【图神经网络】 - GNN的几个模型及论文解析(NN4G、GAT、GCN)

@[TOC]
图神经网络
图神经网络(Graph Neural Network,GNN)是指使用神经网络来学习图结构数据,提取和发掘图结构数据中的特征和模式,满足聚类、分类、预测、分割、生成等图学习任务需求的算法总称。
Neural Network for Graphs(NN4G)
论文信息
Neural Network for Graphs: A ContextualConstructive Approach

摘要
This paper presents a new approach for learning in structured domains (SDs) using a constructive neural network for graphs (NN4G). The new model allows the extension of the input domain for supervised neural networks to a general class of graphs including both acyclic/cyclic, directed/undirected labeled graphs. In particular, the model can realize adaptive contextual transductions, learning the mapping from graphs for both classification and regression tasks. In contrast to previous neural networks for structures that had a recursive dynamics, NN4G is based on a constructive feedforward architecture with state variables that uses neurons with no feedback connections. The neurons are applied to the input graphs by a general traversal process that relaxes the constraints of previous approaches derived by the causality assumption over hierarchical input data. Moreover, the incremental approach eliminates the need to introduce cyclic dependencies in the definition of the system state variables. In the traversal process, the NN4G units exploit (local) contextual information of the graphs vertices. In spite of the simplicity of the approach, we show that, through the compositionality of the contextual information developed by the learning, the model can deal with contextual information that is incrementally extended according to the graphs topology. The effectiveness and the generality of the new approach are investigated by analyzing its theoretical properties and providing experimental results.
本文提出了一种利用构造性神经网络( NN4G )学习结构化领域( SD )的新方法。新模型允许将有监督神经网络的输入域扩展到包括无环/循环、有向/无向标记图的一般图类。特别地,该模型可以实现自适应的上下文转换,从图中学习分类和回归任务的映射。与以往针对具有递归动态结构的神经网络不同,NN4G基于具有状态变量的构造性前馈架构,使用无反馈连接的神经元。通过一个通用的遍历过程将神经元应用到输入图中,该过程放松了先前基于因果关系假设分层输入数据得到的方法的约束。此外,增量方法消除了在系统状态变量的定义中引入循环依赖关系的需要。在遍历过程中,NN4Gunits利用图顶点的(局部)上下文信息。尽管该方法简单,但我们表明,通过学习开发的上下文信息的组合性,该模型可以处理根据图的拓扑结构增量扩展的上下文信息。通过分析其理论性质和提供实验结果,研究了新方法的有效性和通用性。
NN4G模型思想
对于一个输入图,如下图所示:
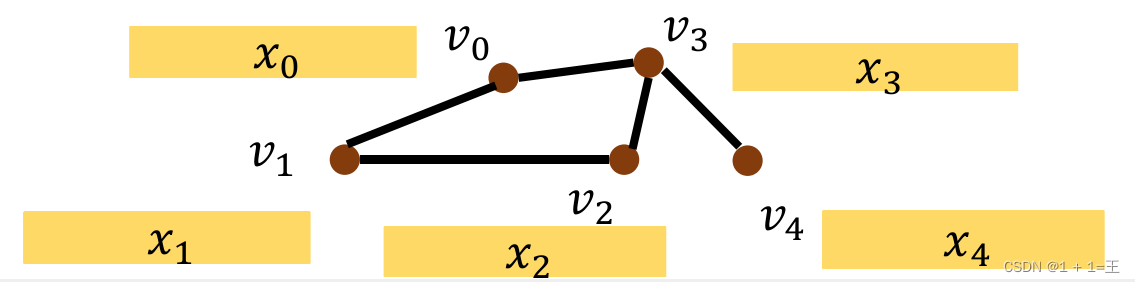
其中,v~i~表示节点,x~i~表示每个节点对应的特征信息。
然后通过隐藏层进行特征学习并更新每个节点的特征信息,更新过程如下:
对于第一个隐藏层:
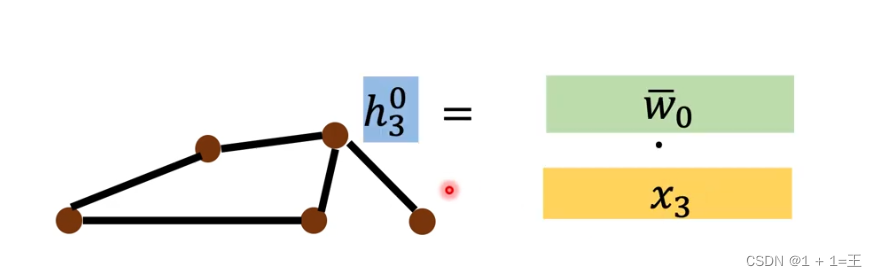
将节点的特征信息更新为 ,其中layer表示当前是第几层,node表示对应哪个节点。
,其中layer表示当前是第几层,node表示对应哪个节点。
h = w * x,
w为一个权重,x为输入时节点的特征信息。
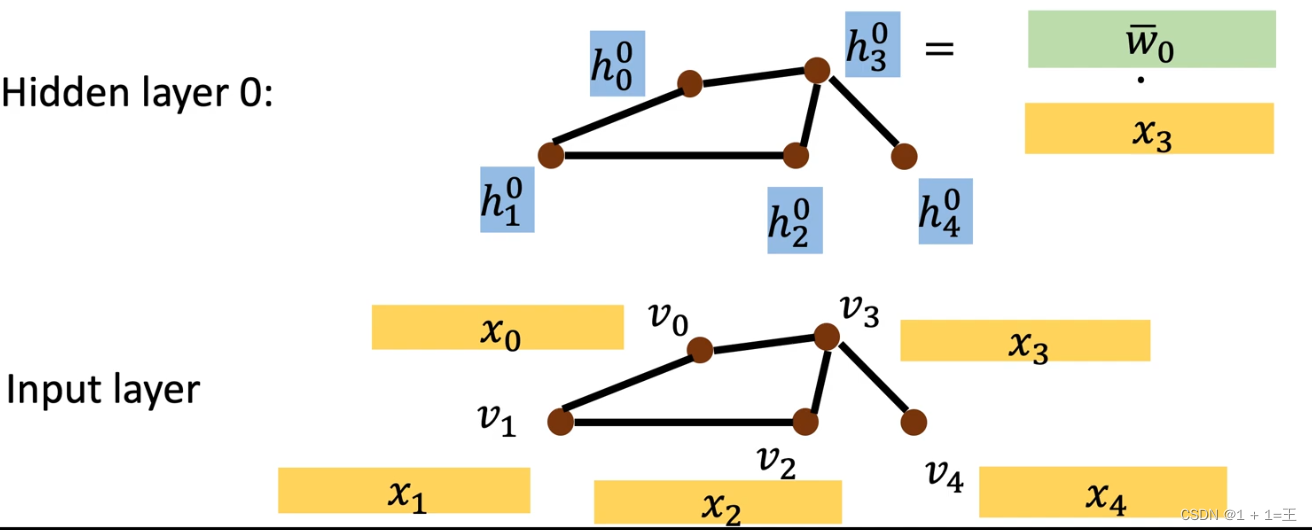
然后对每个节点都做同样的更新,就得到:
对于其他隐藏层,在第一个隐藏层的基础上再做如下更新:
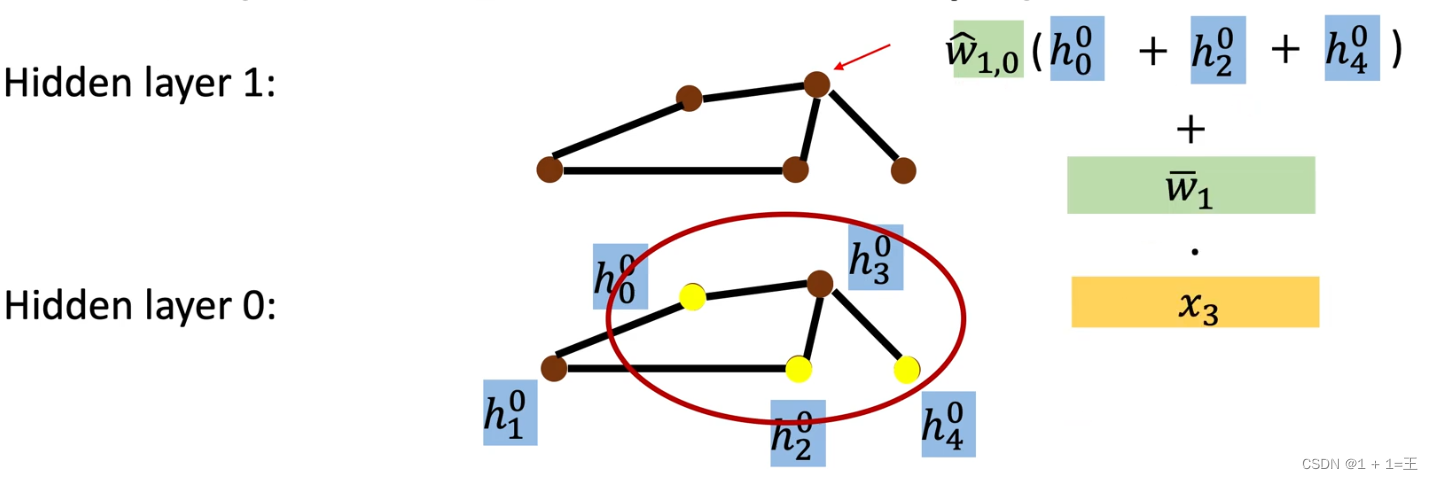
即,先将节点邻居的特征加起来,乘上一个权重W,然后再加上节点本身的特征。
还是对每个节点做同样的更新就可以得到一个隐藏层的表示。
在叠加了多层之后,就可以对节点特征信息进行Readout,来代表整个图的特征信息,做法如下:
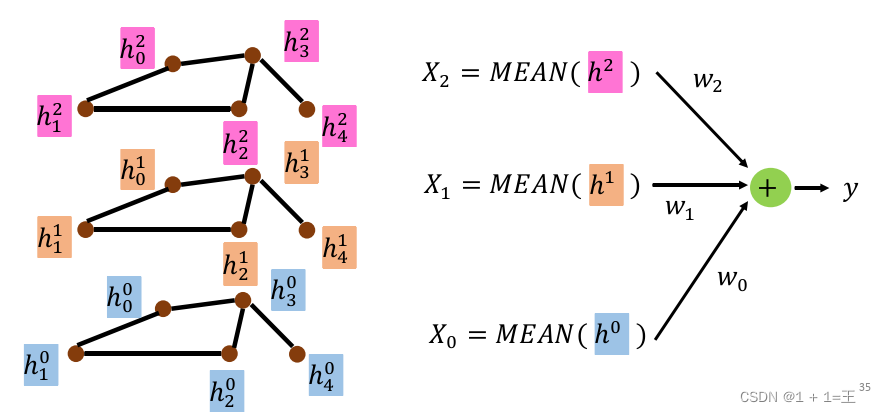
