MyBatis详解 - sqlSession执行流程

前面的章节主要讲mybatis如何解析配置文件,这些都是一次性的过程。从本章开始讲解动态的过程,它们跟应用程序对mybatis的调用密切相关
sqlSessionFactory 与 SqlSession
通过前面的章节对于mybatis 的介绍及使用,大家都能体会到SqlSession的重要性了吧,没错,从表面上来看,咱们都是通过SqlSession去执行sql语句(注意:是从表面看,实际的待会儿就会讲)。
正如其名,Sqlsession对应着一次数据库会话。由于数据库会话不是永久的,因此Sqlsession的生命周期也不应该是永久的,相反,在你每次访问数据库时都需要创建它(当然并不是说在Sqlsession里只能执行一次sql,你可以执行多次,当一旦关闭了Sqlsession就需要重新创建它)。
那么咱们就先看看是怎么获取SqlSession的吧:

首先,SqlSessionFactoryBuilder去读取mybatis的配置文件,然后build一个DefaultSqlSessionFactory。源码如下:
/**
* 一系列的构造方法最终都会调用本方法(配置文件为Reader时会调用本方法,还有一个InputStream方法与此对应)
* @param reader
* @param environment
* @param properties
* @return
*/
public SqlSessionFactory build(Reader reader, String environment, Properties properties) {
try {
//通过XMLConfigBuilder解析配置文件,解析的配置相关信息都会封装为一个Configuration对象
XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties);
//这儿创建DefaultSessionFactory对象
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
reader.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
/**
* 通常一系列openSession方法最终都会调用本方法
* @param execType
* @param level
* @param autoCommit
* @return
*/
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
//通过Confuguration对象去获取Mybatis相关配置信息, Environment对象包含了数据源和事务的配置
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
//之前说了,从表面上来看,咱们是用sqlSession在执行sql语句, 实际呢,其实是通过excutor执行, excutor是对于Statement的封装
final Executor executor = configuration.newExecutor(tx, execType);
//关键看这儿,创建了一个DefaultSqlSession对象
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
通过以上步骤,咱们已经得到SqlSession对象了。接下来就是该干嘛干嘛去了(话说还能干嘛,当然是执行sql语句咯)。看了上面,咱们也回想一下之前写的Demo:
SqlSessionFactory sessionFactory = null;
String resource = "mybatis-conf.xml";
try {
//SqlSessionFactoryBuilder读取配置文件
sessionFactory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsReader(resource));
} catch (IOException e) {
e.printStackTrace();
}
//通过SqlSessionFactory获取SqlSession
SqlSession sqlSession = sessionFactory.openSession();
public SqlSessionopenSession() {
return openSessionFromDataSource(configuration.getDefaultExecutorType(),null, false);
}
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Connection connection = null;
try {
final Environment environment = configuration.getEnvironment();
final DataSource dataSource = getDataSourceFromEnvironment(environment);
// MyBatis对事务的处理相对简单,TransactionIsolationLevel中定义了几种隔离级别,并不支持内嵌事务这样较复杂的场景,同时由于其是持久层的缘故,所以真正在应用开发中会委托Spring来处理事务实现真正的与开发者隔离。分析事务的实现是个入口,借此可以了解不少JDBC规范方面的事情。
TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
connection = dataSource.getConnection();
if (level != null) {
connection.setTransactionIsolation(level.getLevel());
}
connection = wrapConnection(connection);
Transaction tx = transactionFactory.newTransaction(connection,autoCommit);
Executorexecutor = configuration.newExecutor(tx, execType);
return newDefaultSqlSession(configuration, executor, autoCommit);
} catch (Exceptione) {
closeConnection(connection);
throwExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
-
从配置中获取Environment;
-
从Environment中取得DataSource;
-
从Environment中取得TransactionFactory;
-
从DataSource里获取数据库连接对象Connection;
-
在取得的数据库连接上创建事务对象Transaction;
-
创建Executor对象(该对象非常重要,事实上sqlsession的所有操作都是通过它完成的);
-
创建sqlsession对象。
SqlSession咱们也拿到了,咱们可以调用SqlSession中一系列的select..., insert..., update..., delete...方法轻松自如的进行CRUD操作了。就这样?那咱配置的映射文件去哪儿了?别急,咱们接着往下看。
利器之MapperProxy
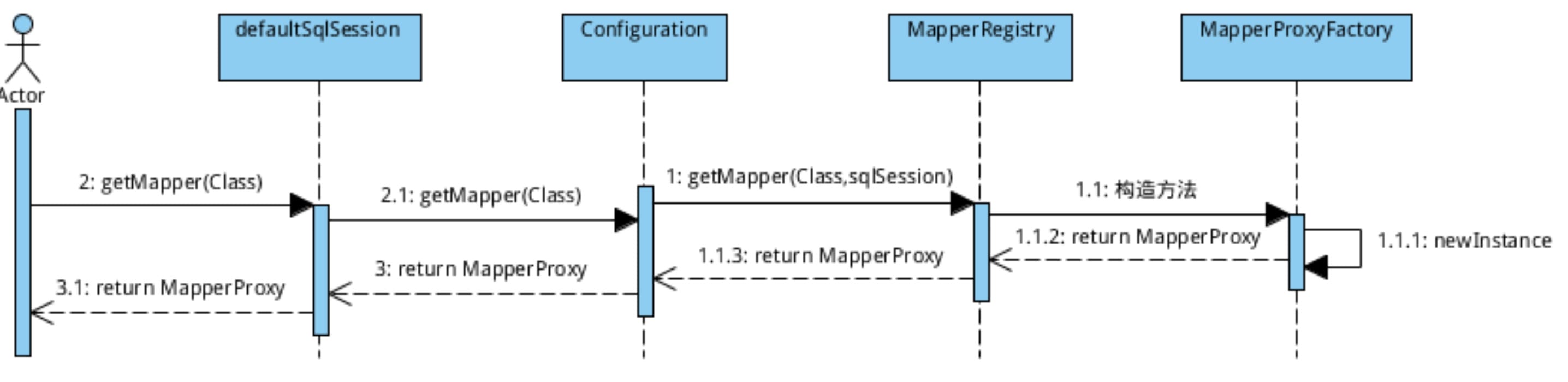
