Redis高可用集群主流架构方案分析


redis在互联网大数据平台有着广泛的应用,主要被用来缓存热点数据,避免海量请求压垮数据库,同时可以提升服务节点的响应速度和并发量。随着数据量的增多,由于redis是占用单台物理机或虚机的内存,内存资源是有限的,要实现弹性扩容缩容,就需要用到redis集群。从单节点到集群经历了以下演变的过程:
**(1) 单实例**
redis以单实例方式运行,特点是简单,但是受限于单实例物理内存,而且有单点故障,如何避免数据丢失呢,redis提供了持久化机制。
**(2) redis开启持久化**
redis支持RDB和AOF两种持久化方式:RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot);AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。 AOF 文件中的命令全部以 Redis 协议的格式来保存,新命令会被追加到文件的末尾。 Redis 还可以在后台对 AOF 文件进行重写(rewrite),使得 AOF 文件的体积不会超出保存数据集状态所需的实际大小。Redis 还可以同时使用 AOF 持久化和 RDB 持久化,RDB方式比较消耗磁盘空间而AOF方式会带来大量的IO操作并且恢复速度更慢。
**(3) 主备模式(一主一备或一主多备)**
类似单实例模式,不同之处在于主节点有备用节点,备用节点会开启一个异步线程同步主节点数据(不保证强一致性,在请求量比较大的情况下会有短暂的时间窗口存在主备数据不一致的情况),主节点磬机后,备用节点升级为主节点对外提供服务(并且数据是热备,避免了持久化方式中缓存数据恢复的过程,主备切换后不会出现大量的缓存穿透现象)。
**(4) 读写分离**
基于主从复制模式,读写分离的思想主要是针对实际项目中读多写少的场景,主节点支持读写,备用节点为只读,实际主节点负责更新数据,备用节点负责读取数据,这样可以备用节点可以有效地分摊数据读取的压力,提升整体性能。
**(5) 集群模式(数据分片、主备、读写分离、高可用都支持)**
持久化和主从复制解决了数据丢失的问题、读写分离分摊了读写压力提升了读写性能、使用数据分片支持多主多从将数据分片存储到多个主节点上以突破单机物理内存限制、而高可用方案是保证单点或少数节点出现故障的情况下系统仍然能够对外提供服务。综合起来,集群方案为就是解决以上问题产生的,下一章本文会介绍几种主流的集群架构方案。
**一、主流集群方案**
**1.1 客户端分片**
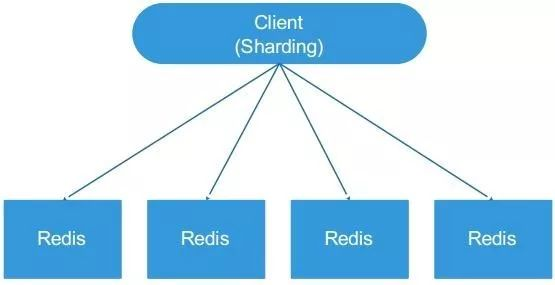
***优点***
不使用第三方中间件,实现方法和代码可以自己掌控并且可随时调整。这种分片性能比代理式更好(因为少了分发环节),分发压力在客户端,无服务端压力增加。
***缺点***
不能平滑地水平扩容,扩容/缩容时,必须手动调整分片程序,出现故障不能自动转移,难以运维。
**1.2 代理方式(以twemproxy为典型)**
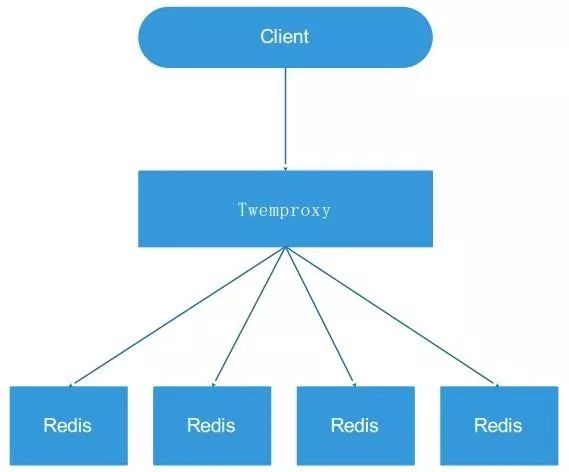
***优点***
运维成本低,业务方不用关心后端 redis 实例,跟操作 redis 一样。Proxy 的逻辑和存储的逻辑是隔离的
***缺点***
a. 代理层多了一次转发,性能有所损耗;
b. 进行扩容/缩容时候,部分数据可能会失效,需要手动进行迁移,对运维要求较高,而且难以做到平滑的扩缩容;
c. 出现故障,不能自动转移,运维性很差。
**1.3 redis cluster**
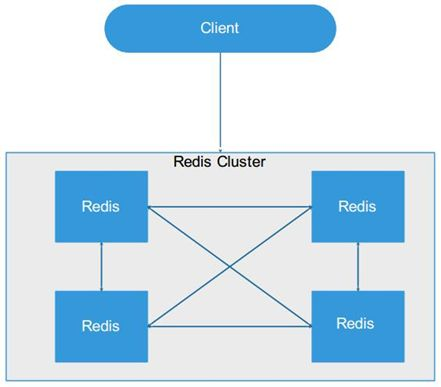
