GC - Java 垃圾回收器之CMS GC问题分析与解决

- GC - Java 垃圾回收器之CMS GC问题分析与解决
1. 写在前面
本文主要针对 Hotspot VM 中“CMS + ParNew”组合的一些使用场景进行总结。重点通过部分源码对根因进行分析以及对排查方法进行总结,排查过程会省略较多,另外本文专业术语较多,有一定的阅读门槛,如未介绍清楚,还请自行查阅相关材料。
1.1 引言
自 Sun 发布 Java 语言以来,开始使用 GC 技术来进行内存自动管理,避免了手动管理带来的悬挂指针(Dangling Pointer)问题,很大程度上提升了开发效率,从此 GC 技术也一举成名。GC 有着非常悠久的历史,1960 年有着“Lisp 之父”和“人工智能之父”之称的 John McCarthy 就在论文中发布了 GC 算法,60 年以来, GC 技术的发展也突飞猛进,但不管是多么前沿的收集器也都是基于三种基本算法的组合或应用,也就是说 GC 要解决的根本问题这么多年一直都没有变过。笔者认为,在不太远的将来, GC 技术依然不会过时,比起日新月异的新技术,GC 这门古典技术更值得我们学习。
目前,互联网上 Java 的 GC 资料要么是主要讲解理论,要么就是针对单一场景的 GC 问题进行了剖析,对整个体系总结的资料少之又少。前车之鉴,后事之师,美团的几位工程师搜集了内部各种 GC 问题的分析文章,并结合个人的理解做了一些总结,希望能起到“抛砖引玉”的作用,文中若有错误之处,还请大家不吝指正。
GC 问题处理能力能不能系统性掌握?一些影响因素都是互为因果的问题该怎么分析?比如一个服务 RT 突然上涨,有 GC 耗时增大、线程 Block 增多、慢查询增多、CPU 负载高四个表象,到底哪个是诱因?如何判断 GC 有没有问题?使用 CMS 有哪些常见问题?如何判断根因是什么?如何解决或避免这些问题?阅读完本文,相信你将会对 CMS GC 的问题处理有一个系统性的认知,更能游刃有余地解决这些问题,下面就让我们开始吧!
1.2 概览
想要系统性地掌握 GC 问题处理,笔者这里给出一个学习路径,整体文章的框架也是按照这个结构展开,主要分四大步。

建立知识体系: 从 JVM 的内存结构到垃圾收集的算法和收集器,学习 GC 的基础知识,掌握一些常用的 GC 问题分析工具。
确定评价指标: 了解基本 GC 的评价方法,摸清如何设定独立系统的指标,以及在业务场景中判断 GC 是否存在问题的手段。
场景调优实践: 运用掌握的知识和系统评价指标,分析与解决九种 CMS 中常见 GC 问题场景。
总结优化经验: 对整体过程做总结并提出笔者的几点建议,同时将总结到的经验完善到知识体系之中。
2. GC 基础
在正式开始前,先做些简要铺垫,介绍下 JVM 内存划分、收集算法、收集器等常用概念介绍,基础比较好的同学可以直接跳过这部分。
2.1 基础概念
-
GC: GC 本身有三种语义,下文需要根据具体场景带入不同的语义:
-
Garbage Collection:垃圾收集技术,名词。
-
Garbage Collector:垃圾收集器,名词。
-
Garbage Collecting:垃圾收集动作,动词。
-
-
Mutator: 生产垃圾的角色,也就是我们的应用程序,垃圾制造者,通过 Allocator 进行 allocate 和 free。
-
TLAB: Thread Local Allocation Buffer 的简写,基于 CAS 的独享线程(Mutator Threads)可以优先将对象分配在 Eden 中的一块内存,因为是 Java 线程独享的内存区没有锁竞争,所以分配速度更快,每个 TLAB 都是一个线程独享的。
-
Card Table: 中文翻译为卡表,主要是用来标记卡页的状态,每个卡表项对应一个卡页。当卡页中一个对象引用有写操作时,写屏障将会标记对象所在的卡表状态改为 dirty,卡表的本质是用来解决跨代引用的问题。具体怎么解决的可以参考 StackOverflow 上的这个问题 how-actually-card-table-and-writer-barrier-works,或者研读一下 cardTableRS.app 中的源码。
2.2 JVM 内存划分
