ModelArts Pro实现文本分类并分析【玩转华为云】

主要内容有:
- 一 ModelArts工具有啥用
- 二 先做好准备工作
- 三 模型训练与评估
- 四 模型开始训练
- 五 如何删除应用呢

一 ModelArts工具有啥用
1.1 如何定义的
它是面向开发者的一站式AI平台,目的是给机器与深度学习提供海量数据预处理及交互式智能标注、大规模分布式训练、自动化模型生成,及端-边-云模型按需部署能力;

1.2 解释下先
“一站式”是指AI开发的各个环节,包括数据处理、算法开发、模型训练、模型部署都可以在ModelArts上完成。从技术上看,ModelArts底层支持各种异构计算资源,开发者可以根据需要灵活选择使用,而不需要关心底层的技术。同时,ModelArts支持Tensorflow、PyTorch、MindSpore等主流开源的AI开发框架,也支持开发者使用自研的算法框架,匹配您的使用习惯。
ModelArts的理念就是让AI开发变得更简单、更方便。
面向不同经验的AI开发者,提供便捷易用的使用流程。例如,面向业务开发者,不需关注模型或编码,可使用自动学习流程快速构建AI应用;面向AI初学者,不需关注模型开发,使用预置算法构建AI应用;面向AI工程师,提供多种开发环境,多种操作流程和模式,方便开发者编码扩展,快速构建模型及应用。
