RegNet架构复现--CVPR2020

@toc
参考论文:Designing Network Design Spaces
作者:Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, ==Kaiming He==, Piotr Dollár
我看了下,这个有两篇论文,一篇是Designing Network Design Spaces,另一篇是Fast and Accurate Model Scaling,这里只说第一篇论文里面的架构,第二篇等我看完论文再说。
1、摘要
在这项工作中,我们提出了一种新的网络设计范式。我们的目标是帮助促进对网络设计的理解,并发现跨环境通用的设计原则。我们不是专注于设计单个网络实例,而是设计参数化网络群体的网络设计空间。整个过程类似于经典的网络手动设计,但提升到了设计空间级别。使用我们的方法,我们探索了网络设计的结构方面,并得出了一个由简单、规则的网络组成的低维设计空间,我们称之为 ==RegNet==。
RegNet 参数化的核心见解非常简单:好的网络的宽度和深度可以用一个量化的线性函数来解释。我们分析了 RegNet 设计空间并得出了与当前网络设计实践不匹配的有趣发现。 RegNet 设计空间提供了简单而快速的网络,可以在各种翻牌制度中很好地工作。在可比较的训练设置和失败情况下,RegNet 模型优于流行的 EfficientNet 模型,同时在 GPU 上的速度提高了 5 倍。
2、RegNet性能

这是一些移动网络模型的性能比较,可以看到,在top-1错误率上面,RegNet和MobileNet、ShuffleNet还是很有竞争力的。
与ResNet和ResNext比较:
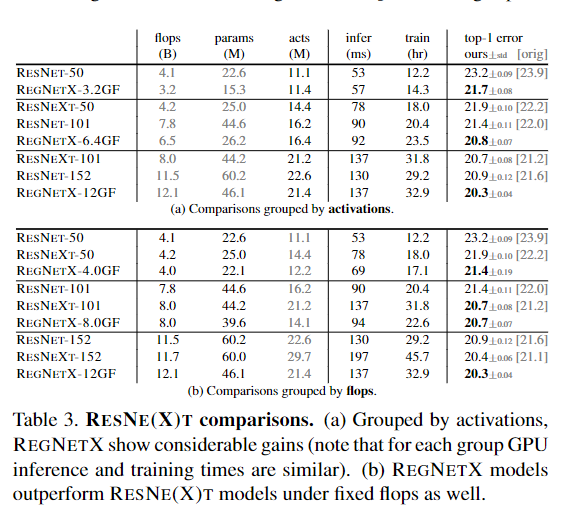
表3 RESNE(X)T 比较。 (a) 按激活分组,REGNETX 显示出可观的收益(请注意,对于每组 GPU 推理和训练时间是相似的)。 (b) REGNETX 模型在固定触发器下也优于 RESNE(X)T 模型。
与EfficientNet比较:
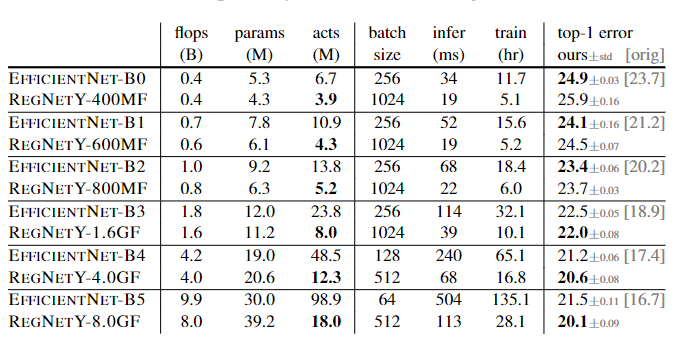
在可比较的训练设置下,REGNETY 在大多数失败状态下的表现都优于 EFFICIENTNET。此外,REGNET 模型要快得多,例如,REGNETX-F8000 比 EFFICIENTNET-B5 快约 5 倍。
3、RegNet网络结构
3.1 General Network structure
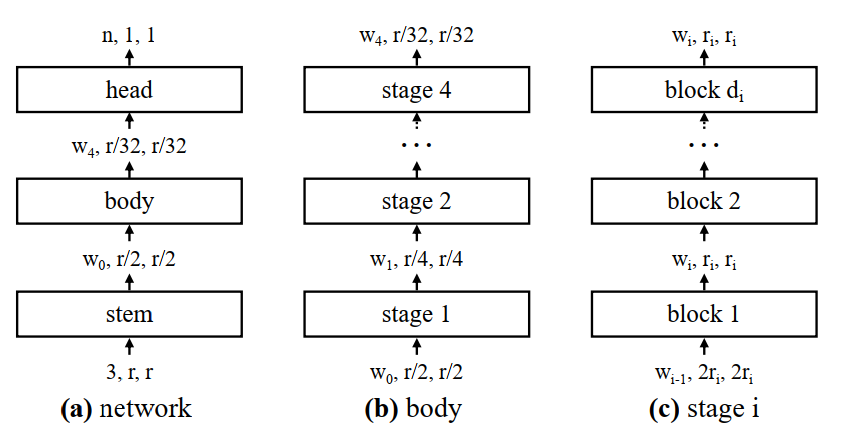
图 3. 我们设计空间中模型的一般网络结构。
(a) 每个网络由一个主干(stride-two 3×3 conv with w0 = 32 output channels),然后是执行大部分计算的网络主体,然后是一个头(平均池化,然后是一个全连接层)预测 n 个输出类别。
(b) 网络主体由一系列阶段组成,这些阶段以逐渐降低的分辨率 运行。
© 每个阶段都由一系列相同的块组成,除了第一个块使用 stride-2 conv。虽然一般结构很简单,但可能的网络配置的总数是巨大的。
其中stem就是一个普通的卷积层(后跟BN+ReLU),卷积核大小为3x3,stride=2,卷积核个数为32。
其中body就是由4个stage堆叠组成,如图(b)所示。每经过一个stage都会将输入特征矩阵的height和width缩减为原来的一半。
而每个stage又是由一系列block堆叠组成,每个stage的第一个block中存在步距为2的组卷积(主分支上)和普通卷积(捷径分支上),剩下的block中的卷积步距都是1,和ResNet类似。
其中head就是分类网络中常见的分类器,由一个全局平均池化层和全连接层构成。
3.2 RegNet Block
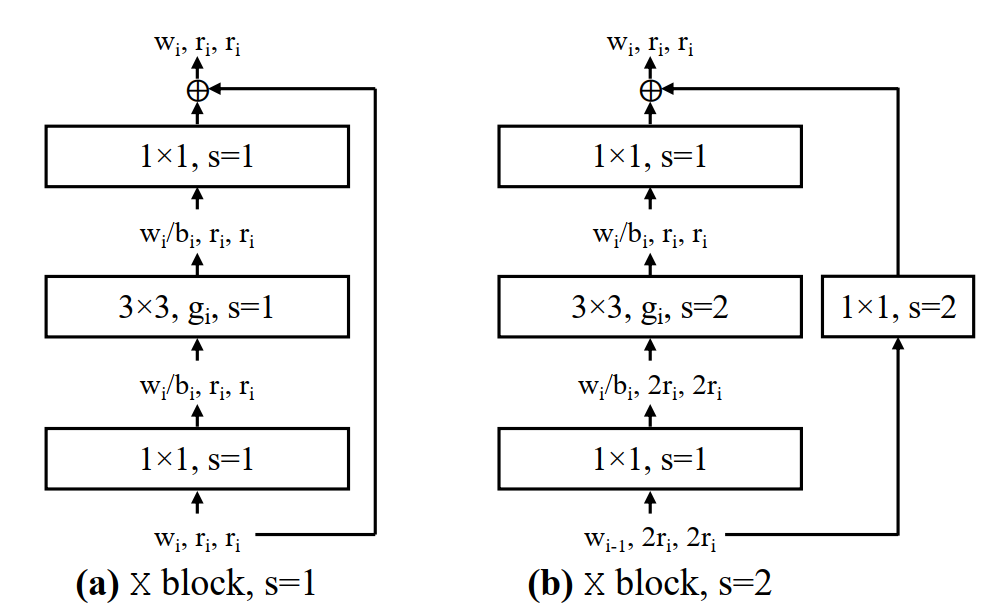
图 4. X 块基于具有组卷积的标准残差瓶颈块 [31]。
(a) 每个 X 块由一个 1×1 卷积、一个 3×3 组卷积和一个最终的 1×1 卷积组成,其中 1×1 卷积会改变通道宽度。conv后跟BN+ReLU。该块有 3 个参数:宽度 wi、瓶颈比 bi 和组宽度 gi。
(b) stride=2的版本。
shortcut捷径分支上当stride=1时不做任何处理,当stride=2时通过一个1x1的卷积(包括bn)进行下采样。
图中的r代表分辨率简单理解为特征矩阵的高、宽,当步距s等于1时,输入输出的r保持不变,当s等于2时,输出的r为输入的一半。