从 JCP(Java Community Process)的官网中可以看到,目前 Java 版本最新已经到了 Java 16,未来的 Java 17 以及现在的 Java 11 和 Java 8 是 LTS 版本,JVM 规范也在随着迭代在变更,由于本文主要讨论 CMS,此处还是放 Java 8 的内存结构。

GC 主要工作在 Heap 区和 MetaSpace 区(上图蓝色部分),在 Direct Memory 中,如果使用的是 DirectByteBuffer,那么在分配内存不够时则是 GC 通过 Cleaner#clean 间接管理。
任何自动内存管理系统都会面临的步骤:为新对象分配空间,然后收集垃圾对象空间,下面我们就展开介绍一下这些基础知识。
2.3 分配对象
Java 中对象地址操作主要使用 Unsafe 调用了 C 的 allocate 和 free 两个方法,分配方法有两种:
-
空闲链表(free list): 通过额外的存储记录空闲的地址,将随机 IO 变为顺序 IO,但带来了额外的空间消耗。
-
碰撞指针(bump pointer): 通过一个指针作为分界点,需要分配内存时,仅需把指针往空闲的一端移动与对象大小相等的距离,分配效率较高,但使用场景有限。
2.4 收集对象
2.4.1 识别垃圾
引用计数法(Reference Counting): 对每个对象的引用进行计数,每当有一个地方引用它时计数器 +1、引用失效则 -1,引用的计数放到对象头中,大于 0 的对象被认为是存活对象。虽然循环引用的问题可通过 Recycler 算法解决,但是在多线程环境下,引用计数变更也要进行昂贵的同步操作,性能较低,早期的编程语言会采用此算法。
可达性分析,又称引用链法(Tracing GC): 从 GC Root 开始进行对象搜索,可以被搜索到的对象即为可达对象,此时还不足以判断对象是否存活/死亡,需要经过多次标记才能更加准确地确定,整个连通图之外的对象便可以作为垃圾被回收掉。目前 Java 中主流的虚拟机均采用此算法。
备注:引用计数法是可以处理循环引用问题的,下次面试时不要再这么说啦~ ~
2.4.2 收集算法
自从有自动内存管理出现之时就有的一些收集算法,不同的收集器也是在不同场景下进行组合。
Mark-Sweep(标记-清除): 回收过程主要分为两个阶段,第一阶段为追踪(Tracing)阶段,即从 GC Root 开始遍历对象图,并标记(Mark)所遇到的每个对象,第二阶段为清除(Sweep)阶段,即回收器检查堆中每一个对象,并将所有未被标记的对象进行回收,整个过程不会发生对象移动。整个算法在不同的实现中会使用三色抽象(Tricolour Abstraction)、位图标记(BitMap)等技术来提高算法的效率,存活对象较多时较高效。
Mark-Compact (标记-整理): 这个算法的主要目的就是解决在非移动式回收器中都会存在的碎片化问题,也分为两个阶段,第一阶段与 Mark-Sweep 类似,第二阶段则会对存活对象按照整理顺序(Compaction Order)进行整理。主要实现有双指针(Two-Finger)回收算法、滑动回收(Lisp2)算法和引线整理(Threaded Compaction)算法等。
Copying(复制): 将空间分为两个大小相同的 From 和 To 两个半区,同一时间只会使用其中一个,每次进行回收时将一个半区的存活对象通过复制的方式转移到另一个半区。有递归(Robert R. Fenichel 和 Jerome C. Yochelson提出)和迭代(Cheney 提出)算法,以及解决了前两者递归栈、缓存行等问题的近似优先搜索算法。复制算法可以通过碰撞指针的方式进行快速地分配内存,但是也存在着空间利用率不高的缺点,另外就是存活对象比较大时复制的成本比较高。
三种算法在是否移动对象、空间和时间方面的一些对比,假设存活对象数量为 L、堆空间大小为 H,则:

把 mark、sweep、compaction、copying 这几种动作的耗时放在一起看,大致有这样的关系:
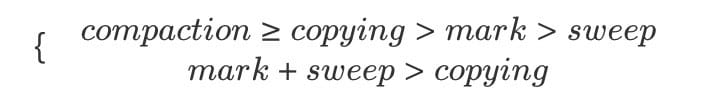
虽然 compaction 与 copying 都涉及移动对象,但取决于具体算法,compaction 可能要先计算一次对象的目标地址,然后修正指针,最后再移动对象。copying 则可以把这几件事情合为一体来做,所以可以快一些。另外,还需要留意 GC 带来的开销不能只看 Collector 的耗时,还得看 Allocator 。如果能保证内存没碎片,分配就可以用 pointer bumping 方式,只需要挪一个指针就完成了分配,非常快。而如果内存有碎片就得用 freelist 之类的方式管理,分配速度通常会慢一些。
