第十四届蓝桥杯集训——数组(一维)


![]()
第十四届蓝桥杯集训——数组(一维)
目录
2、二进制搜索:binarySearch(byte[] a, byte key)
3、复制指定数组:copyOf(int[] original, int newLength)
4、复制指定范围数组:copyOfRange(int[] original, int from, int to) 编辑
数组的定义
数组(Array)是有序的元素序列。若将有限个类型相同的变量的集合命名,那么这个名称为数组名。组成数组的各个变量称为数组的分量,也称为数组的元素,有时也称为下标变量。用于区分数组的各个元素的数字编号称为下标。数组是在程序设计中,为了处理方便, 把具有相同类型的若干元素按有序的形式组织起来的一种形式。这些有序排列的同类数据元素的集合称为数组。
数组是用于储存多个相同类型数据的集合。
如果要用户输入的是一个数组,一般是用一个循环,但是在输入前也需要固定数组的大小。
数组的特点:
同一个数组中的数组元素必须具有相同的数据类型,且在内存中连续分布。
无论数组中包含多少个数组元素,该数组只存在一个名称,即数组名。
数组元素的编号称为下标,数组的下标从0 开始 可以通过“数组名[ 下标]”的方式访问数组中的任何元素。
数组的长度指数组可以存储元素的最大个数,在创建数组时确定。
数组的分类:
数据类型:整数类型、浮点数类型、字符数组、字符串数组。
维度类型:一维数组、二维数组、多维数组。
我们在一些基础题目上操作的都是一维数组,在后期我们会接触到深度搜索与广度搜索以及动态规划,基本都是二维数组的处理,所以我们需要对数组进行深度理解。
结构形式:
栈内存
在方法中定义的一些基本类型的变量和对象的引用变量都在方法的栈内存中分配,当在一段代码中定义一个变量时,java就在栈内存中为这个变量分配内存空间,当超出变量的作用域后,java会自动释放掉为该变量所分配的内存空间。
堆内存
堆内存用来存放由new运算符创建的对象和数组,在堆中分配的内存,由java虚拟机的自动垃圾回收器来管理。在堆中创建了一个数组或对象后,同时还在栈内存中定义一个特殊的变量。让栈内存中的这个变量的取值等于数组或者对象在堆内存中的首地址,栈中的这个变量就成了数组或对象的引用变量,引用变量实际上保存的是数组或对象在堆内存中的地址(也称为对象的句柄),以后就可以在程序中使用栈的引用变量来访问堆中的数组或对象。
与结构或类中的字段的区别
数组中的所有元素都具有相同类型(这一点和结构或类中的字段不同,它们可以是不同类型)。数组中的元素存储在一个连续性的内存块中,并通过索引来访问(这一点也和结构和类中的字段不同,它们通过名称来访问)。
