神经网络实战--使用迁移学习完成猫狗分类


前言:Hello大家好,我是Dream。 今天来学习一下如何使用基于tensorflow和keras的迁移学习完成猫狗分类,欢迎大家一起前来探讨学习~
@TOC
说明:在此试验下,我们使用的是使用tf2.x版本,在jupyter环境下完成
在本文中,我们将主要完成以下任务:
-
实现基于tensorflow和keras的迁移学习
-
加载tensorflow提供的数据集(不得使用cifar10)
-
需要使用markdown单元格对数据集进行说明
-
加载tensorflow提供的预训练模型(不得使用vgg16)
-
需要使用markdown单元格对原始模型进行说明
-
网络末端连接任意结构的输出端网络
-
用图表显示准确率和损失函数
-
用cnn工具可视化一批数据的预测结果
-
用cnn工具可视化一个数据样本的各层输出
一、加载数据集
1.调用库函数
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
import cnn_utils
from tensorflow.keras.preprocessing import image_dataset_from_directory
from tensorflow.keras.layers import GlobalAveragePooling2D,Dense,Input,Dropout
2.加载数据集
数据集加载,数据是通过这个网站下载的猫狗数据集:http://aimaksen.bslience.cn/cats_and_dogs_filtered.zip,实验中为了训练方便,我们取了一个较小的数据集。
path_to_zip = tf.keras.utils.get_file(
'data.zip',
origin='http://aimaksen.bslience.cn/cats_and_dogs_filtered.zip',
extract=True,
)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
3.数据集管理
使用image_dataset_from_director进行数据集管理,使用ImageDataGenerator训练过程中会出现错误,不知道是什么原因,就使用了原始的image_dataset_from_director方法进行数据集管理。
train_dataset = image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
validation_dataset = image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
二、猫狗数据集介绍
1.猫狗数据集介绍:
猫狗数据集包括25000张训练图片,12500张测试图片,包括猫和狗两种图片。在此次实验中为了训练方便,我们取了一个较小的数据集。 数据解压之后会有两个文件夹,一个是 “train”,一个是 “test”,顾名思义一个是用来训练的,另一个是作为检验正确性的数据。

在train文件夹里边是一些已经命名好的图像,有猫也有狗。而在test文件夹中是只有编号名的图像。

2.图片展示
下面是数据集中的图片展示:
class_names = ['cats', 'dogs']
plt.figure(figsize=(10, 10))
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
🌟🌟🌟 这里是输出的结果:✨✨✨

