特定领域知识图谱融合方案:文本匹配算法之预训练Simbert、ERNIE-Gram单塔模型等诸多模型【三】

特定领域知识图谱融合方案:文本匹配算法之预训练模型SimBert、ERNIE-Gram
0.前言:特定领域知识图谱融合方案
本项目主要围绕着特定领域知识图谱(Domain-specific KnowledgeGraph:DKG)融合方案:文本匹配算法、知识融合学术界方案、知识融合业界落地方案、算法测评KG生产质量保障讲解了文本匹配算法的综述,从经典的传统模型到孪生神经网络“双塔模型”再到预训练模型以及有监督无监督联合模型,期间也涉及了近几年前沿的对比学习模型,之后提出了文本匹配技巧提升方案,最终给出了DKG的落地方案。这边主要以原理讲解和技术方案阐述为主,之后会慢慢把项目开源出来,一起共建KG,从知识抽取到知识融合、知识推理、质量评估等争取走通完整的流程。
0.1 前置参考项目
前置参考项目
1.特定领域知识图谱融合方案:技术知识前置【一】-文本匹配算法
https://blog.csdn.net/sinat_39620217/article/details/128718537
2.特定领域知识图谱融合方案:文本匹配算法Simnet、Simcse、Diffcse【二】
https://blog.csdn.net/sinat_39620217/article/details/128833057
3.特定领域知识图谱融合方案:文本匹配算法之预训练Simbert、ERNIE-Gram单塔模型等诸多模型【三】
https://blog.csdn.net/sinat_39620217/article/details/129026570
4.特定领域知识图谱融合方案:学以致用-问题匹配鲁棒性评测比赛验证【四】
https://blog.csdn.net/sinat_39620217/article/details/129026193
NLP知识图谱项目合集(信息抽取、文本分类、图神经网络、性能优化等)
https://blog.csdn.net/sinat_39620217/article/details/128805154
2023计算机领域顶会以及ACL自然语言处理(NLP)研究子方向汇总
https://blog.csdn.net/sinat_39620217/article/details/128897539
0.2 结论先看
仿真结果如下:
| 模型 | dev acc |
|---|---|
| Simcse(无监督) | 58.97% |
| Diffcse(无监督) | 63.23% |
| bert-base-chinese | 86.53% |
| bert-wwm-chinese | 86.33% |
| bert-wwm-ext-chinese | 86.05% |
| ernie-tiny | 86.07% |
| roberta-wwm-ext | 87.53% |
| rbt3 | 85.37% |
| rbtl3 | 85.17% |
| ERNIE-1.0-Base | 89.34% |
| ERNIE-1.0-Base | 89.34% |
| ERNIE-Gram-Base-Pointwise | 90.58% |
-
SimCSE 模型适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。
-
相比于 SimCSE 模型,DiffCSE模型会更关注语句之间的差异性,具有精确的向量表示能力。DiffCSE 模型同样适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。
-
明显看到有监督模型中ERNIE-Gram比之前所有模型性能的优秀
1.SimBERT(UniLM)


预训练模型按照训练方式或者网络结构可以分成三类:
- 一是以BERT[2]为代表的自编码(Auto-Encoding)语言模型,Autoencoding Language Modeling,自编码语言模型:通过上下文信息来预测当前被mask的token,代表有BERT、Word2Vec(CBOW)等.它使用MLM做预训练任务,自编码预训模型往往更擅长做判别类任务,或者叫做自然语言理解(Natural Language Understanding,NLU)任务,例如文本分类,NER等。
content
缺点:由于训练中采用了[MASK]标记,导致预训练与微调阶段不一致的问题,且对于生成式问题的支持能力较差
优点:能够很好的编码上下文语义信息,在自然语言理解(NLU)相关的下游任务上表现突出
- 二是以GPT[3]为代表的自回归(Auto-Regressive)语言模型,Aotoregressive Lanuage Modeling,自回归语言模型:根据前面(或后面)出现的token来预测当前时刻的token,代表模型有ELMO、GTP等,它一般采用生成类任务做预训练,类似于我们写一篇文章,自回归语言模型更擅长做生成类任务(Natural Language Generating,NLG),例如文章生成等。
缺点:只能利用单向语义而不能同时利用上下文信息
优点:对自然语言生成任务(NLG)友好,符合生成式任务的生成过程
- 三是以encoder-decoder为基础模型架构的预训练模,例如MASS[4],它通过编码器将输入句子编码成特征向量,然后通过解码器将该特征向量转化成输出文本序列。基于Encoder-Decoder的预训练模型的优点是它能够兼顾自编码语言模型和自回归语言模型:在它的编码器之后接一个分类层便可以制作一个判别类任务,而同时使用编码器和解码器便可以做生成类任务。
这里要介绍的统一语言模型(Unified Language Model,UniLM)[1]从网络结构上看,它的结构是和BERT相同的编码器的结构。但是从它的预训练任务上来看,它不仅可以像自编码语言模型那样利用掩码标志的上下文进行训练,还可以像自回归语言模型那样从左向右的进行训练。甚至可以像Encoder-Decoder架构的模型先对输入文本进行编码,再从左向右的生成序列。
UniLM是在微软研究院在BERT的基础上提出的预训练语言模型,被称为统一预训练语言模型。使用三种特殊的Mask的预训练目标,从而使得模型可以用于NLG,同时在NLU任务获得和BERT一样的效果
它可以完成单向、序列到序列和双向预测任务,可以说是结合了AR和AE两种语言模型的优点,UniLM在文本摘要、生成式问题回答等领域取得了SOTA的成绩
[1] Dong, Li, et al. “Unified language model pre-training for natural language understanding and generation.” Advances in Neural Information Processing Systems 32 (2019).
[2] Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[3] Radford, A., Narasimhan, K., Salimans, T. and Sutskever, I., 2018. Improving language understanding by generative pre-training.
[4] Song, Kaitao, et al. "Mass: Masked sequence to sequence pre-training for language generation."arXiv preprint arXiv:1905.02450(2019).