2.5 收集器
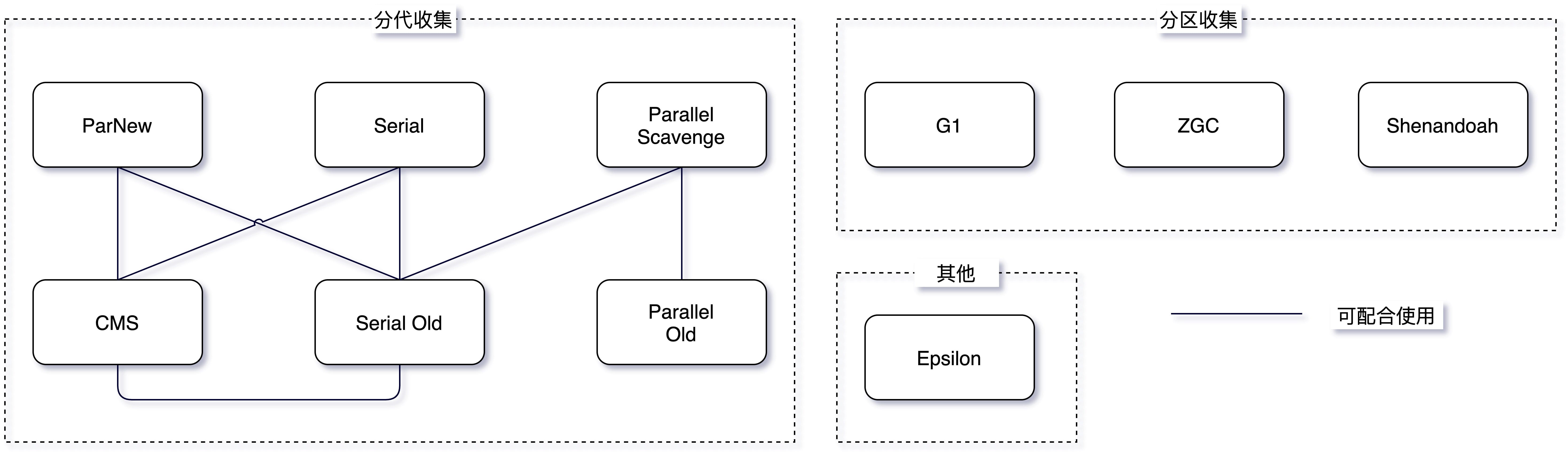
目前在 Hotspot VM 中主要有分代收集和分区收集两大类,具体可以看下面的这个图,不过未来会逐渐向分区收集发展。在美团内部,有部分业务尝试用了 ZGC(感兴趣的同学可以学习下这篇文章 新一代垃圾回收器ZGC的探索与实践),其余基本都停留在 CMS 和 G1 上。另外在 JDK11 后提供了一个不执行任何垃圾回收动作的回收器 Epsilon(A No-Op Garbage Collector)用作性能分析。另外一个就是 Azul 的 Zing JVM,其 C4(Concurrent Continuously Compacting Collector)收集器也在业内有一定的影响力。
备注:值得一提的是,早些年国内 GC 技术的布道者 RednaxelaFX (江湖人称 R 大)也曾就职于 Azul,本文的一部分材料也参考了他的一些文章。
2.5.1 分代收集器
-
ParNew: 一款多线程的收集器,采用复制算法,主要工作在 Young 区,可以通过
-XX:ParallelGCThreads参数来控制收集的线程数,整个过程都是 STW 的,常与 CMS 组合使用。 -
CMS: 以获取最短回收停顿时间为目标,采用“标记-清除”算法,分 4 大步进行垃圾收集,其中初始标记和重新标记会 STW ,多数应用于互联网站或者 B/S 系统的服务器端上,JDK9 被标记弃用,JDK14 被删除,详情可见 JEP 363
2.5.2 分区收集器
-
G1: 一种服务器端的垃圾收集器,应用在多处理器和大容量内存环境中,在实现高吞吐量的同时,尽可能地满足垃圾收集暂停时间的要求。
-
ZGC: JDK11 中推出的一款低延迟垃圾回收器,适用于大内存低延迟服务的内存管理和回收,SPECjbb 2015 基准测试,在 128G 的大堆下,最大停顿时间才 1.68 ms,停顿时间远胜于 G1 和 CMS。
-
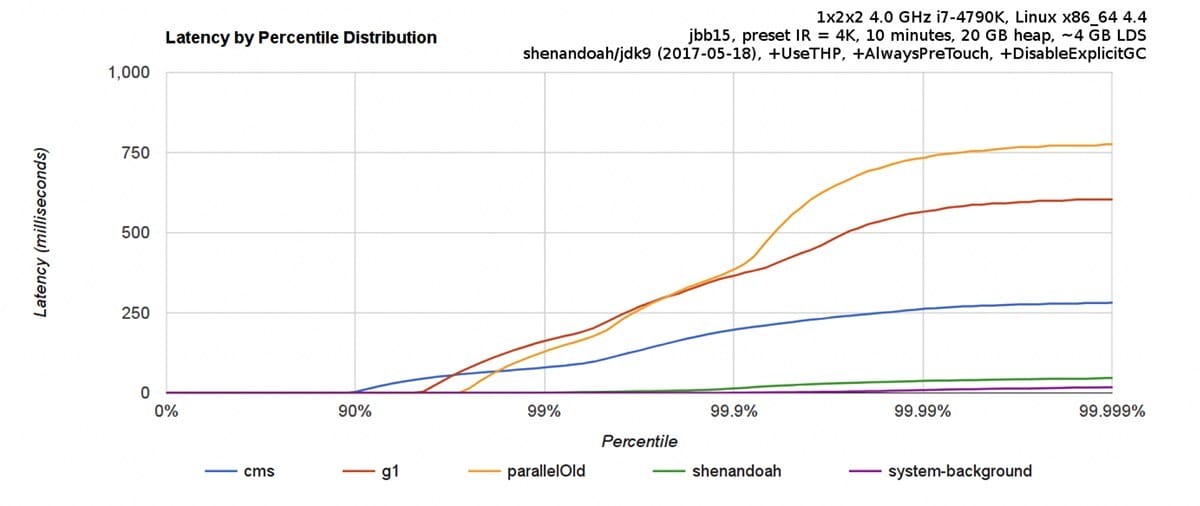
Shenandoah: 由 Red Hat 的一个团队负责开发,与 G1 类似,基于 Region 设计的垃圾收集器,但不需要 Remember Set 或者 Card Table 来记录跨 Region 引用,停顿时间和堆的大小没有任何关系。停顿时间与 ZGC 接近,下图为与 CMS 和 G1 等收集器的 benchmark。
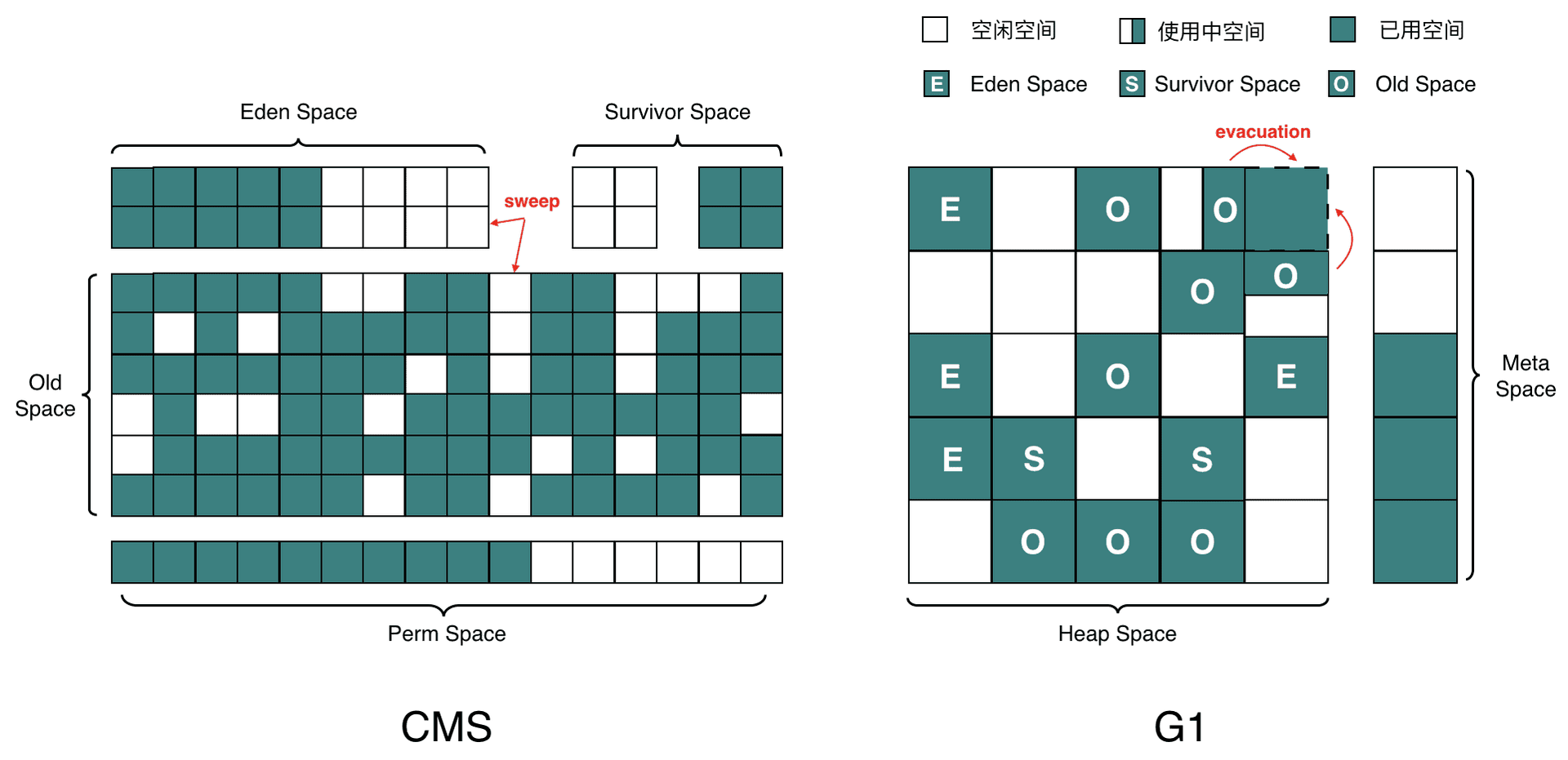
2.5.3 常用收集器
目前使用最多的是 CMS 和 G1 收集器,二者都有分代的概念,主要内存结构如下:
2.5.4 其他收集器
以上仅列出常见收集器,除此之外还有很多,如 Metronome、Stopless、Staccato、Chicken、Clover 等实时回收器,Sapphire、Compressor、Pauseless 等并发复制/整理回收器,Doligez-Leroy-Conthier 等标记整理回收器,由于篇幅原因,不在此一一介绍。
2.6 常用工具
工欲善其事,必先利其器,此处列出一些笔者常用的工具,具体情况大家可以自由选择,本文的问题都是使用这些工具来定位和分析的。
2.6.1 命令行终端
- 标准终端类:jps、jinfo、jstat、jstack、jmap
- 功能整合类:jcmd、vjtools、arthas、greys
2.6.2 可视化界面
- 简易:JConsole、JVisualvm、HA、GCHisto、GCViewer
- 进阶:MAT、JProfiler
- 命令行推荐 arthas ,可视化界面推荐 JProfiler,此外还有一些在线的平台 gceasy、heaphero、fastthread ,美团内部的 Scalpel(一款自研的 JVM 问题诊断工具,暂时未开源)也比较好用。
3. GC 问题判断
在做 GC 问题排查和优化之前,我们需要先来明确下到底是不是 GC 直接导致的问题,或者应用代码导致的 GC 异常,最终出现问题。
3.1 判断 GC 有没有问题?
