前向传播实战

【摘要】 @toc 1、简介 我们这里使用张量的基本操作去完成三层神经网络的实现:out=ReLU(ReLu(ReLU(X@W1+b1)@W2+b2)@W3+b3)out=ReLU(ReLu(ReLU(X@W_1+b_1)@W_2+b_2)@W_3+b3)out=ReLU(ReLu(ReLU(X@W1+b1)@W2+b2)@W3+b3) 采用的数据集是MNIST手写数字图片数据集,输入节...
@toc
1、简介
我们这里使用张量的基本操作去完成三层神经网络的实现:
采用的数据集是MNIST手写数字图片数据集,输入节点数为784,第一层的输出节点数是256,第二层的输出节点数是128,第三层的输出节点数是10,也就是当前样本属于10个类别的概率。
2、前向传播实战
2.1 导入依赖
import os
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow.keras.datasets as datasets
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
plt.rcParams['font.size'] = 16
plt.rcParams['font.family'] = ['STKaiti']
plt.rcParams['axes.unicode_minus'] = False
2.2 加载数据集
def load_data():
# 加载 MNIST 数据集
(x, y), (x_val, y_val) = datasets.mnist.load_data()
# 转换为浮点张量, 并缩放到-1~1
x = tf.convert_to_tensor(x, dtype=tf.float32) / 255.
# 转换为整形张量
y = tf.convert_to_tensor(y, dtype=tf.int32)
# one-hot 编码
y = tf.one_hot(y, depth=10)
# 在前向计算时,首先将shape为[b,28,28]的输入张量的视图调整为[b,784],即将每个图片的矩阵数据调整为向量特征,这样才适合网络的输入格式:
# 改变视图, [b, 28, 28] => [b, 28*28]
x = tf.reshape(x, (-1, 28 * 28))
# 构建数据集对象
train_dataset = tf.data.Dataset.from_tensor_slices((x, y))
# 批量训练
train_dataset = train_dataset.batch(200)
return train_dataset
2.3 创建每个非线性层的W和b参数
每个张量都需要被优化,所以使用Variable类型,并使用截断的正态分布初始化权值向量
# 创建每个非线性层的W和b张量参数
def init_paramaters():
# 每层的张量都需要被优化,故使用 Variable 类型,并使用截断的正太分布初始化权值张量
# 偏置向量初始化为 0 即可
# 第一层的参数
w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1))
b1 = tf.Variable(tf.zeros([256]))
# 第二层的参数
w2 = tf.Variable(tf.random.truncated_normal([256, 128], stddev=0.1))
b2 = tf.Variable(tf.zeros([128]))
# 第三层的参数
w3 = tf.Variable(tf.random.truncated_normal([128, 10], stddev=0.1))
b3 = tf.Variable(tf.zeros([10]))
return w1, b1, w2, b2, w3, b3
2.4 前向计算
第一层计算,这里显示地进行自动扩展操作:
# 第一层计算, [b, 784]@[784, 256] + [256] => [b, 256] + [256] => [b,256] + [b, 256]
h1 = x @ w1 + tf.broadcast_to(b1, (x.shape[0], 256))
h1 = tf.nn.relu(h1) # 通过激活函数
用同样地方法完成第二个和第三个非线性函数层地前向计算,输出层可以不使用ReLU激活函数:
# 第二层计算, [b, 256] => [b, 128]
h2 = h1 @ w2 + b2
h2 = tf.nn.relu(h2)
# 输出层计算, [b, 128] => [b, 10]
out = h2 @ w3 + b3
将真实地标注张量y转变为独热编码,并计算与out的均方误差,代码如下:
# 计算网络输出与标签之间的均方差, mse = mean(sum(y-out)^2)
# [b, 10]
loss = tf.square(y - out)
# 误差标量, mean: scalar
loss = tf.reduce_mean(loss)
上述的前向计算过程都包裹在with tf.GradientTape() as tape上下文中,使得前向计算时候能够保存计算图信息,方便自动求导操作。
2.5 自动梯度与梯度更新
通过tape.gradient()函数求得网络参数得到梯度信息,结果保存在grads列表变量中,实现如下:
# 自动梯度,需要求梯度的张量有[w1, b1, w2, b2, w3, b3]
grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3])
并按照公式:
来更新网络参数:
# 梯度更新, assign_sub 将当前值减去参数值,原地更新
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
w3.assign_sub(lr * grads[4])
b3.assign_sub(lr * grads[5])
其中,assign_sub()将自身减去给定的参数值,实现参数的原地(In-place)更新操作。
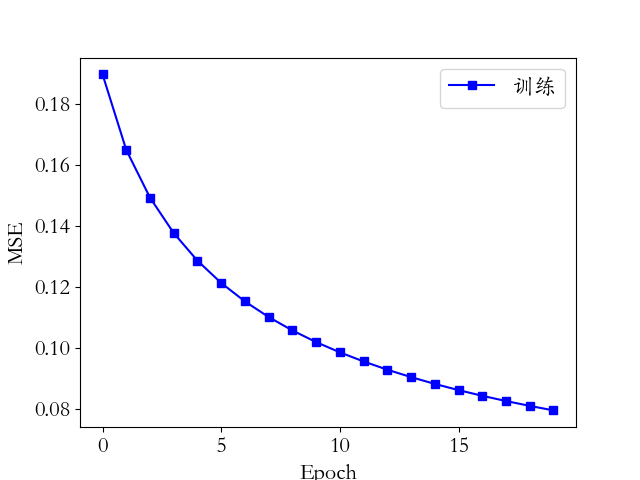
网络训练误差值的变化曲线如下图所示:
2.6 完整代码
import os
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow.keras.datasets as datasets
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
plt.rcParams['font.size'] = 16
plt.rcParams['font.family'] = ['STKaiti']
plt.rcParams['axes.unicode_minus'] = False
def load_data():
# 加载 MNIST 数据集
(x, y), (x_val, y_val) = datasets.mnist.load_data()
# 转换为浮点张量, 并缩放到-1~1
x = tf.convert_to_tensor(x, dtype=tf.float32) / 255.
