Java集合List接口详解——含源码分析

@TOC
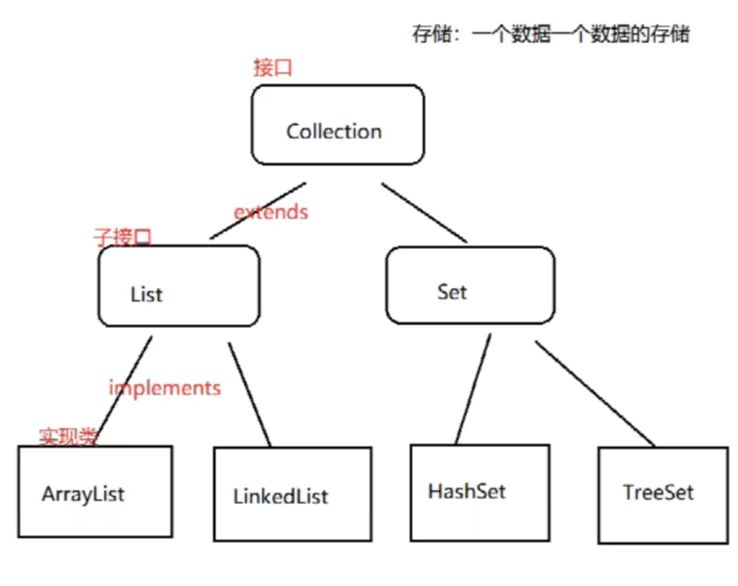
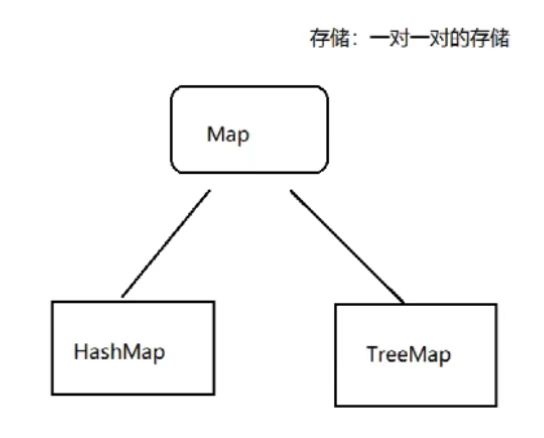
集合
在Java编程中,可以使用数组来保存多个对象,但数组长度不可变化,一旦在初始化数组时指定了数组长度,这个数组长度就是不可变的。如果需要保存数量变化的数据,数组就有点无能为力了。而且数组无法保存具有映射关系的数据,比如5000---iphone,4000----小米,这种俩个数据中存在关联关系的
集合又分为:
- 接口
- 子接口
- 实现类
具体我们看下面俩张图:
Collection集合的常用方法

- 增加:add(E e) addAll(Collection<? extends E>c)
- 删除:clear() remove(Object o)
- 修改
- 查看:iterator() size()
- 判断:contains(Object o) equals(Object o) isEmpty()
import java.util.ArrayList;
import java.util.Collection;
public class jj {
public static void main(String[] args) {
/*
*Collection接口的常用方法
* 增加:add(E e) addAll(Collection<? extends E> c)
* 删除:clear()remove(object o)
*修改
* 判断:contains(Object o) equals(Object o) isEmpty()
*/
//创建对象,接口不能创建对象,利用它的实现类来创建对象
Collection l1 = new ArrayList();
l1.add(18);
//只能存储对象,这里的18实际上是进行了一个装箱的操作
l1.add(19);
System.out.println(l1);
//toString(),就是实现类中的toString
//l1.clear();
System.out.println(l1.size());
System.out.println(l1.isEmpty());
l1.remove(1);
System.out.println(l1);
}
Collection集合的遍历方式:
我们知道常用的遍历数组有俩种方式,普通for循环和增强for循环
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
import java.util.Objects;
public class traverse {
public static void main(String[] args) {
//对集合进行遍历
Collection a = new ArrayList();
a.add(19);
a.add(18);
a.add(20);
a.add(21);
//方式一:普通for循环
// for(int i = 0; i<a.size(); i++){
// col.
