Mycat配置文件详解

@toc
3.1 server.xml
3.1.1 system 标签
| 属性 | 取值 | 含义 |
|---|---|---|
| charset | utf8 | 设置Mycat的字符集, 字符集需要与MySQL的字符集保持一致 |
| nonePasswordLogin | 0,1 | 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户 |
| useHandshakeV10 | 0,1 | 使用该选项主要的目的是为了能够兼容高版本的jdbc驱动, 是否采用HandshakeV10Packet来与client进行通信, 1:是, 0:否 |
| useSqlStat | 0,1 | 开启SQL实时统计, 1 为开启 , 0 为关闭 ; 开启之后, MyCat会自动统计SQL语句的执行情况 ; mysql -h 127.0.0.1 -P 9066 -u root -p 查看MyCat执行的SQL, 执行效率比较低的SQL , SQL的整体执行情况、读写比例等 ; show @@sql ; show @@sql.slow ; show @@sql.sum ; |
| useGlobleTableCheck | 0,1 | 是否开启全局表的一致性检测。1为开启 ,0为关闭 。 |
| sqlExecuteTimeout | 1000 | SQL语句执行的超时时间 , 单位为 s ; |
| sequnceHandlerType | 0,1,2 | 用来指定Mycat全局序列类型,0 为本地文件,1 为数据库方式,2 为时间戳列方式,默认使用本地文件方式,文件方式主要用于测试 |
| sequnceHandlerPattern | 正则表达式 | 必须带有MYCATSEQ_或者 mycatseq_进入序列匹配流程 注意MYCATSEQ_有空格的情况 |
| subqueryRelationshipCheck | true,false | 子查询中存在关联查询的情况下,检查关联字段中是否有分片字段 .默认 false |
| useCompression | 0,1 | 开启mysql压缩协议 , 0 : 关闭, 1 : 开启 |
| fakeMySQLVersion | 5.5,5.6 | 设置模拟的MySQL版本号 |
| defaultSqlParser | 由于MyCat的最初版本使用了FoundationDB的SQL解析器, 在MyCat1.3后增加了Druid解析器, 所以要设置defaultSqlParser属性来指定默认的解析器; 解析器有两个 : druidparser 和 fdbparser, 在MyCat1.4之后,默认是druidparser, fdbparser已经废除了 | |
| processors | 1,2… | 指定系统可用的线程数量, 默认值为CPU核心 x 每个核心运行线程数量; processors 会影响processorBufferPool, processorBufferLocalPercent, processorExecutor属性, 所有, 在性能调优时, 可以适当地修改processors值 |
| processorBufferChunk | 指定每次分配Socket Direct Buffer默认值为4096字节, 也会影响BufferPool长度, 如果一次性获取字节过多而导致buffer不够用, 则会出现警告, 可以调大该值 | |
| processorExecutor | 指定NIOProcessor上共享 businessExecutor固定线程池的大小; MyCat把异步任务交给 businessExecutor线程池中, 在新版本的MyCat中这个连接池使用频次不高, 可以适当地把该值调小 | |
| packetHeaderSize | 指定MySQL协议中的报文头长度, 默认4个字节 | |
| maxPacketSize | 指定MySQL协议可以携带的数据最大大小, 默认值为16M | |
| idleTimeout | 30 | 指定连接的空闲时间的超时长度;如果超时,将关闭资源并回收, 默认30分钟 |
| txIsolation | 1,2,3,4 | 初始化前端连接的事务隔离级别,默认为 REPEATED_READ , 对应数字为3 READ_UNCOMMITED=1; READ_COMMITTED=2; REPEATED_READ=3; SERIALIZABLE=4; |
| sqlExecuteTimeout | 300 | 执行SQL的超时时间, 如果SQL语句执行超时,将关闭连接; 默认300秒; |
| serverPort | 8066 | 定义MyCat的使用端口, 默认8066 |
| managerPort | 9066 | 定义MyCat的管理端口, 默认9066 |
3.1.2 user 标签
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">ITCAST</property>
<property name="readOnly">true</property>