3.1.1 设定评价标准
评判 GC 的两个核心指标:
-
延迟(Latency): 也可以理解为最大停顿时间,即垃圾收集过程中一次 STW 的最长时间,越短越好,一定程度上可以接受频次的增大,GC 技术的主要发展方向。
-
吞吐量(Throughput): 应用系统的生命周期内,由于 GC 线程会占用 Mutator 当前可用的 CPU 时钟周期,吞吐量即为 Mutator 有效花费的时间占系统总运行时间的百分比,例如系统运行了 100 min,GC 耗时 1 min,则系统吞吐量为 99%,吞吐量优先的收集器可以接受较长的停顿。
目前各大互联网公司的系统基本都更追求低延时,避免一次 GC 停顿的时间过长对用户体验造成损失,衡量指标需要结合一下应用服务的 SLA,主要如下两点来判断:

简而言之,即为一次停顿的时间不超过应用服务的 TP9999,GC 的吞吐量不小于 99.99%。举个例子,假设某个服务 A 的 TP9999 为 80 ms,平均 GC 停顿为 30 ms,那么该服务的最大停顿时间最好不要超过 80 ms,GC 频次控制在 5 min 以上一次。如果满足不了,那就需要调优或者通过更多资源来进行并联冗余。(大家可以先停下来,看看监控平台上面的 gc.meantime 分钟级别指标,如果超过了 6 ms 那单机 GC 吞吐量就达不到 4 个 9 了。)
备注:除了这两个指标之外还有 Footprint(资源量大小测量)、反应速度等指标,互联网这种实时系统追求低延迟,而很多嵌入式系统则追求 Footprint。
3.1.2 读懂 GC Cause
拿到 GC 日志,我们就可以简单分析 GC 情况了,通过一些工具,我们可以比较直观地看到 Cause 的分布情况,如下图就是使用 gceasy 绘制的图表:
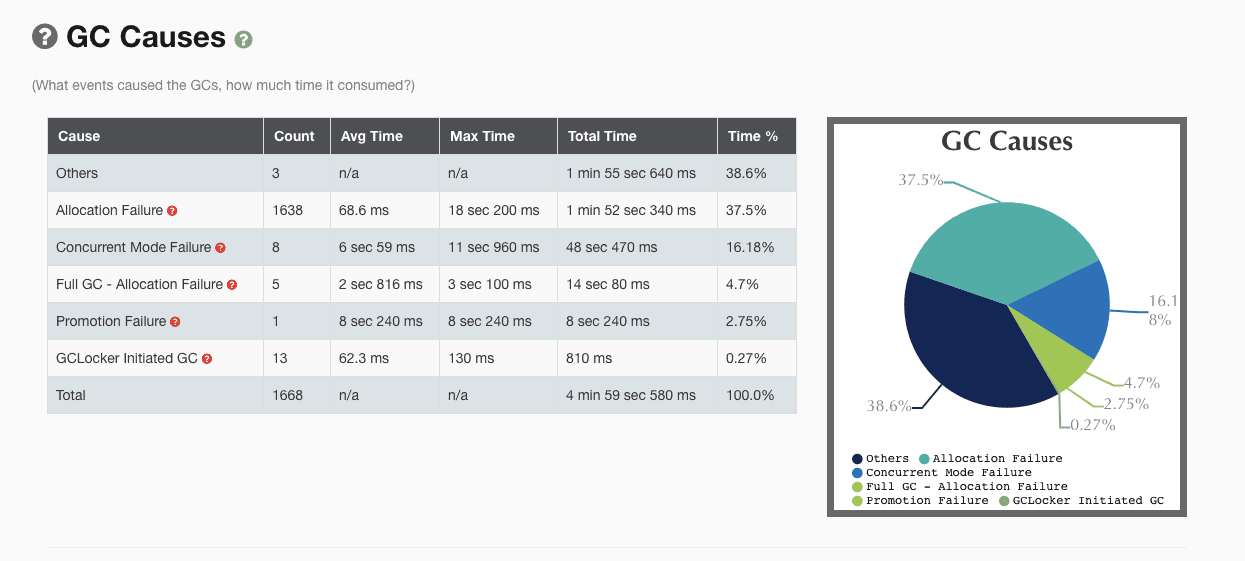
如上图所示,我们很清晰的就能知道是什么原因引起的 GC,以及每次的时间花费情况,但是要分析 GC 的问题,先要读懂 GC Cause,即 JVM 什么样的条件下选择进行 GC 操作,具体 Cause 的分类可以看一下 Hotspot 源码:src/share/vm/gc/shared/gcCause.hpp 和 src/share/vm/gc/shared/gcCause.cpp 中。
const char* GCCause::to_string(GCCause::Cause cause) {
switch (cause) {
case _java_lang_system_gc:
return "System.gc()";
case _full_gc_alot:
return "FullGCAlot";
case _scavenge_alot:
return "ScavengeAlot";
case _allocation_profiler:
return "Allocation Profiler";
case _jvmti_force_gc:
return "JvmtiEnv ForceGarbageCollection";
case _gc_locker:
return "GCLocker Initiated GC";
case _heap_inspection:
return "Heap Inspection Initiated GC";
case _heap_dump:
return "Heap Dump Initiated GC";
case _wb_young_gc:
return "WhiteBox Initiated Young GC";
case _wb_conc_mark:
return "WhiteBox Initiated Concurrent Mark";
case _wb_full_gc:
return "WhiteBox Initiated Full GC";
case _no_gc:
return "No GC";
case _allocation_failure:
return "Allocation Failure";
case _tenured_generation_full:
return "Tenured Generation Full";
case _metadata_GC_threshold:
return "Metadata GC Threshold";
case _metadata_GC_clear_soft_refs:
return "Metadata GC Clear Soft References";
case _cms_generation_full:
return "CMS Generation Full";
case _cms_initial_mark:
return "CMS Initial Mark";
case _cms_final_remark:
return "CMS Final Remark";
case _cms_concurrent_mark:
return "CMS Concurrent Mark";
case _old_generation_expanded_on_last_scavenge:
return "Old Generation Expanded On Last Scavenge";
case _old_generation_too_full_to_scavenge:
return "Old Generation Too Full To Scavenge";
case _adaptive_size_policy:
return "Ergonomics";
case _g1_inc_collection_pause:
return "G1 Evacuation Pause";
case _g1_humongous_allocation:
return "G1 Humongous Allocation";
case _dcmd_gc_run:
return "Diagnostic Command";
case _last_gc_cause:
return "ILLEGAL VALUE - last gc cause - ILLEGAL VALUE";
default:
return "unknown GCCause";
}
ShouldNotReachHere();
}
-
System.gc(): 手动触发GC操作。 -
