【论文导读】- E-LSTM-D: A Deep Learning Framework for Dynamic Network

@[TOC]
论文信息
E-LSTM-D: A Deep Learning Framework for Dynamic Network Link Prediction

原文链接:E-LSTM-D: A Deep Learning Framework for Dynamic Network Link Prediction:https://ieeexplore.ieee.org/abstract/document/8809903
摘要
Predicting the potential relations between nodes in networks, known as link prediction, has long been a challenge in network science. However, most studies just focused on link prediction of static network, while real-world networks always evolve over time with the occurrence and vanishing of nodes and links. Dynamic network link prediction (DNLP) thus has been attracting more and more attention since it can better capture the evolution nature of networks, but still most algorithms fail to achieve satisfied prediction accuracy. Motivated by the excellent performance of long short-term memory (LSTM) in processing time series, in this article, we propose a novel encoder-LSTM-decoder (E-LSTM-D) deep learning model to predict dynamic links end to end. It could handle long-term prediction problems, and suits the networks of different scales with fine-tuned structure. To the best of our knowledge, it is the first time that LSTM, together with an encoder-decoder architecture, is applied to link prediction in dynamic networks. This new model is able to automatically learn structural and temporal features in a unified framework, which can predict the links that never appear in the network before. The extensive experiments show that our E-LSTM-D model significantly outperforms newly proposed DNLP methods and obtain the state-of-the-art results.