三、MobileNetV2网络介绍
1.加载tensorflow提供的预训练模型
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
2.轻量级网络——MobileNetV2
使用轻量级网络——MobileNetV2进行数据预处理 说明: MobileNetV2是基于倒置的残差结构,普通的残差结构是先经过 1x1 的卷积核把 feature map的通道数压下来,然后经过 3x3 的卷积核,最后再用 1x1 的卷积核将通道数扩张回去,即先压缩后扩张,而MobileNetV2的倒置残差结构是先扩张后压缩。
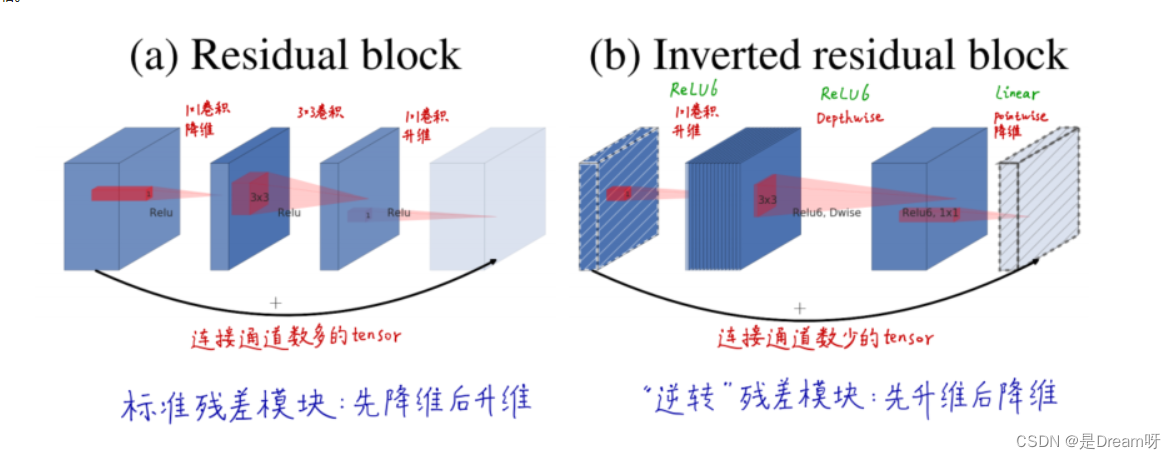
3.MobileNetV2的网络模块
MobileNetV2的网络模块样子是这样的:
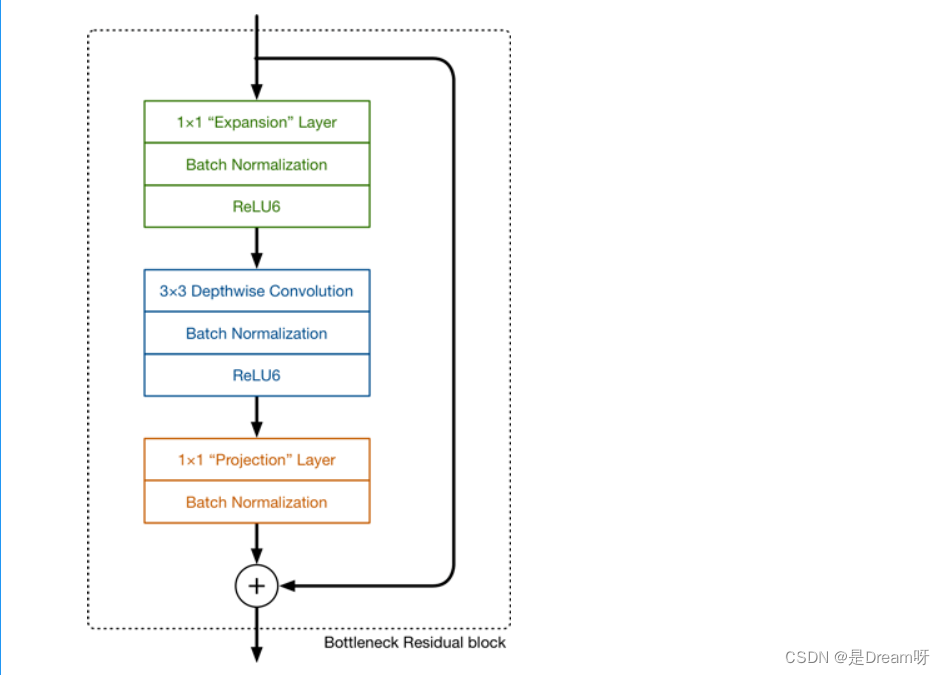
MobileNetV2是基于深度级可分离卷积构建的网络,它是将标准卷积拆分为了两个操作:深度卷积 和 逐点卷积,深度卷积和标准卷积不同,对于标准卷积其卷积核是用在所有的输入通道上,而深度卷积针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说深度卷积是depth级别的操作。而逐点卷积其实就是普通的卷积,只不过其采用1x1的卷积核。
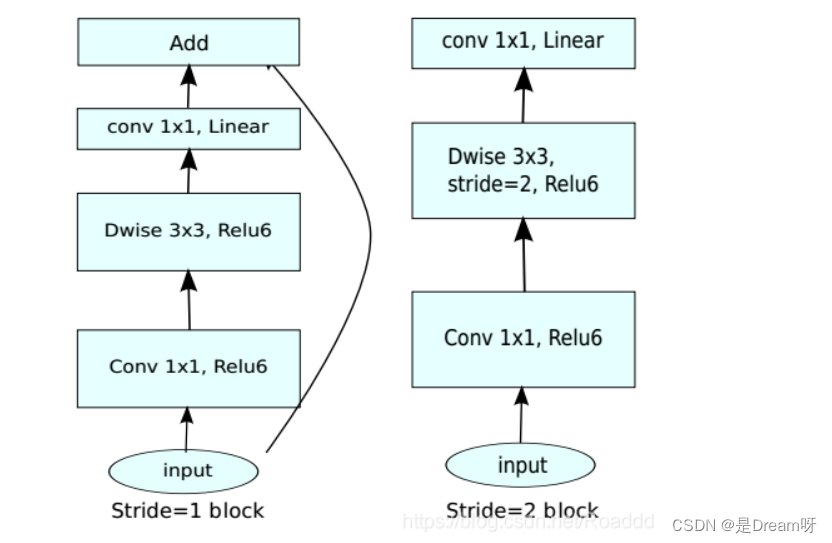
MobileNetV2的模型如下图所示,其中t为Bottleneck内部升维的倍数,c为通道数,n为该bottleneck重复的次数,s为sride:

其中,当stride=1时,才会使用elementwise 的sum将输入和输出特征连接(如下图左侧);stride=2时,无short cut连接输入和输出特征(下图右侧):
四、搭建迁移学习
1.训练
inital_input = tf.keras.applications.mobilenet_v2.preprocess_input
IMG_SHAPE = IMG_SIZE + (3,)
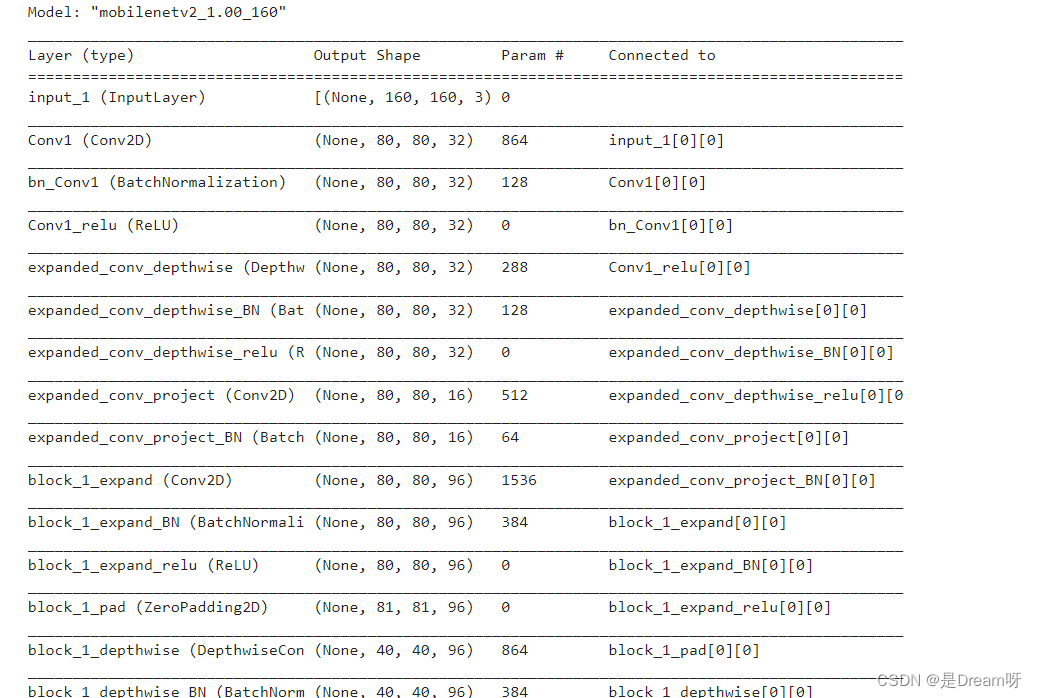
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
base_model.trainable = False
base_model.summary()
🌟🌟🌟 这里是输出的结果:✨✨✨
2.训练结果可视化
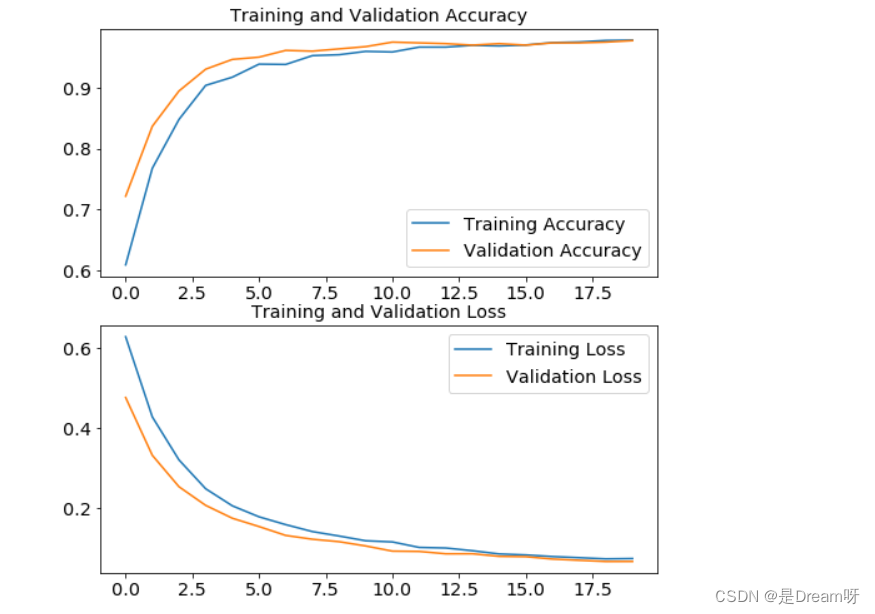
用图表显示准确率和损失函数
# 训练结果可视化,用图表显示准确率和损失函数
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range=range(initial_epochs)
plt.figure(figsize=(8,8))
plt.subplot(2,1,1)
plt.plot(epochs_range, acc, label="Training Accuracy")
plt.plot(epochs_range, val_acc,label="Validation Accuracy")
plt.legend()
plt.title("Training and Validation Accuracy")
plt.subplot(2,1,2)
plt.plot(epochs_range, loss, label="Training Loss")
plt.plot(epochs_range, val_loss,label="Validation Loss")
plt.legend()
plt.title("Training and Validation Loss")
plt.show()
🌟🌟🌟 这里是输出的结果:✨✨✨
3.输出训练的准确率
# 输出训练的准确率
test_loss, test_accuracy = model.evaluate(test_dataset)
print('test accuracy: {:.2f}'.format(test_accuracy))
🌟🌟🌟 这里是输出的结果:✨✨✨