CMS: CMS GC 在执行过程中的一些动作,重点关注 CMS Initial Mark 和 CMS Final Remark 两个 STW 阶段。 -
Promotion Failure: Old 区没有足够的空间分配给 Young 区晋升的对象(即使总可用内存足够大)。 -
Concurrent Mode Failure: CMS GC 运行期间,Old 区预留的空间不足以分配给新的对象,此时收集器会发生退化,严重影响 GC 性能,下面的一个案例即为这种场景。 -
GCLocker Initiated GC: 如果线程执行在 JNI 临界区时,刚好需要进行 GC,此时 GC Locker 将会阻止 GC 的发生,同时阻止其他线程进入 JNI 临界区,直到最后一个线程退出临界区时触发一次 GC。
什么时机使用这些 Cause 触发回收,大家可以看一下 CMS 的代码,这里就不讨论了,具体在 /src/hotspot/share/gc/cms/concurrentMarkSweepGeneration.cpp 中。
bool CMSCollector::shouldConcurrentCollect() {
LogTarget(Trace, gc) log;
if (_full_gc_requested) {
log.print("CMSCollector: collect because of explicit gc request (or GCLocker)");
return true;
}
FreelistLocker x(this);
// ------------------------------------------------------------------
// Print out lots of information which affects the initiation of
// a collection.
if (log.is_enabled() && stats().valid()) {
log.print("CMSCollector shouldConcurrentCollect: ");
LogStream out(log);
stats().print_on(&out);
log.print("time_until_cms_gen_full %3.7f", stats().time_until_cms_gen_full());
log.print("free=" SIZE_FORMAT, _cmsGen->free());
log.print("contiguous_available=" SIZE_FORMAT, _cmsGen->contiguous_available());
log.print("promotion_rate=%g", stats().promotion_rate());
log.print("cms_allocation_rate=%g", stats().cms_allocation_rate());
log.print("occupancy=%3.7f", _cmsGen->occupancy());
log.print("initiatingOccupancy=%3.7f", _cmsGen->initiating_occupancy());
log.print("cms_time_since_begin=%3.7f", stats().cms_time_since_begin());
log.print("cms_time_since_end=%3.7f", stats().cms_time_since_end());
log.print("metadata initialized %d", MetaspaceGC::should_concurrent_collect());
}
// ------------------------------------------------------------------
// If the estimated time to complete a cms collection (cms_duration())
// is less than the estimated time remaining until the cms generation
// is full, start a collection.
if (!UseCMSInitiatingOccupancyOnly) {
if (stats().valid()) {
if (stats().time_until_cms_start() == 0.0) {
return true;
}
} else {
if (_cmsGen->occupancy() >= _bootstrap_occupancy) {
log.print(" CMSCollector: collect for bootstrapping statistics: occupancy = %f, boot occupancy = %f",
_cmsGen->occupancy(), _bootstrap_occupancy);
return true;
}
}
}
if (_cmsGen->should_concurrent_collect()) {
log.print("CMS old gen initiated");
return true;
}
CMSHeap* heap = CMSHeap::heap();
if (heap->incremental_collection_will_fail(true /* consult_young */)) {
log.print("CMSCollector: collect because incremental collection will fail ");
return true;
}
if (MetaspaceGC::should_concurrent_collect()) {
log.print("CMSCollector: collect for metadata allocation ");
return true;
}
// CMSTriggerInterval starts a CMS cycle if enough time has passed.
