深度学习的训练、预测过程详解【以LeNet模型和CIFAR10数据集为例】

【摘要】 深度学习的训练、预测过程详解【以LeNet模型和CIFAR10数据集为例】
@[TOC]
模型和数据集介绍
模型:LeNet
Lenet是一个 7 层的神经网络(不包含输入层),包含 3 个卷积层,2 个池化层,2 个全连接层。
使用pytorch搭建如下:
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5) # C1
self.pool1 = nn.MaxPool2d(2, 2) # S2
self.conv2 = nn.Conv2d(16, 32, 5) # C3
self.pool2 = nn.MaxPool2d(2, 2) # S4
self.fc1 = nn.Linear(32*5*5, 120) # C5(用全连接代替)
self.fc2 = nn.Linear(120, 84) # F6
self.fc3 = nn.Linear(84, 10) # F7
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5) 展平
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
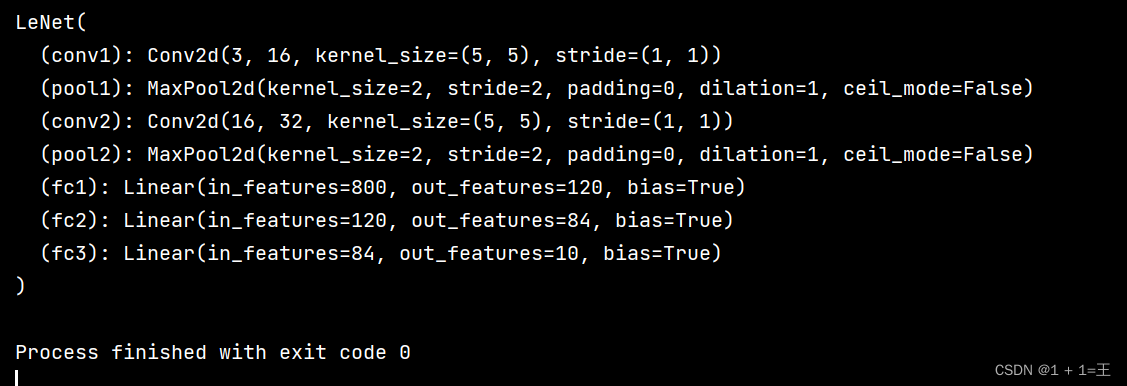
model = LeNet()
print(model)
数据集:CIFAR10
下载地址:https://tensorflow.google.cn/datasets/catalog/cifar10
CIFAR10数据集共有60000张彩色图像,其中50000张用于训练,5个训练批,每一批10000张图;10000张用于测试。
图片大小为3X32X32,分为10个类别,每个类6000张。

训练过程
对于模型的训练可以分为一下几个步骤:
- 数据集加载
- 模型加载
- 迭代训练
- 验证
下面就结合代码进行详细分析:
1. 加载数据与归一化
# 数据归一化处理
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 加载训练数据集
# 第一次使用时要将download设置为True才会自动去下载数据集
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
# 加载测试验证数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=5000,
shuffle=False, num_workers=0)
val_data_iter = iter(val_loader)
# val_image, val_label分别表示原始图像和图像对应的标签(类别)
# 训练集在训练时也要进行拆分
val_image, val_label = val_data_iter.next()
2.加载模型
# 引入模型
net = LeNet()
# 定义损失函数
loss_function = nn.CrossEntropyLoss()
# 定义优化器,传入模型参数和学习率lr
optimizer = optim.Adam(net.parameters(), lr=0.001)
3.迭代训练
for epoch in range(100): # 迭代100次
running_loss = 0.0 # 设置初始损失为0
for step, data in enumerate(train_loader, start=0):
# inputs, labels分别表示原始图像和图像对应的标签(类别)
inputs, labels = data
# 每个batch都把梯度信息设置为0
# (也可以多个batch 只调用一次optimizer.zero_grad函数。这样相当于增大了batch_size)
optimizer.zero_grad()
# 传入原始图片至模型中,得到预测结果
outputs = net(inputs)
# 用预测结果和原始标签计算损失
loss = loss_function(outputs, labels)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
4.验证
for epoch in range(100): # 迭代100次
running_loss = 0.0 # 设置初始损失为0
for step, data in enumerate(train_loader, start=0):
# inputs, labels分别表示原始图像和图像对应的标签(类别)
inputs, labels = data
# 每个batch都把梯度信息设置为0
# (也可以多个batch 只调用一次optimizer.zero_grad函数。这样相当于增大了batch_size)
optimizer.zero_grad()
# 传入原始图片至模型中,得到预测结果
outputs = net(inputs)
# 用预测结果和原始标签计算损失
loss = loss_function(outputs, labels)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 计算训练总损失
running_loss += loss.item()
#上面为训练过程,从此开始验证
##########################################
with torch.no_grad(): # 验证是停止计算梯度
# 传入验证集原始图片至模型中,得到预测结果
outputs = net(val_image)
predict_y = torch.max(outputs, dim=1)[1]
# 计算预测值和标签值相同的个数,并除以总数,得到精确度
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
# 打印训练损失和准确度
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
# 重置损失为0,开启下一次迭代训练
running_loss = 0.0
print('Finished Training')
# 训练结束,保存模型
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)