w代表特征矩阵的channel(注意当s=2时,输入的是
,输出的是
即channel会发生变化。
g代表分组卷积每个group的group width。
b代表bottleneck ratio即输出特征矩阵的channel缩减为输入特征矩阵channel的$\frac{1}{b} $
作者后来在实验中发现当b=1的时候效果最好。
论文中有RegNetX和RegNetY,两者的区别仅在于RegNetY在block中的Group Conv后接了个SE(Squeeze-and-Excitation)模块。
3.3 SE注意力机制
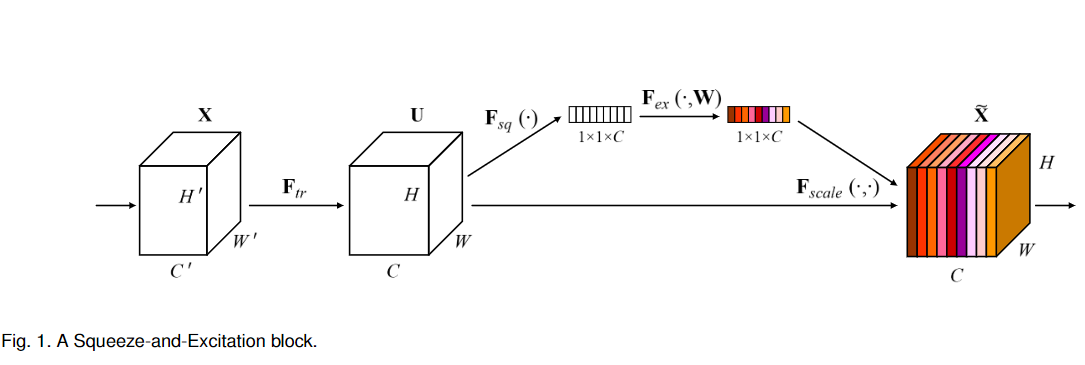
SENet的具体实现如下:
- 对输入进来的特征层进行全局平均池化。
- 然后进行两次全连接(这两个全连接可用1*1卷积代替),第一次全连接神经元个数较少,第二次全连接神经元个数和输入特征层个数相同。
- 在完成两次全连接之后,再取一次sigmoid讲值固定到0-1之间,此时我们获得了输入特征层每一个通道的权值(0-1之间)。
- 在获得这个权值之后,讲这个权值与原输入特征层相乘即可。
在RegNet中,全连接层1(FC1)的节点个数是等于输入该block的特征矩阵channel的四分之一(不是Group Conv输出特征矩阵channel的四分之一),并且激活函数是ReLU。全连接层2(FC2)的节点个数是等于Group Conv输出特征矩阵的channel,并且激活函数是Sigmoid。
4、RegNet代码复现:
模型的命名如下:
RegNet<block_type><flops>whereblock_type是其中之一(X, Y),flops表示亿次浮点运算。例如 RegNetY064 对应于具有 Y 块和 6.4 giga flop(64 亿次 flop)的 RegNet。
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.models import Model
4.1 模型参数配置
MODEL_CONFIGS = {
"x002": {
"depths": [1, 1, 4, 7],
"widths": [24, 56, 152, 368],
"group_width": 8,
"default_size": 224,
"block_type": "X"
},
"x004": {
"depths": [1, 2, 7, 12],
"widths": [32, 64, 160, 384],
"group_width": 16,
"default_size": 224,
"block_type": "X"
},
"x006": {
"depths": [1, 3, 5, 7],
"widths": [48, 96, 240, 528],
"group_width": 24,
"default_size": 224,
"block_type": "X"
},
"x008": {
"depths": [1, 3, 7, 5],
"widths": [64, 128, 288, 672],
"group_width": 16,
"default_size": 224,
"block_type": "X"
},
"x016": {
"depths": [2, 4, 10, 2],
"widths": [72, 168, 408, 912],
"group_width": 24,
"default_size": 224,
"block_type": "X"
},
"x032": {
"depths": [2, 6, 15, 2],
"widths": [96, 192, 432, 1008],
"group_width": 48,
"default_size": 224,
"block_type": "X"
},
"x040": {
"depths": [2, 5, 14, 2],
"widths": [80, 240, 560, 1360],
"group_width": 40,
"default_size": 224,
"block_type": "X"
},
"x064": {
"depths": [2, 4, 10, 1],
"widths": [168, 392, 784, 1624],
"group_width": 56,
"default_size": 224,
"block_type": "X"
},
"x080": {
"depths": [2, 5, 15, 1],