<property name="benchmark">1000</property>
<property name="usingDecrypt">0</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
user标签主要用于定义登录MyCat的用户和权限 :
1). <user name=“root” defaultAccount=“true”> : name 属性用于声明用户名 ;
2). <property name=“password”>123456</property> : 指定该用户名访问MyCat的密码 ;
3). <property name=“schemas”>ITCAST</property> : 能够访问的逻辑库, 多个的话, 使用 “,” 分割
4). <property name=“readOnly”>true</property> : 是否只读
5). <property name=“benchmark”>11111</property> : 指定前端的整体连接数量 , 0 或不设置表示不限制
6). <property name=“usingDecrypt”>0</property> : 是否对密码加密默认 0 否 , 1 是
java -cp Mycat-server-1.6.7.3-release.jar io.mycat.util.DecryptUtil 0:root:123456
7). <privileges check=“false”>
A. 对用户的 schema 及 下级的 table 进行精细化的 DML 权限控制;
B. privileges 节点中的 check 属性是用 于标识是否开启 DML 权限检查, 默认 false 标识不检查,当然 privileges 节点不配置,等同 check=false, 由于 Mycat 一个用户的 schemas 属性可配置多个 schema ,所以 privileges 的下级节点 schema 节点同样 可配置多个,对多库多表进行细粒度的 DML 权限控制;
C. 权限修饰符四位数字(0000 - 1111),对应的操作是 IUSD ( 增,改,查,删 )。同时配置了库跟表的权限,就近原则。以表权限为准。
3.1.3 firewall 标签
firewall标签用来定义防火墙;firewall下whitehost标签用来定义 IP白名单 ,blacklist用来定义 SQL黑名单。
<firewall>
<!-- 白名单配置 -->
<whitehost>
<host user="root" host="127.0.0.1"></host>
</whitehost>
<!-- 黑名单配置 -->
<blacklist check="true">
<property name="selelctAllow">false</property>
</blacklist>
</firewall>
黑名单拦截明细配置:
| 配置项 | 缺省值 | 描述 |
|---|---|---|
| selelctAllow | true | 是否允许执行 SELECT 语句 |
| selectAllColumnAllow | true | 是否允许执行 SELECT * FROM T 这样的语句。如果设置为 false,不允许执行 select * from t,但可以select * from (select id, name from t) a。这个选项是防御程序通过调用 select * 获得数据表的结构信息。 |
| selectIntoAllow | true | SELECT 查询中是否允许 INTO 字句 |
| deleteAllow | true | 是否允许执行 DELETE 语句 |
| updateAllow | true | 是否允许执行 UPDATE 语句 |
| insertAllow | true | 是否允许执行 INSERT 语句 |
| replaceAllow | true | 是否允许执行 REPLACE 语句 |
| mergeAllow | true | 是否允许执行 MERGE 语句,这个只在 Oracle 中有用 |
| callAllow | true | 是否允许通过 jdbc 的 call 语法调用存储过程 |
| setAllow | true | 是否允许使用 SET 语法 |
| truncateAllow | true | truncate 语句是危险,缺省打开,若需要自行关闭 |
| createTableAllow | true | 是否允许创建表 |
| alterTableAllow | true | 是否允许执行 Alter Table 语句 |
| dropTableAllow | true | 是否允许修改表 |
| commentAllow | false | 是否允许语句中存在注释,Oracle 的用户不用担心,Wall 能够识别 hints和注释的区别 |
| noneBaseStatementAllow | false | 是否允许非以上基本语句的其他语句,缺省关闭,通过这个选项就能够屏蔽 DDL。 |