预测网络中节点之间的潜在关系,即链路预测,长期以来一直是网络科学中的一个挑战。然而,大多数研究只关注静态网络的链路预测,而现实世界中的网络总是随着节点和链路的出现和消失而不断演化。动态网络链路预测因其能更好地捕捉网络的演化特性而受到越来越多的关注,但大多数算法仍无法达到令人满意的预测精度。鉴于长短时记忆网络LSTM 在处理时间序列方面的优异性能,本文提出了一种新的编码器- LSTM -解码器( E-LSTM-D)深度学习模型来预测端到端的动态链接。它可以处理长期预测问题,并适用于具有微调结构的不同规模的网络。据我们所知,这是第一次将LSTM与编码器-解码器架构一起应用于动态网络中的链路预测。这种新的模型能够在一个统一的框架中自动学习结构和时间特征,可以预测以前从未出现在网络中的链接。大量实验表明,我们的E - LSTM - D模型明显优于新提出的DNLP方法,并获得了最新的结果。
论文贡献
- 提出了一个通用的端到端深度学习框架,即E - LSTM - D,用于动态网络中的链路预测,其中编码器-解码器架构自动学习网络的表示,而堆叠的LSTM模块增强了学习时间特征的能力。
- 新提出的E - LSTM - D模型能够胜任长期预测任务,性能仅有轻微下降;它适用于不同规模的网络,通过精细调整模型结构,即改变不同层的单元数;此外,它可以预测即将出现或消失的链接,而现有的大多数方法只关注前者。
- 定义了一个新的度量指标- -错误率,来衡量DNLP的性能,这是对ROC曲线下面积( AUC )的一个很好的补充,从而使评估更加全面。
- 进行了大量的实验,将E - LSTM - D模型与五种基准方法在各种度量指标上进行了比较。它表明,我们的模型优于其他模型,并获得了最先进的结果。
问题定义
动态网络
给定一个图序列{ G1,…,GT },其中Gk = ( V、Ek)表示动态网络的第k个快照。设V是所有顶点的集合,Ek∈V × V是固定时间跨度[ tk-1 , tk]内的时态链接.用Ak表示Gk的邻接矩阵,元素为ak;如果存在从vi到vj的有向链接,则ak;i,j = 1;否则为0。
在静态网络中,链路预测的目的是根据观测到的边的分布,找到实际存在的边。类似地,动态网络中的链路预测充分利用从以前的图中提取的信息来揭示底层网络的演化模式,从而预测网络的未来状态。由于邻接矩阵能够精确地描述网络的结构,因此将其作为预测模型的输入和输出是比较理想的。由于动态网络的连续快照之间的强关系,我们可以根据Gt - 1来推断Gt。然而,Gt中包含的信息可能太少,无法进行精确的推断。事实上,在网络演化过程中,不仅是结构本身,结构随时间的变化同样重要。因此,我们倾向于使用长度为N的序列,即{ Gt-N,…,Gt-1 }来预测Gt。
动态网络链接预测
给定一个长度为N的图序列S = { Gt-N,…,Gt-1 },DNLP旨在学习一个将输入序列S映射到Gt的函数。
动态网络的结构是随时间演化的。如下图所示,一些链接可能出现而另一些链接可能消失,这可以通过邻接矩阵随时间的变化来反映。其目标是找到网络中最有可能在下一时间跨度出现或消失的链接。从数学上讲,它也可以理解为寻找一个矩阵的最优化问题,该矩阵的元素要么为0,要么为1。
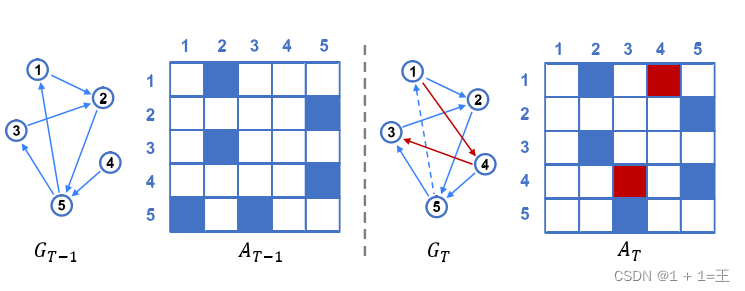
E-LSTM-D 框架
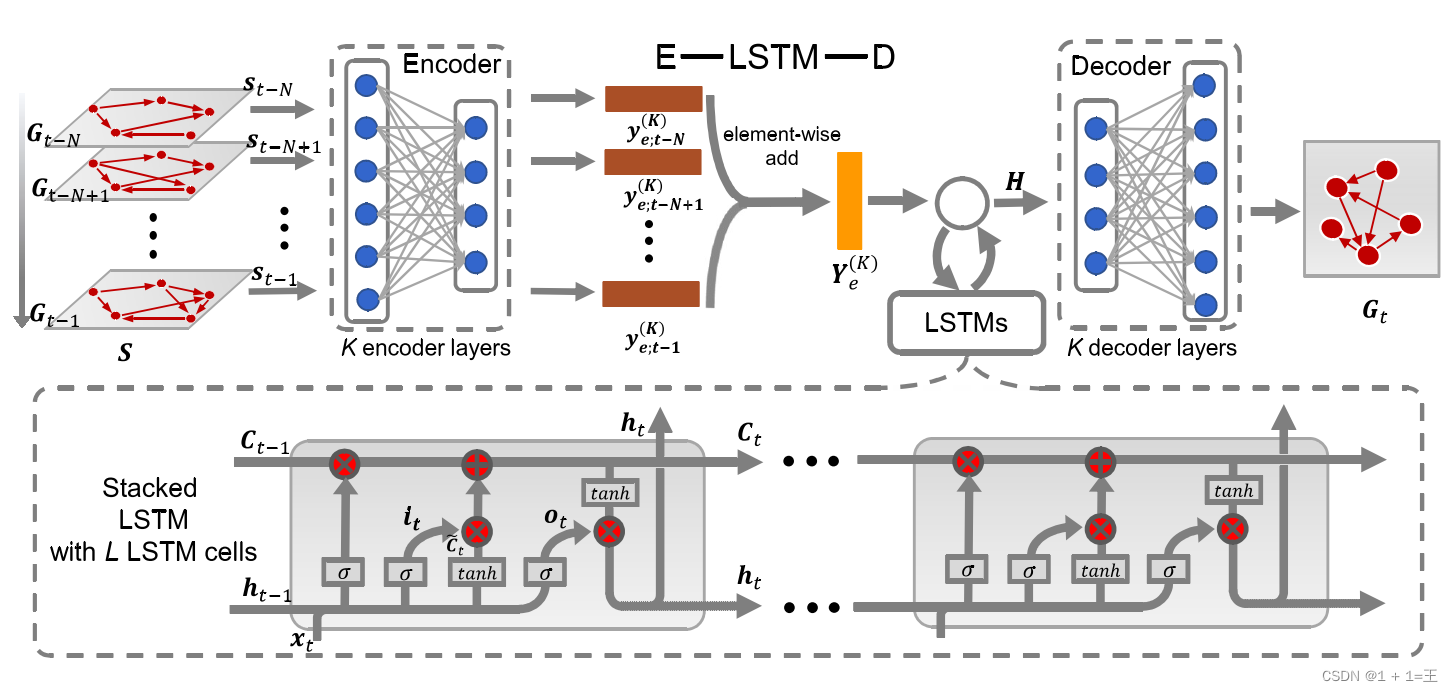