1.1 UniLM 模型详解
原始论文:Unified Language Model Pre-training for Natural Language Understanding and Generation
刚介绍的三种不同的类型的预训练架构往往需要使用不同的预训练任务进行训练。但是这些任务都可以归纳为根据已知的内容预测未知的内容,不同的是哪些内容是我们已知的,哪些是需要预测的。UniLM最核心的内容将用来训练不同架构的任务都统一到了一种类似于掩码语言模型的框架上,然后通过一个变量掩码矩阵M(Mask Matrix)
来适配不同的任务。UniLM所有核心的内容可以概括为下图。
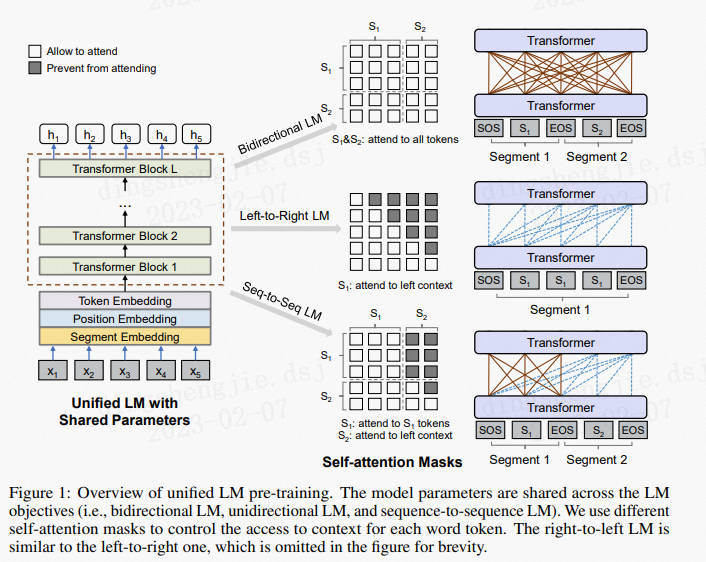
模型框架如上图所示,在预训练阶段,UniLM模型通过三种不同目标函数的语言模型(包括:双向语言模型,单向语言模型和序列到序列语言模型),去共同学习一个Transformer网络;为了控制对将要预测的token可见到的上下文,使用了不同的self-attention mask来实现。即通过不同的掩码来控制预测单词的可见上下文词语数量,实现不同的模型表征.
1.1.1 模型输入
首先对于一个输入句子,UniLM采用了WordPiece的方式对其进行了分词。除了分词得到的token嵌入,UniLM中添加了位置嵌入(和BERT相同的方式)和用于区分文本对的两个段的段嵌入(Segment Embedding)。为了得到整句的特征向量,UniLM在句子的开始添加了[SOS]标志。为了分割不同的段,它向其中添加了[EOS]标志。具体例子可以参考图中的蓝色虚线框中的内容。包括token embedding,position embedding,segment embedding,同时segment embedding还可以作为模型采取何种训练方式(单向,双向,序列到序列)的一种标识
1.1.2 网络结构
如图1红色虚线框中的内容,UniLM使用了
层Transformer的架构,为了区分使不同的预训练任务可以共享这个网络,UniLM在其中添加了掩码矩阵的运算符。具体的讲,我们假设输入文本表示为
,它经过嵌入层后得到第一层的输入
,然后经过
层Transformer后得到最终的特征向量,表示为
,再抽象编码成
的不同层次的上下文表示。在每个
块中,使用多个self-attention heads来聚合前一层的输出向量。对于第
个
层,self-attention head
的输出通过以下方。 不同于原始的Transformer,UniLM在其中添加了掩码矩阵,以第
层为例,此时Transformer转化为式(1)到式(3)所示的形式。
其中 分别使用参数矩阵 分别线性地投影到三元组Query,Key,Value中, 是我们前面多次提到过的用于控制预训练任务的掩码矩阵。通过根据掩码矩阵 确定一对tokens是否可以相互attend,覆盖被编码的特征,让预测时只能关注到与特定任务相关的特征,从而实现了不同的预训练方式.
1.1.3 任务统一
UniLM共有4个预训练任务,除了图1中所示的三个语言模型外,还有一个经典的NSP任务,下面我们分别介绍它们。
-
双向语言模型:
- MASK完形填空任务,输入的是一个文本对
- 双向语言模型是图1的最上面的任务,它和掩码语言模型一样就是利用上下文预测被掩码的部分。,与Bert模型一致,在预测被掩蔽token时,可以观察到所有的token,如上图所示,使用全0矩阵来作为掩码矩阵,模型需要根据所有的上下文分析,所以 是一个0矩阵。
-
单向语言模型:
- MASK完形填空任务,输入的是一个单独的文本
- 单向语言模型可以使从左向右也可以是从右向左,图1的例子是从左向右的,也就是GPT[3]中使用的掩码方式。在这种预测方式中,模型在预测第t时间片的内容时只能看到第t时间片之前的内容,因此 是一个上三角全为 的上三角矩阵(图1中第二个掩码矩阵的阴影部分)。同理,当单向语言模型是从右向左时, 是一个下三角矩阵。在这种训练方式中,观测序列分为从左到右和从右向左两种,从左到右,即仅通过被掩蔽token的左侧所有本文来预测被掩蔽的token;从右到左,则是仅通过被掩蔽token的右侧所有本文来预测被掩蔽的token,如上图所示,使用上三角矩阵来作为掩码矩阵,阴影部分为,空白部分为0,