| multiStatementAllow | false | 是否允许一次执行多条语句,缺省关闭 |
| useAllow | true | 是否允许执行 mysql 的 use 语句,缺省打开 |
| describeAllow | true | 是否允许执行 mysql 的 describe 语句,缺省打开 |
| showAllow | true | 是否允许执行 mysql 的 show 语句,缺省打开 |
| commitAllow | true | 是否允许执行 commit 操作 |
| rollbackAllow | true | 是否允许执行 roll back 操作 |
| 拦截配置-永真条件 | ||
| selectWhereAlwayTrueCheck | true | 检查 SELECT 语句的 WHERE 子句是否是一个永真条件 |
| selectHavingAlwayTrueCheck | true | 检查 SELECT 语句的 HAVING 子句是否是一个永真条件 |
| deleteWhereAlwayTrueCheck | true | 检查 DELETE 语句的 WHERE 子句是否是一个永真条件 |
| deleteWhereNoneCheck | false | 检查 DELETE 语句是否无 where 条件,这是有风险的,但不是 SQL 注入类型的风险 |
| updateWhereAlayTrueCheck | true | 检查 UPDATE 语句的 WHERE 子句是否是一个永真条件 |
| updateWhereNoneCheck | false | 检查 UPDATE 语句是否无 where 条件,这是有风险的,但不是SQL 注入类型的风险 |
| conditionAndAlwayTrueAllow | false | 检查查询条件(WHERE/HAVING 子句)中是否包含 AND 永真条件 |
| conditionAndAlwayFalseAllow | false | 检查查询条件(WHERE/HAVING 子句)中是否包含 AND 永假条件 |
| conditionLikeTrueAllow | true | 检查查询条件(WHERE/HAVING 子句)中是否包含 LIKE 永真条件 |
| 其他拦截配置 | ||
| selectIntoOutfileAllow | false | SELECT … INTO OUTFILE 是否允许,这个是 mysql 注入攻击的常见手段,缺省是禁止的 |
| selectUnionCheck | true | 检测 SELECT UNION |
| selectMinusCheck | true | 检测 SELECT MINUS |
| selectExceptCheck | true | 检测 SELECT EXCEPT |
| selectIntersectCheck | true | 检测 SELECT INTERSECT |
| mustParameterized | false | 是否必须参数化,如果为 True,则不允许类似 WHERE ID = 1 这种不参数化的 SQL |
| strictSyntaxCheck | true | 是否进行严格的语法检测,Druid SQL Parser 在某些场景不能覆盖所有的SQL 语法,出现解析 SQL 出错,可以临时把这个选项设置为 false,同时把 SQL 反馈给 Druid 的开发者。 |
| conditionOpXorAllow | false | 查询条件中是否允许有 XOR 条件。XOR 不常用,很难判断永真或者永假,缺省不允许。 |
| conditionOpBitwseAllow | true | 查询条件中是否允许有"&"、"~"、"|"、"^"运算符。 |
| conditionDoubleConstAllow | false | 查询条件中是否允许连续两个常量运算表达式 |
| minusAllow | true | 是否允许 SELECT * FROM A MINUS SELECT * FROM B 这样的语句 |
| intersectAllow | true | 是否允许 SELECT * FROM A INTERSECT SELECT * FROM B 这样的语句 |
| constArithmeticAllow | true | 拦截常量运算的条件,比如说 WHERE FID = 3 - 1,其中"3 - 1"是常量运算表达式。 |
| limitZeroAllow | false | 是否允许 limit 0 这样的语句 |
| 禁用对象检测配置 | ||
| tableCheck | true | 检测是否使用了禁用的表 |
| schemaCheck | true | 检测是否使用了禁用的 Schema |
| functionCheck | true | 检测是否使用了禁用的函数 |
| objectCheck | true | 检测是否使用了“禁用对对象” |