// }
//方式二:增强for
for (Object o : a){
System.out.println(o);
}
//方式三:iterator
Iterator it = a.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
Collection集合是不支持普通for的,但是支持增强for和迭代器iterator,迭代器我们后面再说
Collection子接口list
通过Javaapi也不难看出这是一个子接口
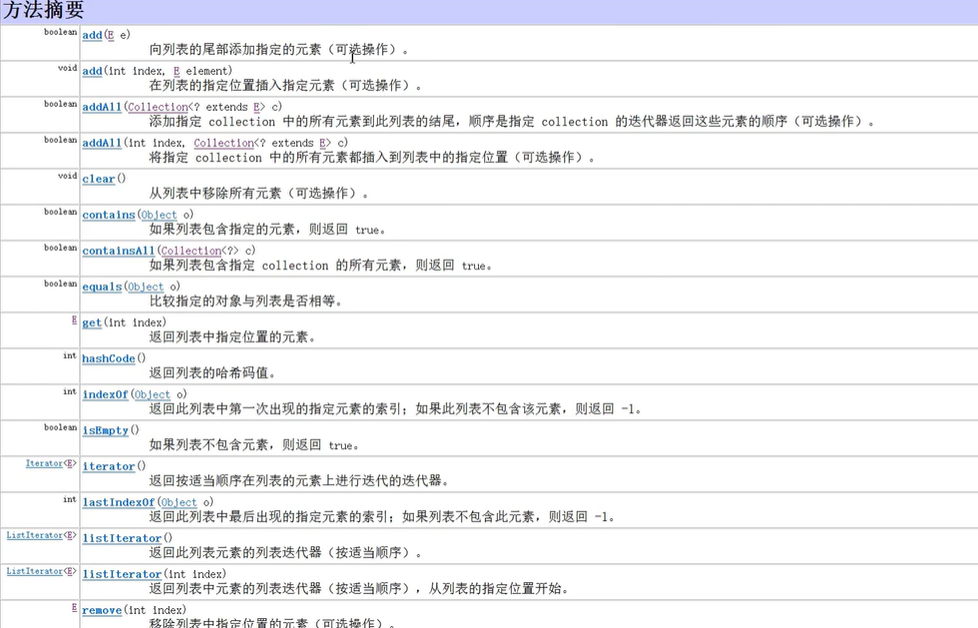
方法比较多,我们主要来说一下Collection没有的方法
/*
*list 接口常用方法
* 增加:add(int index,E element)
* 删除:remove(int index) remove(Object o)
* 修改:set(int index,E element)
* 查看:get(int index)
* 判断
*/
package connector;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class list1 {
public static void main(String[] args) {
List list = new ArrayList();
//子接口要写实现类
list.add(196);
list.add(111);
list.add(222);
System.out.println(list);
list.add(3,333);
System.out.println(list);
list.set(3,33);
System.out.println(list);
list.remove(2);//下标为2的元素
//存入的是Integer类型的数据,删除的是下标为2的元素
System.out.println(list);
list.add("adad");
list.remove("adad");
System.out.println(list);
Object o = list.get(0);
System.out.println(o);
//list集合遍历:
for(int i = 0; i<list.size(); i++){
System.out.println(list.get(i));
}
for(Object object : list){
System.out.println(object);
}
Iterator it = list.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
我们来试想一下,为啥List作为Collection的子接口就能用普通for循环遍历了?