-
Seq-to-Seq语言模型:
- MASK完形填空任务,输入的是一个文本对
- 如果被掩蔽token在第一个文本序列中,那么仅可以使用第一个文本序列中所有token,不能使用第二个文本序列的任何信息;如果被掩蔽token在第二个文本序列中,那么使用一个文本序列中所有token和第二个文本序列中被掩蔽token的左侧所有token预测被掩蔽token
- 如上图所示,在训练的时候,一个序列由[SOS]S_1[EOS]S_2[EOS]组成,其中S1是source segments,S2是target segments。随机mask两个segment其中的词,其中如果masked是source segment的词的话,则它可以attend to所有的source segment的tokens,如果masked的是target segment,则模型只能attend to所有的source tokens以及target segment中当前词和该词左边的所有tokens,这样模型可以隐形地学习到一个双向的encoder和单向decoder(类似transformer)
在Seq-to-Seq任务中,例如机器翻译,我们通常先通过编码器将输入句子编码成特征向量,然后通过解码器将这个特征向量解码成预测内容。UniLM的结构和传统的Encoder-Decoder模型的差异非常大,它仅有一个多层的Transformer构成。在进行预训练时,UniLM首先将两个句子拼接成一个序列,并通过[EOS]来分割句子,表示为:[SOS]S1[EOS]S2[EOS]。在编码时,我们需要知道输入句子的完整内容,因此不需要对输入文本进行覆盖。但是当进行解码时,解码器的部分便变成一个从左向右的单向语言模型。因此对于句子中的第1个片段(S1部分)对应的块矩阵,它是一个0矩阵(左上块矩阵),对于的句子第2个片段(S2部分)的对应的块矩阵,它是上三角矩阵的一部分(右上块矩阵)。因此我们可以得到图1中最下面的 。可以看出,UniLM虽然采用了编码器的架构,但是在训练Seq-to-Seq语言模型时它也可以像经典的Encoder-to-Decoder那样关注到输入的全部特征以及输出的已生成的特征。
- NSP:UniLM也像BERT一样添加了NSP作为预训练任务。对于双向语言模型(Bidirectional LM),与Bert模型一样,也进行下一个句子预测。如果是第一段文本的下一段文本,则预测1;否则预测0
1.1.4 训练与微调
训练:在训练时,1/3的时间用来训练双向语言模型,1/3的时间用来训练单向语言模型,其中从左向右和从右向左各站一半,最后1/3用了训练Encoder-Decoder架构。
微调:对于NLU任务来说,我们可以直接将UniLM视作一个编码器,然后通过[SOS]标志得到整句的特征向量,再通过在特征向量后添加分类层得到预测的类别。对于NLG任务来说,我们可以像前面介绍的把句子拼接成序列“[SOS]S1[EOS]S2[EOS]”。其中S1是输入文本的全部内容。为了进行微调,我们会随机掩码掉目标句子S2的部分内容。同时我们可会掩码掉目标句子的[EOS],我们的目的是让模型自己预测何时预测[EOS]从而停止预测,而不是预测一个我们提前设置好的长度。
- 网络设置:24层Transformer,1024个hidden size,16个attention heads
- 参数大小:340M
- 初始化:直接采用Bert-Large的参数初始化
- 激活函数:GELU,与bert一样
- dropout比例:0.1
- 权重衰减因子:0.01
- batch_size:330
- 混合训练方式:对于一个batch,1/3时间采用双向语言模型的目标,1/3的时间采用Seq2Seq语言模型目标,最后1/3平均分配给两种单向学习的语言模型,也就是left-to-right和right-to-left方式各占1/6时间
- MASK方式:总体比例15%,其中80%的情况下直接用[MASK]替代,10%的情况下随机选择一个词替代,最后10%的情况用真实值。还有就是80%的情况是每次只mask一个词,另外20%的情况是mask掉bi-gram或者tri-gram
1.1.5 小结
