神经网络--基于fashion mnist数据库获得最高的识别准确率

【摘要】 神经网络--基于fashion mnist数据库获得最高的识别准确率

前言:Hello大家好,我是Dream。 今天来学习一下如何基于fashion mnist数据库获得最高的识别准确率,本文是从零开始的,如有需要可自行跳至所需内容~
@TOC
说明:在此试验下,我们使用的是使用tf2.x版本,在jupyter环境下完成
在本文中,我们将主要完成以下任务:
- 基于fashion mnist数据库设计网络模型
- 使用evaluate方法对测试集进行测试,获取尽可能高的准确率
1.调用库函数
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import Model
2.调用数据集
(train_X, train_y),(test_X, test_y) = tf.keras.datasets.fashion_mnist.load_data()
train_X, test_X = train_X / 255.0, test_X / 255.0
train_X = train_X.reshape(-1, 28, 28, 1)
train_y = tf.keras.utils.to_categorical(train_y)
test_X = test_X.reshape(-1, 28, 28, 1)
test_y = tf.keras.utils.to_categorical(test_y)
X_train, X_test, y_train, y_test = train_test_split(train_X, train_y, test_size=0.1, random_state=0)
3.数据增强
在这里我们使用数据增强方法,更好的提高准确率
# 数据增强
datagen = ImageDataGenerator(
rotation_range=15,
zoom_range = 0.01,
width_shift_range=0.1,
height_shift_range=0.1)
train_gen = datagen.flow(X_train, y_train, batch_size=128)
test_gen = datagen.flow(X_test, y_test, batch_size=128)
4.选择模型,构建网络
首先我们批量输入的样本个数:
# 批量输入的样本个数
batch_size = 128
train_steps = X_train.shape[0] // batch_size
valid_steps = X_test.shape[0] // batch_size
在此处,我们使用ResNet残差网络,ResNet-34残差网络中首先是卷积层,然后是池化层,有连接线的结构就是一个残差结构再这个34层的ResNet是由一系列的残差结构组成的。最后通过一个平均池化层以及一个全脸基层也就是输出层组成的。这个网络的结构十分简单,基本就是堆叠残差结构组成的。
ResNet结构中具有以下的优点,可以极大程度的提高我们的模型准确率。
- 超深的网络结构(突破了1000层)
- 提出residual模块
- 使用BN加速训练
# 使用ResNet残差网络
class ResnetBlock(Model):
def __init__(self, filters, strides=1, residual_path=False):
super(ResnetBlock, self).__init__()
self.filters = filters
self.strides = strides
self.residual_path = residual_path
# 第1个部分
self.c1 = Conv2D(filters, (3, 3), strides=strides, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
# 第2个部分
self.c2 = Conv2D(filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b2 = BatchNormalization()
# residual_path为True时,对输入进行下采样,即用1x1的卷积核做卷积操作,保证x能和F(x)维度相同,顺利相加
if residual_path:
self.down_c1 = Conv2D(filters, (1, 1), strides=strides, padding='same', use_bias=False)
self.down_b1 = BatchNormalization()
self.a2 = Activation('relu')
def call(self, inputs):
residual = inputs # residual等于输入值本身,即residual=x
# 将输入通过卷积、BN层、激活层,计算F(x)
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.c2(x)
y = self.b2(x)
if self.residual_path:
residual = self.down_c1(inputs)
residual = self.down_b1(residual)
out = self.a2(y + residual) # 最后输出的是两部分的和,即F(x)+x或F(x)+Wx,再过激活函数
return out
class ResNet18(Model):
def __init__(self, block_list, initial_filters=64): # block_list表示每个block有几个卷积层
super(ResNet18, self).__init__()
self.num_blocks = len(block_list) # 共有几个block
self.block_list = block_list
self.out_filters = initial_filters
# 结构定义
self.c1 = Conv2D(self.out_filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.blocks = tf.keras.models.Sequential()
# 构建ResNet网络结构
for block_id in range(len(block_list)): # 第几个resnet block
for layer_id in range(block_list[block_id]): # 第几个卷积层
if block_id != 0 and layer_id == 0: # 对除第一个block以外的每个block的输入进行下采样
block = ResnetBlock(self.out_filters, strides=2, residual_path=True)
else:
block = ResnetBlock(self.out_filters, residual_path=False)
self.blocks.add(block) # 将构建好的block加入resnet
self.out_filters *= 2 # 下一个block的卷积核数是上一个block的2倍
self.p1 = tf.keras.layers.GlobalAveragePooling2D()
self.f1 = tf.keras.layers.Dense(10, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
def call(self, inputs):
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
# 4个元素,block执行4次,每次有2个
model = ResNet18([2, 2, 2, 2])
5.训练
经过我们测试分析,此模型训练到70轮之前变化趋于静止,我们可以只进行70个epochs
optimizer = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
# 经过我们测试分析,此模型训练到70轮之前变化趋于静止,我们可以只进行70个epochs
es = tf.keras.callbacks.EarlyStopping(
monitor="val_accuracy",
patience=15,
verbose=1,
mode="max",
restore_best_weights=True
)
rp = tf.keras.callbacks.ReduceLROnPlateau(
monitor="val_accuracy",
factor=0.2,
patience=10,
verbose=1,
mode="max",
min_lr=0.0001
)
model.compile(optimizer=optimizer, loss=tf.keras.losses.categorical_crossentropy, metrics=['accuracy'])
# 训练(训练70个epoch)
history = model.fit(train_gen,
batch_size=128,
epochs=70,
verbose=1,
validation_data=test_gen,
validation_steps=valid_steps,
steps_per_epoch=train_steps,
callbacks=[es, rp]
)
🌟🌟🌟 这里是输出的结果:✨✨✨