1.3 产品结构是什么
ModelArts是一个一站式的开发平台,能够支撑开发者从数据到AI应用的全流程开发过程。包含数据处理、模型训练、模型管理、模型部署等操作,并且提供AI Gallery功能,能够在市场内与其他开发者分享模型。
ModelArts支持应用到图像分类、物体检测、视频分析、语音识别、产品推荐、异常检测等多种AI应用场景
1.4 产品有什么优势
- 一站式
开“箱”即用,涵盖AI开发全流程,包含数据处理、模型开发、训练、管理、部署功能,可灵活使用其中一个或多个功能。
- 易上手
- 提供多种预置模型,开源模型想用就用。
- 模型超参自动优化,简单快速。
- 零代码开发,简单操作训练出自己的模型。
- 支持模型一键部署到云、边、端。
- 高性能
- 自研MoXing深度学习框架,提升算法开发效率和训练速度。
- 优化深度模型推理中GPU的利用率,加速云端在线推理。
- 可生成在Ascend芯片上运行的模型,实现高效端边推理。
- 灵活
- 支持多种主流开源框架(TensorFlow、PyTorch、MindSpore等)。
- 支持主流GPU芯片。
- 支持Ascend芯片。
- 支持专属资源独享使用。
- 支持自定义镜像满足自定义框架及算子需求。