# 转换为整形张量
y = tf.convert_to_tensor(y, dtype=tf.int32)
# one-hot 编码
y = tf.one_hot(y, depth=10)
# 改变视图, [b, 28, 28] => [b, 28*28]
x = tf.reshape(x, (-1, 28 * 28))
# 构建数据集对象
train_dataset = tf.data.Dataset.from_tensor_slices((x, y))
# 批量训练
train_dataset = train_dataset.batch(200)
return train_dataset
# 创建每个非线性层的W和b张量参数
def init_paramaters():
# 每层的张量都需要被优化,故使用 Variable 类型,并使用截断的正太分布初始化权值张量
# 偏置向量初始化为 0 即可
# 第一层的参数
w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1))
b1 = tf.Variable(tf.zeros([256]))
# 第二层的参数
w2 = tf.Variable(tf.random.truncated_normal([256, 128], stddev=0.1))
b2 = tf.Variable(tf.zeros([128]))
# 第三层的参数
w3 = tf.Variable(tf.random.truncated_normal([128, 10], stddev=0.1))
b3 = tf.Variable(tf.zeros([10]))
return w1, b1, w2, b2, w3, b3
def train_epoch(epoch, train_dataset, w1, b1, w2, b2, w3, b3, lr=0.001):
for step, (x, y) in enumerate(train_dataset):
with tf.GradientTape() as tape: # 默认跟踪的是tf.Variable类型
# 第一层计算, [b, 784]@[784, 256] + [256] => [b, 256] + [256] => [b,256] + [b, 256]
h1 = x @ w1 + tf.broadcast_to(b1, (x.shape[0], 256))
h1 = tf.nn.relu(h1) # 通过激活函数
# 第二层计算, [b, 256] => [b, 128]
h2 = h1 @ w2 + b2
h2 = tf.nn.relu(h2)
# 输出层计算, [b, 128] => [b, 10]
out = h2 @ w3 + b3
# 计算网络输出与标签之间的均方差, mse = mean(sum(y-out)^2)
# [b, 10]
loss = tf.square(y - out)
# 误差标量, mean: scalar
loss = tf.reduce_mean(loss)
# 自动梯度,需要求梯度的张量有[w1, b1, w2, b2, w3, b3]
grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3])
# 梯度更新, assign_sub 将当前值减去参数值,原地更新
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
w3.assign_sub(lr * grads[4])
b3.assign_sub(lr * grads[5])
if step % 100 == 0:
print(epoch, step, 'loss:', loss.numpy())
return loss.numpy()
def train(epochs):
losses = []
train_dataset = load_data()
w1, b1, w2, b2, w3, b3 = init_paramaters()
for epoch in range(epochs): # 20
loss = train_epoch(epoch, train_dataset, w1, b1, w2, b2, w3, b3, lr=0.001)
losses.append(loss)
x = [i for i in range(0, epochs)]
# 绘制曲线
plt.plot(x, losses, color='blue', marker='s', label='训练')
plt.xlabel('Epoch')
plt.ylabel('MSE')
plt.legend()
plt.savefig('MNIST数据集的前向传播训练误差曲线.png')
plt.show()
if __name__ == '__main__':
train(epochs=20)
看懂上面的代码必须将tensorflow的张量计算十分熟练才可以。
3、总结
刚开始我只会调用keras的API,不知道底层是怎么计算的,导致遇到复杂的模型看不懂别人的代码,现在终于将梯度下降法和前向传播搞明白了(无非就是通过偏导数去更新参数W和b,然后再计算损失)

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)