if (CMSTriggerInterval >= 0) {
if (CMSTriggerInterval == 0) {
// Trigger always
return true;
}
// Check the CMS time since begin (we do not check the stats validity
// as we want to be able to trigger the first CMS cycle as well)
if (stats().cms_time_since_begin() >= (CMSTriggerInterval / ((double) MILLIUNITS))) {
if (stats().valid()) {
log.print("CMSCollector: collect because of trigger interval (time since last begin %3.7f secs)",
stats().cms_time_since_begin());
} else {
log.print("CMSCollector: collect because of trigger interval (first collection)");
}
return true;
}
}
return false;
}
到底是结果(现象)还是原因,在一次 GC 问题处理的过程中,如何判断是 GC 导致的故障,还是系统本身引发 GC 问题。这里继续拿在本文开头提到的一个 Case:“GC 耗时增大、线程 Block 增多、慢查询增多、CPU 负载高等四个表象,如何判断哪个是根因?”,笔者这里根据自己的经验大致整理了四种判断方法供参考:
-
时序分析: 先发生的事件是根因的概率更大,通过监控手段分析各个指标的异常时间点,还原事件时间线,如先观察到 CPU 负载高(要有足够的时间 Gap),那么整个问题影响链就可能是:CPU 负载高 -> 慢查询增多 -> GC 耗时增大 -> 线程Block增多 -> RT 上涨。
-
概率分析: 使用统计概率学,结合历史问题的经验进行推断,由近到远按类型分析,如过往慢查的问题比较多,那么整个问题影响链就可能是:慢查询增多 -> GC 耗时增大 -> CPU 负载高 -> 线程 Block 增多 -> RT上涨。
-
实验分析: 通过故障演练等方式对问题现场进行模拟,触发其中部分条件(一个或多个),观察是否会发生问题,如只触发线程 Block 就会发生问题,那么整个问题影响链就可能是:线程Block增多 -> CPU 负载高 -> 慢查询增多 -> GC 耗时增大 -> RT 上涨。
-
反证分析: 对其中某一表象进行反证分析,即判断表象的发不发生跟结果是否有相关性,例如我们从整个集群的角度观察到某些节点慢查和 CPU 都正常,但也出了问题,那么整个问题影响链就可能是:GC 耗时增大 -> 线程 Block 增多 -> RT 上涨。
不同的根因,后续的分析方法是完全不同的。如果是 CPU 负载高那可能需要用火焰图看下热点、如果是慢查询增多那可能需要看下 DB 情况、如果是线程 Block 引起那可能需要看下锁竞争的情况,最后如果各个表象证明都没有问题,那可能 GC 确实存在问题,可以继续分析 GC 问题了。
3.3 问题分类导读
3.3.1 Mutator 类型
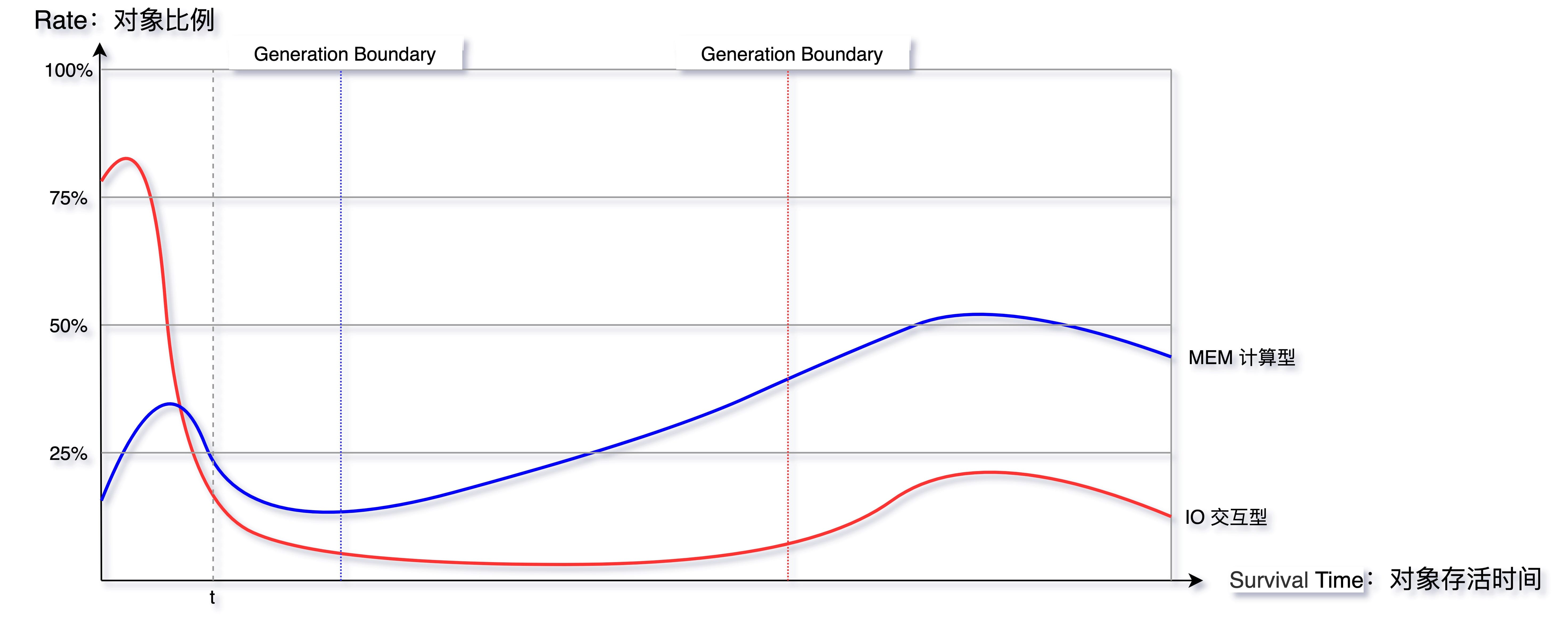
Mutator 的类型根据对象存活时间比例图来看主要分为两种,在弱分代假说中也提到类似的说法,如下图所示 “Survival Time” 表示对象存活时间,“Rate” 表示对象分配比例:
-
IO 交互型: 互联网上目前大部分的服务都属于该类型,例如分布式 RPC、MQ、HTTP 网关服务等,对内存要求并不大,大部分对象在 TP9999 的时间内都会死亡, Young 区越大越好。
-
MEM 计算型: 主要是分布式数据计算 Hadoop,分布式存储 HBase、Cassandra,自建的分布式缓存等,对内存要求高,对象存活时间长,Old 区越大越好。
当然,除了二者之外还有介于两者之间的场景,本篇文章主要讨论第一种情况。对象 Survival Time 分布图,对我们设置 GC 参数有着非常重要的指导意义,如下图就可以简单推算分代的边界。

3.3.2 GC 问题分类
笔者选取了九种不同类型的 GC 问题,覆盖了大部分场景,如果有更好的场景,欢迎在评论区给出。
-
Unexpected GC: 意外发生的 GC,实际上不需要发生,我们可以通过一些手段去避免。
Space Shock: 空间震荡问题,参见“场景一:动态扩容引起的空间震荡”。Explicit GC: 显示执行 GC 问题,参见“场景二:显式 GC 的去与留”。
-
Partial GC: 部分收集操作的 GC,只对某些分代/分区进行回收。
Young GC: 分代收集里面的 Young 区收集动作,也可以叫做 Minor GC。ParNew: Young GC 频繁,参见“场景四:过早晋升”。
Old GC: 分代收集里面的 Old 区收集动作,也可以叫做 Major GC,有些也会叫做 Full GC,但其实这种叫法是不规范的,在 CMS 发生 Foreground GC 时才是 Full GC,CMSScavengeBeforeRemark 参数也只是在 Remark 前触发一次Young GC。- CMS: Old GC 频繁,参见“场景五:CMS Old GC 频繁”。
- CMS: Old GC 不频繁但单次耗时大,参见“场景六:单次 CMS Old GC 耗时长”。
-
Full GC: 全量收集的 GC,对整个堆进行回收,STW 时间会比较长,一旦发生,影响较大,也可以叫做 Major GC,参见“场景七:内存碎片&收集器退化”。
-
MetaSpace: 元空间回收引发问题,参见“场景三:MetaSpace 区 OOM”。
-
Direct Memory: 直接内存(也可以称作为堆外内存)回收引发问题,参见“场景八:堆外内存 OOM”。
-
JNI: 本地 Native 方法引发问题,参见“场景九:JNI 引发的 GC 问题”。
3.3.3 排查难度
一个问题的解决难度跟它的常见程度成反比,大部分我们都可以通过各种搜索引擎找到类似的问题,然后用同样的手段尝试去解决。当一个问题在各种网站上都找不到相似的问题时,那么可能会有两种情况,一种这不是一个问题,另一种就是遇到一个隐藏比较深的问题,遇到这种问题可能就要深入到源码级别去调试了。以下 GC 问题场景,排查难度从上到下依次递增。
4. 常见场景分析与解决
4.1 场景一:动态扩容引起的空间震荡
4.1.1 现象
服务刚刚启动时 GC 次数较多,最大空间剩余很多但是依然发生 GC,这种情况我们可以通过观察 GC 日志或者通过监控工具来观察堆的空间变化情况即可。GC Cause 一般为 Allocation Failure,且在 GC 日志中会观察到经历一次 GC ,堆内各个空间的大小会被调整,如下图所示:

4.1.2 原因
在 JVM 的参数中 -Xms 和 -Xmx 设置的不一致,在初始化时只会初始 -Xms 大小的空间存储信息,每当空间不够用时再向操作系统申请,这样的话必然要进行一次 GC。具体是通过 ConcurrentMarkSweepGeneration::compute_new_size() 方法计算新的空间大小:
void ConcurrentMarkSweepGeneration::compute_new_size() {
assert_locked_or_safepoint(Heap_lock);
// If incremental collection failed, we just want to expand
// to the limit.
