卷积神经网络模型之——VGG-16网络结构与代码实现

【摘要】 卷积神经网络模型之——VGG-16网络结构与代码实现
@[TOC]
VGGNet简介
VGG原文:Very deep convolutional networks for large-scale image recognition:https://arxiv.org/pdf/1409.1556.pdf

VGG在2014年由牛津大学Visual GeometryGroup提出,获得该年lmageNet竞赛中Localization Task(定位任务)第一名和 Classification Task (分类任务)第二名。
VGG与AlexNet相比,它采用几个连续的3x3的卷积核代替AlexNet中的较大卷积核。
在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,从而在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
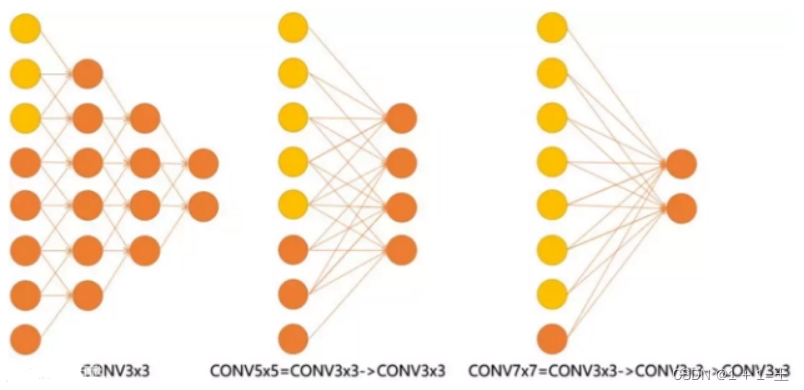
在论文中,作者尝试了使用5种不同的网络结构,深度分别为11,11,13,16,19,5种结构图如下所示:
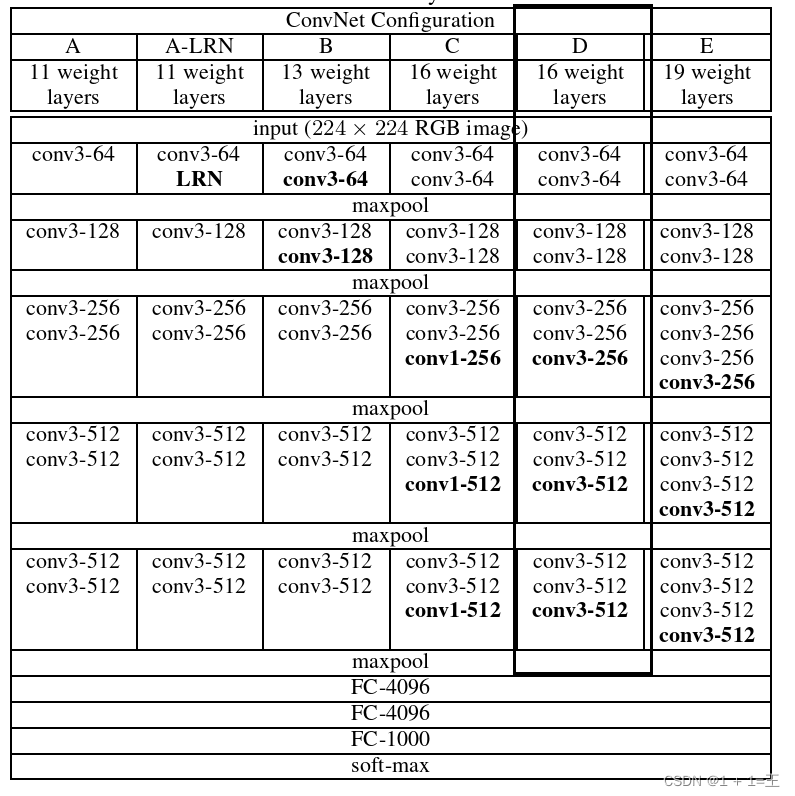
其中最常用的是VGG16和VGG19,下面我们就以VGG16为例来分析它的网络结构。
VGG16网络结构
VGG16中的16指的是它由16层组成(13个卷积层 + 3个全连接层,不包括池化层)。
VGG的输入图像大小为224X224X3的三通道彩色图像,共有1000个类别。
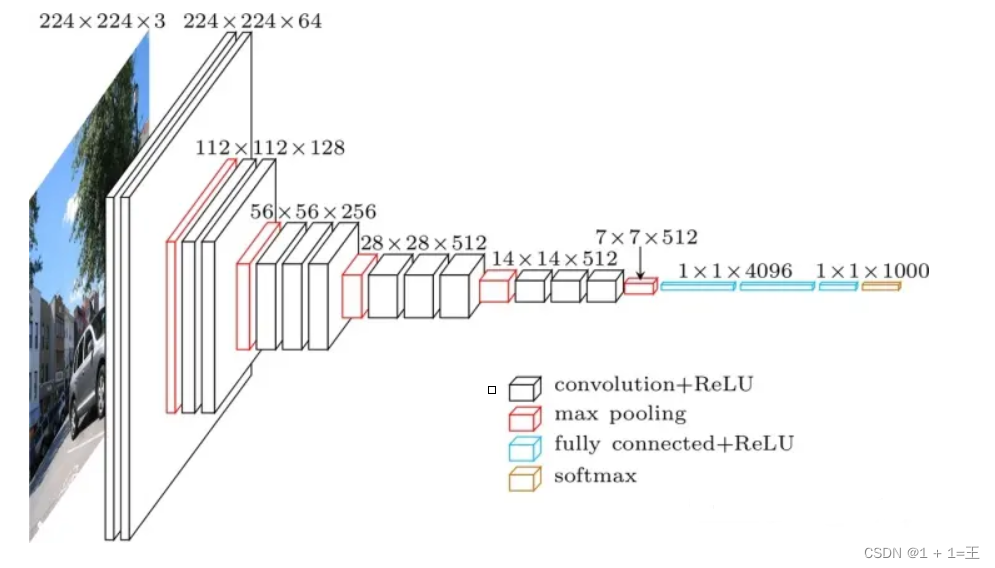
其中卷积层的卷积核大小都为3,padding为1;池化层的kernel_size为2,stride为2。
因此
- 卷积层只改变特征图的通道数,不改变大小。(W - 3 + 2*1)/ 1 + 1 = W
- 池化层不改变特征图的通道数,大小变为原来的一半。
VGG具有明显的块结构,VGG可以分为如下六块:
- 两个卷积 + 一个池化:conv3-64+conv3-64 + maxpool