首先我们要明白要用普通for循环,就要有索引方法,来获取元素,而List继承Collection,多出的get方法,使得我们可以获取索引,继而使用普通for循环
源码(均来自JDK1.8)
ArrayList实现类
Array是数组的意思,我们见名知意,可以猜出它的底层应该是用数组来实现的,这个我们后面看源码的时候再说,首先我们看一下,ArrayList中有没有前面没有见过的方法:
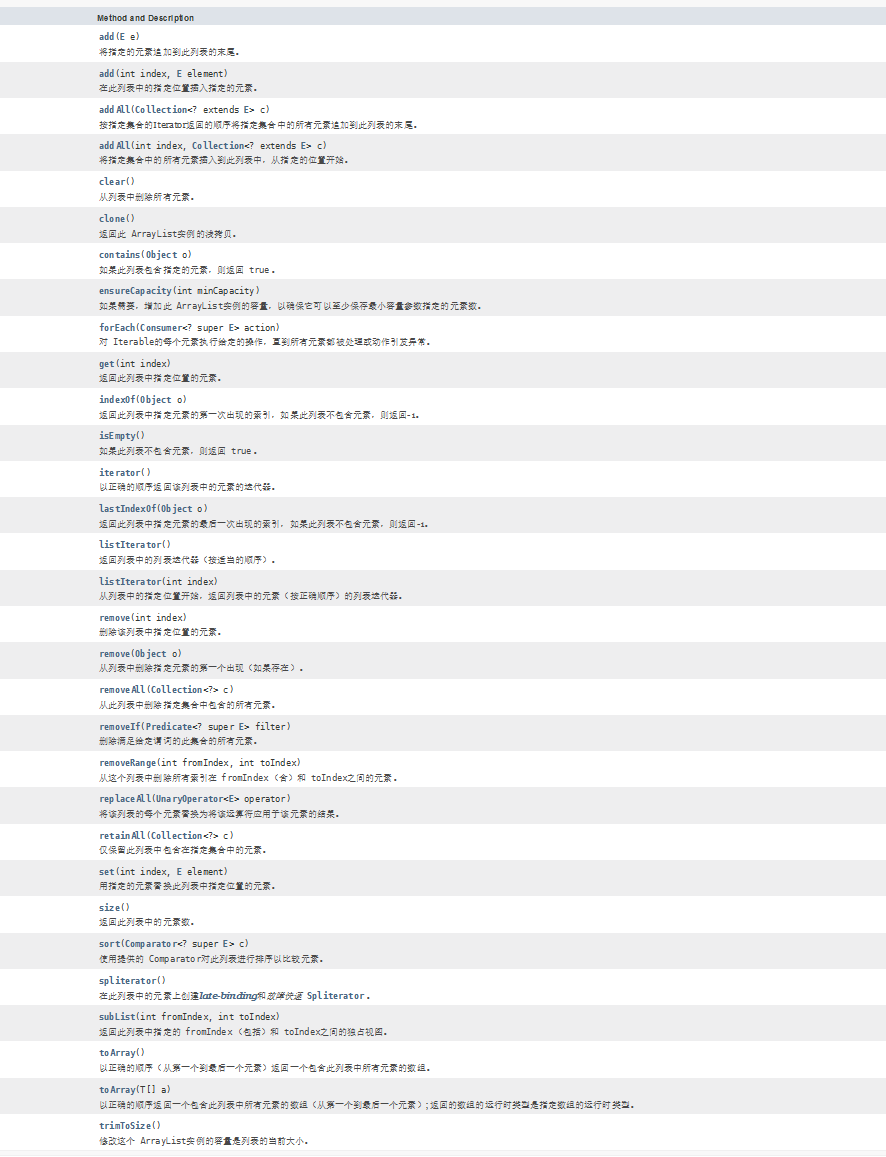
貌似都用过,只有后面三个没用过,其中sort排序方法可以参考我的这篇博客,详述Java中sort排序函数
源码来自JDK1.8
Object类型的数组,和size(数组中的有效长度)
transient Object[] elementData; // non-private to simplify nested class access
private int size;
- 构造一个ArrayList类型的数组
public class arraylist {
public static void main(String[] args) {
ArrayList a1 = new ArrayList();
}
}
//new ArrayList的源码
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;//就是给elementData进行了一个赋值操作
}
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//继续,发现它是给了一个空数组
在jdk1.8中,ArrayList初始化为一个空数组{}
- add方法
package connector;
import java.util.ArrayList;
public class arraylist {
public static void main(String[] args) {
ArrayList a1 = new ArrayList();
a1.add("1");
}
}
public boolean add(E e) {
ensureCapacityInternal(size + 1);
//1. 调用ensureCapacityInternal方法,并且传入size+1,现在数组是空,传入的0+1 = 1
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
//2.传入elementData, minCapacity
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
//3.传入的为elementData和1
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//4.进行比对,发现还是个空数组
return Math.max(DEFAULT_CAPACITY, minCapacity);
//5. 取比较大的值,发现它变为了10
}
return minCapacity;
}
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
private static final int DEFAULT_CAPACITY = 10;
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
//6. 10-0,必然会进入if语句中