"widths": [80, 240, 720, 1920],
"group_width": 120,
"default_size": 224,
"block_type": "X"
},
"x120": {
"depths": [2, 5, 11, 1],
"widths": [224, 448, 896, 2240],
"group_width": 112,
"default_size": 224,
"block_type": "X"
},
"x160": {
"depths": [2, 6, 13, 1],
"widths": [256, 512, 896, 2048],
"group_width": 128,
"default_size": 224,
"block_type": "X"
},
"x320": {
"depths": [2, 7, 13, 1],
"widths": [336, 672, 1344, 2520],
"group_width": 168,
"default_size": 224,
"block_type": "X"
},
"y002": {
"depths": [1, 1, 4, 7],
"widths": [24, 56, 152, 368],
"group_width": 8,
"default_size": 224,
"block_type": "Y"
},
"y004": {
"depths": [1, 3, 6, 6],
"widths": [48, 104, 208, 440],
"group_width": 8,
"default_size": 224,
"block_type": "Y"
},
"y006": {
"depths": [1, 3, 7, 4],
"widths": [48, 112, 256, 608],
"group_width": 16,
"default_size": 224,
"block_type": "Y"
},
"y008": {
"depths": [1, 3, 8, 2],
"widths": [64, 128, 320, 768],
"group_width": 16,
"default_size": 224,
"block_type": "Y"
},
"y016": {
"depths": [2, 6, 17, 2],
"widths": [48, 120, 336, 888],
"group_width": 24,
"default_size": 224,
"block_type": "Y"
},
"y032": {
"depths": [2, 5, 13, 1],
"widths": [72, 216, 576, 1512],
"group_width": 24,
"default_size": 224,
"block_type": "Y"
},
"y040": {
"depths": [2, 6, 12, 2],
"widths": [128, 192, 512, 1088],
"group_width": 64,
"default_size": 224,
"block_type": "Y"
},
"y064": {
"depths": [2, 7, 14, 2],
"widths": [144, 288, 576, 1296],
"group_width": 72,
"default_size": 224,
"block_type": "Y"
},
"y080": {
"depths": [2, 4, 10, 1],
"widths": [168, 448, 896, 2016],
"group_width": 56,
"default_size": 224,
"block_type": "Y"
},
"y120": {
"depths": [2, 5, 11, 1],
"widths": [224, 448, 896, 2240],
"group_width": 112,
"default_size": 224,
"block_type": "Y"
},
"y160": {
"depths": [2, 4, 11, 1],
"widths": [224, 448, 1232, 3024],
"group_width": 112,
"default_size": 224,
"block_type": "Y"
},
"y320": {
"depths": [2, 5, 12, 1],
"widths": [232, 696, 1392, 3712],
"group_width": 232,