数组初始化:
数组初始化通常为两种方法:
1、直接赋值并定义
int[] arr = { 9, 5, 2, 7 };//批量赋值
2、先声明后赋值
int[] array = new int[5];
int[0]=9;//每次单一赋值
数组的读取:
下标读取:System.out.println(arr[1]);
数组常用属性:
1、数组长度:System.out.println(arr.length);
2、数组地址:System.out.println(arr.hashCode());
3、克隆数组:int[] clone = arr.clone();//后期经常用于解决bug
克隆出的数组与原数组是两个地址,不能使用【=】号进行赋值,这样引用的地址是相同的。
package com.item.action; public class demo { public static void main(String[] args) { int[] arr = { 9, 5, 2, 7 }; int[] clone = arr.clone(); System.out.println("原地址:"+arr.hashCode()); System.out.println("克隆地址:"+clone.hashCode()); int[] array = arr; System.out.println("=号赋值地址:"+array.hashCode()); System.out.println("原地址匹配克隆地址:"+arr.equals(clone)); System.out.println("原地址匹配=号赋值地址:"+arr.equals(array)); } }
可以在地址上看出,克隆的重要性,这个问题是后期基础不牢靠的孩子经常出现的问题在这里我标红的特别说一下。

数组遍历:
基础for循环遍历(有下标):
package com.item.action;
public class demo {
public static void main(String[] args) {
int[] arr = { 9, 5, 2, 7 };
//基础for循环遍历
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
}
加强for循环遍历(无下标):
package com.item.action;
public class demo {
public static void main(String[] args) {
int[] arr = { 9, 5, 2, 7 };
//加强for循环遍历
for (int i : arr) {