if (incremental_collection_failed()) {
clear_incremental_collection_failed();
grow_to_reserved();
return;
}
// The heap has been compacted but not reset yet.
// Any metric such as free() or used() will be incorrect.
CardGeneration::compute_new_size();
// Reset again after a possible resizing
if (did_compact()) {
cmsSpace()->reset_after_compaction();
}
}
-XX:MinHeapFreeRatio 和 -XX:MaxHeapFreeRatio 来控制扩容和缩容的比例,调节这两个值也可以控制伸缩的时机,例如扩容便是使用 GenCollectedHeap::expand_heap_and_allocate() 来完成的,代码如下:
HeapWord* GenCollectedHeap::expand_heap_and_allocate(size_t size, bool is_tlab) {
HeapWord* result = NULL;
if (_old_gen->should_allocate(size, is_tlab)) {
result = _old_gen->expand_and_allocate(size, is_tlab);
}
if (result == NULL) {
if (_young_gen->should_allocate(size, is_tlab)) {
result = _young_gen->expand_and_allocate(size, is_tlab);
}
}
assert(result == NULL || is_in_reserved(result), "result not in heap");
return result;
}
4.1.3 策略
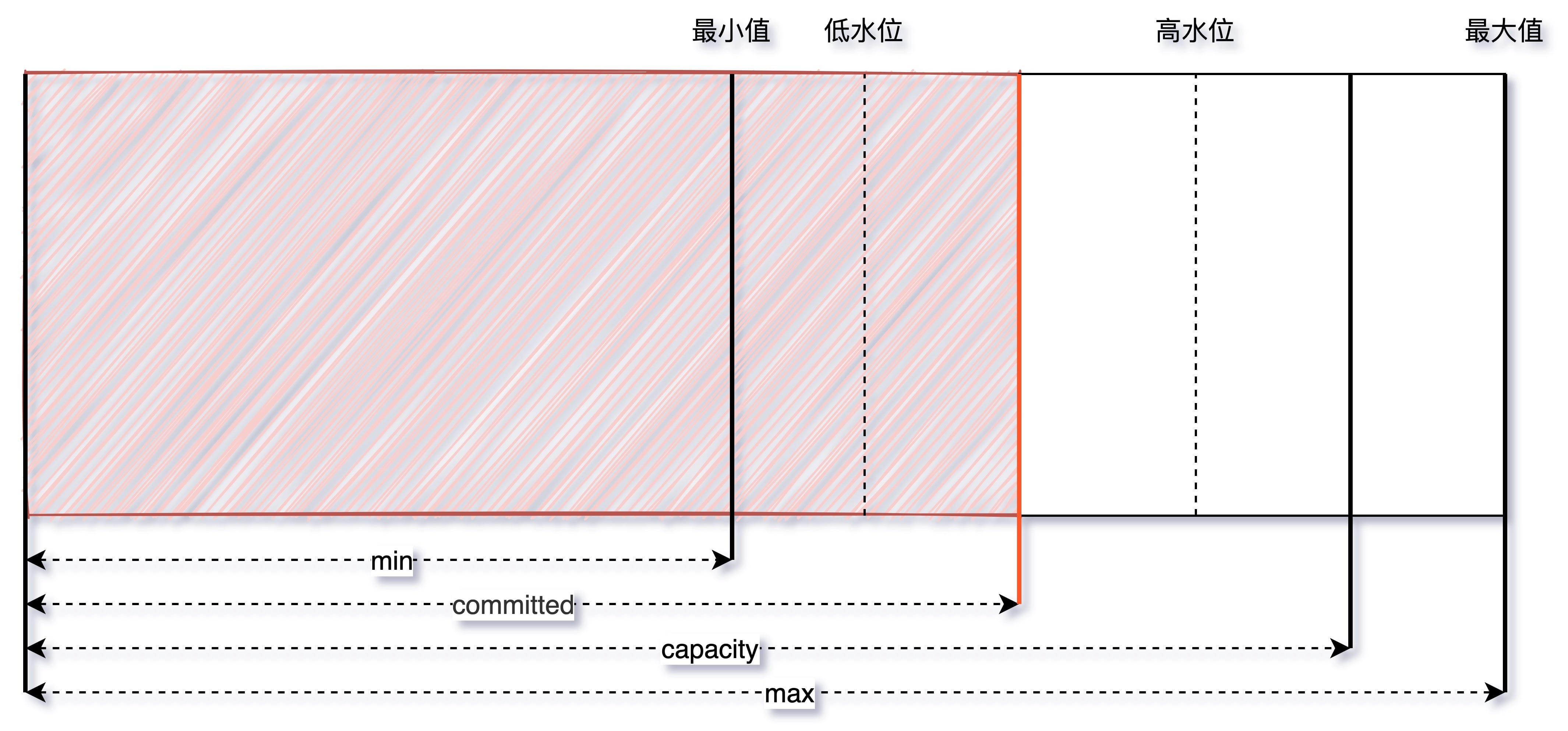
定位:观察 CMS GC 触发时间点 Old/MetaSpace 区的 committed 占比是不是一个固定的值,或者像上文提到的观察总的内存使用率也可以。
解决:尽量将成对出现的空间大小配置参数设置成固定的,如 -Xms 和 -Xmx,-XX:MaxNewSize 和 -XX:NewSize,-XX:MetaSpaceSize 和 -XX:MaxMetaSpaceSize 等。
4.1.4 小结
一般来说,我们需要保证 Java 虚拟机的堆是稳定的,确保 -Xms 和 -Xmx 设置的是一个值(即初始值和最大值一致),获得一个稳定的堆,同理在 MetaSpace 区也有类似的问题。不过在不追求停顿时间的情况下震荡的空间也是有利的,可以动态地伸缩以节省空间,例如作为富客户端的 Java 应用。
这个问题虽然初级,但是发生的概率还真不小,尤其是在一些规范不太健全的情况下。
4.2 场景二:显式 GC 的去与留
4.2.1 现象
除了扩容缩容会触发 CMS GC 之外,还有 Old 区达到回收阈值、MetaSpace 空间不足、Young 区晋升失败、大对象担保失败等几种触发条件,如果这些情况都没有发生却触发了 GC ?这种情况有可能是代码中手动调用了 System.gc 方法,此时可以找到 GC 日志中的 GC Cause 确认下。那么这种 GC 到底有没有问题,翻看网上的一些资料,有人说可以添加 -XX:+DisableExplicitGC 参数来避免这种 GC,也有人说不能加这个参数,加了就会影响 Native Memory 的回收。先说结论,笔者这里建议保留 System.gc,那为什么要保留?我们一起来分析下。
4.2.2 原因
找到 System.gc 在 Hotspot 中的源码,可以发现增加 -XX:+DisableExplicitGC 参数后,这个方法变成了一个空方法,如果没有加的话便会调用 Universe::heap()::collect 方法,继续跟进到这个方法中,发现 System.gc 会引发一次 STW 的 Full GC,对整个堆做收集。
JVM_ENTRY_NO_ENV(void, JVM_GC(void))
JVMWrapper("JVM_GC");
if (!DisableExplicitGC) {
Universe::heap()->collect(GCCause::_java_lang_system_gc);
}
JVM_END
void GenCollectedHeap::collect(GCCause::Cause cause) {
if (cause == GCCause::_wb_young_gc) {
// Young collection for the WhiteBox API.
collect(cause, YoungGen);
} else {
#ifdef ASSERT
if (cause == GCCause::_scavenge_alot) {
// Young collection only.
collect(cause, YoungGen);
} else {