- 两个卷积 + 一个池化:conv3-128+conv3-128+ maxpool
- 三个卷积 + 一个池化:conv3-256+conv3-256+conv3-256+ maxpool
- 三个卷积 + 一个池化:conv3-512+conv3-512+conv3-512+ maxpool
- 三个卷积 + 一个池化:conv3-512+conv3-512+conv3-512+ maxpool
- 三个全连接:fc-4096 + fc-4096 + fc-1000(对应1000个类别)
使用pytorch搭建VGG16
为了便于理解,我们把正向传播过程分为两块,
- 一块为特征提取层(features),包括13个卷积层;
- 另一块为分类层(classify),包括3个全连接层。
features
def make_features(self):
cfgs = [64, 64, 'MaxPool', 128, 128, 'MaxPool', 256, 256, 256, 'MaxPool', 512, 512, 512, 'MaxPool', 512, 512, 512, 'MaxPool']
layers = []
in_channel = 3
for cfg in cfgs:
if cfg == "MaxPool": # 池化层
layers += [nn.MaxPool2d(kernel_size=2,stride=2)]
else:
layers += [nn.Conv2d(in_channels=in_channel,out_channels=cfg,kernel_size=3,padding=1)]
layers += [nn.ReLU(True)]
in_channel = cfg
return nn.Sequential(*layers)
classifier
【注意】:在进行全连接之前,需要现将卷积层输出的三维特征图展平为1维。
x = torch.flatten(x,start_dim=1)
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 1000)
)
完整代码
"""
