Pandas数据处理3、DataFrame去重函数drop_duplicates()详解


![]()
Pandas数据处理3、DataFrame去重函数drop_duplicates()详解
目录
Pandas数据处理3、DataFrame去重函数drop_duplicates()详解
前言
这个女娃娃是否有一种初恋的感觉呢,但是她很明显不是一个真正意义存在的图片,我们需要很复杂的推算以及各种炼丹模型生成的AI图片,我自己认为难度系数很高,我仅仅用了64个文字形容词就生成了她,很有初恋的感觉,符合审美观,对于计算机来说她是一组数字,可是这个数字是怎么推断出来的就是很复杂了,我们在模型训练中可以看到基本上到处都存在着Pandas处理,在最基础的OpenCV中也会有很多的Pandas处理,所以我OpenCV写到一般就开始写这个专栏了,因为我发现没有Pandas处理基本上想好好的操作图片数组真的是相当的麻烦,可以在很多AI大佬的文章中发现都有这个Pandas文章,每个人的写法都不同,但是都是适合自己理解的方案,我是用于教学的,故而我相信我的文章更适合新晋的程序员们学习,期望能节约大家的事件从而更好的将精力放到真正去实现某种功能上去。本专栏会更很多,只要我测试出新的用法就会添加,持续更新迭代,可以当做【Pandas字典】来使用,期待您的三连支持与帮助。
环境
系统环境:win11
Python版本:python3.9
编译工具:PyCharm Community Edition 2022.3.1
Numpy版本:1.19.5
Pandas版本:1.4.4
基础函数的使用
drop_duplicates函数
函数语法:
data.drop_duplicates(subset=['a','b','b'],keep='first',inplace=True)函数参数:
subset:表示要进去重的列名,默认为 None。
keep:有三个可选参数,分别是 first、last、False,默认为 first,表示只保留第一次出现的重复项,删除其余重复项,last 表示只保留最后一次出现的重复项,False 则表示删除所有重复项。
inplace:布尔值参数,默认为 False 表示删除重复项后返回一个副本,若为 Ture 则表示直接在原数据上删除重复项。
subset参数测试
根据参数说明我们知道,是根据列名去重。
import pandas as pd
import numpy as np
df = pd.DataFrame(
{'name': ['张丽华', '李诗诗', '王语嫣', '赵飞燕', '阮玲玉'],
'sex': ['girl', 'woman', np.nan, 'girl', 'woman'],
'age': [22, np.nan, 16, np.nan, 27]
}
)
print(df)
print("----drop_duplicates----")
# drop_duplicates使用
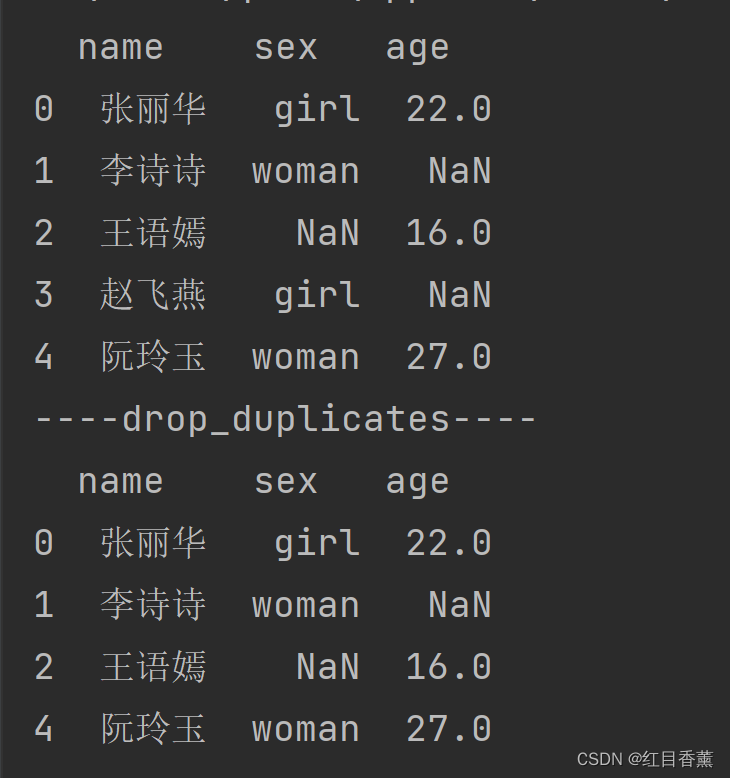
df = df.drop_duplicates(subset=['age'])
print(df)
数据中能看到我们的age列的赵飞燕行业是NaN,故而直接删除了没有显示。
![]()
Keep参数测试
全都删掉【keep=False】
这里是只要有重复的就全部删除。
import pandas as pd
import numpy as np
df = pd.DataFrame(
{'name': ['张丽华', '李诗诗', '王语嫣', '赵飞燕', '阮玲玉'],
'sex': ['girl', 'woman', np.nan, 'girl', 'woman'],
'age': [22, np.nan, 16, np.nan, 27]
}
)
print(df)
print("----drop_duplicates----")
# drop_duplicates使用
df = df.drop_duplicates(subset=['sex'], keep=False)
print(df)
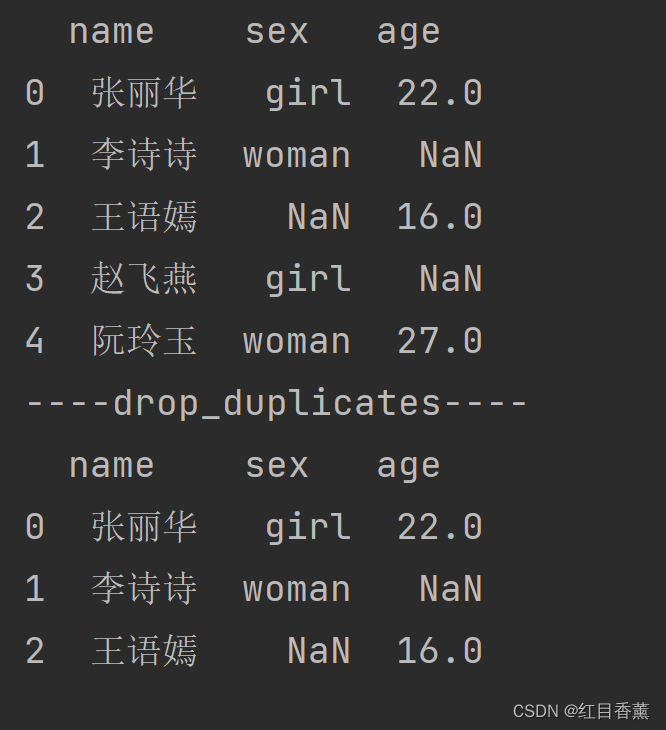
留第一次出现的【keep='first'】
保留第一次出现的,后面的都删除。
import pandas as pd
import numpy as np
df = pd.DataFrame(
{'name': ['张丽华', '李诗诗', '王语嫣', '赵飞燕', '阮玲玉'],
'sex': ['girl', 'woman', np.nan, 'girl', 'woman'],
'age': [22, np.nan, 16, np.nan, 27]
}
)
print(df)
print("----drop_duplicates----")
# drop_duplicates使用
df = df.drop_duplicates(subset=['sex'], keep='first')
print(df)
![]()
留最后一次出现的【keep='last'】
保留最后一次出现的,其它的都删除。
import pandas as pd
import numpy as np
df = pd.DataFrame(
{'name': ['张丽华', '李诗诗', '王语嫣', '赵飞燕', '阮玲玉'],
'sex': ['girl', 'woman', np.nan, 'girl', 'woman'],
'age': [22, np.nan, 16, np.nan, 27]
}
)
print(df)
print("----drop_duplicates----")
# drop_duplicates使用
df = df.drop_duplicates(subset=['sex'], keep='last')
print(df)

