用DevKit插件来集成API实现语音合成【玩转华为云】

主要内容有:
- 一 语音识别基础
- 二 语音合成TTS是啥
- 三 准备工作先做好
- 四 应用开发过程
- 五 下载到本地体验,更多乐趣
一 语音识别基础
1.1 简单定义
所谓语音识别,就是把一段语音信号转成相对应的文本信息,系统主要包含特征提取、声学模型,语言模型以及字典与解码四大部分;
1.2 识别过程
此外为了更有效地提取特征往往还需要对所采集到的声音信号进行滤波、分帧等音频数据预处理工作,将需要分析的音频信号从原始信号中合适地提取出来;特征提取工作将声音信号从时域转换到频域,为声学模型提供合适的特征向量;声学模型中再根据声学特性计算每一个特征向量在声学特征上的得分;
而语言模型则根据语言学相关的理论,计算该声音信号对应可能词组序列的概率;最后根据已有的字典,对词组序列进行解码,得到最后可能的文本表示。
1.2.0 预处理:
- 首尾端的静音切除,降低对后续步骤造成的干扰,静音切除的操作一般称为VAD。
- 声音分帧,也就是把声音切开成一小段一小段,每小段称为一帧,使用移动窗函数来实现,不是简单的切开,各帧之间一般是有交叠的‘;’
1.2.1特征提取:主要算法有线性预测倒谱系数(LPCC)和Mel 倒谱系数(MFCC),目的是把每一帧波形变成一个包含声音信息的多维向量。
1.2.2声学模型(AM):通过对语音数据进行训练获得,输入是特征向量,输出为音素信息。字典:字或者词与音素的对应, 简单来说, 中文就是拼音和汉字的对应,英文就是音标与单词的对应。
1.2.3语言模型(LM):通过对大量文本信息进行训练,得到单个字或者词相互关联的概率。
1.2.4解码:就是通过声学模型,字典,语言模型对提取特征后的音频数据进行文字输出;
语音识别流程的举例(只是形象描述,不是真实数据与过程哈):
1.语音信号:PCM文件等(我是机器人)
2. 特征提取:提取特征向量[1 2 3 4 56 0 …]
3. 声学模型:[1 2 3 4 56 0]-> w o s i j i q i r n
4. 字典:窝:w o;我:w o;是:s i;机:j i;器:q i;人:r n;级:j i;忍:r n;