***优点***
a. 无中心节点;
b. 数据按照 slot 存储分布在多个 redis 实例上;
c. 平滑的进行扩容/缩容节点;
d. 自动故障转移(节点之间通过 gossip 协议交换状态信息,进行投票机制完成 Slave 到 Master 角色的提升);
e. 降低运维成本,提高了系统的可扩展性和高可用性。
***缺点***
a. 严重依赖外部 redis-trib;
b. 缺乏监控管理;
c. 需要依赖 smart client(连接维护, 缓存路由表, multiop 和 pipeline 支持);
d. failover 节点的检测过慢,不如“中心节点 zookeeper”及时;
e. gossip 消息的开销;
f. 无法根据统计区分冷热数据;
g. slave“冷备”不能缓解读压力。
**1.4 proxy + redis cluster**
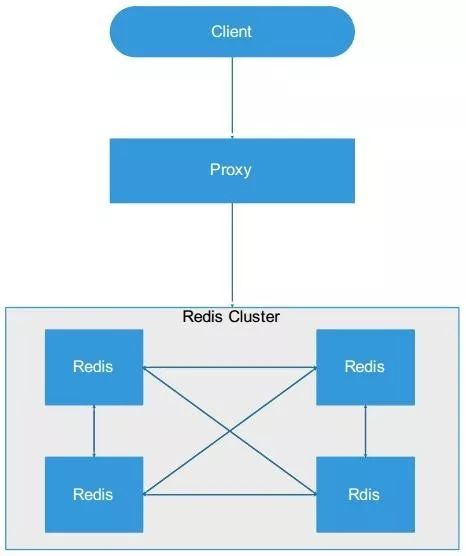
***优点***
如果使用smart client(三 redis cluster架构方式)
a. 相比于使用代理,减少了一层网络传输的消耗,效率较高;
b. 不依赖于第三方中间件,实现方法和代码自己掌控,可随时调整。
如果使用proxy:
a. 提供一套 http restful 接口,隔离底层存储。对客户端完全透明,跨语言调用;
b. 升级维护较为容易,维护 redis cluster,只需要平滑升级 proxy;
c. 层次化存储,底层存储做冷热异构存储;
d. 权限控制,proxy 可以通过秘钥控制白名单,把一些不合法的请求都过滤掉,并且也可以控制用户请求的超大 value 进行控制和过滤;
e. 安全性,可以屏蔽掉一些危险命令,比如 keys、save、flushall 等;
f. 容量控制,根据不同用户容量申请进行容量限制;
g. 资源逻辑隔离,根据不同用户的 Key 加上前缀,来进行资源隔离;
h. 监控埋点,对于不同的接口进行埋点监控等信息。
***缺点***
**smart client:**
a. 客户端的不成熟,影响应用的稳定性,提高开发难度;
b. multiop 和 pipeline 支持有限;
c. 连接维护,smart 客户端对连接到集群中每个结点 socket 的维护。
**Proxy:**
a. 代理层多了一次转发,性能有所损耗;
b.进行扩容/缩容时候对运维要求较高,而且难以做到平滑的扩缩容。
**二、实际项目中该如何选型呢?**
redis官方文档中有如下这段话:
The redis-cli cluster support is very basic so it always uses the fact that Redis Cluster nodes are able to redirect a client to the right node. A serious client is able to do better than that, and cache the map between hash slots and nodes addresses, to directly use the right connection to the right node. The map is refreshed only when something changed in the cluster configuration, for example after a failover or after the system administrator changed the cluster layout by adding or removing nodes.