![]()
ignore_index参数测试
ignore_index=True重新排序
我们测试的时候能看到我们用的是保存后面的行值。true就是重新排序,我们会看到行是0,1,2的排序。
import pandas as pd
import numpy as np
df = pd.DataFrame(
{'name': ['张丽华', '李诗诗', '王语嫣', '赵飞燕', '阮玲玉'],
'sex': ['girl', 'woman', np.nan, 'girl', 'woman'],
'age': [22, np.nan, 16, np.nan, 27]
}
)
print(df)
print("----drop_duplicates----")
# drop_duplicates使用
df = df.drop_duplicates(subset=['sex'], keep='last', ignore_index=True)
print(df)
重新排序:

![]()
ignore_index=False不重新排序
这里是False,代表我们不会对结果进行排序,能看到结果行显示:[2,3,4]
import pandas as pd
import numpy as np
df = pd.DataFrame(
{'name': ['张丽华', '李诗诗', '王语嫣', '赵飞燕', '阮玲玉'],
'sex': ['girl', 'woman', np.nan, 'girl', 'woman'],
'age': [22, np.nan, 16, np.nan, 27]
}
)
print(df)
print("----drop_duplicates----")
# drop_duplicates使用
df = df.drop_duplicates(subset=['sex'], keep='last', ignore_index=False)
print(df)

总结
去重还是用的非常多的,我们技术的时候就可以先将内容去重,在根据出现的次数累加就可以了,很方便的用法,当然也有直接能处理的计数函数Counter()。有兴趣可以去试试,我会在后面经常使用这个函数的。

- 点赞
- 收藏
- 关注作者
评论(0)