即,将每个节点对应每一层的特征信息相加求平均值,再乘上一个权重,并相加,就得到最后的结果y。
Graph Attention Network(GAT)
论文信息
GRAPH ATTENTION NETWORKS

摘要
We present graph attention networks (GATs), novel neural network architectures that operate on graph-structured data, leveraging masked self-attentional layers to address the short comings of prior methods based on graph convolutions or their approximations. By stacking layers in which nodes are able to attend over their neighborhoods’ features, we enable (implicitly) specifying different weights todifferent nodes in a neighborhood, without requiring any kind of costly matrix operation (such as inversion) or depending on knowing the graph structure upfront.In this way, we address several key challenges of spectral-based graph neural net-works simultaneously, and make our model readily applicable to inductive as wellas transductive problems. Our GAT models have achieved or matched state-of-the-art results across four established transductive and inductive graph benchmarks:the Cora, Citeseer and Pubmed citation network datasets, as well as a protein-protein interaction dataset (wherein test graphs remain unseen during training)
我们提出了图注意力网络( Graph Attention Networks,GATs ),它是一种新颖的神经网络架构,可以在图结构数据上运行,利用掩蔽的自注意力层来解决基于图卷积或其近似的先验方法的缺点。通过将节点能够处理其邻域特性的层进行堆叠,我们可以(隐式地)为邻域中的不同节点指定不同的权重,而不需要任何昂贵的矩阵运算(例如反转),也不需要预先知道图结构。通过这种方式,我们同时解决了基于谱的图神经网络的几个关键挑战,并使我们的模型易于适用于归纳和转导问题。我们的GAT模型在四个公认的直推式和归纳式图形基准上取得或匹配了最先进的结果:Cora、Citeseer和Pubmed引文网络数据集,以及蛋白质-蛋白质相互作用数据集。