E-LSTM-L由编码器-解码器架构和堆叠的LSTM组成。编码器被放置在模型的入口处学习高度非线性的网络结构,解码器将提取的特征转换回原始空间。这样的编码器-解码器架构能够处理空间非线性和稀疏性,而编码器和解码器之间的堆叠LSTM可以学习时间依赖。因此,设计良好的端到端模型可以同时学习结构和时间特征,并以统一的方式进行链接预测。
Encoder–Decoder结构
1. 编码器(Encoder)
自动编码器可以以无监督的方式有效地学习数据的表示。受此启发,我们在模型的入口处放置一个编码器来捕捉高度非线性的网络结构,并在末端放置一个图重构器将潜在的特征转化为固定形状的矩阵。然而,在这里,整个过程是有监督的,这与自动编码器不同,因为我们已经标记了数据( At )来指导解码器构建能够更好地拟合目标分布的矩阵。特别是,由多个非线性感知组成的编码器将高维图形数据投影到一个相对较低维的向量空间。因此,得到的向量可以表征网络中顶点的局部结构。这个过程可以描述为:
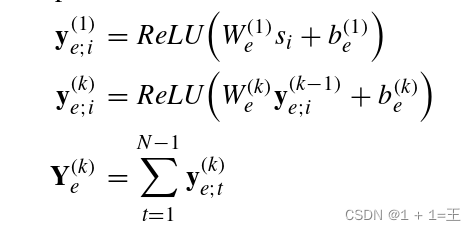
其中,si表示输入序列S中的第i个图。W(k) e 和b(k) e 分别表示第k个编码器层的权重和偏置,Y ( k ) e为第k个编码器层的输出。
对于一个输入序列,每个编码器层分别对每一个项进行处理,然后通过逐元素相加的方式将所有激活串联起来。
2. 解码器(Decoder)
具有编码器镜像结构的解码器接收潜在特征,并在At的监督下将其映射到重建空间,表示为:
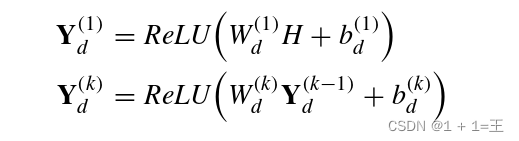 其中H由堆叠的LSTM生成,表示目标快照的特征,而不是编码器中使用的所有先前快照的特征序列。W ( k ) d和b ( k ) d分别表示解码器中第k个的权重和偏置,Y ( k )表示第k个解码器层的输出。
其中H由堆叠的LSTM生成,表示目标快照的特征,而不是编码器中使用的所有先前快照的特征序列。W ( k ) d和b ( k ) d分别表示解码器中第k个的权重和偏置,Y ( k )表示第k个解码器层的输出。
堆叠的LSTM
虽然编码器-解码器结构可以处理高非线性,但它不能捕获时变特性。LSTM作为一种特殊的RNN,可以学习长期依赖关系,并在这里被引入来解决这个问题。一个LSTM由三个门组成,即遗忘门、输入门和输出门。
- forget gate
第一步是决定哪些信息将从先前的细胞状态中丢弃。操作由忘记门执行,其定义为:

- input gate
然后输入门决定哪些新信息应该添加到单元状态,操作定义为:
- output gate
利用遗忘门和输入门的优点,LSTM单元不仅可以存储长时记忆,而且可以过滤掉无用的信息。LSTM单元的输出基于Ct,由输出门控制,输出门决定应该输出什么信息,该过程被描述为:
单个LSTM单元能够学习时间依赖关系,但是链状LSTM模块,即堆叠LSTM,更适合处理时间序列数据。堆叠LSTM由多个LSTM单元组成,这些单元按时间顺序将信号作为输入。将堆叠的LSTM放在编码器和解码器之间,以学习网络演化的模式。在接收到t时刻提取的特征后,LSTM模块将它们转换成ht,然后在下一个训练步骤将ht反馈给模型。
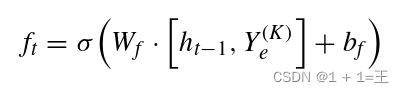
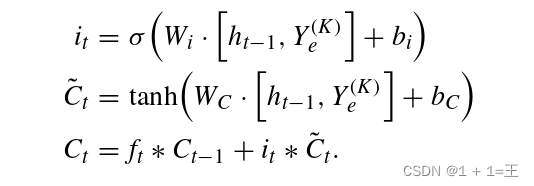
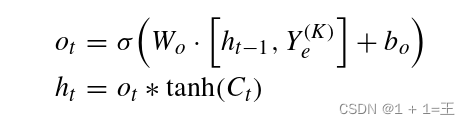
编码器可以降低每个图形的维度,从而以合理的成本保持堆叠LSTM的计算。而擅长处理时序性和顺序性数据的堆叠LSTM依次对编码器进行补充。

- 点赞
- 收藏
- 关注作者
评论(0)