| variantCheck | true | 检测是否使用了“禁用的变量” |
| readOnlyTables | 空 | 指定的表只读,不能够在 SELECT INTO、DELETE、UPDATE、INSERT、MERGE 中作为"被修改表"出现 |
3.2 schema.xml
schema.xml 作为MyCat中最重要的配置文件之一 , 涵盖了MyCat的逻辑库 、 表 、 分片规则、分片节点及数据源的配置。
3.2.1 schema 标签
<schema name="ITCAST" checkSQLschema="false" sqlMaxLimit="100">
<table name="TB_TEST" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
</schema>
schema 标签用于定义 MyCat实例中的逻辑库 , 一个MyCat实例中, 可以有多个逻辑库 , 可以通过 schema 标签来划分不同的逻辑库。MyCat中的逻辑库的概念 , 等同于MySQL中的database概念 , 需要操作某个逻辑库下的表时, 也需要切换逻辑库:
use ITCAST;
3.2.1.1 属性
schema 标签的属性如下 :
1). name
指定逻辑库的库名 , 可以自己定义任何字符串 ;
2). checkSQLschema
取值为 true / false ;
如果设置为true时 , 如果我们执行的语句为 “select * from ITCAST.TB_TEST;” , 则MyCat会自动把schema字符去掉, 把SQL语句修改为 “select * from TB_TEST;” 可以避免SQL发送到后端数据库执行时, 报table不存在的异常 。
不过当我们在编写SQL语句时, 指定了一个不存在schema, MyCat是不会帮我们自动去除的 ,这个时候数据库就会报错, 所以在编写SQL语句时,最好不要加逻辑库的库名, 直接查询表即可。
3). sqlMaxLimit
当该属性设置为某个数值时,每次执行的SQL语句如果没有加上limit语句, MyCat也会自动在limit语句后面加上对应的数值 。也就是说, 如果设置了该值为100,则执行 select * from TB_TEST 与 select * from TB_TEST limit 100 是相同的效果 。
所以在正常的使用中, 建立设置该值 , 这样就可以避免每次有过多的数据返回。
3.2.1.2 子标签table
table 标签定义了MyCat中逻辑库schema下的逻辑表 , 所有需要拆分的表都需要在table标签中定义 。
<table name="TB_TEST" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
属性如下 :
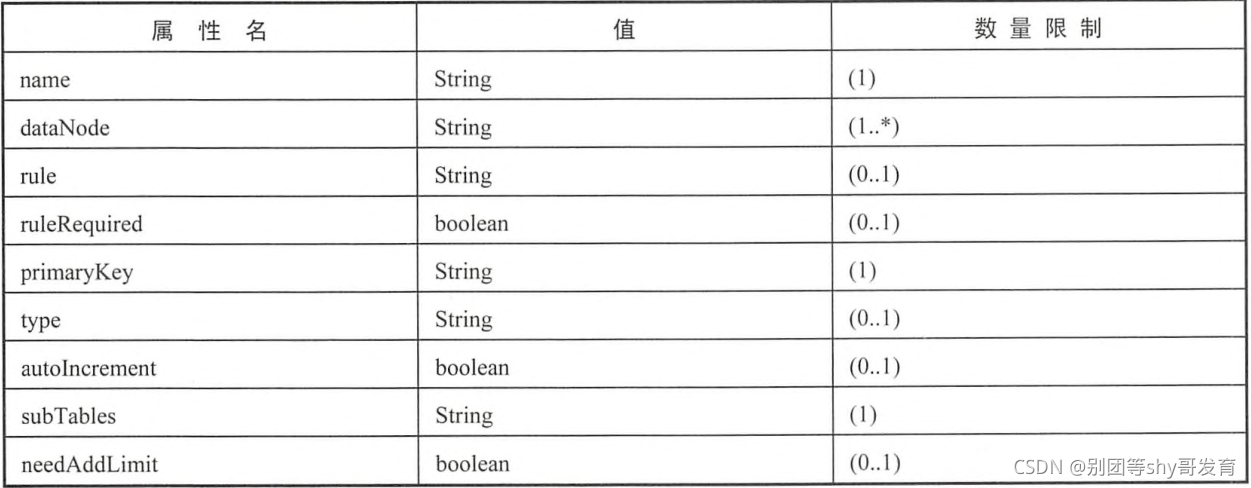
1). name
定义逻辑表的表名 , 在该逻辑库下必须唯一。
2). dataNode
定义的逻辑表所属的dataNode , 该属性需要与dataNode标签中的name属性的值对应。 如果一张表拆分的数据,存储在多个数据节点上,多个节点的名称使用","分隔 。

3). rule
该属性用于指定逻辑表的分片规则的名字, 规则的名字是在rule.xml文件中定义的, 必须与tableRule标签中name属性对应。

4). ruleRequired
该属性用于指定表是否绑定分片规则, 如果配置为true, 但是没有具体的rule, 程序会报错。
5). primaryKey
逻辑表对应真实表的主键
如: 分片规则是使用主键进行分片, 使用主键进行查询时, 就会发送查询语句到配置的所有的datanode上; 如果使用该属性配置真实表的主键, 那么MyCat会缓存主键与具体datanode的信息, 再次使用主键查询就不会进行广播式查询了, 而是直接将SQL发送给具体的datanode。
6). type
该属性定义了逻辑表的类型,目前逻辑表只有全局表和普通表。
全局表:type的值是 global , 代表 全局表 。
普通表:无
7). autoIncrement
mysql对非自增长主键,使用last_insert_id() 是不会返回结果的,只会返回0。所以,只有定义了自增长主键的表,才可以用last_insert_id()返回主键值。
mycat提供了自增长主键功能,但是对应的mysql节点上数据表,没有auto_increment,那么在mycat层调用last_insert_id()也是不会返回结果的。
如果使用这个功能, 则最好配合数据库模式的全局序列。使用 autoIncrement=“true” 指定该表使用自增长主键,这样MyCat才不会抛出 “分片键找不到” 的异常。 autoIncrement的默认值为 false。
8). needAddLimit
指定表是否需要自动在每个语句的后面加上limit限制, 默认为true。
3.2.2 dataNode 标签
<dataNode name="dn1" dataHost="host1" database="db1" />
