爬虫基础入门理论

【摘要】 近年来由于抓取数据而引起的纠纷越来越多,有的锒铛入狱,有的被处罚金,本人爬虫笔记学习提醒大家:爬虫有风险,采集需谨慎,写代码不能违法,写代码背后也有法律风险 1.1爬虫注意点 1.1.1遵守Robots协议Robots协议,也称为爬虫协议、机器人协议等,全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉爬虫哪些页面可以抓取,哪些页面...
近年来由于抓取数据而引起的纠纷越来越多,有的锒铛入狱,有的被处罚金,本人爬虫笔记学习提醒大家:爬虫有风险,采集需谨慎,写代码不能违法,写代码背后也有法律风险
1.1爬虫注意点
1.1.1遵守Robots协议
Robots协议,也称为爬虫协议、机器人协议等,全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉爬虫哪些页面可以抓取,哪些页面不能抓取
如何查看网站的rebots协议?
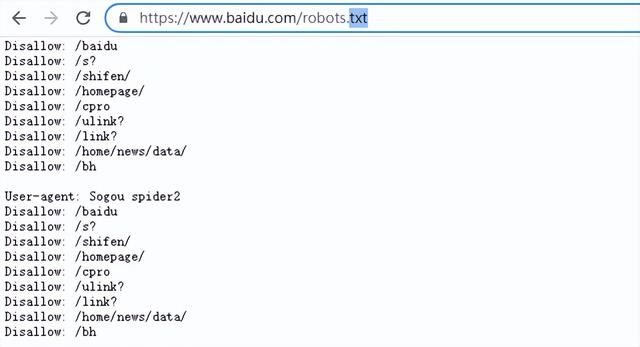
(1)打开浏览器,在地址栏中输入http://网站域名/robots.txt即可,以查询百度的robots协议为例;Disallow后边的目录是禁止所有搜索引擎搜索的
(2)或者借助相关网站进行查看,如站长工具等,浏览器打开http://s.tool.chinaz.com/robots,输入网站地址,点击查询即可
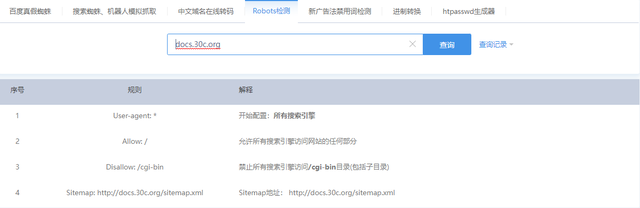
1.1.2.不过度采集数据
过度数据采集会对目标站点产生非常大的压力,可导致目标站点服务器瘫痪、不能访问等,相当于网络攻击。学习过程中抓取数据不可贪多,满足学习需求即可,损害他人权益的事不能做
1.1.3.不要采集隐私数据
有选择地采集数据,别人不让看的数据不要爬,私人数据不要爬,如手机号、身份证号、住址、个人财产等不要抓取,受法律保护的特定类型的数据或信息不能抓取
1.1.4.网站有声明”禁止爬虫采集或转载商业化”
当采集的站点有声明,禁止爬虫采集或转载商业化,请绕行,不让爬的数据不要爬
1.1.5.不得将抓取数据用于商业化使用
恶意利用爬虫技术抓取数据,进行不正当竞争,甚至牟取不法利益,会触犯法律,数据采集不得伤害他人利益
1.2.爬虫与爬虫工程师
爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,是搜索引擎的重要组成;爬虫可以用于以下场景:搜索引擎、数据分析、人工智能、薅羊毛、抢车票等。
目前市面主流的爬虫产品有:神箭手、八爪鱼、造数、后羿采集器等
爬虫工程师简单点理解就是数据的搬运工
爬虫工程师的技术储备
- python编程基础
- linux系统管理基础
- http协议
- 数据库增删改查为基础
爬虫技术怎么学
- 首先要学会基础的Python语法知识
- 学习Python爬虫常用到的几个重要内置库Requests,用于请求网页
- 学习正则表达式re、Xpath(lxml)等网页解析工具
- 了解爬虫的一些反爬机制,header、robot、代理IP、验证码等
- 了解爬虫与数据库的结合,如何将爬取的数据进行存储
- 学习应用python的多线程、多进程进行爬取,提高爬虫效率
- 学习爬虫的框架scrapy

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)