二 先做好准备工作
2.1 先准备好数据
进入控制台,将光标移动至左边栏,弹出菜单中选择“服务列表”->“存储”->“对象存储服务OBS”,如下图
点击“创建桶”按钮进入创建界面
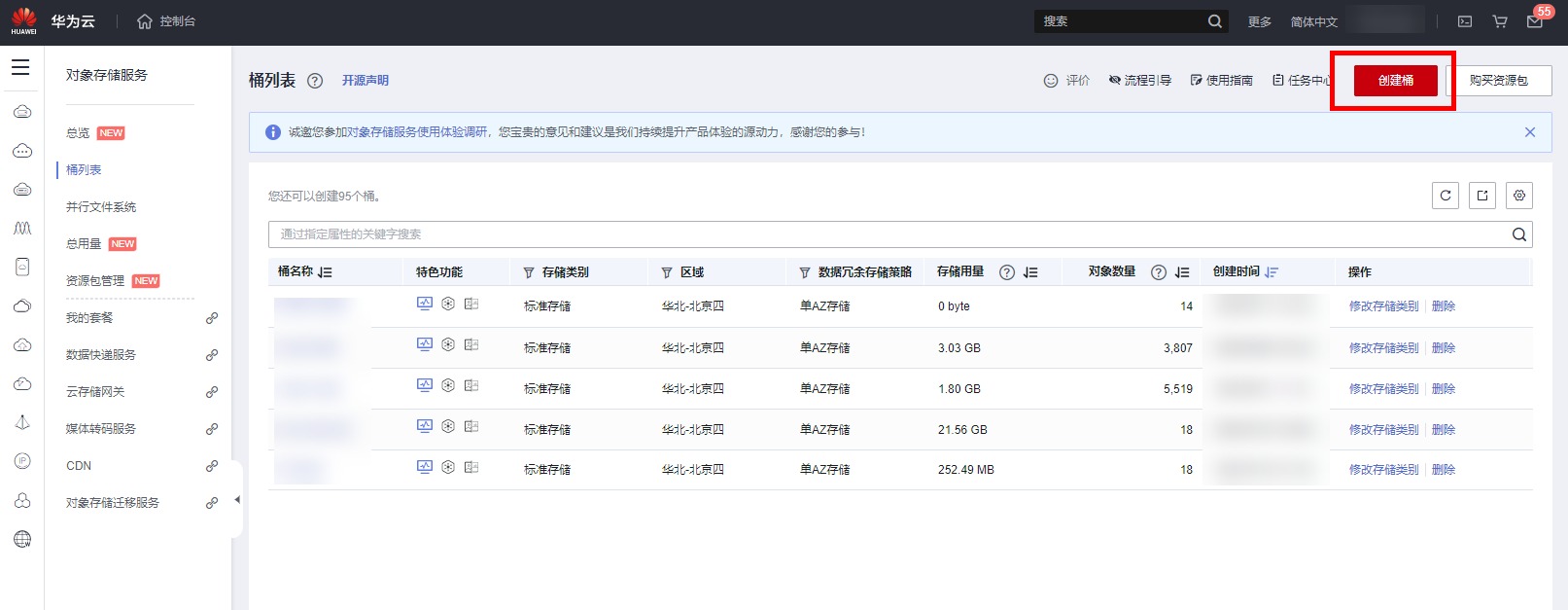
开始创建。配置参数如下:
① 复制桶配置:不选
② 区域:华北-北京四
③ 桶名称:自定义,将在后续步骤使用
④ 数据冗余存储策略:单AZ存储
⑤ 默认存储类别:标准存储
⑥ 桶策略:私有
⑦ 默认加密:关闭
⑧ 归档数据直读:关闭
单击“立即创建”>“确定”,完成桶创建。
点击创建的“桶名称”->“对象”->“新建文件夹”,创建两个文件夹,分明命名input,output,用于存放后续数据集的输入和输出。
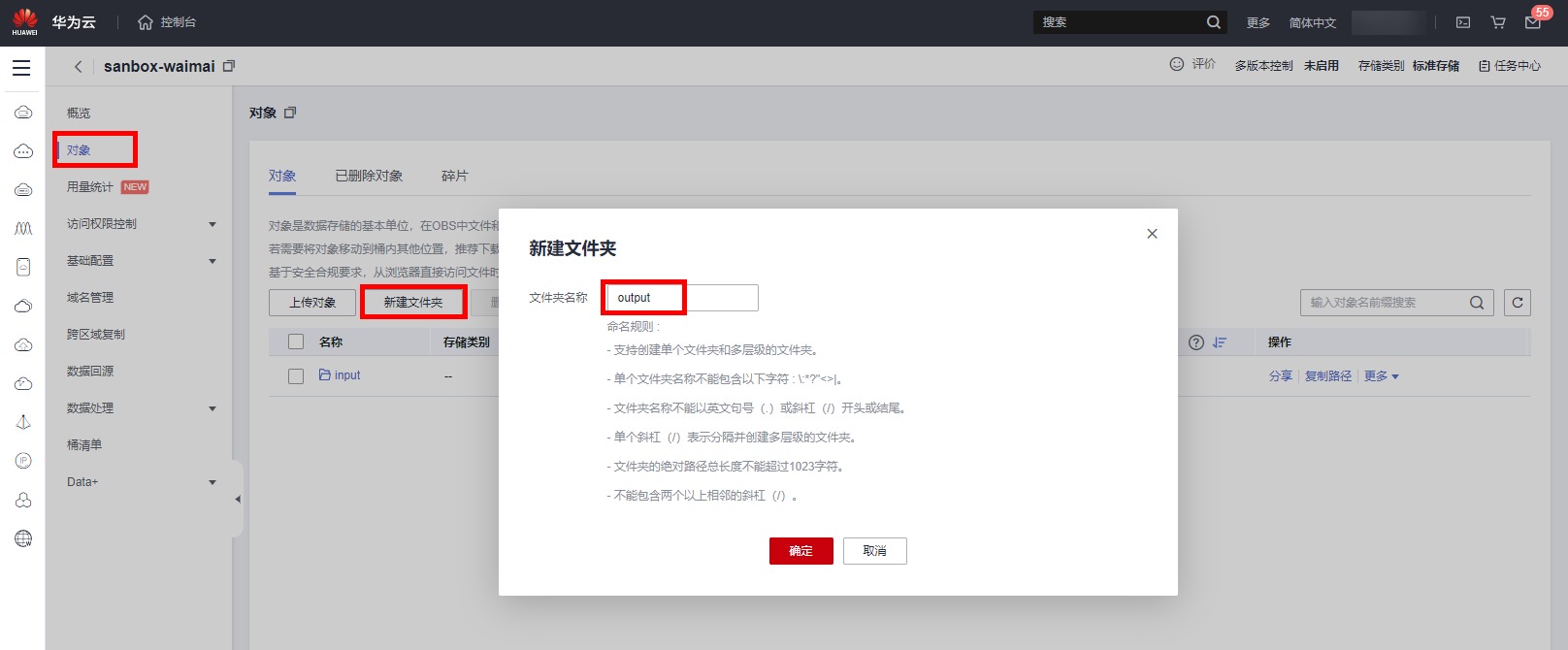
本实验准备了一份标注了的外卖评论语料,语料分正负样本:1表示好评,0表示差评。每行一条数据,文本和标签之间用制表符隔开
语料下载URL:
https://sandbox-expriment-files.obs.cn-north-1.myhuaweicloud.com:443/20221019/waimai_10_mapro.csv
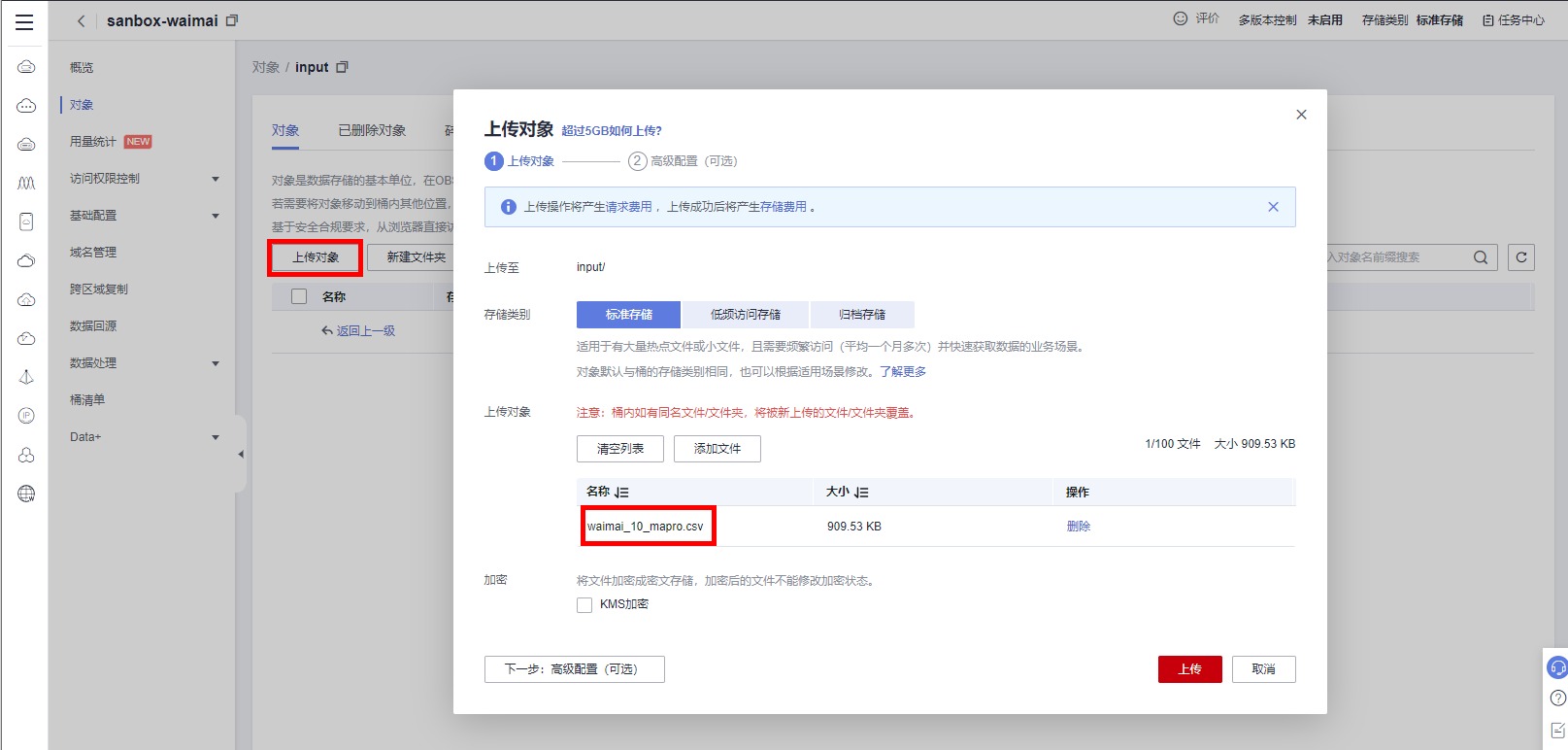