"default_size": 224,
"block_type": "Y"
},
}
这里只演示RegNetX002和RegNetY002。其他的无非就是改下参数而已。
4.2 PreStem预处理层
# 将输入重新缩放并归一化为[0,1]和ImageNet均值和std
def PreStem(x, name=None):
x = layers.experimental.preprocessing.Rescaling(1. / 255.)(x)
return x
这里我的tensorflow版本太低,高版本直接使用
layers.Rescaling()即可。
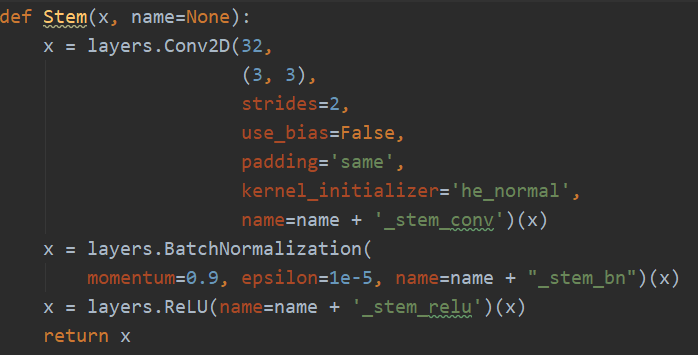
4.3 Stem
论文中的stem(stride=2 3x3卷积+w0 = 32 output channels)
stem就是一个普通的卷积层(默认包含bn以及relu),卷积核大小为3x3,步距为2,卷积核个数为32。
def Stem(x, name=None):
x = layers.Conv2D(32,
(3, 3),
strides=2,
use_bias=False,
padding='same',
kernel_initializer='he_normal',
name=name + '_stem_conv')(x)
x = layers.BatchNormalization(
momentum=0.9, epsilon=1e-5, name=name + "_stem_bn")(x)
x = layers.ReLU(name=name + '_stem_relu')(x)
return x
4.4 Se注意力机制模块
def SqueezeAndExciteBlock(inputs, filters_in, se_filters, name=None):
# 获得通道数
channel=inputs.shape[-1]
x = layers.GlobalAveragePooling2D(name=name + '_squeeze_and_excite_gap')(inputs)
x=layers.Reshape((1,1,channel))(x)
# 两个全连接层(目前看到的所有源码都是使用两个1x1卷积层代替)
x = layers.Conv2D(filters=se_filters,
kernel_size=(1, 1),
activation='relu',
kernel_initializer='he_normal',
name=name + '_squeeze_and_excite_squeeze')(x)
x = layers.Conv2D(filters=filters_in,
kernel_size=(1, 1),
activation='sigmoid',
kernel_initializer='he_normal',
name=name + '_squeeze_and_excite')(x)
x = layers.multiply([x, inputs])
return x
关于通道的缩放比在Block写着,ratio=0.25
4.5 XBlock实现
XBlock实现:1x1卷积+3x3分组卷积+1x1卷积(conv后跟BN+ReLU)
def XBlock(inputs, filters_in, filters_out, group_width, stride=1, name=None):
# declare layers
groups = filters_out // group_width
# 当stide=2的时候,残差边需要使用1x1卷积降维处理保持shape一致
if stride != 1:
skip = layers.Conv2D(
filters_out,
(1, 1),
strides=stride,
use_bias=False,
kernel_initializer='he_normal',
name=name + '_skip_1x1')(inputs)
skip = layers.BatchNormalization(
momentum=0.9, epsilon=1e-5, name=name + "_skip_bn")(skip)
else:
skip = inputs
# build block
# conv_1x1_1
x = layers.Conv2D(
filters_out,
(1, 1),
use_bias=False,
kernel_initializer='he_normal',