大意就是目前redis cluster官方客户端功能简陋,依赖于redis节点重定向去到集群中找到数据所在的redis实例。需要有一个更完善的客户端,能够实现一致性hash,failover和集群管理功能。因此使用官方的redis cluster客户端不是一个明智的选择,本文提供3种方案供大家参考,如果有不合理的地方,欢迎大家与我共同探讨。
**方案 1 openresty方式**
即使用lua语言基于nginx进行redis cluster代理的开发,原因如下:
a. 单 master 多 worker 模式,每个 worker 跟 redis 一样都是单进程单线程模式,并且都是基于 epoll 事件驱动的模式;
b. nginx 采用了异步非阻塞的方式来处理请求,高效的异步框架;
c. 内存占用少,有自己的一套内存池管理方式。将大量小内存的申请聚集到一块,能够malloc 更快。减少内存碎片,防止内存泄漏减少内存管理复杂度;
d. 为了提高 nginx 的访问速度,nginx 使用了自己的一套连接池;
e. 最重要的是支持自定义模块开发;
f. 业界内,对于 nginx,redis 的口碑可称得上两大神器,性能也就不用说了,而且nginx自带lua模块,lua脚本开发简单效率高。
**方案 2 codis(豌豆荚采用的基于代理的redis集群方案)**
Codis是一整套缓存解决方案,包含高可用、数据分片、监控、动态扩态等。
走的是 Apps->代理->redis cluster,一定规模后基本都采用这种方式。
**方案3 自己独立开发redis智能客户端**
主要实现redis slots管理,failover,一致性hash功能。
**三、通用业务平台redis集群方案介绍**
下图展示的是通用业务平台所采用的缓存集群方案(期权指标监控项目也使用该方案),图中是三主三备的:
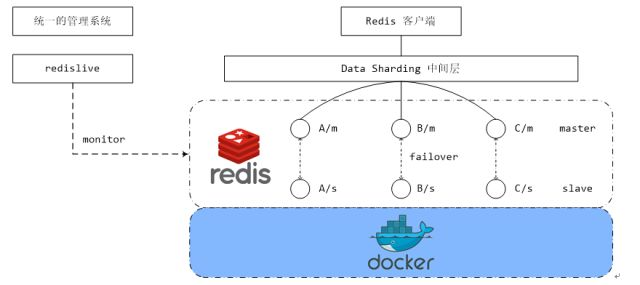
如图所示,客户端和redis集群之间有一个 data sharding中间层,主要用于redis数据的分片,redis后端将key通过一致性hash映射到16384个Slot中,而分片是针对slot做分片并非按照key做分片,这样做的好处是有利于redis数据的迁移(每个服务器负责存储一定范围slot的数据,如果需要扩容或者缩容,只需要对slot分布进行rebalance即可)。redis集群使用的是redis sentinel做集群管理,redis sentinel用于实现主备切换和读写分离。目前此套方案支持以下特性:
a. 缓存分片
缓存组件支持缓存分片,也就是缓存集群中的数据是分布在不同的缓存节点上的,并且缓存客户端能够知道某一条数据位于哪一个节点上,对于开发者而言是透明的。这些工作都是由图中的data sharding中间层来完成的。
b. 主备数据一致
主节点和备节点数据支持读写一致,当向主节点插入、修改或删除一条数据时,redis会异步地更新备用节点上的数据(Asynchronous replication)。Redis不保证强一致性,主备节点会有短暂的数据不一致的窗口期。
c. 读写分离
为了支持更大的并发,缓存做了读写分离(适合一主多备的场景),master节点用于写,slave节点用于读。开发者在使用组件提供的标准接口时,无需关心操作哪个节点,组件自身会对节点的路由选择进行封装。
d. 主备failover支持
集群支持主从切换(failover),redis官方sentinel解决方案在主节点down掉时会选举出新的slave节点升级为master节点(目前期权监控指标项目也是使用redis sentinel实现分布式缓存节点的高可用)。
e. 组件对外提供简单的接口,屏蔽底层技术细节
技术组件会对外提供通用且简单的接口用于操作分布式缓存集群,调用者无需关心服务器的部署结构,主备切换以及分片路由等细节。
f. 支持对redis实例的监控
使用redislive对redis cluster进行监控,并将监控结果集成到管理系统中
g. 支持容器化
redis实例支持运行在docker容器中,易于线上快速运维。
以上是我学习和使用redis的心得和体会,水平有限,欢迎指正。
【这里想说,因为自己也走了很多弯路过来的,所以才下定决心整理,收集过程虽不易,但想到能帮助到一部分自学java想提升Java架构师技术的,P5-P6-P7-P8 的人,心里也是甜的!有需要的伙伴请点㊦方】↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓

- 点赞
- 收藏
- 关注作者
评论(0)