请在右侧浏览器中,新建标签页,输入如上URL,下载语料。下载完语料之后,点击进入input文件夹
点击“上传对象”,在/home/user/Downloads/路径下,选择已下载的外卖评论语料waimai_10_mapro.csv,点击“上传”,完成对象上传,如下图
2.2 新建应用
点击控制台页面,点击左上角服务列表按钮,下拉找到【人工智能】,再找到【ModelArts pro】,点击进入,如下图
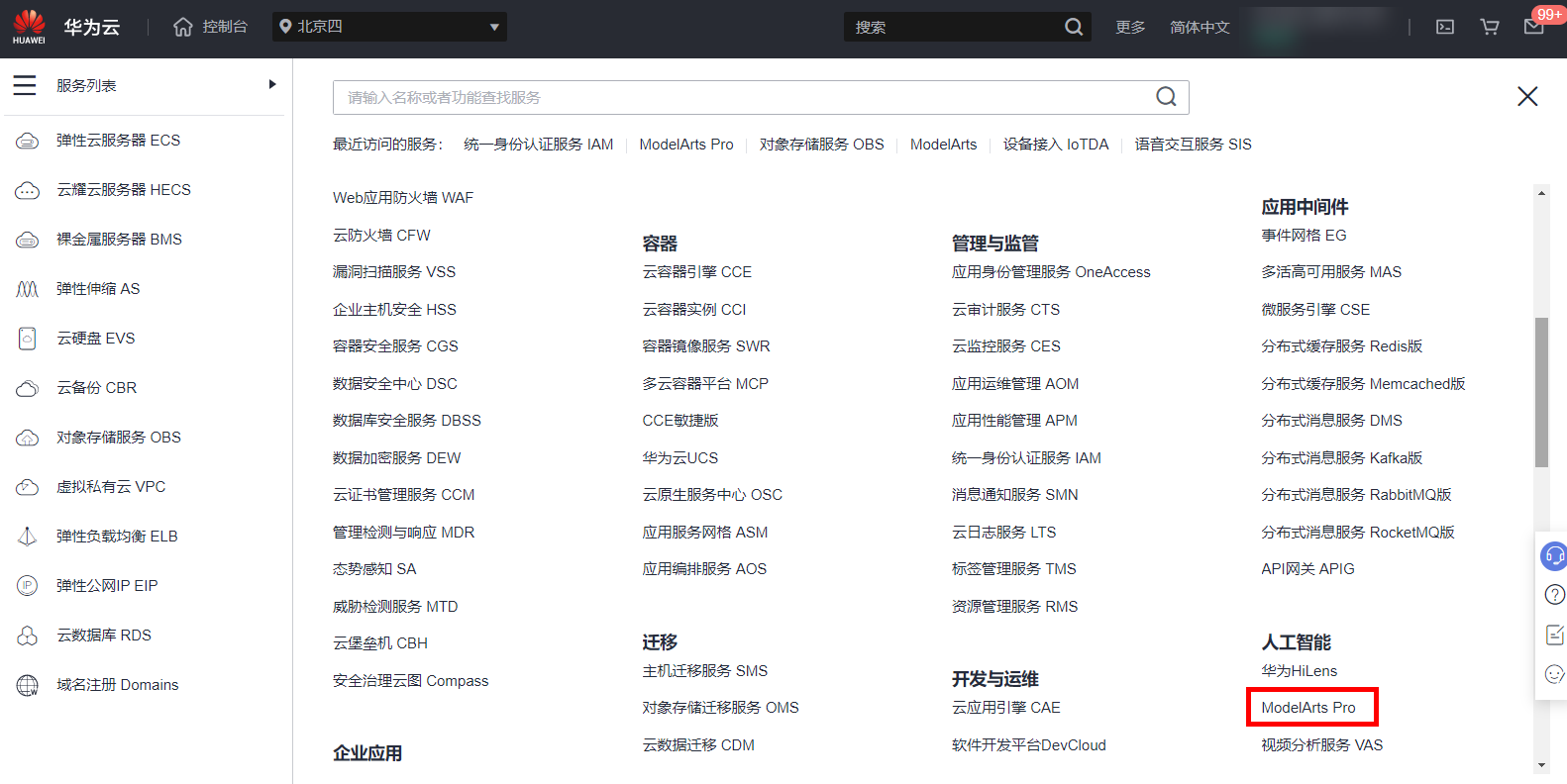
进入ModelArts Pro平台地址,选择自然语言处理套件,点击“进入套件”
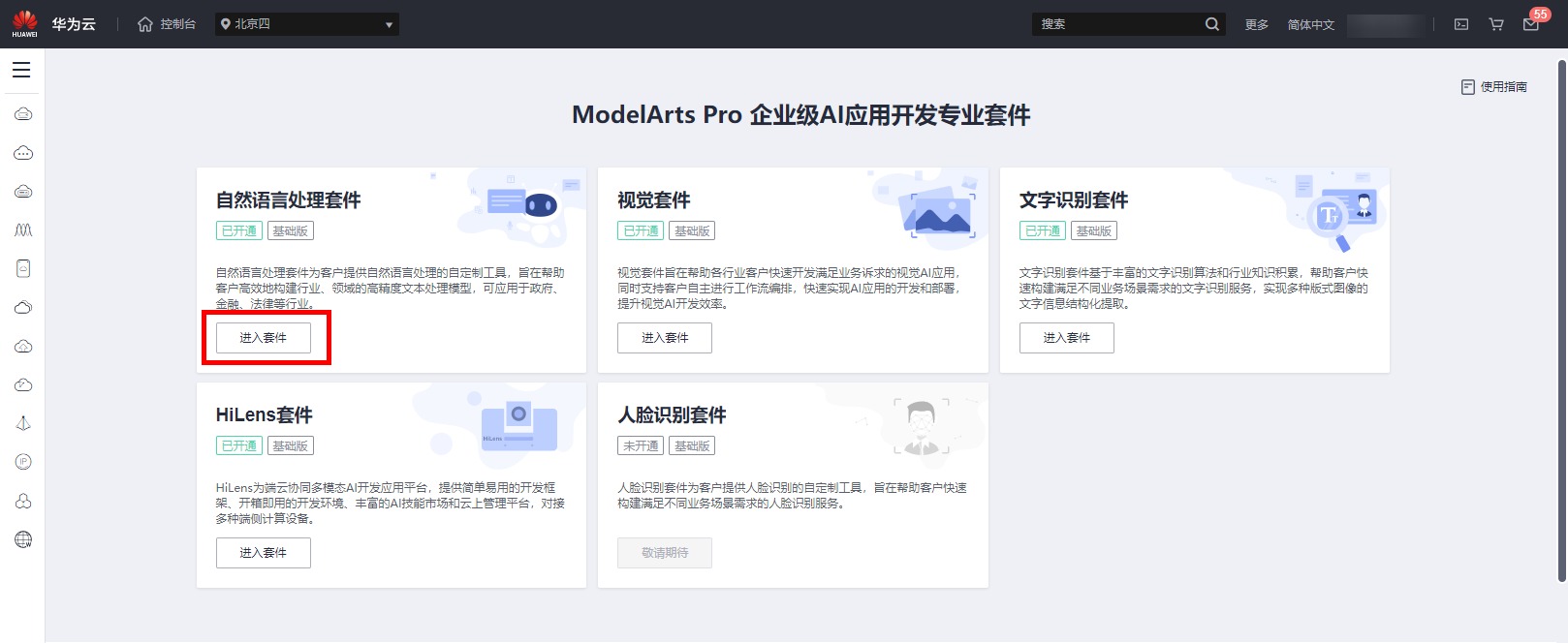
勾选ModelArts服务声明,同意访问授权
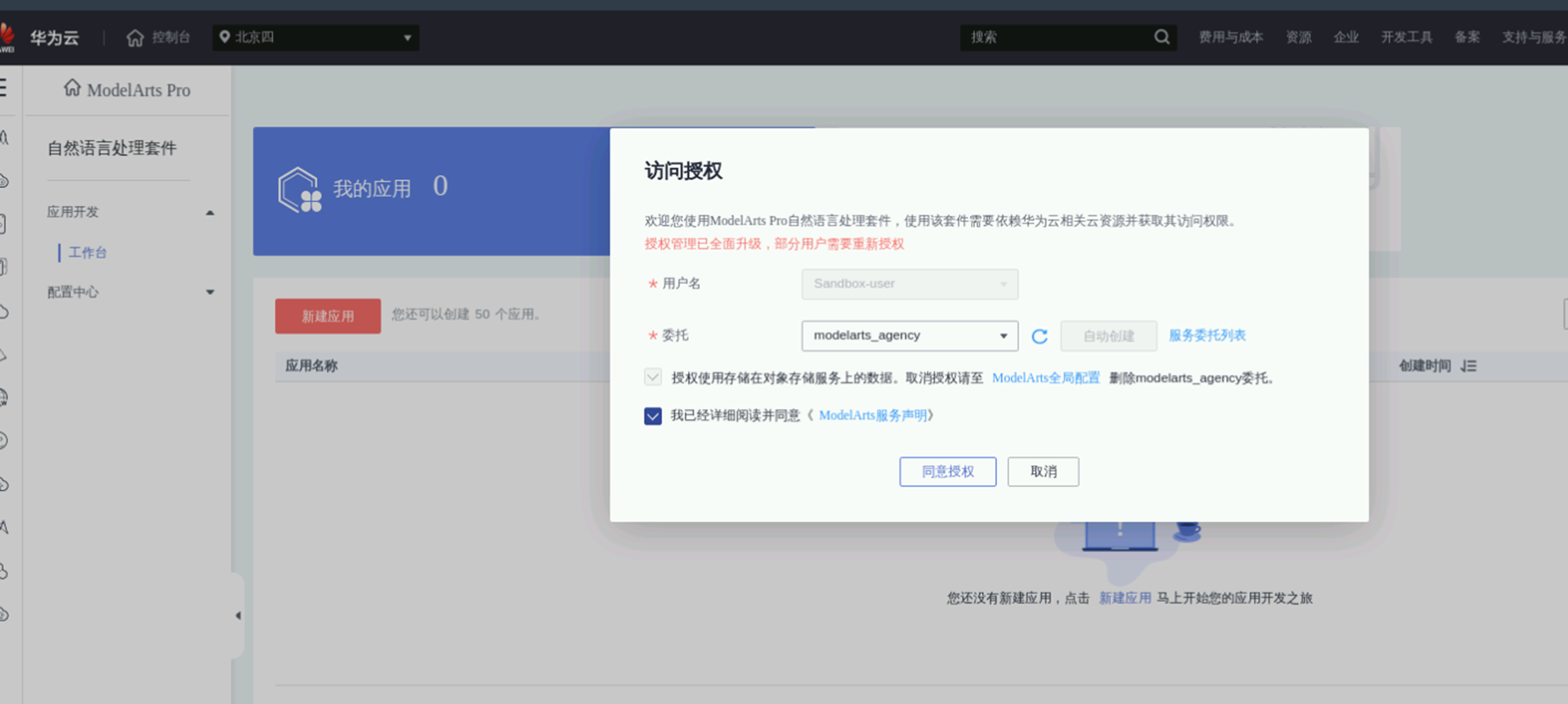
进入应用开发工作台,切换到我的工作流。选择通用文本分类工作流,点击“新建应用”
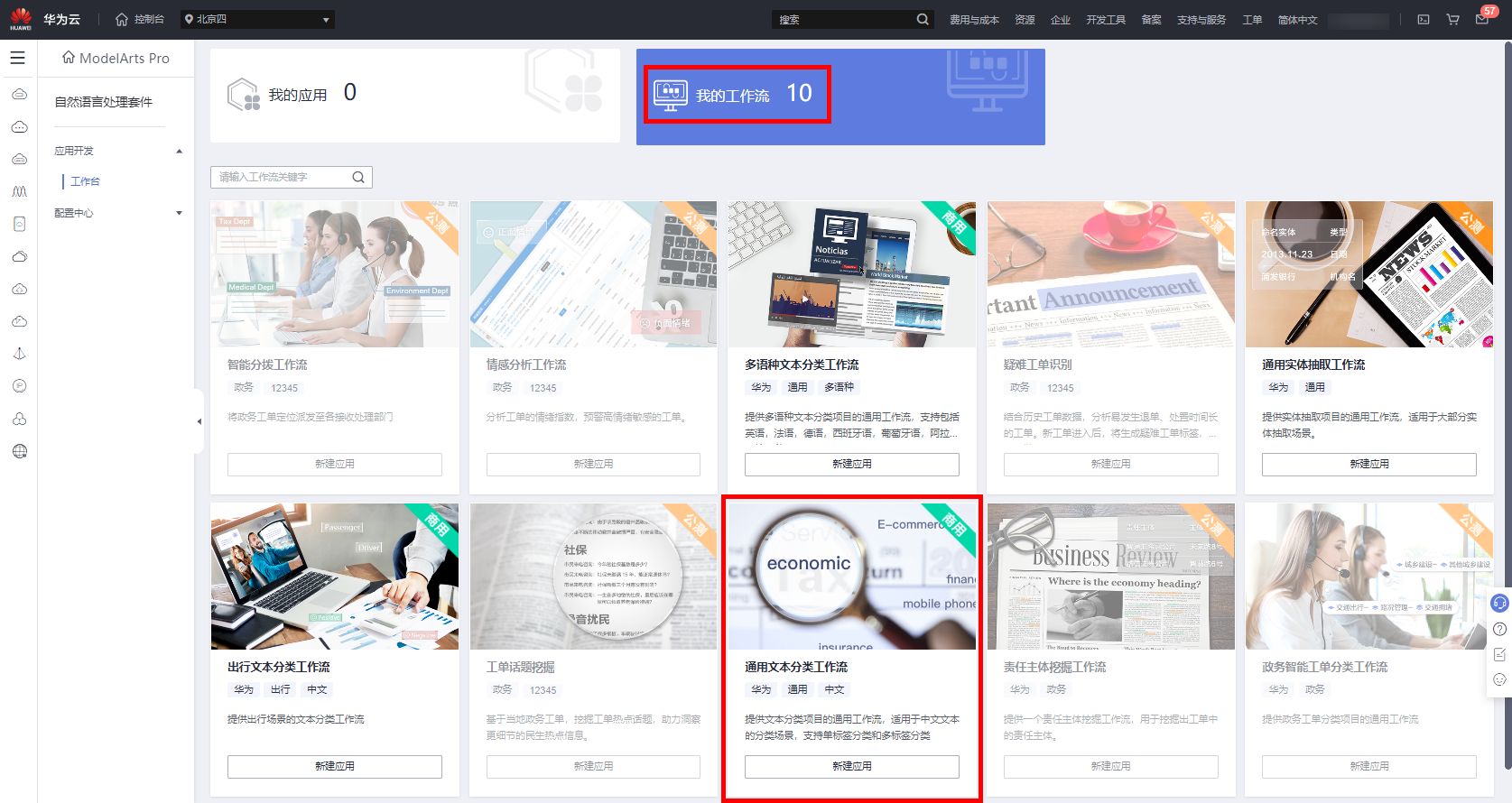
进入新建应用页面。信息填写如下所示,
应用名称:自定义,如waimai;
所属行业:通用;
选择工作流:通用文本分类工作流;
