随机森林分类器

【摘要】 @toc 1、随机森林 随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树。想象组合分类器中的每个分类器都是一棵决策树,因此,分类器的集合就是一个“森林”。更准确地说,每一棵树都依赖于独立抽样,并与森林中所有树具有相同分布地随机向量值。 随机森林是利用多个决策树对样本进行训练、分类并预测地一种算法,主要应用于回归和分类场景。在对数据进行分类地同时,还可以给出各个变...
@toc
1、随机森林
随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树。想象组合分类器中的每个分类器都是一棵决策树,因此,分类器的集合就是一个“森林”。更准确地说,每一棵树都依赖于独立抽样,并与森林中所有树具有相同分布地随机向量值。
随机森林是利用多个决策树对样本进行训练、分类并预测地一种算法,主要应用于回归和分类场景。在对数据进行分类地同时,还可以给出各个变量地重要性评分,评估各个变量在分类中所起地作用。分类时,每棵树都投票并且返回得票最多的类。

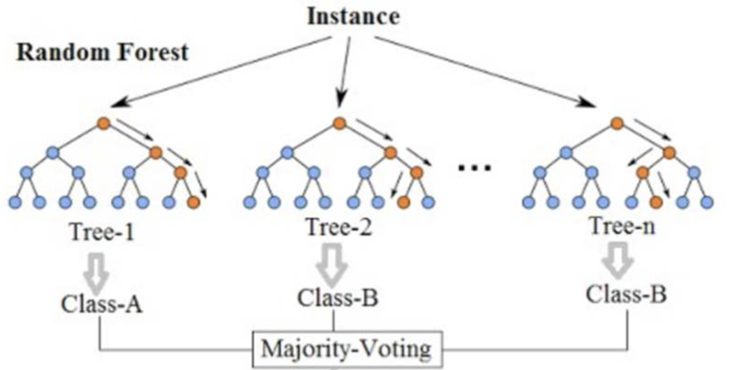
2、基本思想
-
行采样:有放回的重采用抽样数据;数据的随机性,模型求同存异。

-
列采样:有放回的重采用抽样特征。特征的随机性,模型求同存异。
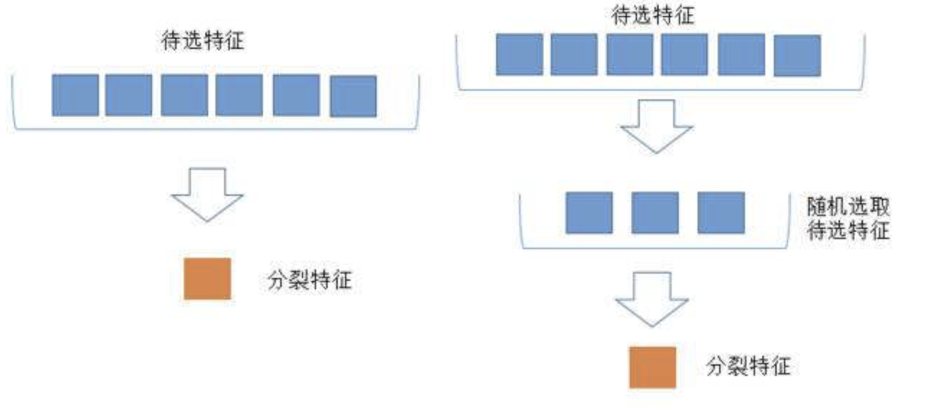
3、随机森林的生成
-
关键因素:每棵树选择特征的数量m
-
随机森林分类效果(错误率)与两个因素有关:
-
森林中任意两棵树的相关性:相关性越大,错误率就越大;(说明基分类器差异性越小)
-
森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低(基分类器准确率高)
-
-
减小特征选择个数m,树的相关性和分类能力也会相应的降低;增大m,两者也会随之增大。所以关键问题是如何选择最优的m
4、随机森林参数与评价
4.1 特征数量m的选择
- Square Root(K):根据特征数量开根号,一般不用。
- 网格搜索法调参GridSearch:尝试多种m,看哪种随机森林最有效。
4.2 决策树的数量
- 500或者更多。
5、随机森林的优点
- 两个随机性的引入,使得随机森林不容易陷入过拟合;
- 两个随机性的引入,使得随机森林具有很好的抗噪声能力;
- 对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化且能够有效地运行在大数据集上;
- 能够处理具有高维特征的输入样本,而且不需要降维;
- 对于缺失值问题也能够获得很好得结果。
6、实战:随机森林实现iris数据集分类
任务描述:使用Python语言编程,使用 iris 数据集训练一个RandomForestClassifier 随机森林分类器。RandomForestClassifier 在 scikit-learn 库的 ensemble 包之中。RandomForestClassifier 使用很简单,三步:
- 创建 RandomForestClassifier 对象
- 调用 fit 函数
- 调用 predict 函数进行预测
# 随机森林分类器
# 导入相关库
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
import numpy as np
# 下载数据集
iris = load_iris()
X = iris["data"]
y = iris["target"]
np.random.seed(0)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 创建 RandomForestClassifier 对象
########## Begin ##########
clf = RandomForestClassifier(n_estimators=100)
########## End ##########
# 调用 fit 函数执行训练过程
clf.fit(X_train,y_train)
# 打印结果
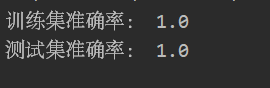
print('训练集准确率:', accuracy_score(y_train, clf.predict(X_train)))
print('测试集准确率:', accuracy_score(y_test, clf.predict(X_test)))

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)