dataNode标签中定义了MyCat中的数据节点, 也就是我们通常说的数据分片。一个dataNode标签就是一个独立的数据分片。
具体的属性 :
| 属性 | 含义 | 描述 |
|---|---|---|
| name | 数据节点的名称 | 需要唯一 ; 在table标签中会引用这个名字, 标识表与分片的对应关系 |
| dataHost | 数据库实例主机名称 | 引用自 dataHost 标签中name属性 |
| database | 定义分片所属的数据库 |
3.2.3 dataHost 标签
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.192.147:3306" user="root" password="itcast"></writeHost>
</dataHost>
该标签在MyCat逻辑库中作为底层标签存在, 直接定义了具体的数据库实例、读写分离、心跳语句。
3.2.3.1 属性
| 属性 | 含义 | 描述 |
|---|---|---|
| name | 数据节点名称 | 唯一标识, 供上层标签使用 |
| maxCon | 最大连接数 | 内部的writeHost、readHost都会使用这个属性 |
| minCon | 最小连接数 | 内部的writeHost、readHost初始化连接池的大小 |
| balance | 负载均衡类型 | 取值0,1,2,3 ; |
| writeType | 写操作分发方式 | 0 : 写操作都转发到第1台writeHost, writeHost1挂了, 会切换到writeHost2上; 1 : 所有的写操作都随机地发送到配置的writeHost上 ; |
| dbType | 后端数据库类型 | mysql, mongodb , oracle |
| dbDriver | 数据库驱动 | 指定连接后端数据库的驱动,目前可选值有 native和JDBC。native执行的是二进制的MySQL协议,可以使用MySQL和MariaDB。其他类型数据库需要使用JDBC(需要在MyCat/lib目录下加入驱动jar) |
| switchType | 数据库切换策略 | 取值 -1,1,2,3; |
3.2.3.2 子标签heartbeat
配置MyCat与后端数据库的心跳,用于检测后端数据库的状态。heartbeat用于配置心跳检查语句。例如 : MySQL中可以使用 select user(), Oracle中可以使用 select 1 from dual等。
3.2.3.3 子标签writeHost、readHost
指定后端数据库的相关配置, 用于实例化后端连接池。 writeHost指定写实例, readHost指定读实例。
在一个dataHost中可以定义多个writeHost和readHost。但是,如果writeHost指定的后端数据库宕机, 那么这个writeHost绑定的所有readHost也将不可用。
属性:
| 属性名 | 含义 | 取值 |
|---|---|---|
| host | 实例主机标识 | 对于writeHost一般使用 *M1;对于readHost,一般使用 *S1; |
| url | 后端数据库连接地址 | 如果是native,一般为 ip:port ; 如果是JDBC, 一般为jdbc:mysql://ip:port/ |
| user | 数据库用户名 | root |
| password | 数据库密码 | itcast |
| weight | 权重 | 在readHost中作为读节点权重 |
| usingDecrypt | 密码加密 | 默认 0 否 , 1 是 |
3.3 rule.xml
rule.xml中定义所有拆分表的规则, 在使用过程中可以灵活的使用分片算法, 或者对同一个分片算法使用不同的参数, 它让分片过程可配置化。
3.3.1 tableRule标签
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
A. name : 指定分片算法的名称
B. rule : 定义分片算法的具体内容
C. columns : 指定对应的表中用于分片的列名
D. algorithm : 对应function中指定的算法名称
3.3.2 Function标签
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
A. name : 指定算法名称, 该文件中唯一
B. class : 指定算法的具体类
C. property : 根据算法的要求执行
3.4 sequence 配置文件
在分库分表的情况下 , 原有的自增主键已无法满足在集群中全局唯一的主键 ,因此, MyCat中提供了全局sequence来实现主键 , 并保证全局唯一。那么在MyCat的配置文件 sequence_conf.properties 中就配置的是序列的相关配置。
主要包含以下几种形式:
1). 本地文件方式
2). 数据库方式
3). 本地时间戳方式
4). 其他方式
5). 自增长主键

- 点赞
- 收藏
- 关注作者
评论(0)