数据处理资源:公共资源池,CPU : 2核8GiB;
模型训练资源:公共资源池,GPU : 1* NVIDIA-V100 32 GPU | CPU :8核 64GiB;
模型部署资源:自然语言处理套件-基础版-计算型CPU实例;
部署方式:在线部署;
点击“确认”,完成工作流及资源的配置。
3.3 然后是数据选择
进入数据选择页面,点击新建数据集,信息填写如下
数据集名称:dataset-waimai;
数据集输入位置:选择已创建的OBS input文件夹路径;
输出位置:选择output文件夹路径;
数据标注状态:选择已标注;
文本与标签分隔符:默认Tab;
多标签分隔符:默认分号即可
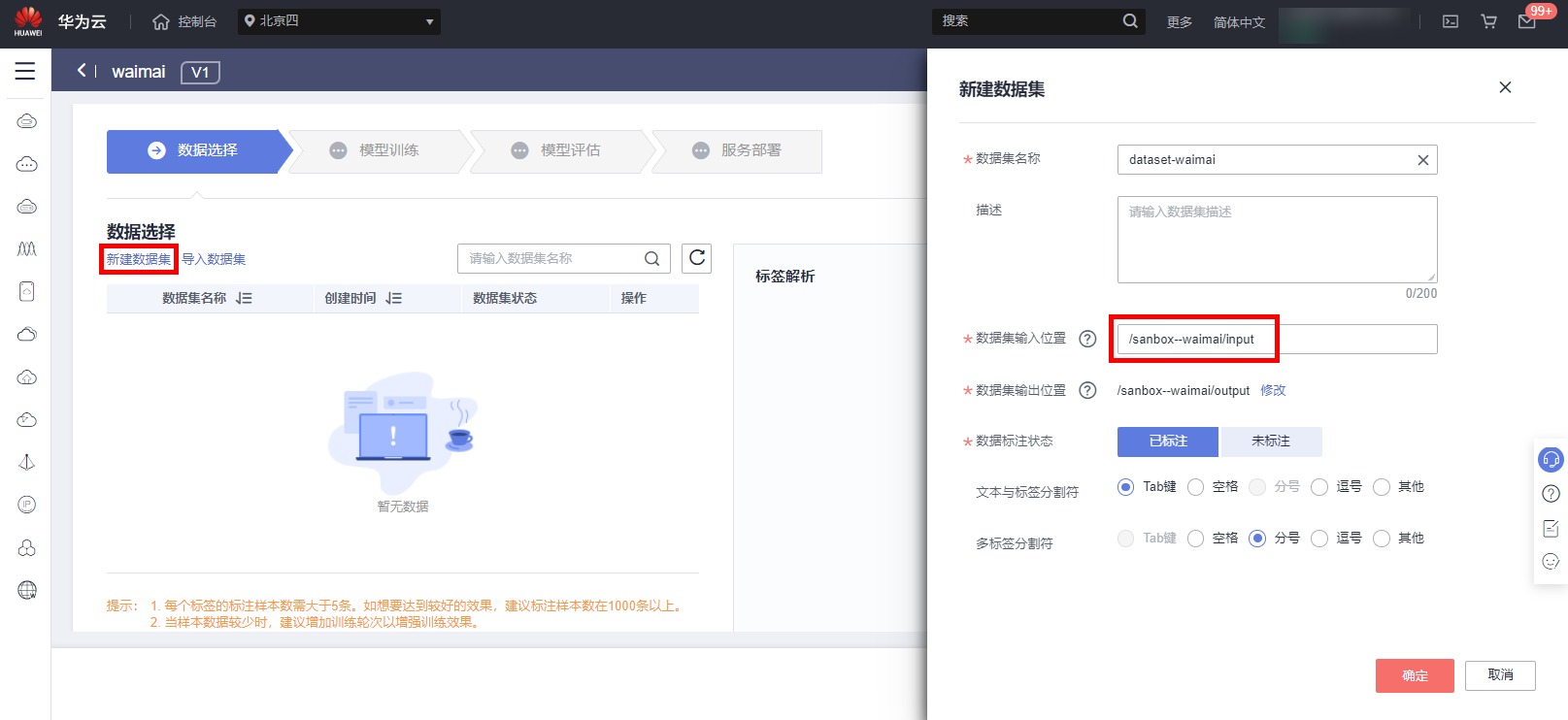
点击确认,等待数据集导入完成后,点击创建标注数据,构建标注任务,标注名称自定义,如下
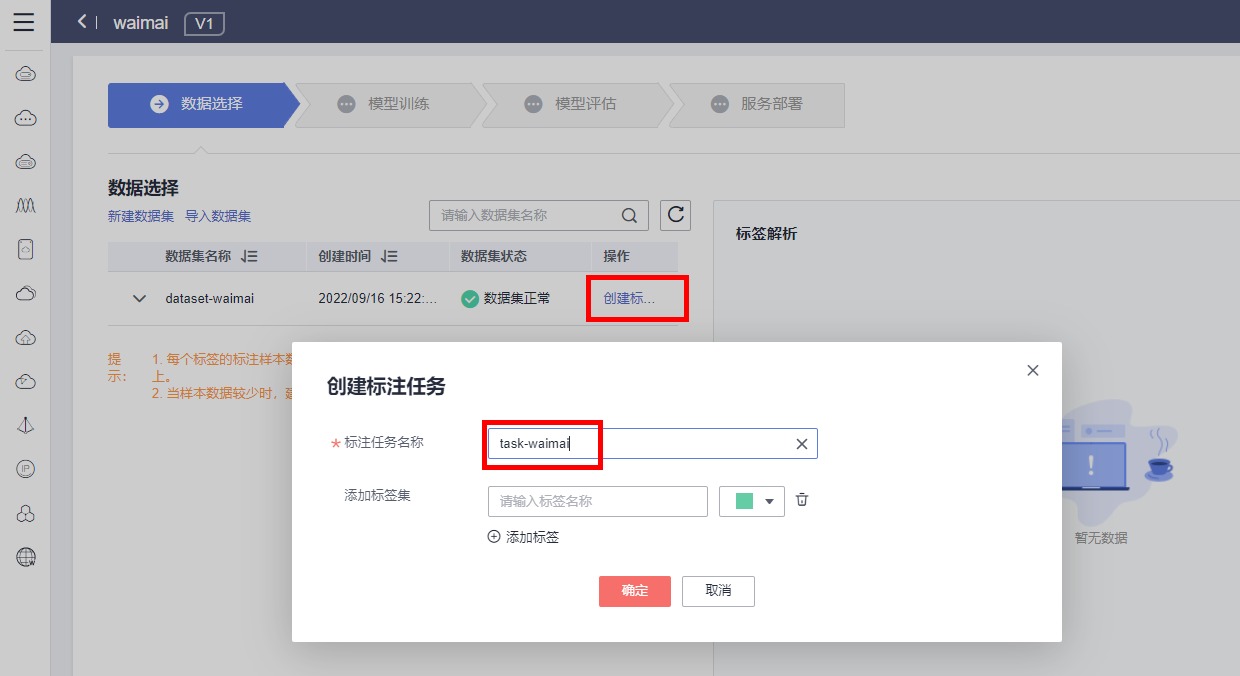
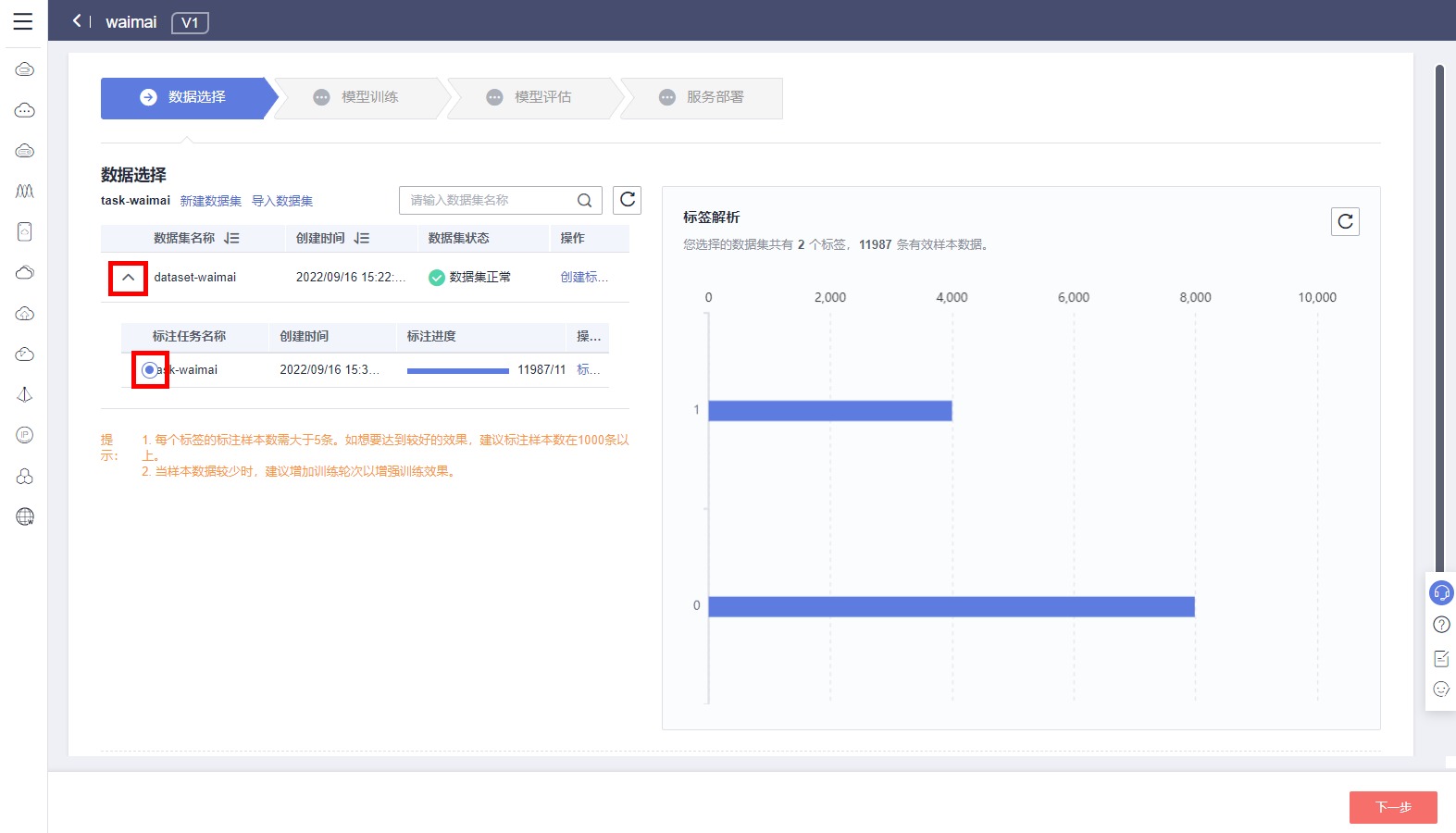
标注任务构建完成后,点击下拉按钮,即可查看标注任务进度。标注任务完成后,勾选标注任务,即可看到数据集标签解析结果。点击下一步,进行模型训练。
三 模型训练与评估
3.4 模型训练