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
//7. 数组长度变为10
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
//8. 数组变化完成,将newCapacity赋值给elementData
}
不难看出,初始数组为0,只有当你添加对象的时候,才重新赋值为新的数组,且初始赋值为长度为10的数组
Vector实现类源码
首先我们来说一下区别,再看源码,
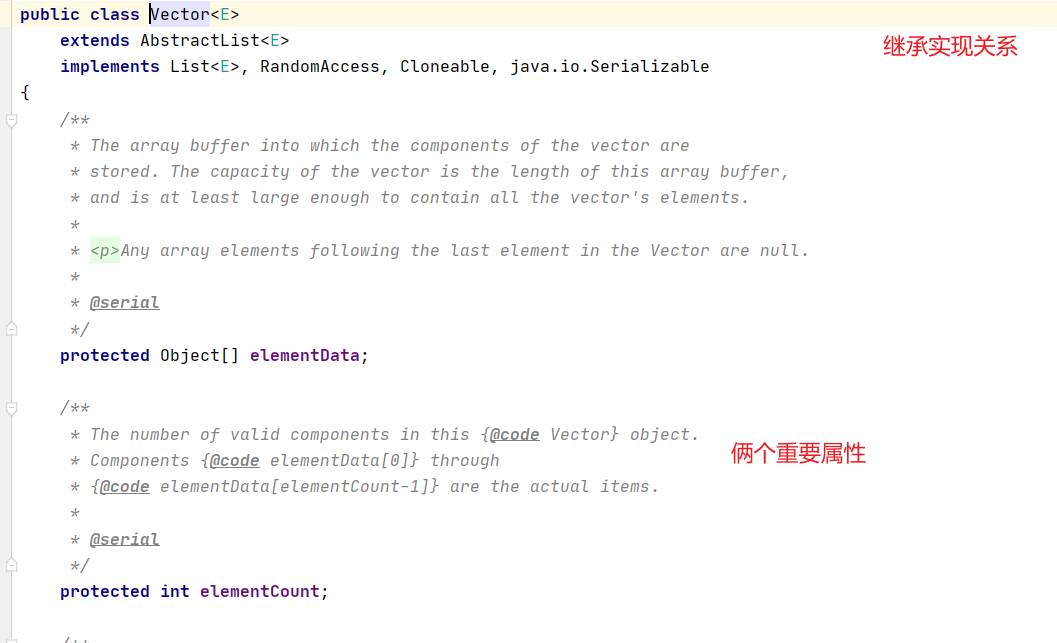
- 底层Object数组,int类型表示数组中的有效长度
- 调用构造器的时候,初始化了一个长度为10 的数组
- add添加元素的时候,底层扩容数组长度为2倍
//调用构造器
public Vector() {
this(10);
}
//add
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
//传入0+1
elementData[elementCount++] = e;
return true;
}
private void ensureCapacityHelper(int minCapacity) {
if (minCapacity - elementData.length > 0)
grow(minCapacity);
//grow
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
//扩容长度为2倍
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
//基本和上面的ArrayList的add源码一样
对比ArrayList线程安全
synchronized
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
联系:
- 底层都是数组的扩容
- ArrayList是1.5倍扩容,但是不安全
- Vector是2倍扩容,但是安全
数组的优缺点:
数据可重复,查询快,删改慢,这个可以参考,数据结构相关书籍
LinkList实现类
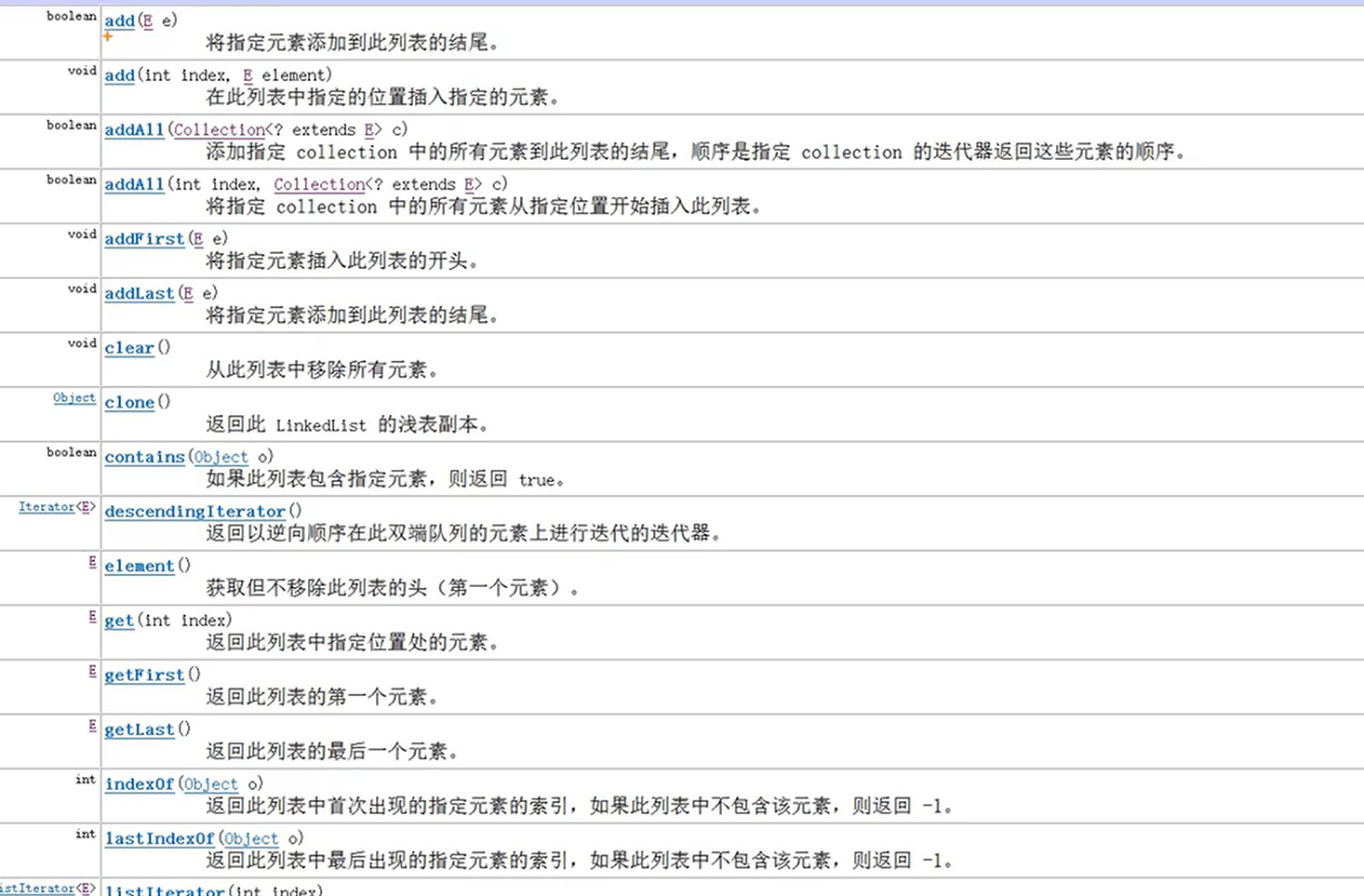
不难看出add方法中,LinkList多了addFirst,addLast,下面我们用crud来总结一下:
增加:addFirst(E e) addLast(E e)
删除:poll()
pollFirst() pollLast()
removeFirst() removeLast()
修改:
查看:element()
getFirst() getLast()
indexof(Object o) LastIndexOf(Object o)
peek()
peekFirst() peekLast()
判断:
代码实现:
import java.util.HashMap;
import java.util.LinkedList;
public class Main {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("addd");
list.add("bddd");
list.add("cddd");
list.add("addd");
System.out.println(list);//LinkedList可以添加重复数据