UniLM和很多Encoder-Decoder架构的模型一样(例如MASS)像统一NLU和NLG任务,但是无疑UniLM的架构更加优雅。像MASS在做NLU任务时,它只会采用模型的Encoder部分,从而丢弃了Decoder部分的全部特征。UniLM有一个问题是在做机器翻译这样经典的Seq-to-Seq任务时,它的掩码机制导致它并没有使用表示[SOS]标志对应的全句特征,而是使用了输入句子的序列。这个方式可能缺乏了对整句特征的捕获,从而导致生成的内容缺乏对全局信息的把控。此外,UniLM在五个NLG数据集上的表现优于以前的最新模型:CNN/DailyMail和Gigaword文本摘要、SQuAD问题生成、CoQA生成问题回答和DSTC7基于对话生成,其优势总结如下:
- 三种不同的训练目标,网络参数共享
- 网络参数共享,使得模型避免了过拟合于某单一的语言模型,使得学习出来的模型更加具有普适性
- 采用了Seq2Seq语言模型,使得其在能够完成NLU任务的同时,也能够完成NLG任务
1.2 SimBert
1.2.1 融合检索和生成的SimBERT模型
基于UniLM思想、融检索与生成于一体的BERT模型。
权重下载:https://github.com/ZhuiyiTechnology/pretrained-models
UniLM的核心是通过特殊的Attention Mask来赋予模型具有Seq2Seq的能力。假如输入是“你想吃啥”,目标句子是“白切鸡”,那UNILM将这两个句子拼成一个:[CLS] 你 想 吃 啥 [SEP] 白 切 鸡 [SEP],然后接如图的Attention Mask:

换句话说,[CLS] 你 想 吃 啥 [SEP]这几个token之间是双向的Attention,而白 切 鸡 [SEP]这几个token则是单向Attention,从而允许递归地预测白 切 鸡 [SEP]这几个token,所以它具备文本生成能力。
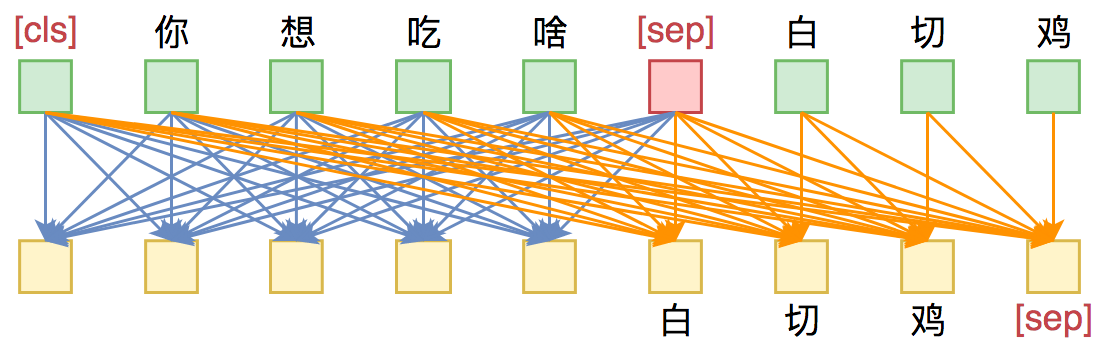
Seq2Seq只能说明UniLM具有NLG的能力,那前面为什么说它同时具备NLU和NLG能力呢?因为UniLM特殊的Attention Mask,所以[CLS] 你 想 吃 啥 [SEP]这6个token只在它们之间相互做Attention,而跟白 切 鸡 [SEP]完全没关系,这就意味着,尽管后面拼接了白 切 鸡 [SEP],但这不会影响到前6个编码向量。再说明白一点,那就是前6个编码向量等价于只有[CLS] 你 想 吃 啥 [SEP]时的编码结果,如果[CLS]的向量代表着句向量,那么它就是你 想 吃 啥的句向量,而不是加上白 切 鸡后的句向量。
由于这个特性,UniLM在输入的时候也随机加入一些[MASK],这样输入部分就可以做MLM任务,输出部分就可以做Seq2Seq任务,MLM增强了NLU能力,而Seq2Seq增强了NLG能力,一举两得。
1.2.2 SimBert
SimBERT属于有监督训练,训练语料是自行收集到的相似句对,通过一句来预测另一句的相似句生成任务来构建Seq2Seq部分,然后前面也提到过[CLS]的向量事实上就代表着输入的句向量,所以可以同时用它来训练一个检索任务,如下图
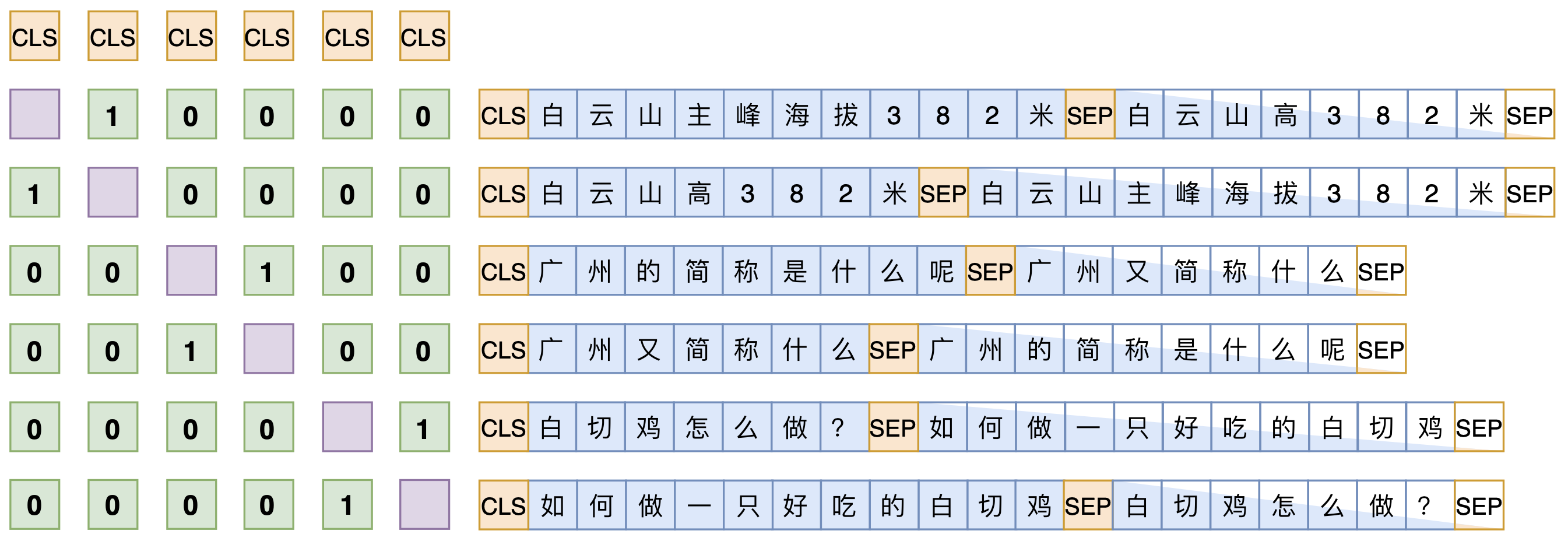
假设SENT_a和SENT_b是一组相似句,那么在同一个batch中,把[CLS] SENT_a [SEP] SENT_b [SEP]和[CLS] SENT_b [SEP] SENT_a [SEP]都加入训练,做一个相似句的生成任务,这是Seq2Seq部分。
另一方面,把整个batch内的[CLS]向量都拿出来,得到一个bxd的句向量矩阵V(b是batch_size,d是hidden_size),然后对d维度做l2归一化,得到新的V,然后两两做内积,得到bxv的相似度矩阵VV^T,接着乘以一个scale(我们取了30),并mask掉对角线部分,最后每一行进行softmax,作为一个分类任务训练,每个样本的目标标签是它的相似句(至于自身已经被mask掉)。说白了,就是把batch内所有的非相似样本都当作负样本,借助softmax来增加相似样本的相似度,降低其余样本的相似度。
详细介绍请看:https://kexue.fm/archives/7427
部分结果展示:
>>> gen_synonyms(u'微信和支付宝哪个好?')