System.out.println(i);
}
}
}
数组常用函数:
1、自然排序:Arrays.sort(arr);
从小到大,从左到右排序。
package com.item.action;
import java.util.Arrays;
public class demo {
public static void main(String[] args) {
int[] arr = { 9, 5, 2, 7 };
//自然排序
Arrays.sort(arr);
for (int i : arr) {
System.out.println(i);
}
}
}
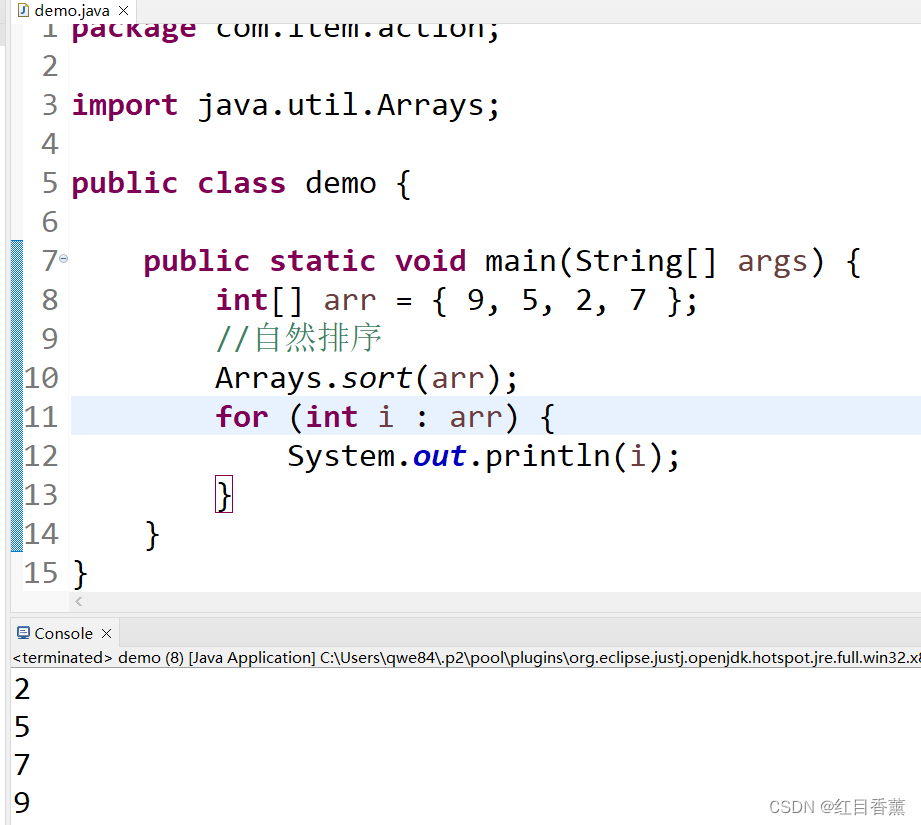
2、二进制搜索:binarySearch(byte[] a, byte key)
package com.item.action;
import java.util.Arrays;
public class demo {
public static void main(String[] args) {
int[] arr = { 9, 5, 2, 7 };
//二进制搜索算法
int index = Arrays.binarySearch(arr, 5);
System.out.println("搜索数字的下标是:"+index);
}
}
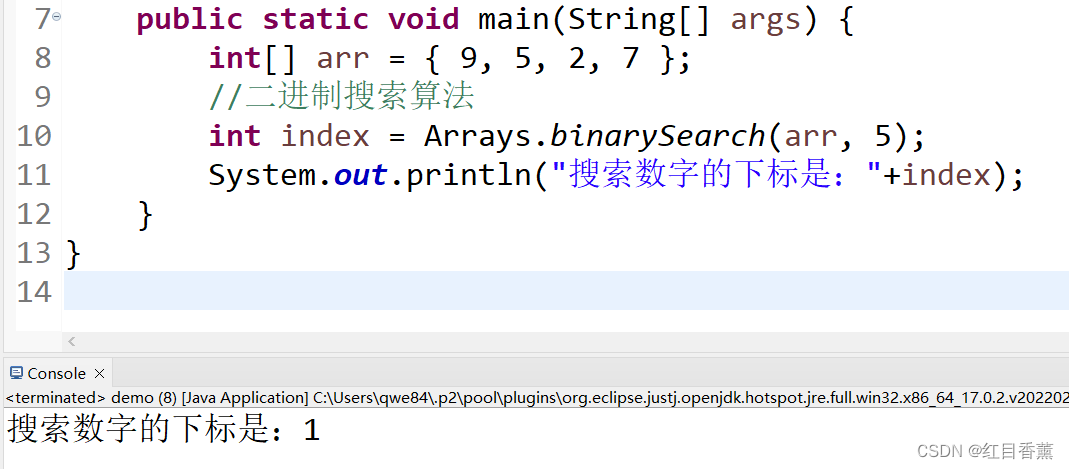
3、复制指定数组:copyOf(int[] original, int newLength)
package com.item.action;
import java.util.Arrays;
public class demo {
public static void main(String[] args) {
int[] arr = { 9, 5, 2, 7 };
//按一定长度截取数组并重新赋值数组
int[] copyOf = Arrays.copyOf(arr, 2);
for (int i : copyOf) {
System.out.println(i);
}
}
}
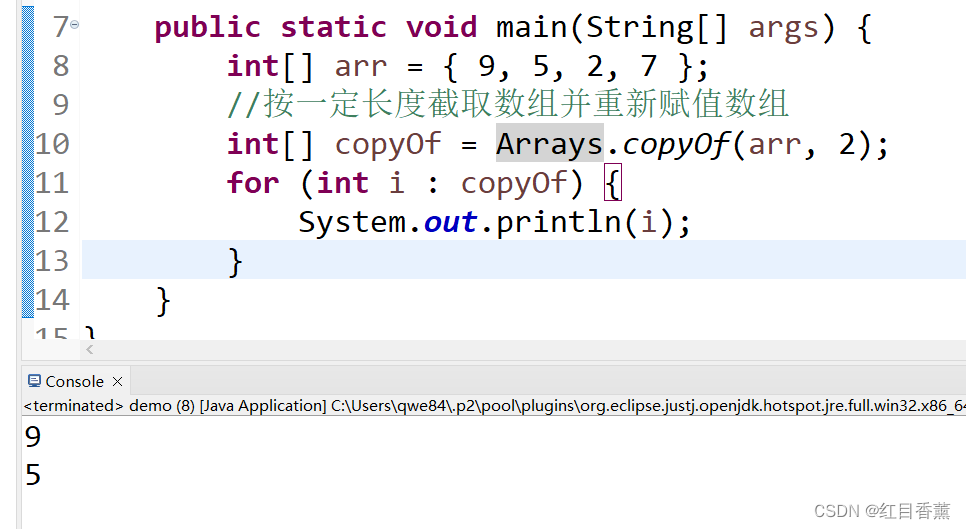
4、复制指定范围数组:copyOfRange(int[] original, int from, int to)
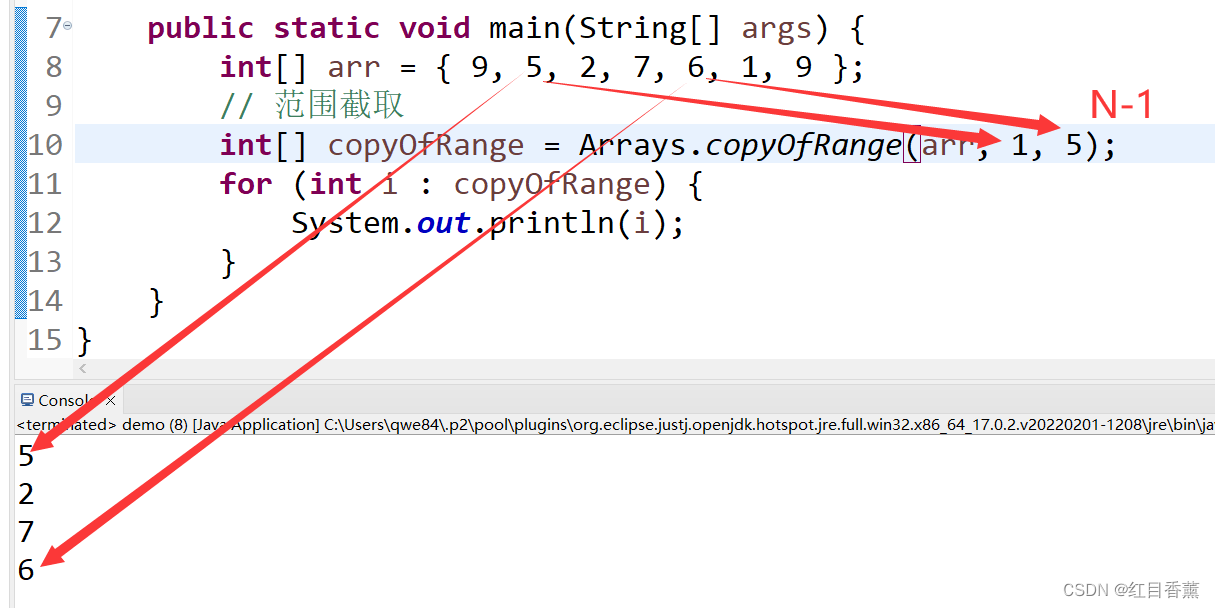
基本常用的函数就这么几个,都是比较常用的。但是不是前期啊,是后期,特别是国赛刷题的时候。

- 点赞
- 收藏
- 关注作者
评论(0)