DTSE Tech Talk 第18期丨统计信息大揭秘,数仓SQL执行优化之密钥

在本期《统计信息大揭秘——SQL执行优化之密钥》的主题直播中,我们邀请到华为云EI DTSE技术布道师王跃,针对统计信息对于查询优化器的重要性,GaussDB(DWS)最新版本的analyze当前能力,与开发者和伙伴朋友们展开交流互动,帮助开发者快速上手使用统计信息的自动收集功能。
为何要重视统计信息收集?
现阶段市场上的数据库产品,基本上都是基于CBO模型的优化器,在基于CBO模型的优化器中,统计信息是生成最优执行计划的前提,会直接影响到执行计划的选择,因此统计信息的及时收集是尤为重要的。

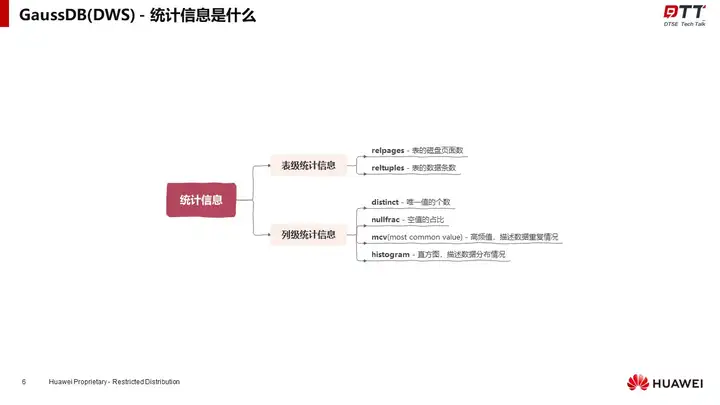
统计信息主要包括“描述表规模的表级统计信息”和“描述列数据特征的列级统计信息”两部分内容。
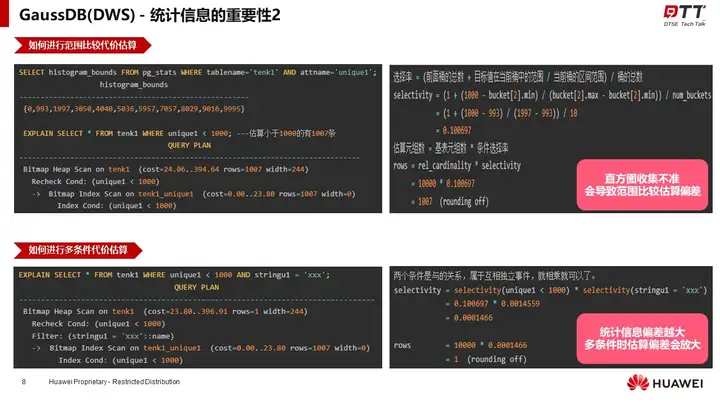
王跃从统计数据在优化器中的运用这一角度,向我们展示了统计信息影响表达小估算的原理、进行等值比较、范围比较、多条件、简单JOIN代价估算的原理,进一步解释了统计信息的重要性。