[
u'微信和支付宝,哪个好?',
u'微信和支付宝哪个好',
u'支付宝和微信哪个好',
u'支付宝和微信哪个好啊',
u'微信和支付宝那个好用?',
u'微信和支付宝哪个好用',
u'支付宝和微信那个更好',
u'支付宝和微信哪个好用',
u'微信和支付宝用起来哪个好?',
u'微信和支付宝选哪个好',
u'微信好还是支付宝比较用',
u'微信与支付宝哪个',
u'支付宝和微信哪个好用一点?',
u'支付宝好还是微信',
u'微信支付宝究竟哪个好',
u'支付宝和微信哪个实用性更好',
u'好,支付宝和微信哪个更安全?',
u'微信支付宝哪个好用?有什么区别',
u'微信和支付宝有什么区别?谁比较好用',
u'支付宝和微信哪个好玩'
]
>>> most_similar(u'怎么开初婚未育证明', 20)
[
(u'开初婚未育证明怎么弄?', 0.9728098),
(u'初婚未育情况证明怎么开?', 0.9612292),
(u'到哪里开初婚未育证明?', 0.94987774),
(u'初婚未育证明在哪里开?', 0.9476072),
(u'男方也要开初婚证明吗?', 0.7712214),
(u'初婚证明除了村里开,单位可以开吗?', 0.63224965),
(u'生孩子怎么发', 0.40672967),
(u'是需要您到当地公安局开具变更证明的', 0.39978087),
(u'淘宝开店认证未通过怎么办', 0.39477515),
(u'您好,是需要当地公安局开具的变更证明的', 0.39288986),
(u'没有工作证明,怎么办信用卡', 0.37745982),
(u'未成年小孩还没办身份证怎么买高铁车票', 0.36504325),
(u'烟草证不给办,应该怎么办呢?', 0.35596085),
(u'怎么生孩子', 0.3493368),
(u'怎么开福利彩票站', 0.34158638),
(u'沈阳烟草证怎么办?好办不?', 0.33718678),
(u'男性不孕不育有哪些特征', 0.33530876),
(u'结婚证丢了一本怎么办离婚', 0.33166665),
(u'怎样到地税局开发票?', 0.33079252),
(u'男性不孕不育检查要注意什么?', 0.3274408)
]
1.2.3 SimBER训练预测
SimBERT的模型权重是以Google开源的BERT模型为基础,基于微软的UniLM思想设计了融检索与生成于一体的任务,来进一步微调后得到的模型,所以它同时具备相似问生成和相似句检索能力。
数据集使用的是LCQMC相关情况参考:https://aistudio.baidu.com/aistudio/projectdetail/5423713?contributionType=1
#数据准备:使用PaddleNLP内置数据集
from paddlenlp.datasets import load_dataset
train_ds, dev_ds, test_ds = load_dataset("lcqmc", splits=["train", "dev", "test"])
#保存数据集并查看
import json
with open("/home/aistudio/output/test.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾
for result in dev_ds:
line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False
f.write(line + "\n")
#数据有上传一份也有内置读取,根据个人喜好自行选择
待预测数据集部分展示:
开初婚未育证明怎么弄? 初婚未育情况证明怎么开? 1
谁知道她是网络美女吗? 爱情这杯酒谁喝都会醉是什么歌 0
人和畜生的区别是什么? 人与畜生的区别是什么! 1
男孩喝女孩的尿的故事 怎样才知道是生男孩还是女孩 0
这种图片是用什么软件制作的? 这种图片制作是用什么软件呢? 1
这腰带是什么牌子 护腰带什么牌子好 0
什么牌子的空调最好! 什么牌子的空调扇最好 0
这里要注意数据格式。没有标签的
开初婚未育证明怎么弄? 初婚未育情况证明怎么开?
谁知道她是网络美女吗? 爱情这杯酒谁喝都会醉是什么歌
人和畜生的区别是什么? 人与畜生的区别是什么!
男孩喝女孩的尿的故事 怎样才知道是生男孩还是女孩
这种图片是用什么软件制作的? 这种图片制作是用什么软件呢?
这腰带是什么牌子 护腰带什么牌子好
什么牌子的空调最好! 什么牌子的空调扇最好
#模型预测
# %cd SimBERT
!export CUDA_VISIBLE_DEVICES=0
!python predict.py --input_file /home/aistudio/LCQMC/dev.txt
按照predict.py.py进行预测得到相似度,部分展示:
{'query': '开初婚未育证明怎么弄?', 'title': '初婚未育情况证明怎么开?', 'similarity': 0.9500292}
{'query': '谁知道她是网络美女吗?', 'title': '爱情这杯酒谁喝都会醉是什么歌', 'similarity': 0.24593769}
{'query': '人和畜生的区别是什么?', 'title': '人与畜生的区别是什么!', 'similarity': 0.9916624}
{'query': '男孩喝女孩的尿的故事', 'title': '怎样才知道是生男孩还是女孩', 'similarity': 0.3250241}
{'query': '这种图片是用什么软件制作的?', 'title': '这种图片制作是用什么软件呢?', 'similarity': 0.9774641}
{'query': '这腰带是什么牌子', 'title': '护腰带什么牌子好', 'similarity': 0.74771273}
{'query': '什么牌子的空调最好!', 'title': '什么牌子的空调扇最好', 'similarity': 0.83304036}
以阈值0.9以上为相似度判断,得到结果和标注答案一致1010100.
2.Sentence Transformers (ERNIE/BERT/RoBERTa/Electra)
随着深度学习的发展,模型参数的数量飞速增长。为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集非常困难(成本过高),特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。为了利用这些数据,我们可以先从其中学习到一个好的表示,再将这些表示应用到其他任务中。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 在NLP任务上取得了很好的表现。
近年来,大量的研究表明基于大型语料库的预训练模型(Pretrained Models, PTM)可以学习通用的语言表示,有利于下游NLP任务,同时能够避免从零开始训练模型。随着计算能力的发展,深度模型的出现(即 Transformer)和训练技巧的增强使得 PTM 不断发展,由浅变深。
百度的预训练模型ERNIE经过海量的数据训练后,其特征抽取的工作已经做的非常好。借鉴迁移学习的思想,我们可以利用其在海量数据中学习的语义信息辅助小数据集(如本示例中的医疗文本数据集)上的任务。以 ERNIE 为代表的模型Fine-tune完成文本匹配任务。

使用预训练模型ERNIE完成文本匹配任务,大家可能会想到将query和title文本拼接,之后输入ERNIE中,取CLS特征(pooled_output),之后输出全连接层,进行二分类。如下图ERNIE用于句对分类任务的用法:
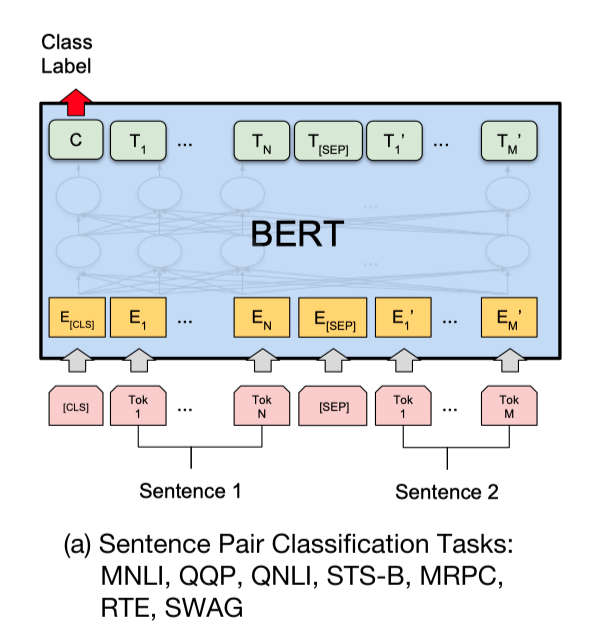
然而,以上用法的问题在于,ERNIE的模型参数非常庞大,导致计算量非常大,预测的速度也不够理想。从而达不到线上业务的要求。针对该问题,可以使用PaddleNLP工具搭建Sentence Transformer网络。
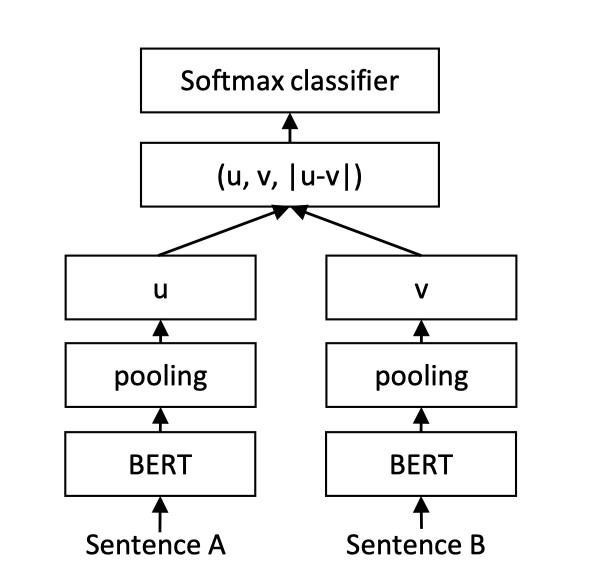