list.addLast("hh");
list.addFirst("gg");
list.offer("kk");//添加元素到尾端
System.out.println(list);
//删除
System.out.println(list.poll());//删除头上的元素,并且返回头上元素
System.out.println(list);
System.out.println(list.removeFirst());//删除头尾元素
System.out.println(list.removeLast());
list.clear();//清空集合
System.out.println(list);
System.out.println(list.pollFirst());//可以
System.out.println(list.removeFirst());//报错
}
}
poll和remove的区别:
如果为空,poll不报错,返回null,但是remove报错

LinkedList的遍历
import java.util.HashMap;
import java.util.Iterator;
import java.util.LinkedList;
public class Main {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("addd");
list.add("bddd");
list.add("cddd");
list.add("addd");
//集合的遍历
System.out.println("---------------");
//普通for循环
for(int i = 0;i<list.size(); i++){
System.out.println(list.get(i));
}
//增强for
for(String s : list){
System.out.println(s);
}
//迭代器
Iterator<String >iterator = list.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
LinkedList源码(JDK17)
为啥突然换成jdk17了?前几天电脑崩了,脑子一糊涂,c盘删了10个g的文件,被迫用笔记本来看源码了,hh
LinkedList数据结构:
线性表(链表)——>双向链表
下面,用Java语言来描述一下:
//节点类
public class Node{
//上一个元素的地址:
private Node pre;
//当前存入的元素:
private Object obj;
//下一个元素的地址:
private Node next;
public Node getPre() {
return pre;
}
public void setPre(Node pre) {
this.pre = pre;
}
public Object getObj() {
return obj;
}
public void setObj(Object obj) {
this.obj = obj;
}
public Node getNext() {
return next;
}
public void setNext(Node next) {
this.next = next;
}
@Override
public String toString() {
return "Node{" +
"pre=" + pre +