6.画出图像
使用plt模块进行数据可视化处理
# 显示训练集和验证集的acc和loss曲线
fig, ax = plt.subplots(2,1, figsize=(14, 10))
ax[0].plot(history.history['loss'], color='b', label="Training loss")
ax[0].plot(history.history['val_loss'], color='r', label="Validation loss",axes =ax[0])
ax[0].legend(loc='best', shadow=False)
ax[1].plot(history.history['accuracy'], color='b', label="Training accuracy")
ax[1].plot(history.history['val_accuracy'], color='r',label="Validation accuracy")
ax[1].legend(loc='best')
🌟🌟🌟 这里是输出的结果:✨✨✨
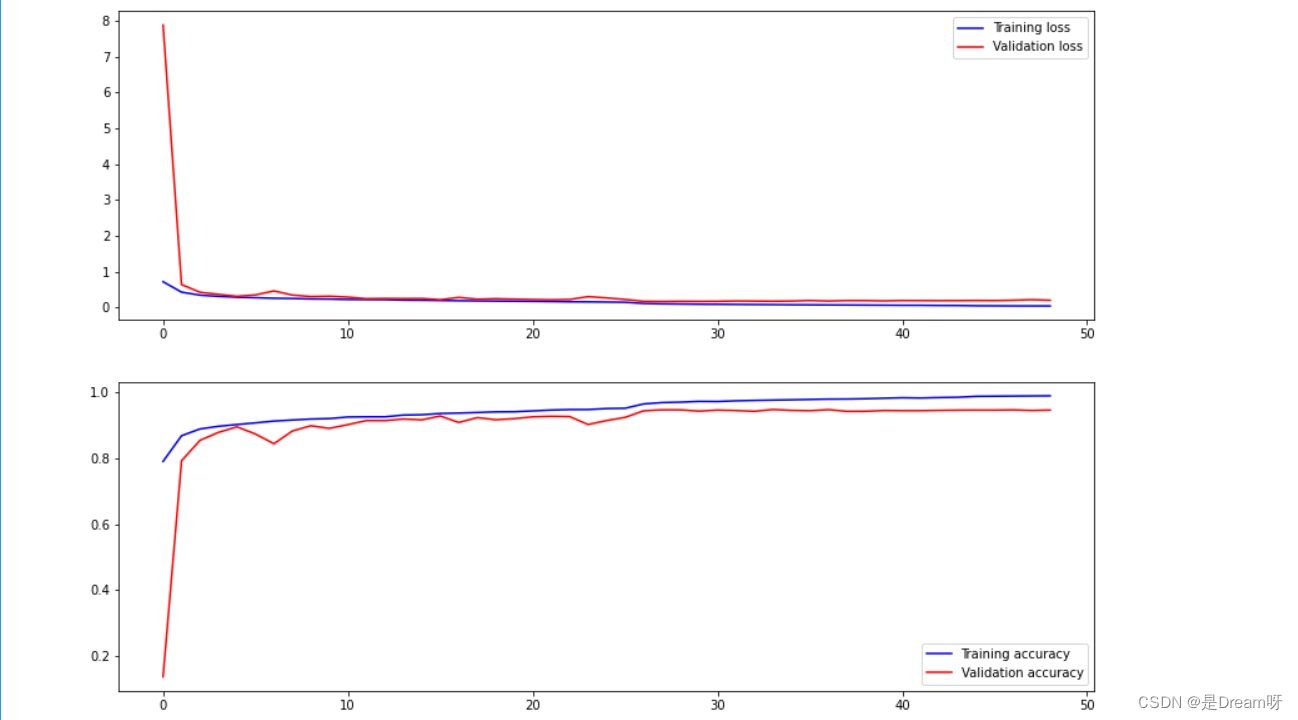
7.输出
最后在测试集上进行模型评估,输出测试集上的预测准确率
score = model.evaluate(X_test, y_test) # 在测试集上进行模型评估
print('测试集预测准确率:', score[1]) # 打印测试集上的预测准确率
🌟🌟🌟 这里是输出的结果:✨✨✨

8.结果
print("The accuracy of the model is %f" %score[1])
🌟🌟🌟 这里是输出的结果:✨✨✨
The accuracy of the model is 0.950667
源码获取
关注此公众号:人生苦短我用Pythons,回复 神经网络实验获取源码,快点击我吧
🌲🌲🌲 好啦,这就是今天要分享给大家的全部内容了,我们下期再见!
❤️❤️❤️如果你喜欢的话,就不要吝惜你的一键三连了~



【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)