Java集合Set接口详解——含源码分析

@TOC
前言
前几天我们看了Java集合List接口详解——含源码分析,今天我们看一个数据一个数据存储的另一个接口——Set。
Set
前面我们说List最大的特点是:有序,不唯一,而set是:无序,唯一,无序不是随机,我们后面来通过实现类来看他这俩个特点,还有与list差距比较大的地方是set没有与索引相关的方法,在ArrayList中我们说过,没有索引,就不能用普通for循环来进行遍历。
HashSet
import java.util.HashSet;
public class text1 {
public static void main(String[] args) {
HashSet<Integer> hashSet = new HashSet<>();
hashSet.add(1);
hashSet.add(2);
hashSet.add(2);//唯一性的体现
hashSet.add(3);
hashSet.add(4);
System.out.println(hashSet);
}
}

很好的体现了唯一性,但是有小伙伴可能要说,这不是有序的吗?
其实这是hash内部的存储,与查找,在我的实验中,短数据,有序的Integer类型确实会产生这种情况(具体我们后文再说,hh),但是我们看下面的代码,即可知道hashset的无序性(存入,与取出的顺序不确定)。
import java.util.HashSet;
public class text1 {
public static void main(String[] args) {
HashSet<String > hashSet = new HashSet<>();
hashSet.add("aaa");
hashSet.add("adbab");
hashSet.add("abdb");
hashSet.add("abw");
System.out.println(hashSet);
}
}
下面,我们来存取自定义数据类型,Student对象,存入他们的学号和姓名
import java.util.HashSet;
public class text1 {
public static class Student{
private int id;
private String name;
public Student(int i, String s) {
this.id = i;
this.name = s;
}
public void setId(int id){
this.id = id;
}
public int getId(){
return id;
}
public void setName(String name){
this.name = name;
}
public String getName(){
return name;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
public static void main(String[] args) {
HashSet<Student> hashSet = new HashSet<>();
hashSet.add(new Student(1,"ymm"));
hashSet.add(new Student(1,"ymm"));
hashSet.add(new Student(2,"yxc"));
hashSet.add(new Student(3,"hh"));
System.out.println(hashSet);
}
}

hh,这块hashset又可以重复了?
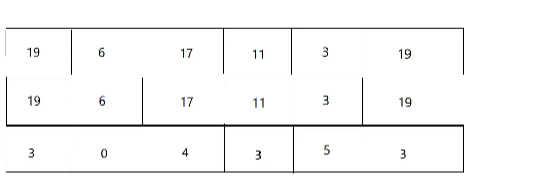
hashset如何进行存取:
- 集合中存入数据
- 要访问的时候,调用对应的hashcode方法来计算哈希值
- 通过哈希值和一个**表达式(我们是不知道的)**计算所对应的值在数组中存放的位置
19便不会被放入。