**Sentence Transformer采用了双塔(Siamese)的网络结构。Query和Title分别输入ERNIE,共享一个ERNIE参数,得到各自的token embedding特征。之后对token embedding进行pooling(此处教程使用mean pooling操作),之后输出分别记作u,v。之后将三个表征(u,v,|u-v|)拼接起来,进行二分类。网络结构如上图所示。同时,不仅可以使用ERNIR作为文本语义特征提取器,可以利用BERT/RoBerta/Electra等模型作为文本语义特征提取器
**
论文参考:Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks https://arxiv.org/abs/1908.10084
那么Sentence Transformer采用Siamese的网路结构,是如何提升预测速度呢?
Siamese的网络结构好处在于query和title分别输入同一套网络。如在信息搜索任务中,此时就可以将数据库中的title文本提前计算好对应sequence_output特征,保存在数据库中。当用户搜索query时,只需计算query的sequence_output特征与保存在数据库中的title sequence_output特征,通过一个简单的mean_pooling和全连接层进行二分类即可。从而大幅提升预测效率,同时也保障了模型性能。
关于匹配任务常用的Siamese网络结构可以参考:https://blog.csdn.net/thriving_fcl/article/details/73730552
2.1 模型简介
针对中文文本匹配问题,开源了一系列模型:
- BERT(Bidirectional Encoder Representations from Transformers)中文模型,简写bert-base-chinese, 其由12层Transformer网络组成。
- ERNIE(Enhanced Representation through Knowledge Integration),支持ERNIE 1.0中文模型(简写ernie-1.0)和ERNIE Tiny中文模型(简写ernie-tiny)。 其中ernie由12层Transformer网络组成,ernie-tiny由3层Transformer网络组成。
- RoBERTa(A Robustly Optimized BERT Pretraining Approach),支持12层Transformer网络的roberta-wwm-ext。
在LQCMC数据集下各个模型评估:
| 模型 | dev acc | test acc |
|---|---|---|
| bert-base-chinese | 0.86537 | 0.84440 |
| bert-wwm-chinese | 0.86333 | 0.84128 |
| bert-wwm-ext-chinese | 0.86049 | 0.83848 |
| ernie-1.0 | 0.87480 | 0.84760 |
| ernie-tiny | 0.86071 | 0.83352 |
| roberta-wwm-ext | 0.87526 | 0.84904 |
| rbt3 | 0.85367 | 0.83464 |
| rbtl3 | 0.85174 | 0.83744 |
2.2 模型训练
以中文文本匹配公开数据集LCQMC为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行模型训练,并在开发集(dev.tsv)验证
部分结果展示:
global step 7010, epoch: 8, batch: 479, loss: 0.06888, accu: 0.97227, speed: 1.40 step/s
global step 7020, epoch: 8, batch: 489, loss: 0.08377, accu: 0.97617, speed: 6.30 step/s
global step 7030, epoch: 8, batch: 499, loss: 0.07471, accu: 0.97630, speed: 6.32 step/s
global step 7040, epoch: 8, batch: 509, loss: 0.05239, accu: 0.97559, speed: 6.32 step/s
global step 7050, epoch: 8, batch: 519, loss: 0.04824, accu: 0.97539, speed: 6.30 step/s
global step 7060, epoch: 8, batch: 529, loss: 0.05198, accu: 0.97617, speed: 6.42 step/s
global step 7070, epoch: 8, batch: 539, loss: 0.07196, accu: 0.97651, speed: 6.42 step/s
global step 7080, epoch: 8, batch: 549, loss: 0.07003, accu: 0.97646, speed: 6.36 step/s
global step 7090, epoch: 8, batch: 559, loss: 0.10023, accu: 0.97587, speed: 6.34 step/s
global step 7100, epoch: 8, batch: 569, loss: 0.04805, accu: 0.97641, speed: 6.08 step/s
eval loss: 0.46545, accu: 0.87264
[2023-02-07 17:31:29,933] [ INFO] - tokenizer config file saved in ./checkpoints_ernie/model_7100/tokenizer_config.json
[2023-02-07 17:31:29,933] [ INFO] - Special tokens file saved in ./checkpoints_ernie/model_7100/special_tokens_map.json
代码示例中使用的预训练模型是ERNIE,如果想要使用其他预训练模型如BERT,RoBERTa,Electra等,只需更换model 和 tokenizer即可。
# 使用 BERT 预训练模型
# bert-base-chinese
# model = AutoModel.Model.from_pretrained('bert-base-chinese')
# tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese')
# bert-wwm-chinese
# model = AutoModel.from_pretrained('bert-wwm-chinese')
# tokenizer = AutoTokenizer.from_pretrained('bert-wwm-chinese')
# bert-wwm-ext-chinese
# model = AutoModel.from_pretrained('bert-wwm-ext-chinese')
# tokenizer = AutoTokenizer.from_pretrained('bert-wwm-ext-chinese')
# 使用 RoBERTa 预训练模型
# roberta-wwm-ext
# model = AutoModel..from_pretrained('roberta-wwm-ext')
# tokenizer = AutoTokenizer.from_pretrained('roberta-wwm-ext')
# roberta-wwm-ext
# model = AutoModel.from_pretrained('roberta-wwm-ext-large')
# tokenizer = AutoTokenizer.from_pretrained('roberta-wwm-ext-large')
更多预训练模型,参考transformers
程序运行时将会自动进行训练,评估,测试。同时训练过程中会自动保存模型在指定的save_dir中。 如:
checkpoints/
├── model_100
│ ├── model_config.json
│ ├── model_state.pdparams
│ ├── tokenizer_config.json
│ └── vocab.txt
└── ...