", obj=" + obj +
", next=" + next +
'}';
}
}
//链表实现类
public class MyLinkedList {
//链表中一定有一个首节点,一定有一个尾节点
//当为空链的时候俩个节点都为null
Main.Node first;
Main.Node last;
//计数器
int count = 0;
//构造器:
public MyLinkedList(){
}
//add
public void add(Object obj){
if(first == null){
//add(第一个元素)
Main.Node n = new Main.Node();
n.setPre(null);
n.setObj(obj);
n.setNext(null);
//节点变化
first = n;
last = n;
} else {
//常规情况
Main.Node node = new Main.Node();
node.setPre(last);//node的上一个节点一定是当前链中的最后一个节点
node.setObj(obj);
node.setNext(null);
//当前链中的最后一个节点的下一个元素 要指向node
last.setNext(node);
//最后一个节点变成node
last = node;
}
//计数器加一
count++;
}
public int getCount(){
return count;
}
public Object get(int index){
Main.Node n = first;//表头
for(int i = 0; i<index; i++){
n = n.getNext();
}
return n.getObj();
}
}
class Text{
public static void main(String[] args) {
MyLinkedList ml = new MyLinkedList();
ml.add("aa");
ml.add("bb");
ml.add("cc");
System.out.println(ml.getCount());
System.out.println(ml.get(2));
}
}
下面我们来看jdk17当中LinkedList的源码是怎么写的吧,
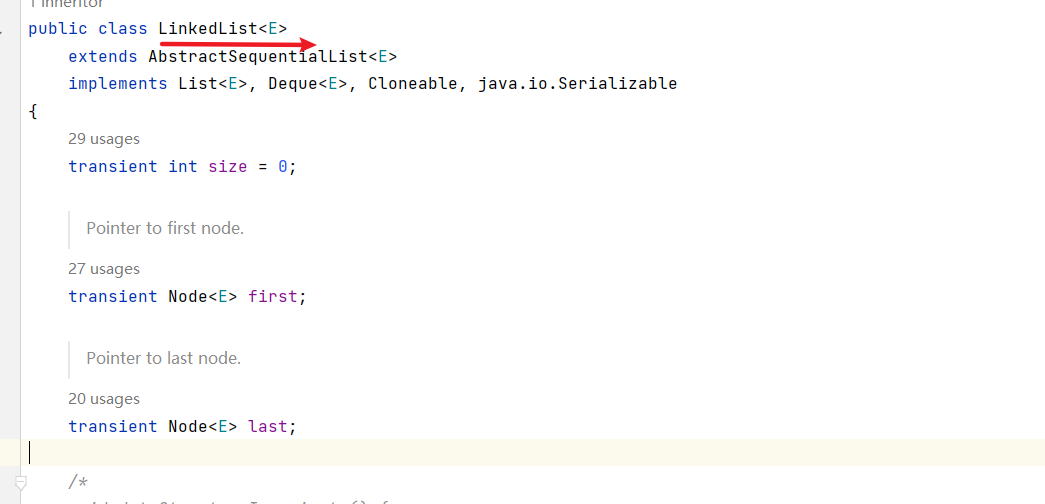
E就是一个泛型,具体的类型要在实例化的时候才会最终确定,具体可以看一下,我前几天写的这篇文章:
Java泛型——帮助你更好的读懂源码<dog>
int size就是集合中元素的数量
first,last,就是我们上面手写link的First,Last
空构造器

add方法

//add方法
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first; //添加元素为第一个节点
final Node<E> newNode = new Node<>(null, e, f);//将元素封装成一个具体对象
first = newNode;
if (f == null)
last = newNode;//如果是第一个节点,将链表的first节点指向为新节点
else
f.prev = newNode;//将l的下一个指向为新节点
size++;
modCount++;
}
鉴于篇幅原因,剩下的方法源码分析,还请读者自行解决,或者可以私信我!

- 点赞
- 收藏
- 关注作者
评论(0)