在mybatis中,通过MapperProxy动态代理咱们的dao, 也就是说, 当咱们执行自己写的dao里面的方法的时候,其实是对应的mapperProxy在代理。那么,咱们就看看怎么获取MapperProxy对象吧:
通过SqlSession从Configuration中获取。源码如下:
/**
* 什么都不做,直接去configuration中找, 哥就是这么任性
*/
@Override
public <T> T getMapper(Class<T> type) {
return configuration.<T>getMapper(type, this);
}
SqlSession把包袱甩给了Configuration, 接下来就看看Configuration。源码如下:
/**
* 烫手的山芋,俺不要,你找mapperRegistry去要
* @param type
* @param sqlSession
* @return
*/
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}
Configuration不要这烫手的山芋,接着甩给了MapperRegistry, 那咱看看MapperRegistry。 源码如下:
/**
* 烂活净让我来做了,没法了,下面没人了,我不做谁来做
* @param type
* @param sqlSession
* @return
*/
@SuppressWarnings("unchecked")
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
//能偷懒的就偷懒,俺把粗活交给MapperProxyFactory去做
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
//关键在这儿
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
/**
* 别人虐我千百遍,我待别人如初恋
* @param mapperProxy
* @return
*/
@SuppressWarnings("unchecked")
protected T newInstance(MapperProxy<T> mapperProxy) {
//动态代理我们写的dao接口
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<T>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
UserDao userMapper = sqlSession.getMapper(UserDao.class);
User insertUser = new User();
这下方便多了吧, 呵呵, 貌似mybatis的源码就这么一回事儿啊。具体详细介绍,请参见MyBatis Mapper 接口如何通过JDK动态代理来包装SqlSession 源码分析。别急,还没完, 咱们还没看具体是怎么执行sql语句的呢。
Excutor
Executor与Sqlsession的关系就像市长与书记,Sqlsession只是个门面,真正干事的是Executor,Sqlsession对数据库的操作都是通过Executor来完成的。与Sqlsession一样,Executor也是动态创建的:

- Executor创建的源代码:
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ?ExecutorType.SIMPLE : executorType;
Executor executor;
if(ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this,transaction);
} else if(ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this,transaction);
} else {
executor = newSimpleExecutor(this, transaction);
}
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
Executor对象是可以被插件拦截的,如果定义了针对Executor类型的插件,最终生成的Executor对象是被各个插件插入后的代理对象。
接下来,咱们才要真正去看sql的执行过程了。上面,咱们拿到了MapperProxy, 每个MapperProxy对应一个dao接口, 那么咱们在使用的时候,MapperProxy是怎么做的呢? 源码奉上:
- MapperProxy
我们知道对被代理对象的方法的访问都会落实到代理者的invoke上来,MapperProxy的invoke如下:
/**
* MapperProxy在执行时会触发此方法
*/
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (Object.class.equals(method.getDeclaringClass())) {
try {
return method.invoke(this, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
final MapperMethod mapperMethod = cachedMapperMethod(method);
//二话不说,主要交给MapperMethod自己去管
return mapperMethod.execute(sqlSession, args);
}
- MapperMethod
就像是一个分发者,他根据参数和返回值类型选择不同的sqlsession方法来执行。这样mapper对象与sqlsession就真正的关联起来了。
/**
* 看着代码不少,不过其实就是先判断CRUD类型,然后根据类型去选择到底执行sqlSession中的哪个方法,绕了一圈,又转回sqlSession了
* @param sqlSession
* @param args
* @return
*/
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
if (SqlCommandType.INSERT == command.getType()) {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
} else if (SqlCommandType.UPDATE == command.getType()) {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
} else if (SqlCommandType.DELETE == command.getType()) {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
} else if (SqlCommandType.SELECT == command.getType()) {
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
}
} else {
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
//CRUD实际上是交给Excetor去处理, excutor其实也只是穿了个马甲而已,小样,别以为穿个马甲我就不认识你嘞!
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