NOTE:
如需恢复模型训练,则可以设置init_from_ckpt, 如init_from_ckpt=checkpoints/model_100/model_state.pdparams。
如需使用ernie-tiny模型,则需要提前先安装sentencepiece依赖,如pip install sentencepiece
#模型预测
!export CUDA_VISIBLE_DEVICES=0
!python predict.py --device gpu --params_path /home/aistudio/Fine-tune/checkpoints_ernie/model_7100/model_state.pdparams
输出结果:
Data: ['开初婚未育证明怎么弄?', '初婚未育情况证明怎么开?'] Lable: similar
Data: ['谁知道她是网络美女吗?', '爱情这杯酒谁喝都会醉是什么歌'] Lable: dissimilar
Data: ['人和畜生的区别是什么?', '人与畜生的区别是什么!'] Lable: similar
1010100和Simbert以及标注真实标签一致
修改代码api接口参考:https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/argmax_cn.html#argmax
2.3小结
基于双塔 Point-wise 范式的语义匹配模型 SimNet 和 Sentence Transformers, 这 2 种方案计算效率更高,适合对延时要求高、根据语义相似度进行粗排的应用场景。
关于Sentence Transformer更多信息参考www.SBERT.net以及论文:
3.预训练模型 ERNIE-Gram 的单塔文本匹配
文本匹配任务数据每一个样本通常由两个文本组成(query,title)。类别形式为 0 或 1,0 表示 query 与 title 不匹配; 1 表示匹配。
- 基于单塔 Point-wise 范式的语义匹配模型 ernie_matching: 模型精度高、计算复杂度高, 适合直接进行语义匹配 2 分类的应用场景。
- 基于单塔 Pair-wise 范式的语义匹配模型 ernie_matching: 模型精度高、计算复杂度高, 对文本相似度大小的序关系建模能力更强,适合将相似度特征作为上层排序模块输入特征的应用场景。
- 基于双塔 Point-Wise 范式的语义匹配模型 这2 种方案计算效率更高,适合对延时要求高、根据语义相似度进行粗排的应用场景。
- Pointwise:输入两个文本和一个标签,可看作为一个分类问题,即判断输入的两个文本是否匹配。
- Pairwise:输入为三个文本,分别为Query以及对应的正样本和负样本,该训练方式考虑到了文本之间的相对顺序。
单塔/双塔
-
单塔:先将输入文本合并,然后输入到单一的神经网络模型。
-
双塔:对输入文本分别进行编码成固定长度的向量,通过文本的表示向量进行交互计算得到文本之间的关系。
本项目使用语义匹配数据集 LCQMC 作为训练集 , 基于 ERNIE-Gram 预训练模型热启训练并开源了单塔 Point-wise 语义匹配模型, 用户可以直接基于这个模型对文本对进行语义匹配的 2 分类任务
代码结构说明
ernie_matching/
├── deply # 部署
| └── python
| └── predict.py # python 预测部署示例
├── export_model.py # 动态图参数导出静态图参数脚本
├── model.py # Point-wise & Pair-wise 匹配模型组网
├── data.py # Point-wise & Pair-wise 训练样本的转换逻辑 、Pair-wise 生成随机负例的逻辑
├── train_pointwise.py # Point-wise 单塔匹配模型训练脚本
├── train_pairwise.py # Pair-wise 单塔匹配模型训练脚本
├── predict_pointwise.py # Point-wise 单塔匹配模型预测脚本,输出文本对是否相似: 0、1 分类
├── predict_pairwise.py # Pair-wise 单塔匹配模型预测脚本,输出文本对的相似度打分
└── train.py # 模型训练评估
数据集简介:
LCQMC是百度知道领域的中文问题匹配数据集,目的是为了解决在中文领域大规模问题匹配数据集的缺失。该数据集从百度知道不同领域的用户问题中抽取构建数据。
3.1模型训练与预测
以中文文本匹配公开数据集 LCQMC 为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行单塔 Point-wise 模型训练,并在开发集(dev.tsv)验证。
%cd ERNIE_Gram
!unset CUDA_VISIBLE_DEVICES
!python -u -m paddle.distributed.launch --gpus "0" train_pointwise.py \
--device gpu \
--save_dir ./checkpoints \
--batch_size 32 \
--learning_rate 2E-5\
--save_step 1000 \
--eval_step 200 \
--epochs 3
预测结果部分展示:
global step 3810, epoch: 1, batch: 3810, loss: 0.27187, accu: 0.90938, speed: 1.25 step/s
global step 3820, epoch: 1, batch: 3820, loss: 0.24648, accu: 0.92188, speed: 21.63 step/s
global step 3830, epoch: 1, batch: 3830, loss: 0.23190, accu: 0.92604, speed: 21.38 step/s
如果想要使用其他预训练模型如 ERNIE, BERT,RoBERTa,Electra等,只需更换model 和 tokenizer即可。
# 使用 ERNIE-3.0-medium-zh 预训练模型
model = AutoModel.from_pretrained('ernie-3.0-medium-zh')
tokenizer = AutoTokenizer.from_pretrained('ernie-3.0-medium-zh')
# 使用 ERNIE-Gram 预训练模型
model = AutoModel.from_pretrained('ernie-gram-zh')
tokenizer = AutoTokenizer.from_pretrained('ernie-gram-zh')
NOTE:
如需恢复模型训练,则可以设置init_from_ckpt, 如init_from_ckpt=checkpoints/model_100/model_state.pdparams。
如需使用ernie-tiny模型,则需要提前先安装sentencepiece依赖,如pip install sentencepiece
!unset CUDA_VISIBLE_DEVICES
!python -u -m paddle.distributed.launch --gpus "0" \