GAT模型思想
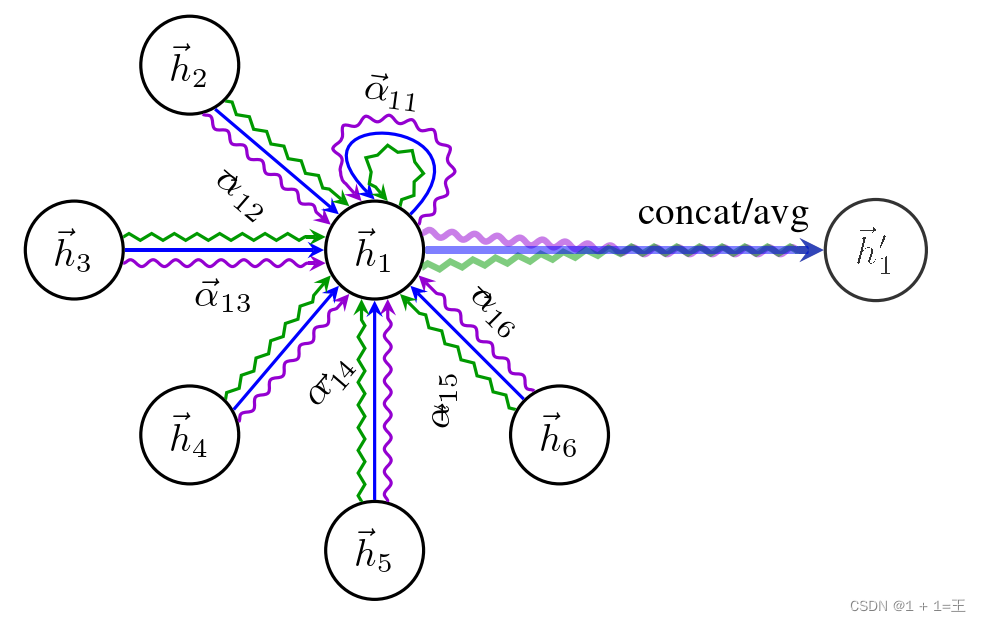
对于输入图用h表示每个节点的特征信息:

其中,N为节点的数量。
经过一个隐藏层之后,得到一层新的节点特征:
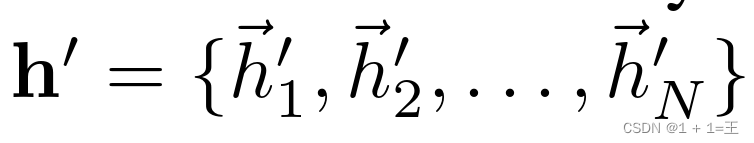
特征信息更新过程如下:
- 为了获得足够的表达能力,将输入特征通过至少一个可学习的线性变换,转换为更高层次的特征W~i~。
- 通过一个注意力机制,计算得到一个注意力系数:

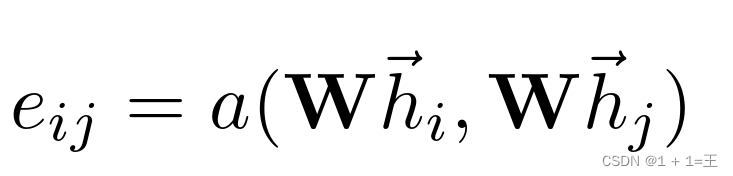
e~ij~ 表示节点j 的特征对节点i 的重要性。a表示注意力机制,是一个单层前馈神经网络。
-
对节点的每一个邻居计算一个注意力系数(邻居节点对该节点的重要性),然后使用softmax进行归一化处理。
N~i~ 表示节点i的邻居节点。 -
得到归一化的注意力系数之后,再通过对邻接节点特征的线性组合经过一个非线性激活函数来更新节点自身的特征作为输出:
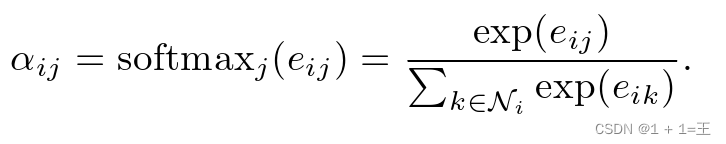 N~i~ 表示节点i的邻居节点。
N~i~ 表示节点i的邻居节点。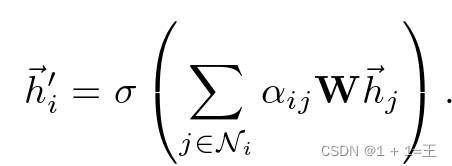
Graph Convolutional Networks(GCN)
论文信息

摘要
We present a scalable approach for semi-supervised learning on graph-structured data that is based on an efficient variant of convolutional neural networks which operate directly on graphs. We motivate the choice of our convolutional archi-tecture via a localized first-order approximation of spectral graph convolutions.Our model scales linearly in the number of graph edges and learns hidden layer representations that encode both local graph structure and features of nodes. Ina number of experiments on citation networks and on a knowledge graph dataset we demonstrate that our approach outperforms related methods by a significant margin.
