k=5)个大小相同的子集,每次取其中一个子集作为测试集,其余k-1个子集共同构成训练集,如此重复次,最后取在k个不同测试集上的结果的平均值作为最终的评估结果。注意,在一些算法中,我们可能需要先使用一个较小的验证集来寻找最优的模型参数,这种情况下,我们可以先固定一个测试集作为验证集来进行调参。
2)留一法
留一法(leave-one-out)是交叉验证法的一个特例,即将数据集中的每个样本都分到一个不同的子集中(即k等于数据集的大小),只选取一个样本用作测试,其余数据全部用于训练。在推荐算法研究中,留一法多用于引入序列信息的情况。通常,为了评估模型对用户行为序列的预测能力,我们将每个用户的最后一次行为记录划入测试集,其余记录划入训练集。注意,在进行正式的模型测试前,为了调节模型参数,可以将每个用户的倒数第二次行为记录划入一个新增加的验证集,然后使用剩下的训练集数据来训练模型并观察在各参数下的表现。
3)强泛化效果验证和弱泛化效果验证
在推荐技术的验证中,比较主流的模型效果验证方法包括强泛化效果验证和弱泛化效果验证。强泛化效果验证先对用户进行划分从而得到训练集用户图片、验证集用户图片和测试集用户图片,使得图片,再将每一位用户的交互数据划分到对应的数据中。显然,验证集用户和测试集用户的交互数据没有出现在训练过程中,因此模型需要具备较强的泛化能力才能获得较好的推荐效果。弱泛化效果验证则将每一位用户的交互数据按照设定的阈值划分到训练集、验证集和测试集中,因此验证集用户和测试集用户在训练过程中会以训练集用户的角色出现并参与到训练过程中。显而易见,弱泛化效果验证在验证和测试模型效果时,需要衡量模型在每一个用户上的推荐效果,当用户数目较多时,这种验证方式相较于强泛化效果验证而言效率较低,并且由于验证集用户和测试集用户在训练中已经出现并参与了训练,因此弱泛化验证对模型泛化能力要求相对较低。

- 点赞
- 收藏
- 关注作者
评论(0)