- CacheExecutor
CacheExecutor有一个重要属性delegate,它保存的是某类普通的Executor,值在构照时传入。执行数据库update操作时,它直接调用delegate的update方法,执行query方法时先尝试从cache中取值,取不到再调用delegate的查询方法,并将查询结果存入cache中。代码如下:
public List query(MappedStatement ms, Object parameterObject, RowBounds rowBounds,ResultHandler resultHandler) throws SQLException {
if (ms != null) {
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
cache.getReadWriteLock().readLock().lock();
try {
if (ms.isUseCache() && resultHandler ==null) {
CacheKey key = createCacheKey(ms, parameterObject, rowBounds);
final List cachedList = (List)cache.getObject(key);
if (cachedList != null) {
return cachedList;
} else {
List list = delegate.query(ms,parameterObject, rowBounds, resultHandler);
tcm.putObject(cache,key, list);
return list;
}
} else {
return delegate.query(ms,parameterObject, rowBounds, resultHandler);
}
} finally {
cache.getReadWriteLock().readLock().unlock();
}
}
}
return delegate.query(ms,parameterObject, rowBounds, resultHandler);
}
- 普通Executor
有3类,他们都继承于BaseExecutor,BatchExecutor专门用于执行批量sql操作,ReuseExecutor会重用statement执行sql操作,SimpleExecutor只是简单执行sql没有什么特别的。下面以SimpleExecutor为例:
public List doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds,ResultHandler resultHandler) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(this, ms,parameter, rowBounds,resultHandler);
stmt =prepareStatement(handler);
returnhandler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
//StatementHandler封装了Statement, 让 StatementHandler 去处理
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
但batch模式也有自己的问题,比如在Insert操作时,在事务没有提交之前,是没有办法获取到自增的id,这在某型情形下是不符合业务要求的;
通过走码和研读spring相关文件发现,在同一事务中batch模式和simple模式之间无法转换,由于本项目一开始选择了simple模式,所以碰到需要批量更新时,只能在单独的事务中进行;
在代码中使用batch模式可以使用以下方式:
//从spring注入原有的sqlSessionTemplate
@Autowired
private SqlSessionTemplate sqlSessionTemplate;
public void testInsertBatchByTrue() {
//新获取一个模式为BATCH,自动提交为false的session
//如果自动提交设置为true,将无法控制提交的条数,改为最后统一提交,可能导致内存溢出
SqlSession session = sqlSessionTemplate.getSqlSessionFactory().openSession(ExecutorType.BATCH, false);
//通过新的session获取mapper
fooMapper = session.getMapper(FooMapper.class);
int size = 10000;
try {
for (int i = 0; i < size; i++) {
Foo foo = new Foo();
foo.setName(String.valueOf(System.currentTimeMillis()));
fooMapper.insert(foo);
if (i % 1000 == 0 || i == size - 1) {
//手动每1000个一提交,提交后无法回滚
session.commit();
//清理缓存,防止溢出
session.clearCache();
}
}
} catch (Exception e) {
//没有提交的数据可以回滚
session.rollback();
} finally {
session.close();
}
}
StatementHandler
可以看出,Executor本质上也是个甩手掌柜,具体的事情原来是StatementHandler来完成的。当Executor将指挥棒交给StatementHandler后,接下来的工作就是StatementHandler的事了。我们先看看StatementHandler是如何创建的:
public StatementHandler newStatementHandler(Executor executor, MappedStatementmappedStatement,
ObjectparameterObject, RowBounds rowBounds, ResultHandler resultHandler) {
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement,parameterObject,rowBounds, resultHandler);
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
StatementHandler创建后需要执行一些初始操作,比如statement的开启和参数设置、对于PreparedStatement还需要执行参数的设置操作等。代码如下:
private Statement prepareStatement(StatementHandler handler) throws SQLException {
Statement stmt;
Connection connection = transaction.getConnection();
stmt =handler.prepare(connection);
handler.parameterize(stmt);
return stmt;
}
public ParameterHandler newParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {
ParameterHandler parameterHandler = new DefaultParameterHandler(mappedStatement,parameterObject,boundSql);
parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);
return parameterHandler;
}
public void setParameters(PreparedStatement ps) throws SQLException {
ErrorContext.instance().activity("settingparameters").object(mappedStatement.getParameterMap().getId());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if(parameterMappings != null) {
MetaObject metaObject = parameterObject == null ? null :configuration.newMetaObject(parameterObject);
for (int i = 0; i< parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
if(parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
PropertyTokenizer prop = newPropertyTokenizer(propertyName);
if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())){
value = parameterObject;
} else if (boundSql.hasAdditionalParameter(propertyName)){
value = boundSql.getAdditionalParameter(propertyName);
} else if(propertyName.startsWith(ForEachSqlNode.ITEM_PREFIX)
&& boundSql.hasAdditionalParameter(prop.getName())){
value = boundSql.getAdditionalParameter(prop.getName());
if (value != null) {
value = configuration.newMetaObject(value).getValue(propertyName.substring(prop.getName().length()));
}
} else {
value = metaObject == null ? null :metaObject.getValue(propertyName);
}
TypeHandler typeHandler = parameterMapping.getTypeHandler();
if (typeHandler == null) {
throw new ExecutorException("Therewas no TypeHandler found for parameter " + propertyName + " of statement " + mappedStatement.getId());
}
typeHandler.setParameter(ps, i + 1, value,parameterMapping.getJdbcType());
}
}
}
}
this.boundSql= mappedStatement.getBoundSql(parameterObject);
参数设置完毕后,执行数据库操作(update或query)。如果是query最后还有个查询结果的处理过程。
接下来,咱们看看StatementHandler 的一个实现类 PreparedStatementHandler(这也是我们最常用的,封装的是PreparedStatement), 看看它使怎么去处理的:
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
// 到此,原形毕露, PreparedStatement, 这个大家都已经滚瓜烂熟了吧
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
// 结果交给了ResultSetHandler 去处理
return resultSetHandler.<E> handleResultSets(ps);
}
public ResultSetHandler newResultSetHandler(Executor executor, MappedStatement mappedStatement,
RowBounds rowBounds, ParameterHandler parameterHandler, ResultHandler resultHandler, BoundSql boundSql) {
ResultSetHandler resultSetHandler = mappedStatement.hasNestedResultMaps() ? newNestedResultSetHandler(executor, mappedStatement, parameterHandler, resultHandler, boundSql, rowBounds): new FastResultSetHandler(executor,mappedStatement, parameterHandler, resultHandler, boundSql, rowBounds);
resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler);
return resultSetHandler;
}
protected boolean applyAutomaticMappings(ResultSet rs, List<String> unmappedColumnNames,MetaObject metaObject) throws SQLException {
boolean foundValues = false;
for (String columnName : unmappedColumnNames) {
final String property = metaObject.findProperty(columnName);
if (property!= null) {
final ClasspropertyType =metaObject.getSetterType(property);
if (typeHandlerRegistry.hasTypeHandler(propertyType)) {
final TypeHandler typeHandler = typeHandlerRegistry.getTypeHandler(propertyType);
final Object value = typeHandler.getResult(rs,columnName);
if (value != null) {
metaObject.setValue(property, value);
foundValues = true;
}
}
}
}
return foundValues;
}

- 点赞
- 收藏
- 关注作者
评论(0)