我们提出了一种可扩展的基于图结构数据的半监督学习方法,该方法基于直接在图上运行的卷积神经网络的有效变体。我们通过谱图卷积的局部一阶近似来激励我们的卷积架构的选择。我们的模型以图边数线性扩展,并学习隐藏层表示,这些表示同时编码局部图结构和节点特征。在引文网络和知识图谱数据集上的大量实验表明,我们的方法优于相关方法。
GCN模型思想
对于一个输入图,他有N个节点,每个节点的特征组成一个特征矩阵X,节点与节点之间的关系组成一个邻接矩阵A,X和A即为模型的输入。
GCN是一个神经网络层,它具有以下逐层传播规则:
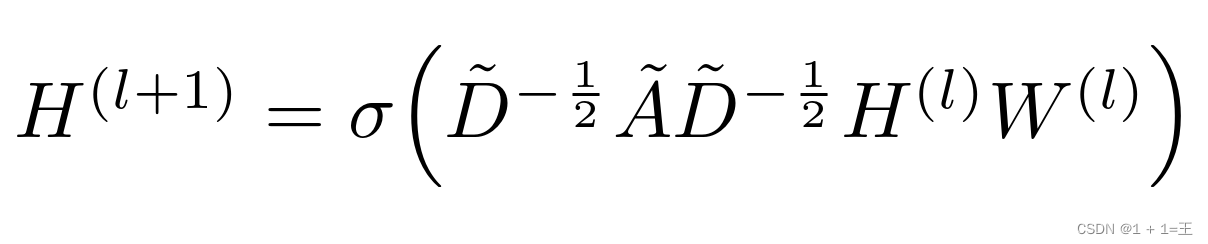
其中,
- ˜A = A + I,A为输入图的领接矩阵,I为单位矩阵。
- ˜D为˜A的度矩阵,˜D~ii~ = ∑~j~ ˜A~ij~