4.用cnn工具可视化一批数据的预测结果
label_dict = {
0: 'cat',
1: 'dog'
}
test_image_batch, test_label_batch = test_dataset.as_numpy_iterator().next()
# 编码成uint8 以图片形式输出
test_image_batch = test_image_batch.astype('uint8')
cnn_utils.plot_predictions(model, test_image_batch, test_label_batch, label_dict, 32, 5, 5)
🌟🌟🌟 这里是输出的结果:✨✨✨

5.数据输出
# 数据输出,数字化特征图
test_image_batch, test_label_batch = train_dataset.as_numpy_iterator().next()
img_idx = 0
random_batch = np.random.permutation(np.arange(0,len(test_image_batch)))[:BATCH_SIZE]
image_activation = test_image_batch[random_batch[img_idx]:random_batch[img_idx]+1]
cnn_utils.get_activations(base_model, image_activation[0])
🌟🌟🌟 这里是输出的结果:✨✨✨

6.用cnn工具可视化一个数据样本的各层输出
cnn_utils.display_activations(cnn_utils.get_activations(base_model, image_activation[0]))
🌟🌟🌟 这里是输出的结果:✨✨✨

7.输出结果图像
🌟🌟🌟 这里是输出的结果:✨✨✨



五、源码获取
关注此公众号:人生苦短我用Pythons,回复 神经网络源码获取源码,快点击我吧
🌲🌲🌲 好啦,这就是今天要分享给大家的全部内容了,我们下期再见!
❤️❤️❤️如果你喜欢的话,就不要吝惜你的一键三连了~



- 点赞
- 收藏
- 关注作者
评论(0)