最后要求:数组+链表=哈希表,重要的方法,也可以说是要满足hashset集合,就要重写hashcode和equals
重写hashcode和equals
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Student)) return false;
Student student = (Student) o;
return getId() == student.getId() && getName().equals(student.getName());
}
@Override
public int hashCode() {
return Objects.hash(getId(), getName());
}
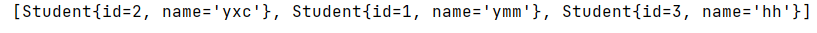
LinkedHashSet
如果我们想要元素有序,可以使用LinkedHashSet,底层是一个链表,这个链表的作用就是将放入的元素串在一起,方便有序的遍历
特点:有序(按照输入顺序进行输出),唯一
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>();
linkedHashSet.add("aa");
linkedHashSet.add("bbc");
linkedHashSet.add("aabsb");
linkedHashSet.add("sjfjdakl");
System.out.println(linkedHashSet);
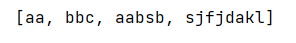
treeset
上面我们说hashset是无序(输入顺序和输出顺序不一致),linkedhashset(输入顺序和输出顺序一致),那么treeset就比较牛逼了,直接输出的时候就帮你排好序(底层是一个红黑树(特殊的二叉查找树)),但是在这个之前,我们先来看一下,比较器这个概念:
比较器
- 相同数据类型的比较
这个没什么好说的,我们直接来看代码:
public int compareTo(String anotherString) {
byte v1[] = value;
byte v2[] = anotherString.value;
if (coder() == anotherString.coder()) {
return isLatin1() ? StringLatin1.compareTo(v1, v2)
: StringUTF16.compareTo(v1, v2);
}
return isLatin1() ? StringLatin1.compareToUTF16(v1, v2)
: StringUTF16.compareToLatin1(v1, v2);
}
上述代码是String内部的比较方法,我们一起来读一下,首先是按照位数进行比较,如果位数相同按照字典序进行一个比较,还是比较简单的
- 比较自定义的数据类型
上面我们看到,相同的数据类型,基本上系统都集成了比较的接口和方法,那么我们自定义的数据类型怎么进行比较呢?是否可以像上面的一样,直接自己写一个比较方法,hh
//内部比较器
public class Student implements Comparable<Student> {
public Student(int id, String name) {
this.id = id;
this.name = name;
}
private int id;
private String name;
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public static void main(String[] args) {
Student s1 = new Student(1,"ymm");
Student s2 = new Student(2,"yxc");
System.out.println(s1.compareTo(s2));
}
//对方法进行重写
@Override
public int compareTo(Student o) {
//按照id进行比较
// return this.getId() - o.getId();
//按照姓名进行比较
return this.getName().compareTo(o.getName());
}
}
缺点:要想比较id就要注释姓名,要想比较姓名就要注释id,故引出下面的外部比较器
class BiJiao01 implements Comparator<Student> {
@Override
public int compare(Student o1,Student o2){
return o1.getName().compareTo(o2.getName());
}
}
class BiJiao02 implements Comparator<Student>{
@Override
public int compare(Student o1,Student o2){
return o1.getId() - o2.getId();
}
}
class BiJiao03 implements Comparator<Student>{
@Override
public int compare(Student o1,Student o2){
if((o1.getId() - o2.getId()) == 0){
return ((o1.getName()).compareTo(o2.getName()));
}else{
return o1.getId() - o2.getId();
}
}
}
由于外部比较器利用了多态,所以可拓展性比较好。
TreeSet特点:唯一,无序(没有按照输入顺序进行输出),有序(按照升序进行遍历)
特殊的二叉搜索树(后面有时间写一篇):
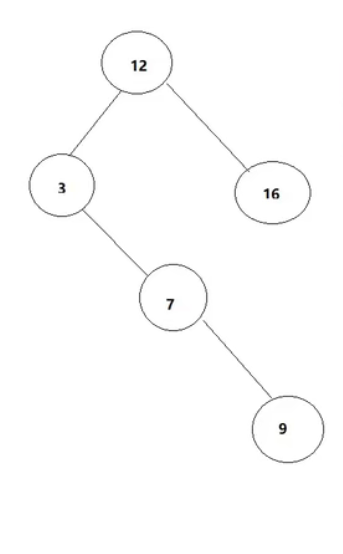
不难看出,在树中放入数据的时候,最重要的事情就是比较,比较的实现: = 0 <0 >0
import java.util.TreeSet;
public class treeSetDemo {
public static void main(String[] args) {
TreeSet<Integer> treeSet = new TreeSet<>();
treeSet.add(12);
treeSet.add(3);
treeSet.add(7);
System.out.println(treeSet);
}
}
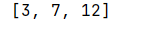

底层运用的是Integer内部比较器
自定义比较器来实现Student类的treeSet存取
import java.util.Comparator;
public class Student implements Comparable<Student> {
public Student(int id, String name) {
this.id = id;
this.name = name;
}
private int id;
private String name;
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
//对方法进行重写
@Override
public int compareTo(Student o) {
//按照id进行比较
return this.getId() - o.getId();
//按照姓名进行比较
//return this.getName().compareTo(o.getName());
}
}
import java.util.TreeSet;
public class treeSetDemo {
public static void main(String[] args) {
TreeSet<Student> treeSet1 = new TreeSet<>();
treeSet1.add(new Student(1,"ymm"));
treeSet1.add(new Student(3,"sss"));
treeSet1.add(new Student(2,"jjj"));
System.out.println(treeSet1);
}
}

外部比较器同理,hh,就像我上面比较器那样,但是在创建类的时候有一点点不一样
public static void main(String[] args){
Comparator<Student> com = new BiJiao();
TreeSet<Student> ts = new TreeSet<>(com);
//指定了一个外部比较器
}
最后
这里挖一个坑,后面我们来讲一下二叉查找树,hh,挖坑没停止

- 点赞
- 收藏
- 关注作者
评论(0)