// Stop-the-world full collection.
collect(cause, OldGen);
}
#else
// Stop-the-world full collection.
collect(cause, OldGen);
#endif
}
}
此处补充一个知识点,CMS GC 共分为 Background 和 Foreground 两种模式,前者就是我们常规理解中的并发收集,可以不影响正常的业务线程运行,但 Foreground Collector 却有很大的差异,他会进行一次压缩式 GC。此压缩式 GC 使用的是跟 Serial Old GC 一样的 Lisp2 算法,其使用 Mark-Compact 来做 Full GC,一般称之为 MSC(Mark-Sweep-Compact),它收集的范围是 Java 堆的 Young 区和 Old 区以及 MetaSpace。由上面的算法章节中我们知道 compact 的代价是巨大的,那么使用 Foreground Collector 时将会带来非常长的 STW。如果在应用程序中 System.gc 被频繁调用,那就非常危险了。
去掉 System.gc
如果禁用掉的话就会带来另外一个内存泄漏问题,此时就需要说一下 DirectByteBuffer,它有着零拷贝等特点,被 Netty 等各种 NIO 框架使用,会使用到堆外内存。堆内存由 JVM 自己管理,堆外内存必须要手动释放,DirectByteBuffer 没有 Finalizer,它的 Native Memory 的清理工作是通过 sun.misc.Cleaner 自动完成的,是一种基于 PhantomReference 的清理工具,比普通的 Finalizer 轻量些。
为 DirectByteBuffer 分配空间过程中会显式调用 System.gc ,希望通过 Full GC 来强迫已经无用的 DirectByteBuffer 对象释放掉它们关联的 Native Memory,下面为代码实现:
// These methods should be called whenever direct memory is allocated or
// freed. They allow the user to control the amount of direct memory
// which a process may access. All sizes are specified in bytes.
static void reserveMemory(long size) {
synchronized (Bits.class) {
if (!memoryLimitSet && VM.isBooted()) {
maxMemory = VM.maxDirectMemory();
memoryLimitSet = true;
}
if (size <= maxMemory - reservedMemory) {
reservedMemory += size;
return;
}
}
System.gc();
try {
Thread.sleep(100);
} catch (InterruptedException x) {
// Restore interrupt status
Thread.currentThread().interrupt();
}
synchronized (Bits.class) {
if (reservedMemory + size > maxMemory)
throw new OutOfMemoryError("Direct buffer memory");
reservedMemory += size;
}
}
4.2.3 策略
通过上面的分析看到,无论是保留还是去掉都会有一定的风险点,不过目前互联网中的 RPC 通信会大量使用 NIO,所以笔者在这里建议保留。此外 JVM 还提供了 -XX:+ExplicitGCInvokesConcurrent 和 -XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses 参数来将 System.gc 的触发类型从 Foreground 改为 Background,同时 Background 也会做 Reference Processing,这样的话就能大幅降低了 STW 开销,同时也不会发生 NIO Direct Memory OOM。
4.2.4 小结
不止 CMS,在 G1 或 ZGC中开启 ExplicitGCInvokesConcurrent 模式,都会采用高性能的并发收集方式进行收集,不过还是建议在代码规范方面也要做好约束,规范好 System.gc 的使用。
P.S. HotSpot 对 System.gc 有特别处理,最主要的地方体现在一次 System.gc 是否与普通 GC 一样会触发 GC 的统计/阈值数据的更新,HotSpot 里的许多 GC 算法都带有自适应的功能,会根据先前收集的效率来决定接下来的 GC 中使用的参数,但 System.gc 默认不更新这些统计数据,避免用户强行 GC 对这些自适应功能的干扰(可以参考
-XX:+UseAdaptiveSizePolicyWithSystemGC参数,默认是 false)。

- 点赞
- 收藏
- 关注作者
评论(0)