predict_pointwise.py \
--device gpu \
--params_path "./checkpoints/model_4000/model_state.pdparams"\
--batch_size 128 \
--max_seq_length 64 \
--input_file '/home/aistudio/LCQMC/test.tsv'
预测结果部分展示:
{'query': '这张图是哪儿', 'title': '这张图谁有', 'pred_label': 0}
{'query': '这是什么水果?', 'title': '这是什么水果。怎么吃?', 'pred_label': 1}
3.2 基于静态图部署预测
模型导出
使用动态图训练结束之后,可以使用静态图导出工具 export_model.py 将动态图参数导出成静态图参数。 执行如下命令:
!python export_model.py --params_path checkpoints/model_4000/model_state.pdparams --output_path=./output
# 其中params_path是指动态图训练保存的参数路径,output_path是指静态图参数导出路径。
# 预测部署
# 导出静态图模型之后,可以基于静态图模型进行预测,deploy/python/predict.py 文件提供了静态图预测示例。执行如下命令:
!python deploy/predict.py --model_dir ./output
部分结果展示:
Data: {'query': '〈我是特种兵之火凤凰〉好看吗', 'title': '特种兵之火凤凰好看吗?'} Label: similar
Data: {'query': '现在看电影用什么软件好', 'title': '现在下电影一般用什么软件'} Label: similar
3.3 小结
| 模型 | dev acc |
|---|---|
| Simcse(无监督) | 58.97% |
| Diffcse(无监督) | 63.23% |
| bert-base-chinese | 86.53% |
| bert-wwm-chinese | 86.33% |
| bert-wwm-ext-chinese | 86.05% |
| ernie-tiny | 86.07% |
| roberta-wwm-ext | 87.53% |
| rbt3 | 85.37% |
| rbtl3 | 85.17% |
| ERNIE-1.0-Base | 89.34% |
| ERNIE-1.0-Base | 89.34% |
| ERNIE-Gram-Base-Pointwise | 90.58% |
-
SimCSE 模型适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。
-
相比于 SimCSE 模型,DiffCSE模型会更关注语句之间的差异性,具有精确的向量表示能力。DiffCSE 模型同样适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。
-
明显看到有监督模型中ERNIE-Gram比之前所有模型性能的优秀
参考文章:https://aistudio.baidu.com/aistudio/projectdetail/5423713?contributionType=1
4.学以致用–千言问题匹配鲁棒性评测比赛验证
特定领域知识图谱融合方案:学以致用-问题匹配鲁棒性评测比赛验证
本项目主要讲述文本匹配算法的应用实践、并给出相应的优化方案介绍如:可解释学习等。最后文末介绍了知识融合学术界方案、知识融合业界落地方案、算法测评KG生产质量保障等,涉及对比学习和文本。
https://blog.csdn.net/sinat_39620217/article/details/129026193
5.特定领域知识图谱(Domain-specific KnowledgeGraph:DKG)融合方案(重点!)
在前面技术知识下可以看看后续的实际业务落地方案和学术方案
关于图神经网络的知识融合技术学习参考下面链接:PGL图学习项目合集&数据集分享&技术归纳业务落地技巧[系列十]
从入门知识到经典图算法以及进阶图算法等,自行查阅食用!
文章篇幅有限请参考专栏按需查阅:NLP知识图谱相关技术业务落地方案和码源
5.1特定领域知识图谱知识融合方案(实体对齐):优酷领域知识图谱为例
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128614951
5.2特定领域知识图谱知识融合方案(实体对齐):文娱知识图谱构建之人物实体对齐
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128673963
5.3特定领域知识图谱知识融合方案(实体对齐):商品知识图谱技术实战
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128674429
5.4特定领域知识图谱知识融合方案(实体对齐):基于图神经网络的商品异构实体表征探索
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128674929
5.5特定领域知识图谱知识融合方案(实体对齐)论文合集
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128675199
论文资料链接:两份内容不相同,且按照序号从小到大重要性依次递减
知识图谱实体对齐资料论文参考(PDF)+实体对齐方案+特定领域知识图谱知识融合方案(实体对齐)
知识图谱实体对齐资料论文参考(CAJ)+实体对齐方案+特定领域知识图谱知识融合方案(实体对齐)
5.6知识融合算法测试方案(知识生产质量保障)
方案链接:https://blog.csdn.net/sinat_39620217/article/details/128675698
6. 总结
| 模型 | dev acc |
|---|---|
| Simcse(无监督) | 58.97% |
| Diffcse(无监督) | 63.23% |
| bert-base-chinese | 86.53% |
| bert-wwm-chinese | 86.33% |
| bert-wwm-ext-chinese | 86.05% |
| ernie-tiny | 86.07% |
| roberta-wwm-ext | 87.53% |
| rbt3 | 85.37% |
| rbtl3 | 85.17% |
| ERNIE-1.0-Base | 89.34% |
| ERNIE-1.0-Base | 89.34% |
| ERNIE-Gram-Base-Pointwise | 90.58% |
-
SimCSE 模型适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。
-
相比于 SimCSE 模型,DiffCSE模型会更关注语句之间的差异性,具有精确的向量表示能力。DiffCSE 模型同样适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。
-
明显看到有监督模型中ERNIE-Gram比之前所有模型性能的优秀

- 点赞
- 收藏
- 关注作者
评论(0)