如何收集统计信息
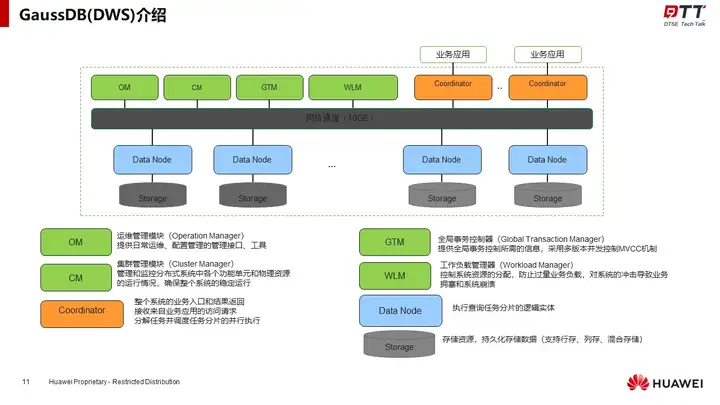
王跃先带我们简单了解了GaussDB(DWS)的部署架构,说明了分布式查询的执行流程和统计信息收集的执行流程。
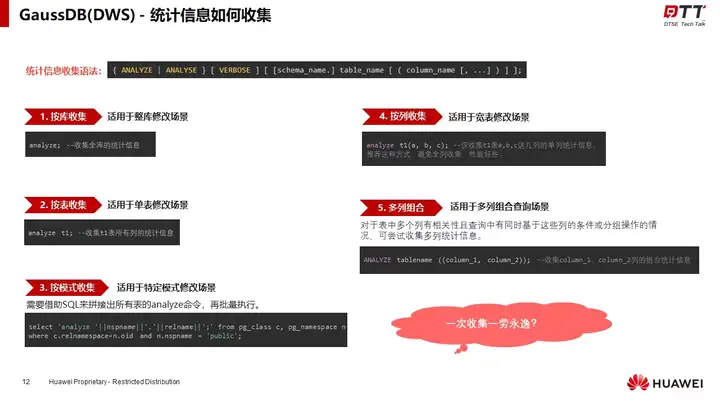
基于此,GaussDB(DWS)共有五种统计信息收集的方法,分别是按库收集、按表收集、按模式收集、按列收集以及多列组合。
GaussDB(DWS)拥有强大的统计信息自动收集能力,通过后台线程轮询收集与优化器同步收集两种方式来实现。王跃建议开发者可以同步开启两种方式,以达到最优的收集功能。
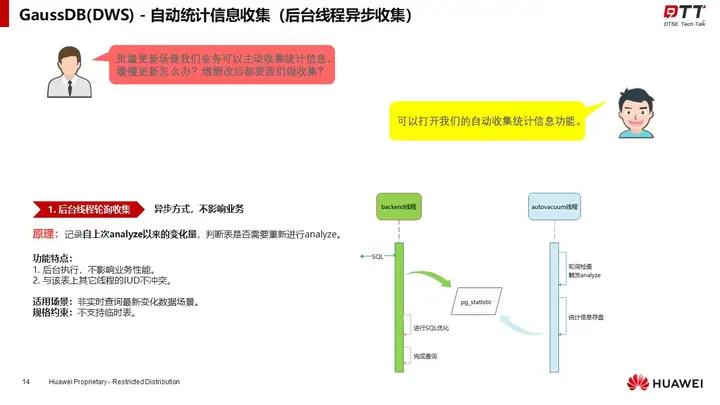
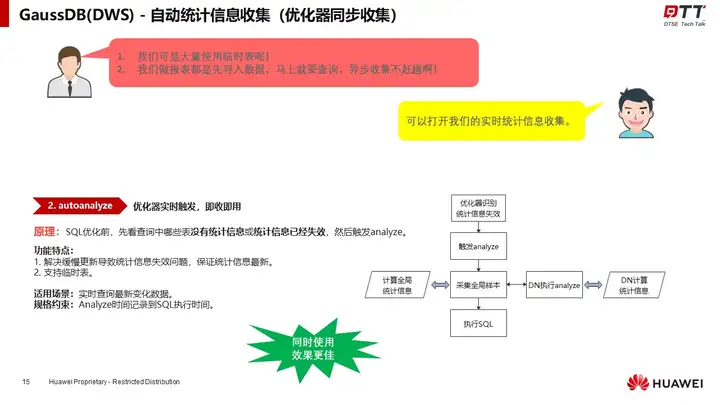
此外,还强调了自动收集的阈值控制方法,同时对收集不及时,统计信息可能失效的场景,提出了一种统计信息推算的兜底策略。确保每个查询都有及时有效的统计信息可用。保证了尽可能最优的执行性能。
华为云数仓analyze能力
通过“基本功能”,“收集方式”,“准确性”,“可靠性”,“估算增强”,详细的介绍了华为云GaussDB(DWS)近年来在统计信息方面的持续耕耘和比较有亮点的特色功能。
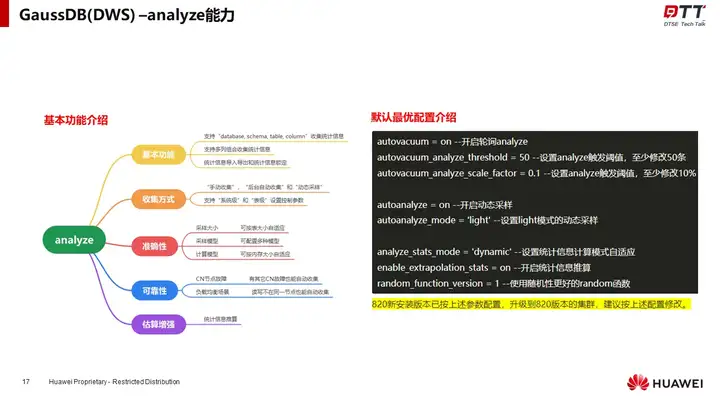
GaussDB(DWS)在analyze的各个执行过程中都进行了精心打造。统计信息是基于对目标数据的采样生成的,所以准确性才是统计信息的关键。
- 样本数据能不能代表全表数据特征?
- 如何找到一个恰当的采样大小,让统计信息收集的又快又准?
- 不同存储类型的表如何自适应的选取采样模型?
- 内存不足时应该如何计算统计信息?
在采样大小,采样模型,计算模型等方面的深入投入,GaussDB(DWS)寻找出了这些问题的最佳答案。
最后给出了一键式统计信息自动收集的最优配置,让用户不再担心统计信息忘记收集的烦恼,帮助开发者专注于自己业务领域,减少统计信息忘收集的困扰。
统计信息常见问题
我们知道了GaussDB(DWS)的统计信息自动收集功能很强大,那我们接下来更关心的是如何检测它的使用效果,如何知道收集的进度和方式。
如何判断统计信息是否失效,给用户提供了三种简单快速识别统计信息未收集的方法:
- 已知SQL执行慢,看是否有未收集统计信息的表;
- 批量作业执行慢,哪些SQL是没收统计信息;
- 通过日志查找历史未收集统计信息的表。
analyze易运维,通过非常巧妙的方法,将analyze每一步的执行过程和运行模式,详细的展示到活跃会话视图和线程等待视图,王跃也在最后列举了一些使用者最常问到关于analyze的几个TOP问题。

欢迎感兴趣的开发者们收看我们的直播回放,了解更多~
视频连接:https://bbs.huaweicloud.com/live/DTT_live/202301111600.html
- 点赞
- 收藏
- 关注作者
评论(0)