进入模型训练页面,选择基础版算法 ,学习率设置为0.001,训练轮次为40。模型运行环境根据实际需求而定,CPU推理费用低、推理速度慢;GPU推理速度快、推理费用高,建议测试时选择CPU
点击开始训练
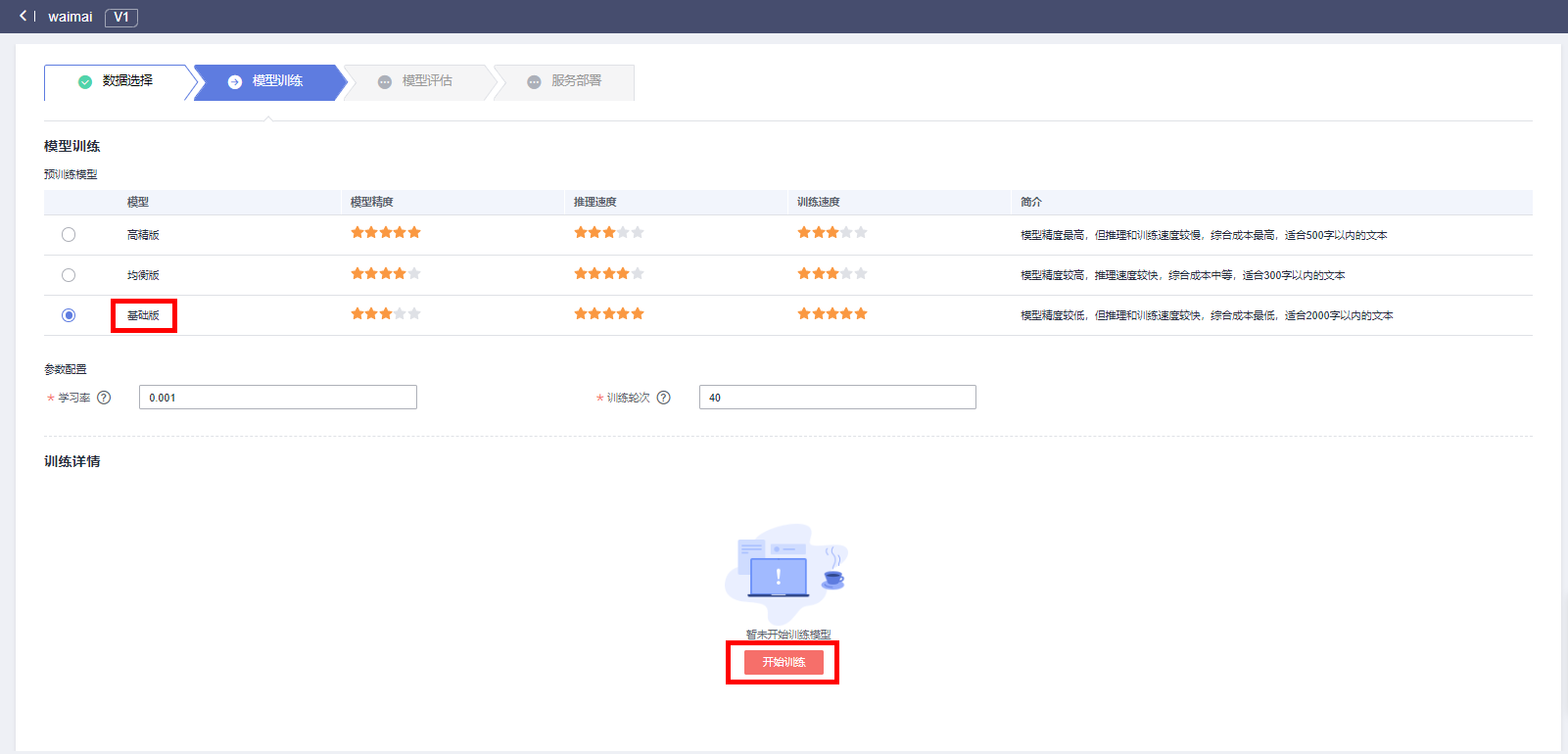
数据处理约4-5分钟,等待数据处理之后,开始模型训练,基础版训练时间短,预计等待3-4分钟,模型训练过程中,能够看到模型训练详情。
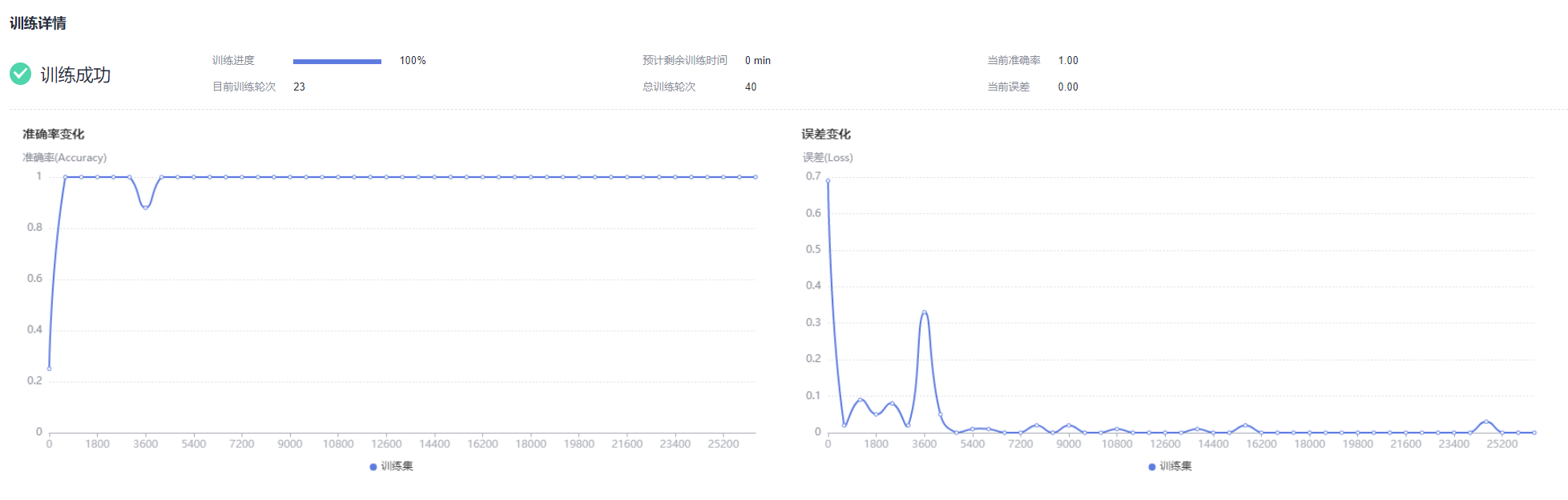
模型训练完成后,点击下一步,进行模型评估;
3.5 模型评估
进入模型评估页面,可展示测试集评估效果。在应用开发的“详细评估”页面,您可以搜索查看测试集中数据模型预测结果。
“详细评估”左侧在搜索框中搜索标签,右侧显示正确标签所对应样本的正确标签和预测标签,您可以对比正确标签和预测标签,判断当前模型预测该样本是否预测正确。
例如搜索框内输入标签“1”,下方会显示正确标签为“1”的样本中,预测正确的样本数在验证集中的占比。右侧显示正确标签为“1”的样本信息,包括样本的正确标签和预测标签
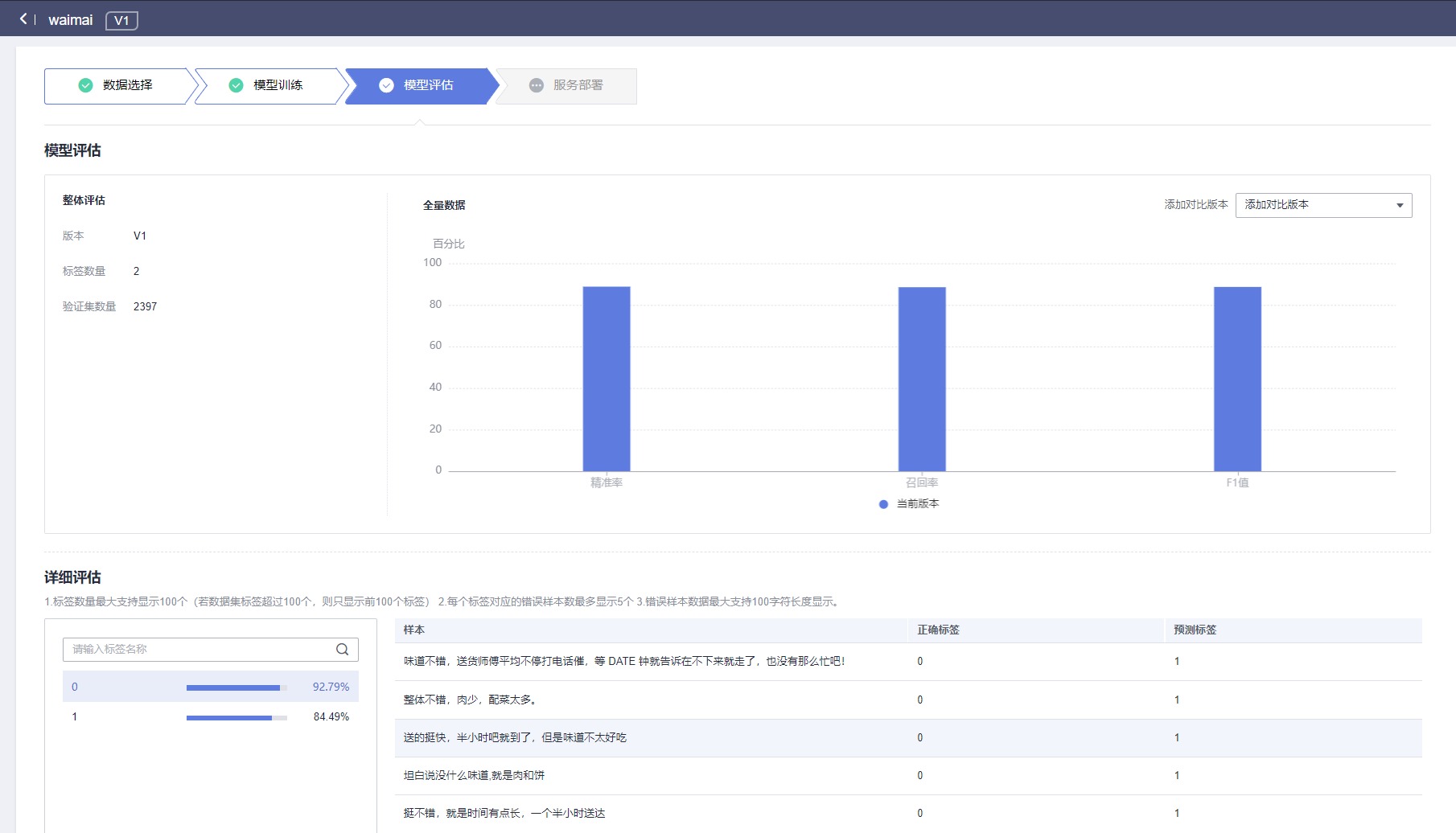
模型评估完成后,点击发布部署;
四 模型开始训练
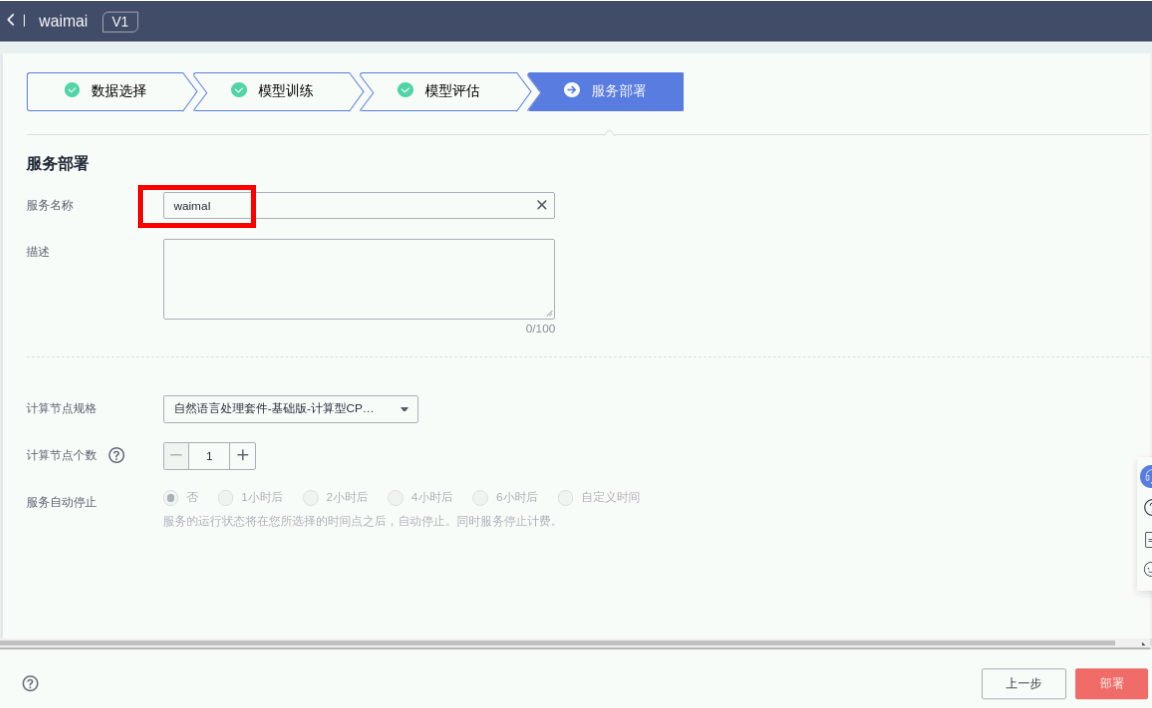