5. 语言模型:我:0.0786, 是:0.0546,我是:0.0898,机器:0.0967,机器人:0.6785;
6. 输出文字:我是机器人;
二 语音合成TTS是啥
2.1 如何定义
是种提供在线语音合成能力,支持将文本信息实时转化为近似的真人发声,支持多语言多音色语音在线合成。支持客户的个性化语音定制化需求;
2.2 有啥场景呢
- 语音客服质检
- 会议记录
- 语音短消息
- 游戏娱乐
- 有声读物
将书籍、杂志、新闻的文本内容转换成逼真的人声发音,充分解放人们的眼睛,在搭乘地铁、开车、健身等场景下获取信息、享受乐趣。
- 电话回访
- 智能教育
- 直播实时字幕
- 会议实时记录
- 即时文本录入
- 人机交互
- 智能客服
三 准备工作先做好
3.1 开通服务
本实验需用到语音交互服务中的语音合成API,在账户余额充足的情况下,无需开通即可直接调用接口并按需计费;

3.2 下载ak/sk
登录华为云,在右上角单击“控制台”

在“控制台”页面,鼠标移动至右上方的用户名,在下拉列表中选择“我的凭证”
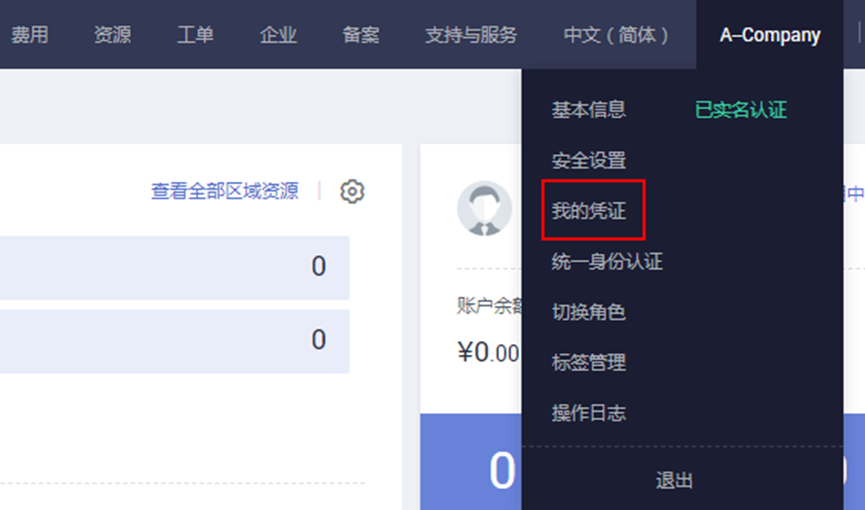
在“我的凭证”页面,然后依次点击【访问密钥】、【新增访问密钥
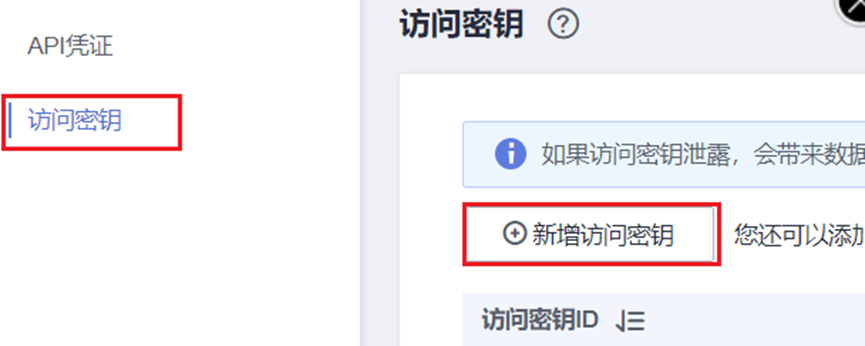
确定后华为云会为您生成credentials.csv文件,点击“立即下载”,文件会下载到/home/user/Downloads/路径下,下载完成后双击打开,可以看到用户的用户名(User Name)、ak(Access Key Id)、sk(Secret Access Key),如下所示
3.3 安装Huawei Cloud DevKit
双击打开桌面上的IntelliJ IDEA,完成以下操作:

- 在IntelliJ IDEA左侧的菜单栏中选择Plugins。
- 在Plugins区域单击Marketplace。
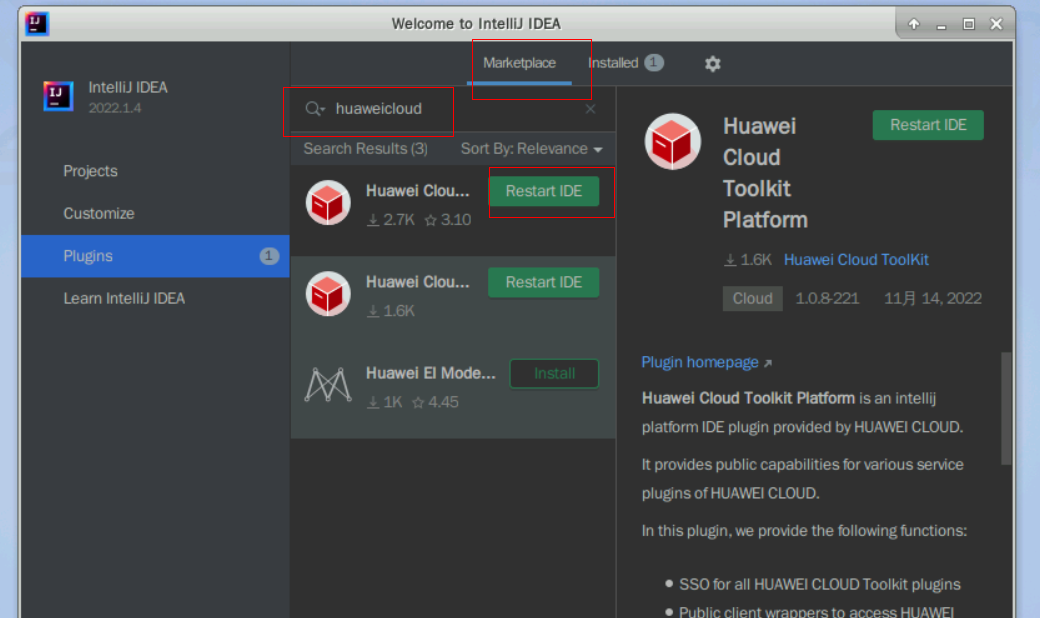
- 在搜索栏中输入Huawei Cloud。