name=name + '_conv_1x1_1')(inputs)
x = layers.BatchNormalization(
momentum=0.9, epsilon=1e-5, name=name + "_conv_1x1_1_bn")(x)
x = layers.ReLU(name=name + "_conv_1x1_1_relu")(x)
# group conv_3x3
x = layers.Conv2D(
filters_out,
(3, 3),
use_bias=False,
strides=stride,
groups=groups,
padding='same',
kernel_initializer='he_normal',
name=name + '_conv_3x3')(x)
x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name=name + "_conv_3x3_bn")(x)
x = layers.ReLU(name=name + "_conv_3x3_relu")(x)
# conv_1x1_2
x = layers.Conv2D(
filters_out, (1, 1),
use_bias=False,
kernel_initializer="he_normal",
name=name + "_conv_1x1_2")(x)
x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name=name + "_conv_1x1_2_bn")(x)
x = layers.ReLU(name=name + "_exit_relu")(x + skip)
return x
4.6 YBlock实现
YBlock实现:1x1卷积+3x3分组卷积+SE注意力机制+1x1卷积(conv后跟BN+ReLU)
def YBlock(inputs,
filters_in,
filters_out,
group_width,
stride=1,
squeeze_excite_ratio=0.25,
name=None):
groups = filters_out // group_width
se_filters = int(filters_in * squeeze_excite_ratio)
if stride != 1:
skip = layers.Conv2D(filters_out,
(1, 1),
strides=stride,
use_bias=False,
kernel_initializer="he_normal",
name=name + "_skip_1x1")(inputs)
skip = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name=name + "_skip_bn")(skip)
else:
skip = inputs
# Build Block
# conv_1x1_1
x = layers.Conv2D(filters_out, (1, 1),
use_bias=False,
kernel_initializer="he_normal",
name=name + "_conv_1x1_1")(inputs)
x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name=name + "_conv_1x1_1_bn")(x)
x = layers.ReLU(name=name + "_conv_1x1_1_relu")(x)
# conv_3x3
x = layers.Conv2D(
filters_out, (3, 3),
use_bias=False,
strides=stride,
groups=groups,
padding="same",
kernel_initializer="he_normal",
name=name + "_conv_3x3")(x)
x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name=name + "_conv_3x3_bn")(x)
x = layers.ReLU(name=name + "_conv_3x3_relu")(x)
# SE注意力机制模块
x = SqueezeAndExciteBlock(x, filters_out, se_filters, name=name)