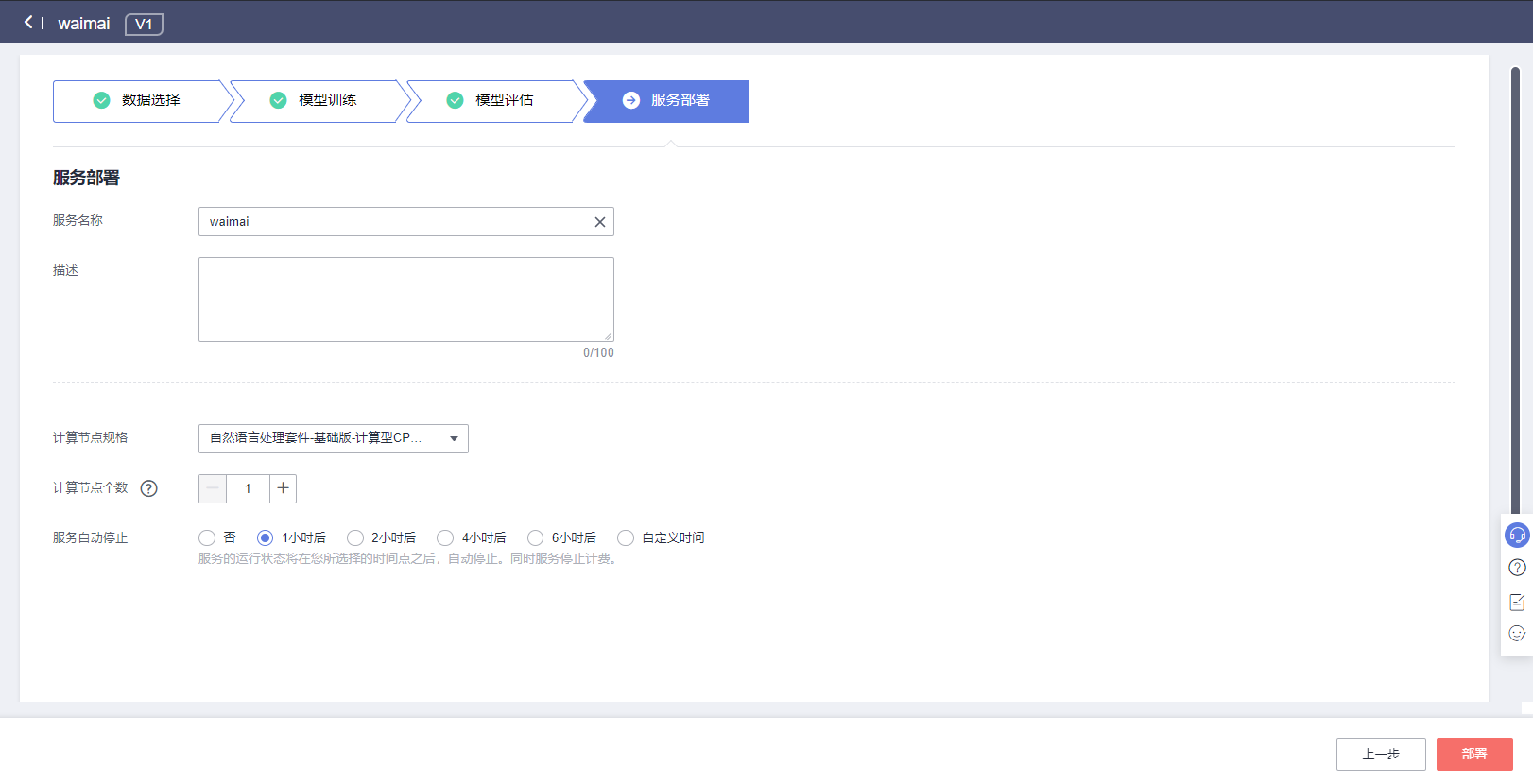
进入服务部署页面,可根据实际需求,设定计算节点个数和服务自动停止时间,
服务名称:waimai,
计算节点规格:自然语言处理套件-基础版-计算型CPU实例,
计算节点个数:1,
服务自动停止:可选时间,
如下图所示,完成后点击部署即可
等待服务部署,约3-5分钟,服务部署成功后,点击“查看应用监控”,即可在应用监控处进行在线测试。若需调用推理接口,调用方法可参考:https://support.huaweicloud.com/engineers-modelarts/modelarts_23_0063.html
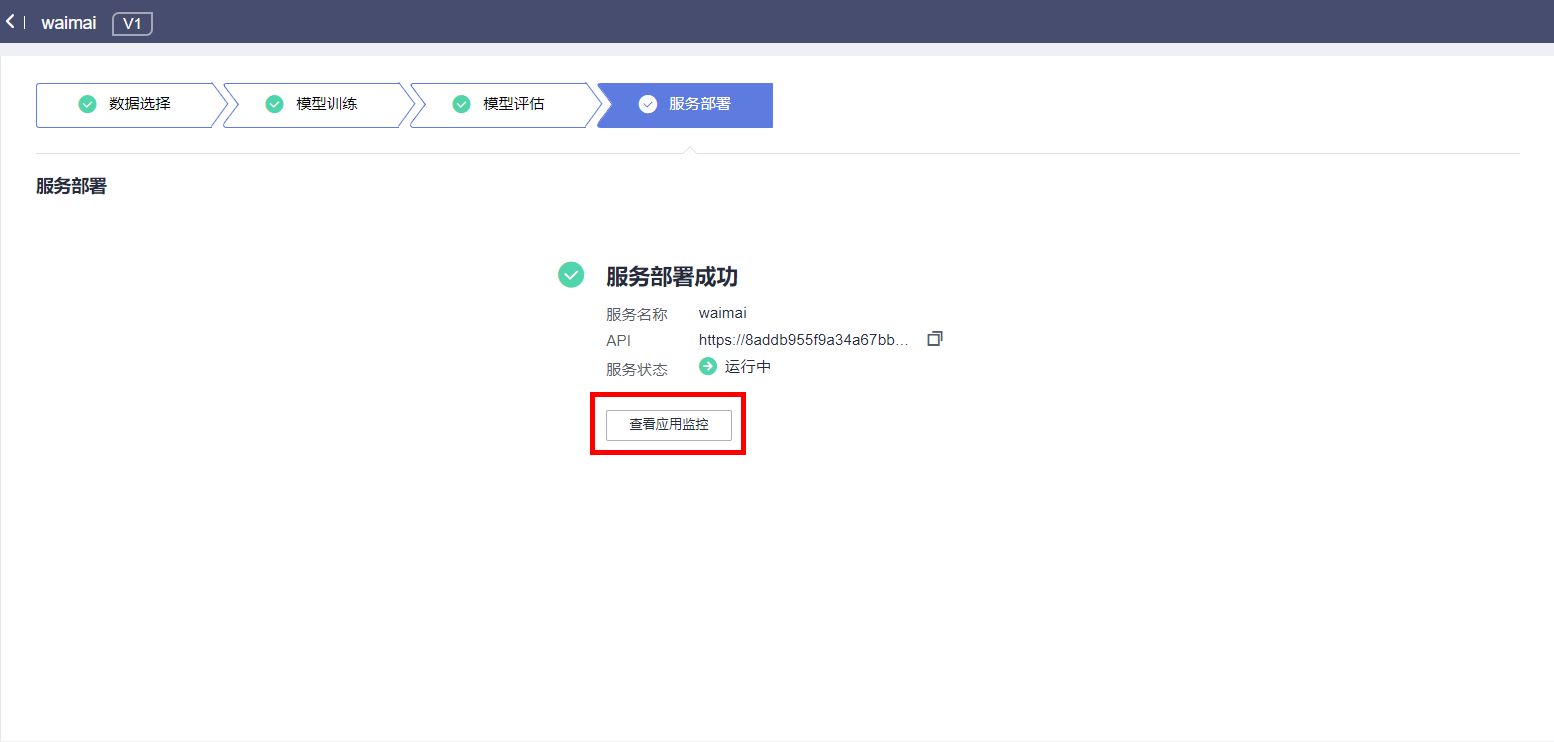
调用接口为API URL,请求体和参数如调用指南所示
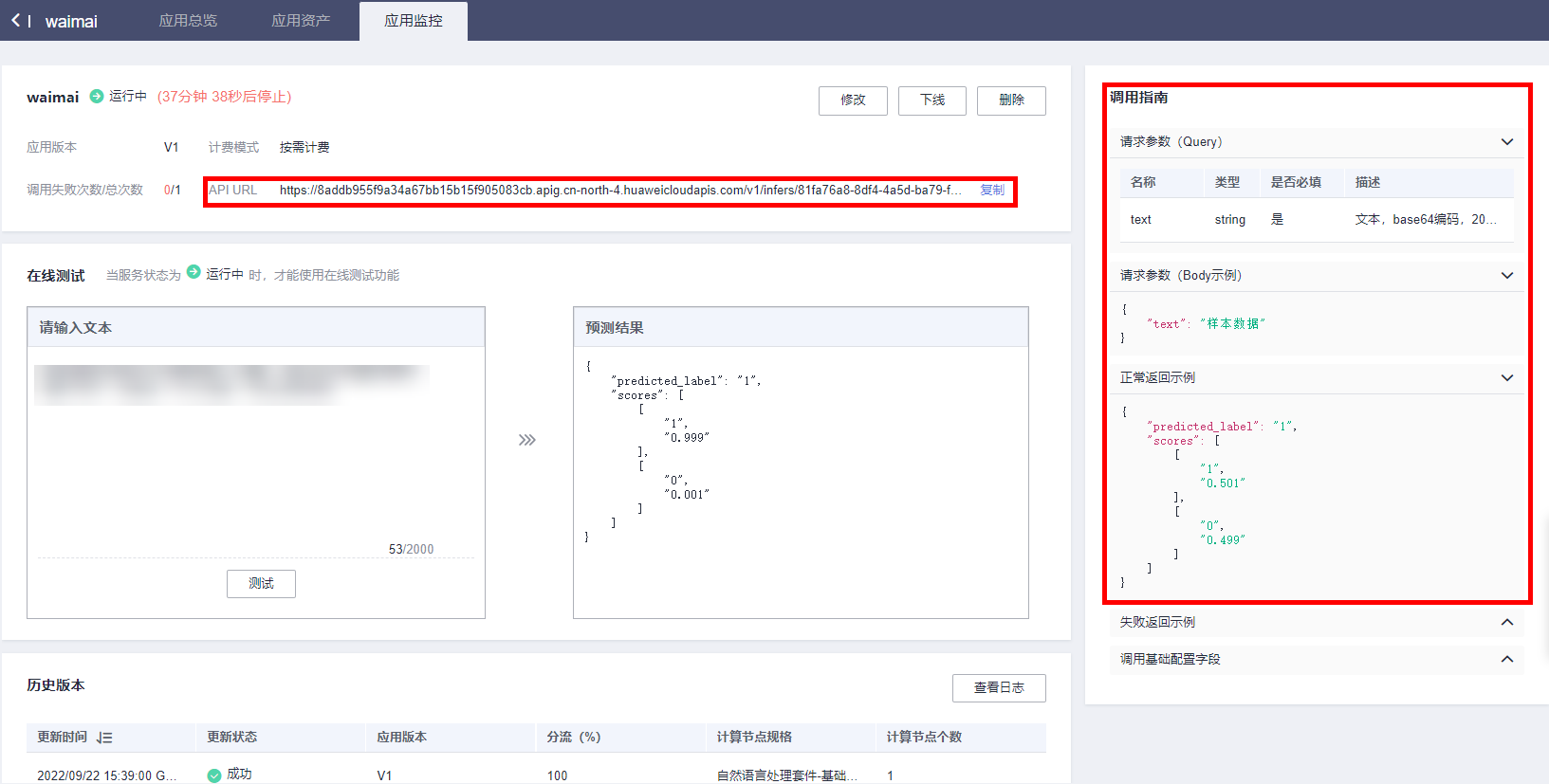
下面提供了几条待测试的文本评论,选择复制其中任意一条评论,在在线测试左侧文本框粘贴测试中文外卖评论再预测结果。
注意:只需要复制一条评论即可
1、这么好吃的店,我就要给大大地好评,让所有人都看见,都能享受到这样的美食!干净卫生,吃完之后毫不犹豫地把这家店加入了我的收藏名单!