- H是每一层的特征,对于输入层H = X
- σ是非线性激活函数
- W为特定层的可训练权重矩阵
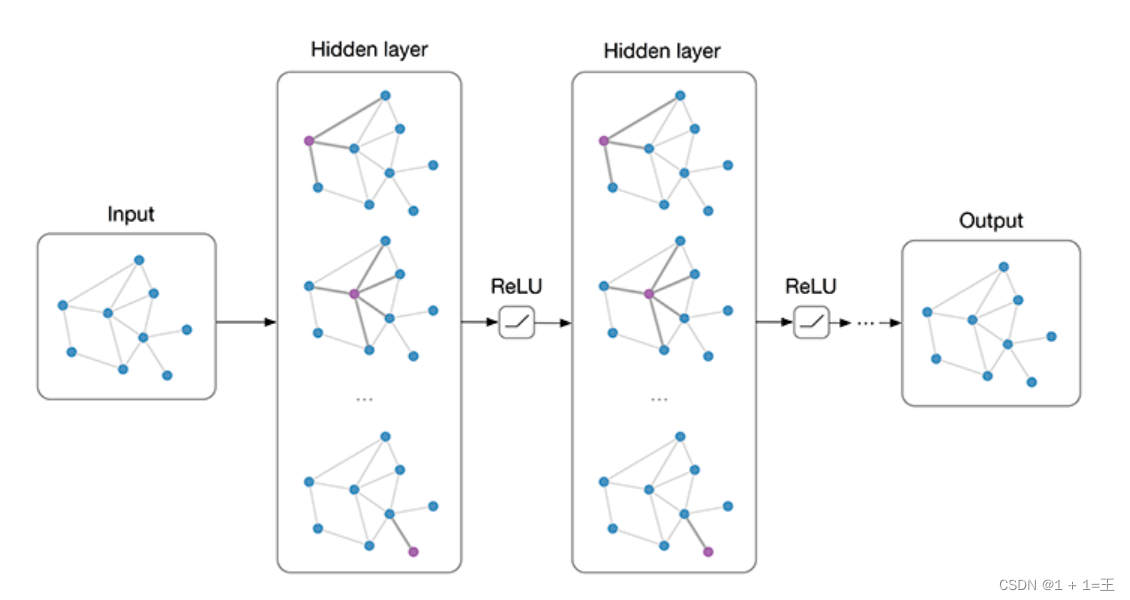
经过多层GCN逐层传播,输入图的特征矩阵由X变为Z,但邻接矩阵A始终保持共享,如下图:
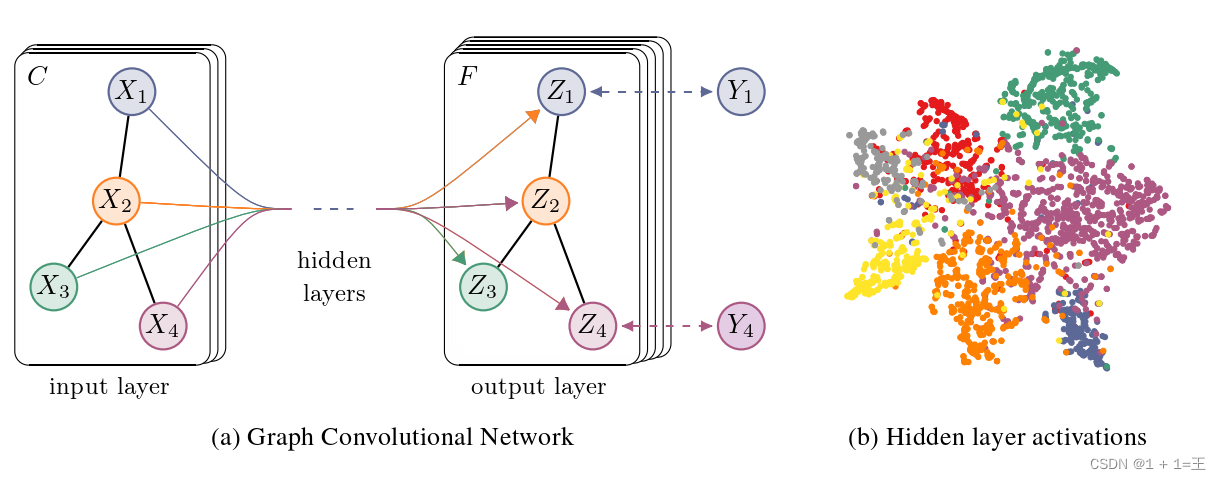
然后,根据带有标签的节点计算cross-entropy损失:
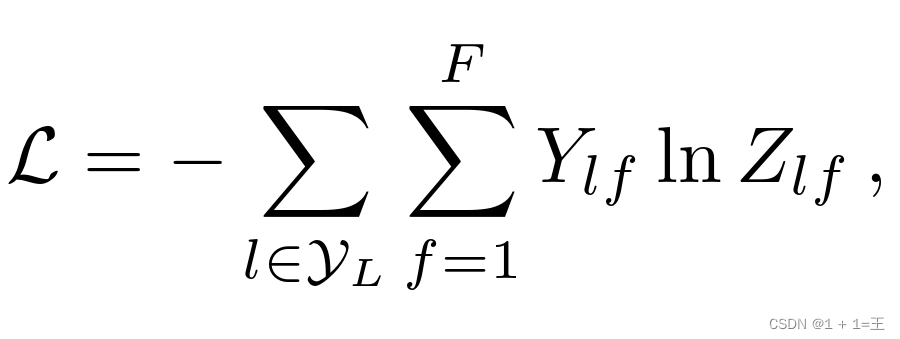
其中,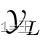 表示具有标签的节点索引的集合。
表示具有标签的节点索引的集合。
并采用梯度下降法训练神经网络权值W 。

- 点赞
- 收藏
- 关注作者
评论(0)