#-*-coding:utf-8-*-
# @author: wangyu a beginner programmer, striving to be the strongest.
# @date: 2022/7/1 15:01
"""
import torch
import torch.nn as nn
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.features = self.make_features()
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 1000)
)
def forward(self,x):
x = self.features(x)
x = torch.flatten(x,start_dim=1)
x = self.classifier(x)
return x
def make_features(self):
cfgs = [64, 64, 'MaxPool', 128, 128, 'MaxPool', 256, 256, 256, 'MaxPool', 512, 512, 512, 'MaxPool', 512, 512, 512, 'MaxPool']
layers = []
in_channel = 3
for cfg in cfgs:
if cfg == "MaxPool": # 池化层
layers += [nn.MaxPool2d(kernel_size=2,stride=2)]
else:
layers += [nn.Conv2d(in_channels=in_channel,out_channels=cfg,kernel_size=3,padding=1)]
layers += [nn.ReLU(True)]
in_channel = cfg
return nn.Sequential(*layers)
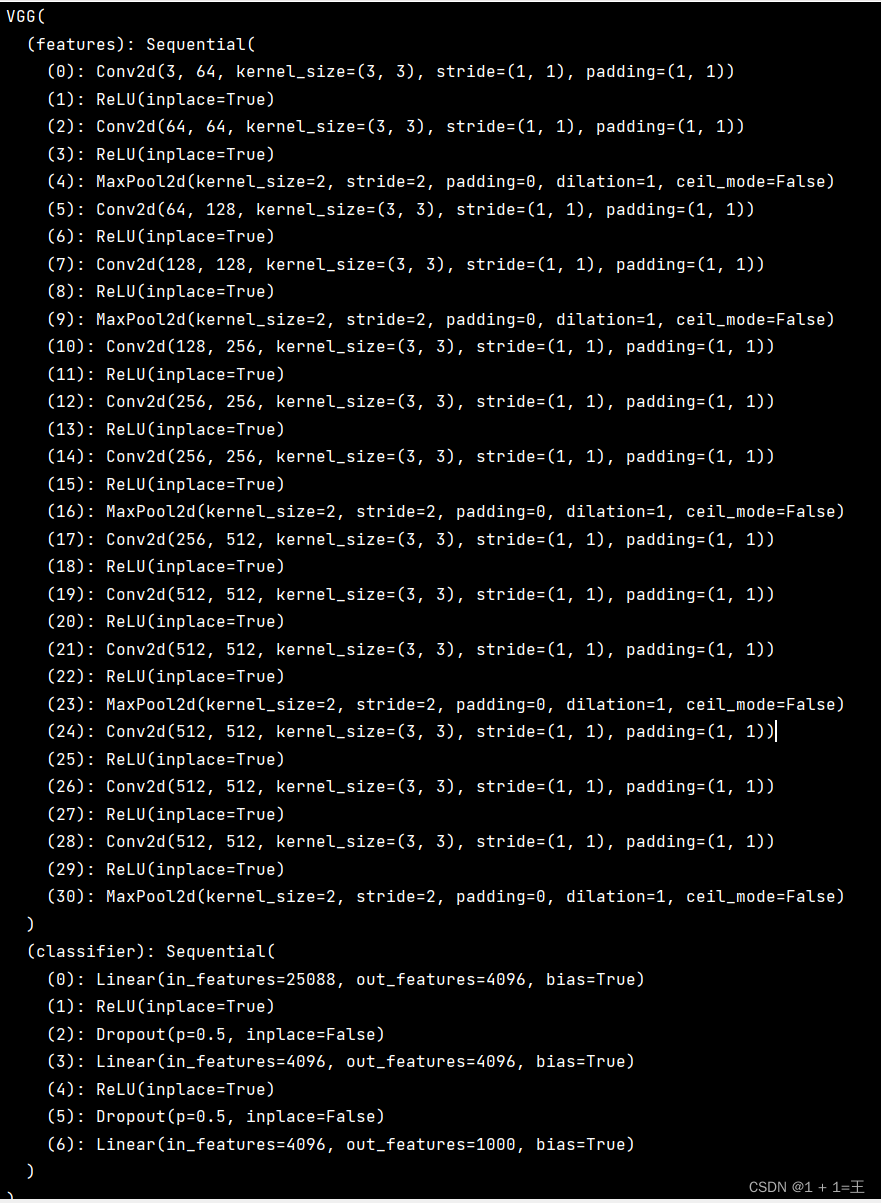
net = VGG()
print(net)

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)