2、很难吃,跟剩面一样,以前在店里很好吃的,外卖之前点过一次还行,现在越来越难吃了,失望……
3、不懂为什么别人评论的包装这么好这么干净寻思着30一份拌面也不便宜不会回购了菜品一般口味一般不是很值这个价网上营销比较厉害踩雷了
4、老板人太实在了,给的份量非常足,味道也是大众口味,性价比超高,以后就是我家的后厨了。包装真的十分用心了,口感质量服务一如既往的好,品质绝对对的起这个价。日常美食了,分量太大,一个人吃不完,这次的薯条不是很大,都是碎的,但是很好吃实事求是地写真要觉得好就写服务态度,好送货迅速,味道美极,下次还要来等等。
5、作为这个价位来讲按道理应该是一个相对整体都要有点品质的店,但实则让我有些大跌眼镜,包装很随便,点的小菜惨不忍睹,#红焖大肉#很小一块,并且很肥,#红油鸡小涅槃#少的可怜以及就是一个普通到不能再普通的红油皮蛋,#小时候土豆片#就更别提了,几乎没有味道,只是土豆切的样子稍微好看那么一点。最后说主食,#椒派牛蛙面#算是所有菜品里相对好一点的吧,但是讲实并不突出,也谈不上好吃#青椒肉片拌川(拌面)#就极为普通了。三四十一碗的面是这个品质和品相,我表示拔草的非常快。总之整体就是能吃而已,完全不值这个价格,图片拍的确实好,非常失望。
6、味道超级好,这家店已经列入了我无限回购的列表。份量真的超多,第一次看到荤菜份量这么多的外卖,简直是物超所值!!!
五 如何删除应用呢
另外,可通过“修改”按钮改变服务规格和推理时间;通过“下线”按钮来关闭服务,停止计费。
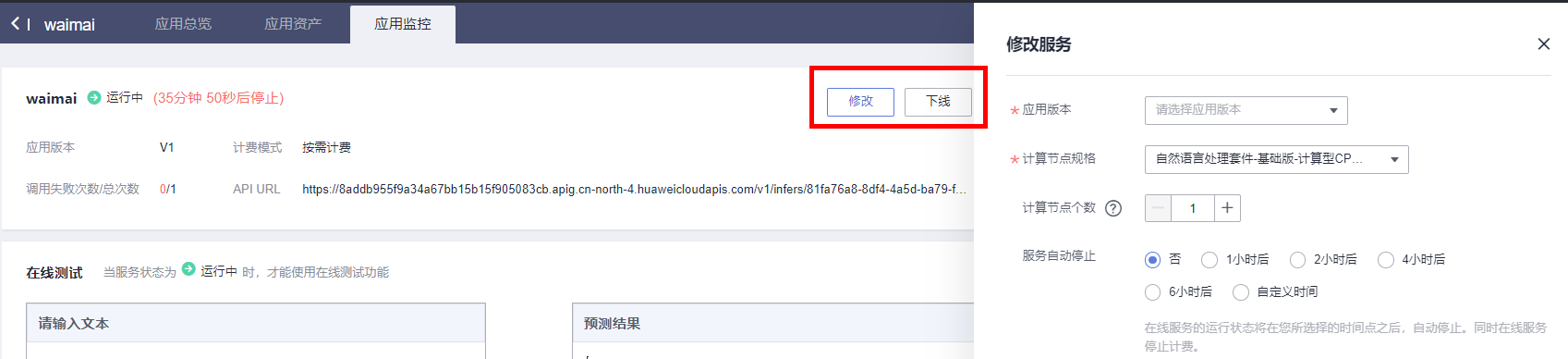
请确认应用监控页面调用总次数不为“0”后,再结束实验,否则无法检测到此步骤。
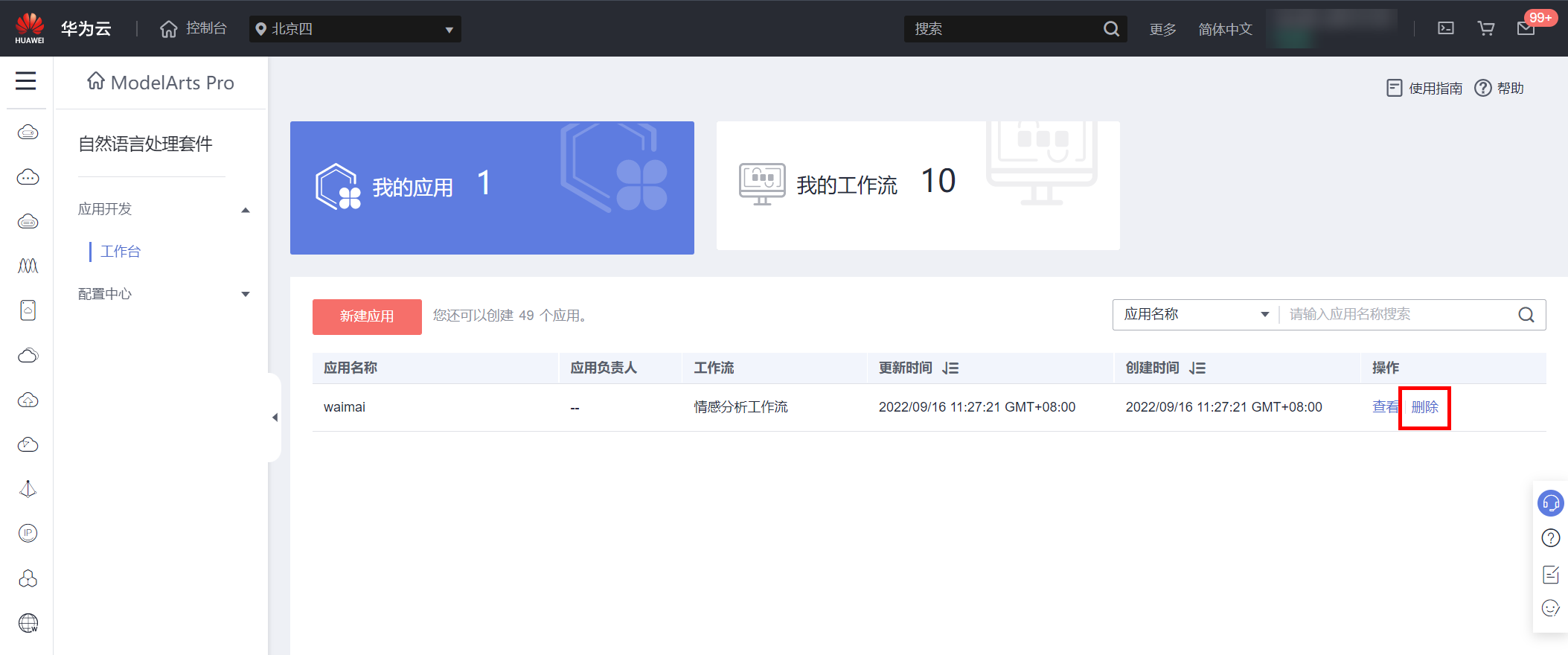
实验完成之后,请删除通用文本分类工作流中创建的应用。
在右侧浏览器复制以下链接:
https://console.huaweicloud.com/mapro/
返回ModelArts Pro页面,选择“自然语言处理套件”,点击“进入套件”,删除已创建的应用,如下图所示

- 点赞
- 收藏
- 关注作者
评论(0)