# conv_1x1_2
x = layers.Conv2D(filters_out,
(1, 1),
use_bias=False,
kernel_initializer="he_normal",
name=name + "_conv_1x1_2")(x)
x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name=name + "_conv_1x1_2_bn")(x)
x = layers.ReLU(name=name + "_exit_relu")(x + skip)
return x
4.7 Block块的堆叠
def Stage(inputs,
block_type, # 必须是X、Y、Z之一
depth, # stage深度,要使用的块数
group_width, # 本stage所有块的group宽度
filters_in, #
filters_out,
name=None): # 名称前缀
x = inputs
if block_type == "X":
# 论文原话:Stage的第一个block的步长为2
x = XBlock(
x,
filters_in,
filters_out,
group_width,
stride=2,
name=f"{name}_XBlock_0")
for i in range(1, depth):
x = XBlock(x, filters_out, filters_out, group_width, name=f"{name}_XBlock_{i}")
elif block_type== "Y":
x=YBlock(x,filters_in,filters_out,group_width,stride=2,name=name+'_YBlock_0')
for i in range(1,depth):
x=YBlock(x,filters_out,filters_out,group_width,name=f"{name}_YBlock_{i}")
# TODO ZBlock
return x
这里还有一个ZBlock没有实现,那个是另一篇论文的,我看完再发。
注意:每个Stage的第一个Block的stride=2
4.8 分类头部分(Head)
def Head(x, num_classes=1000, name=None):
x = layers.GlobalAveragePooling2D(name=name + '_head_gap')(x)
x = layers.Dense(num_classes, name=name + 'head_dense')(x)
return x
4.9 RegNet骨干搭建
def RegNet(depths, # 每个stage的深度
widths, # 块宽度(输出通道数)
group_width, # 每组中要使用的通道数
block_type, # "X","Y","Z"之一
default_size, # 默认输入图像大小
model_name='regnet', # 模型的可选名称
include_preprocessing=True, # 是否包含预处理
include_top=True, # 是否包含分类头
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000, # 可选的类数量
classifier_activation='softmax'): # 分类器激活
img_input = layers.Input(shape=input_shape)
inputs = img_input
x = inputs
if include_preprocessing:
x = PreStem(x, name=model_name)
x = Stem(x, name=model_name)
in_channels = 32 # Output from Stem
for num_stage in range(4):
depth = depths[num_stage]
out_channels = widths[num_stage]
x = Stage(x,
block_type,
depth,
group_width,
in_channels,
out_channels,
name=model_name + '_Stage_' + str(num_stage))
in_channels = out_channels
if include_top:
x = Head(x, num_classes=classes, name='head')
else:
if pooling == 'avg':
x = layers.GlobalAveragePooling2D()(x)
elif pooling == 'max':
x = layers.GlobalMaxPooling2D()(x)
model = Model(inputs=inputs, outputs=x, name=model_name)
return model
for num_stage in range(4),这里之所以遍历四次,是因为原论文中body部分只有4个stage,看原论文图3你就明白了。
4.10 RegNetX002模型
def RegNetX002(model_name='regnetx002',
include_top=True,
include_preprocessing=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
classifier_activation='softmax'):
return RegNet(
MODEL_CONFIGS['x002']['depths'],
MODEL_CONFIGS['x002']['widths'],
MODEL_CONFIGS['x002']['group_width'],
MODEL_CONFIGS['x002']['block_type'],
MODEL_CONFIGS['x002']['default_size'],
model_name=model_name,
include_top=include_top,
include_preprocessing=include_preprocessing,
weights=weights,
input_tensor=input_tensor,
input_shape=input_shape,
pooling=pooling,
classes=classes,
classifier_activation=classifier_activation
)
if __name__ == '__main__':
model = RegNetX002(input_shape=(224, 224, 3))
model.summary()
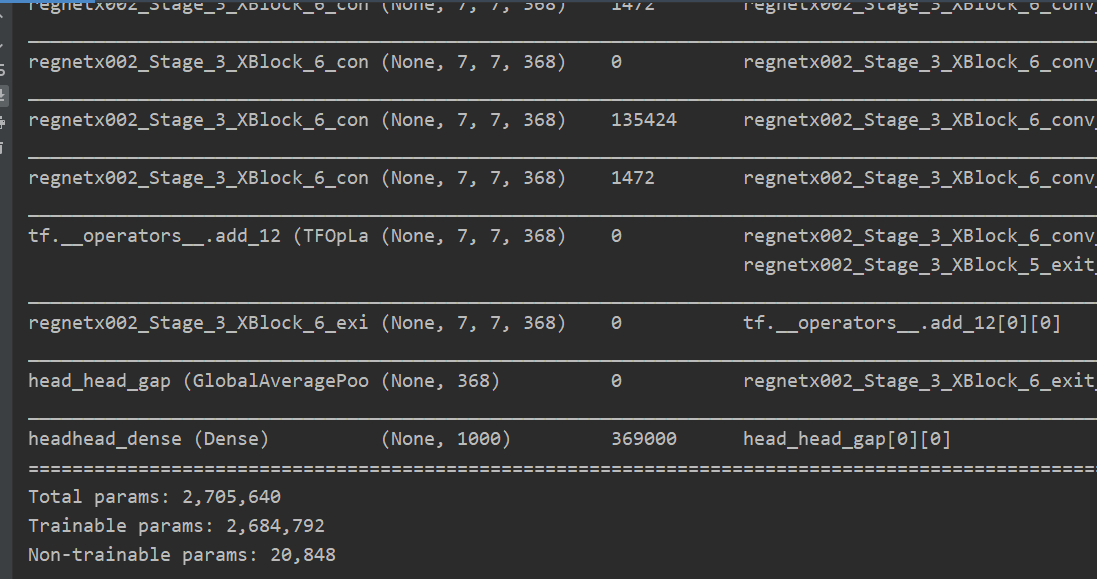
图太长了,只能截一部份
4.11 RegNetY002模型
def RegNetY002(model_name="regnety002",
include_top=True,
include_preprocessing=True,
weights="imagenet",
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
classifier_activation="softmax"):
return RegNet(
MODEL_CONFIGS["y002"]["depths"],
MODEL_CONFIGS["y002"]["widths"],
MODEL_CONFIGS["y002"]["group_width"],
MODEL_CONFIGS["y002"]["block_type"],
MODEL_CONFIGS["y002"]["default_size"],
model_name=model_name,
include_top=include_top,
include_preprocessing=include_preprocessing,
weights=weights,
input_tensor=input_tensor,
input_shape=input_shape,
pooling=pooling,
classes=classes,
classifier_activation=classifier_activation)

到此,RegNetX与RegNetY模型就搭建完了。
Reference
Designing Network Design Spaces
https://www.tensorflow.org/api_docs/python/tf/keras/applications/regnet/RegNetX002
https://github.com/keras-team/keras/blob/v2.9.0/keras/applications/regnet.py#L1245-L1270

- 点赞
- 收藏
- 关注作者
评论(0)