理解整型在内存中的存储

理解整型在内存中的存储
对于整型,我想大家都不感到陌生,毕竟程序员天天都得int,int 类型的输入,强调!因此,深入理解整型在内存中的存储方式,显得尤为重要!
笔者不才!最近斗胆创建了一个名为C语言大家庭的公众号,里面记录了笔者之前的CSDN文章,感兴趣的读者请添加关注哦!
最近刚刚开始起步,急剧寻找合作伙伴!有意者请一步微信公众号私聊
对于整型:int 大家都知道,占据4个字节,但是这4个字节在内存中是怎样分配的呢?这就值得大家去思考,比如:定义:int a=10, 计算机是如何将a 的值存储在计算机中的??
想要理解笔者上面的简单举列,就需要知道:计算机中的整数有三种2进制表示方法,即原码、反码和补码。
原码、反码、补码
计算机中的整数有三种2进制表示方法,即原码、反码和补码。
三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”,而数值位
正数的原、反、补码都相同。
负整数的三种表示方法各不相同。
原码
直接将数值按照正负数的形式翻译成二进制就可以得到原码。
反码
将原码的符号位不变,其他位依次按位取反就可以得到反码
补码
反码+1就得到补码
对于整形来说:数据存放内存中其实存放的是补码
对于上述情况,笔者用代码加分析的方式来带大家分析:
#include <stdio.h>
int main()
{
int a = 20;
return 0;
}在上述代码中,我们主要看a在内存中的存储方式,因此没有用printf()函数打印出来结果!这个只能由我们调试来进行!
经过运行后的结果为: 14 00 00 00
在这里指的是16进制的运算结果!1*16^1+4*16^0=20;
什么大端小端:
大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址
中;
小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地
址中。
为什么有大端和小端??
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8 bit。但是在C语言中除了8 bit的char之外,还有16 bit的short
型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32
位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因
此就导致了大端存储模式和小端存储模式。
例如:一个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为
高字节, 0x22 为低字节。对于大端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在高
地址中,即 0x0011 中。小端模式,刚好相反。我们常用的 X86 结构是小端模式,而 KEIL C51 则
为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式
还是小端模式
上述内容可以概括为:
1.对于123(一百二十三): 1为高位,3为低位!
2.对于0x11223344在内存中的存储举列:
| 0x11 | 0x22 | 0x33 | 0x44 |
高位 低位
| 44 | 33 | 22 | 11 |
低地址 小端字节存储 (在vs中存放方式) 高地址
| 11 | 22 | 33 | 44 |
低地址 大端字节存储 高地址
下面笔者借用:
百度2015年系统工程师笔试题:
请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序。(10分)
来带领大家认识大小端:
//代码1
#include <stdio.h>
int check_sys()
{
int i = 1;
return (*(char*)&i);
}
int main()
{
int ret = check_sys();
if (ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}上述代码中,直接在main函数里面调用了check_sys() 这个函数!
在函数体部分,通过定义int i = 1; 判断在内存中的存储情况!
return (*(char*)&i);通过取地址操作符,将a 的地址取出来,在强制转化为char*类型的指针,最后解引用,然后得到第一个字节!
若是01则返回值为1,为小端,否则为00,则是大端!
上述代码的运行结果为:
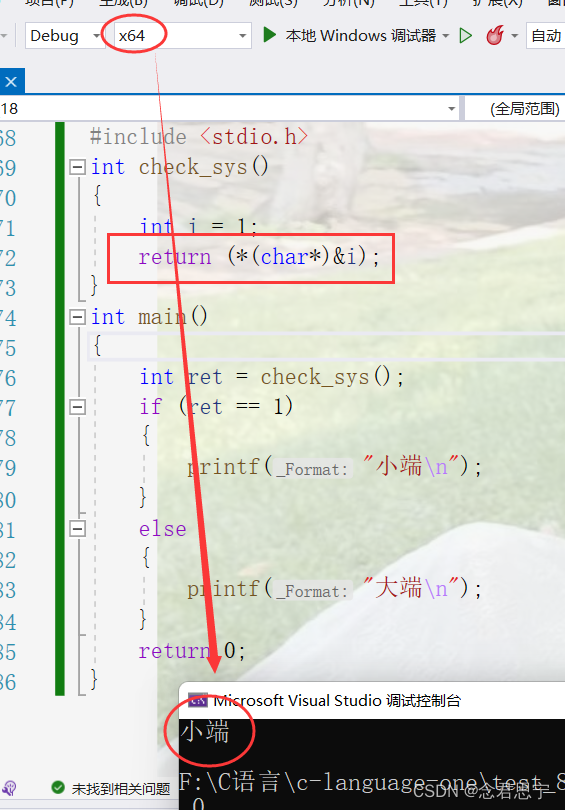
需要强调的是,这个仅仅是笔者的编译器所产生的结果,对于其他编译器,或许有着不同的情况!
因此笔者的编译器是小端存储模式!
上述代码也可以更改为:
#include <Stdio.h>
int check_sys()
{
union
{
int i;
char c;
}un;
un.i = 1;
return un.c;
}
int main()
{
int ret = check_sys();
if (ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}上述代码用union函数来涉及,该段代码,仅供参考,最后的运转结果还是一样的!
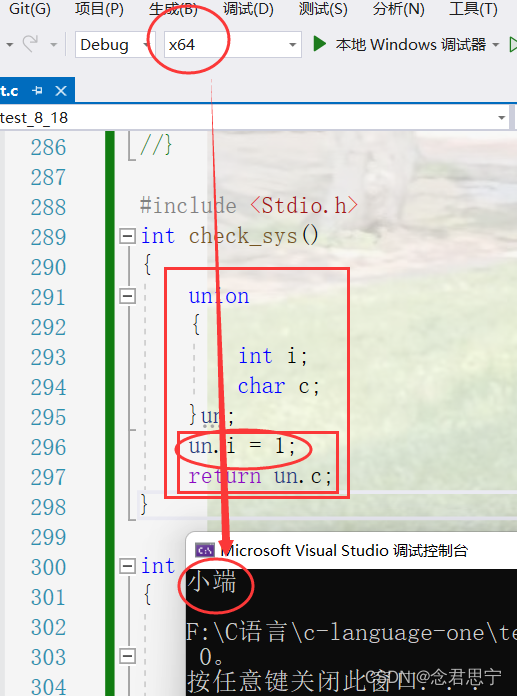
综上所述,笔者所要表达的内容已经完毕,读者若有不同的见解,请及时联系笔者!

- 点赞
- 收藏
- 关注作者
评论(0)