- Search Results区域会出现Huawei Cloud DevKit和 Huawei Cloud Toolkit Platform,分别单击Install安装,如果有弹窗选择"accept"。
- 点击ReStart IDE完成重启
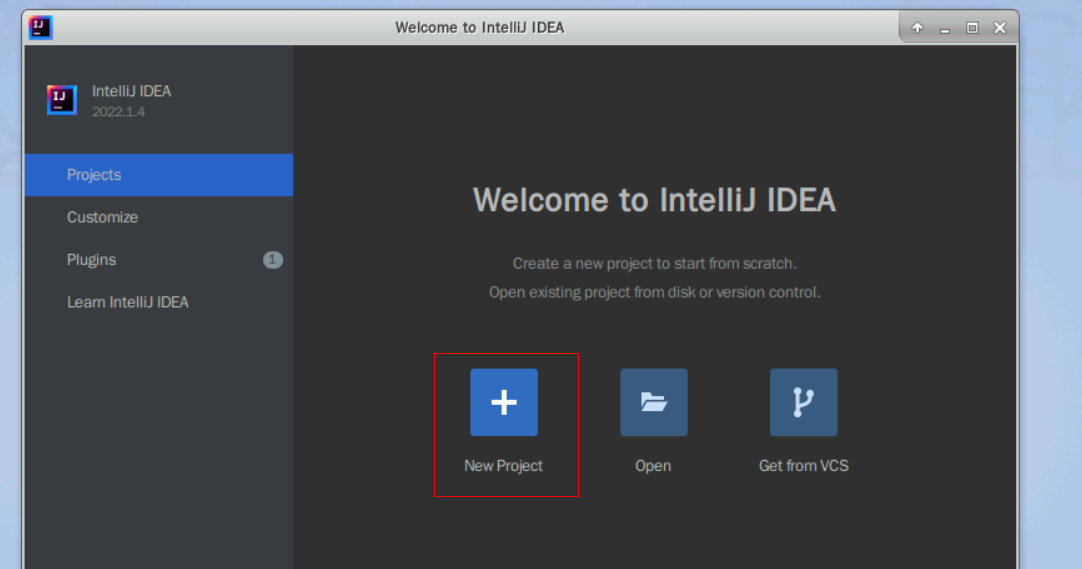
3.4、初始化配置
再次进入IDEA页面,选择new project,然后选择create
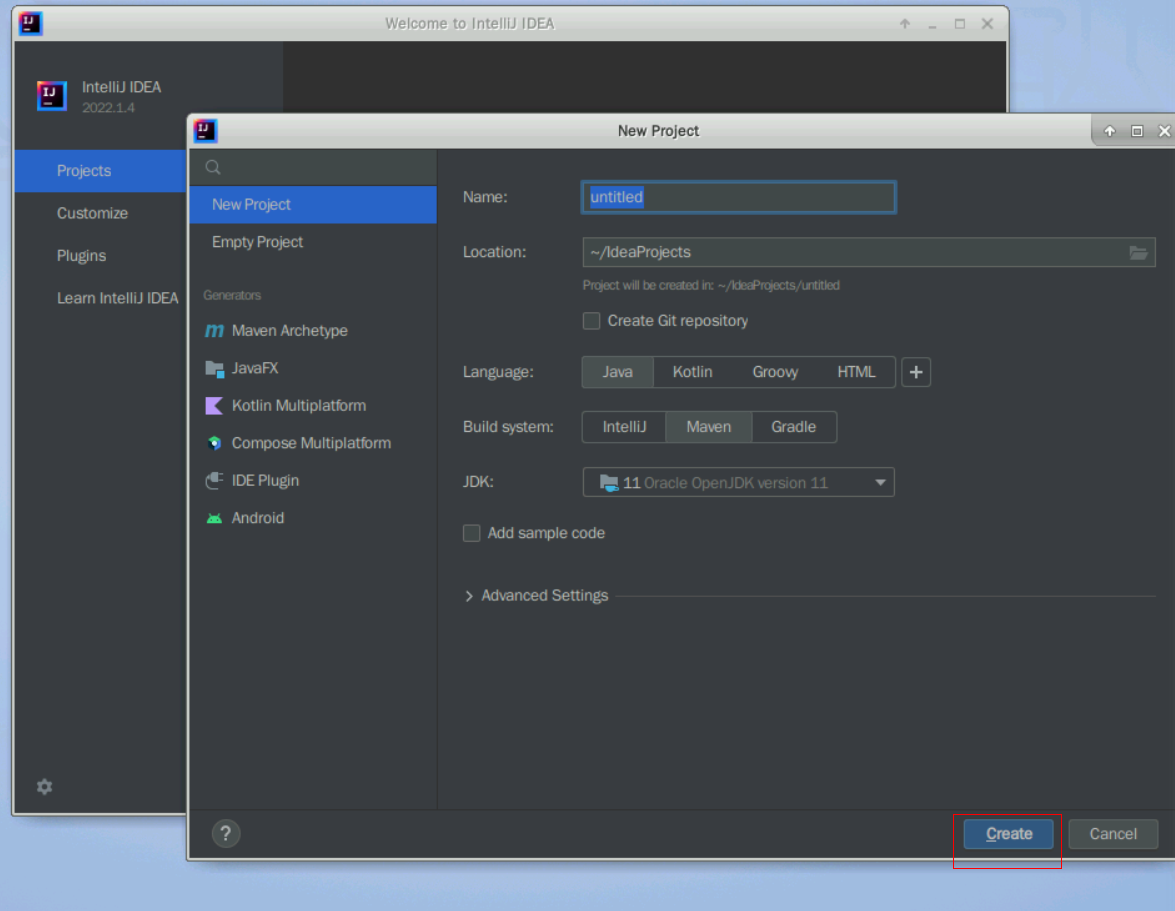
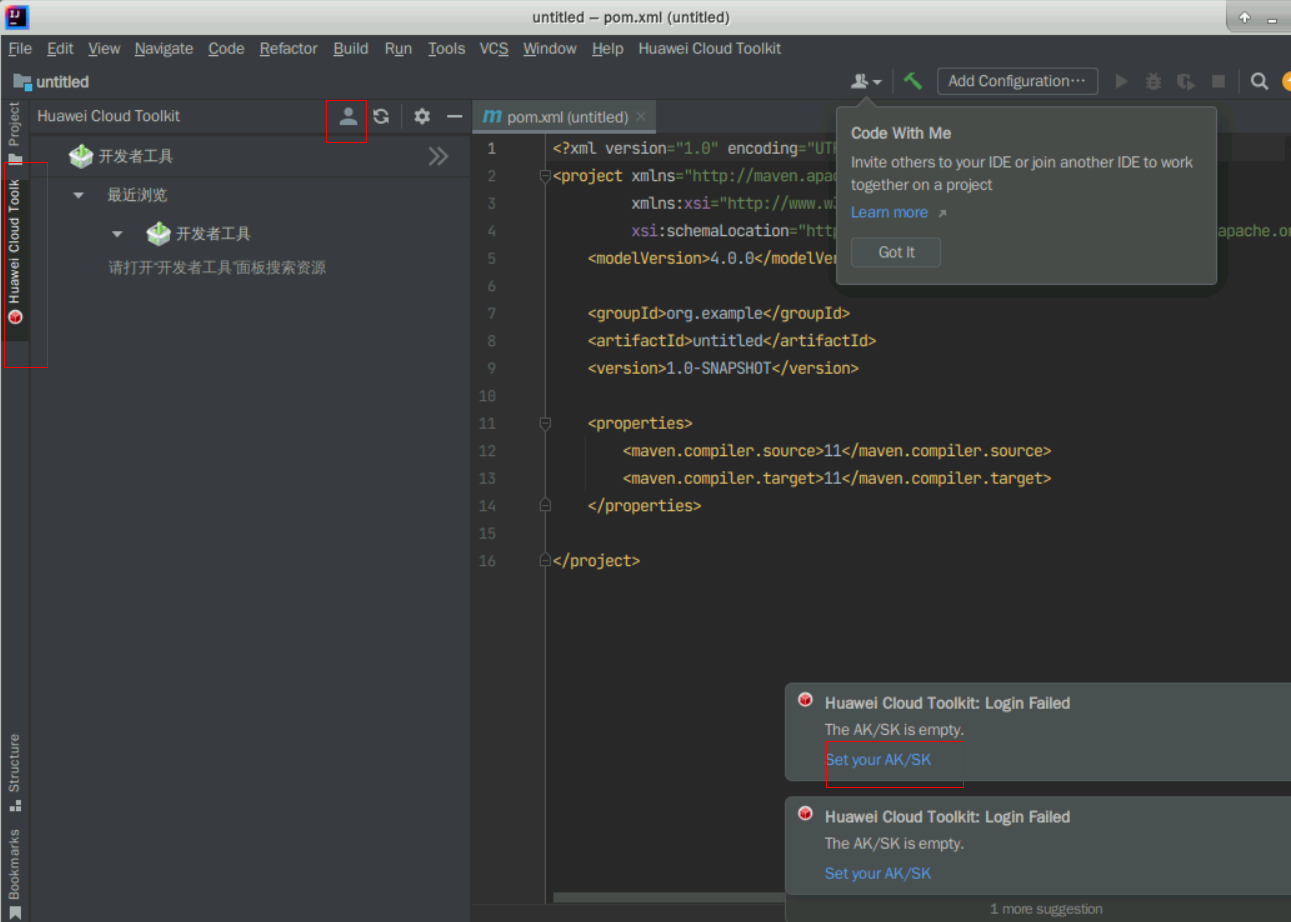
这时会打开一个全新的IDEA窗口,点击左侧的Huawei Cloud Toolkit按钮,点击用户登录按钮,这时右下角弹出“Huawei Cloud Toolkit:Login Failed The AK/SK is empty”,点击下面的“Set your AK/SK”
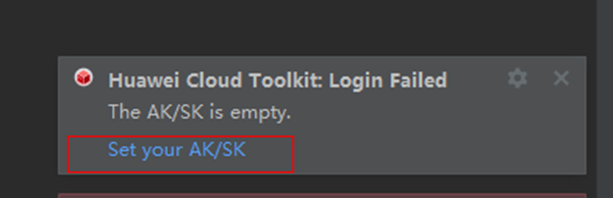
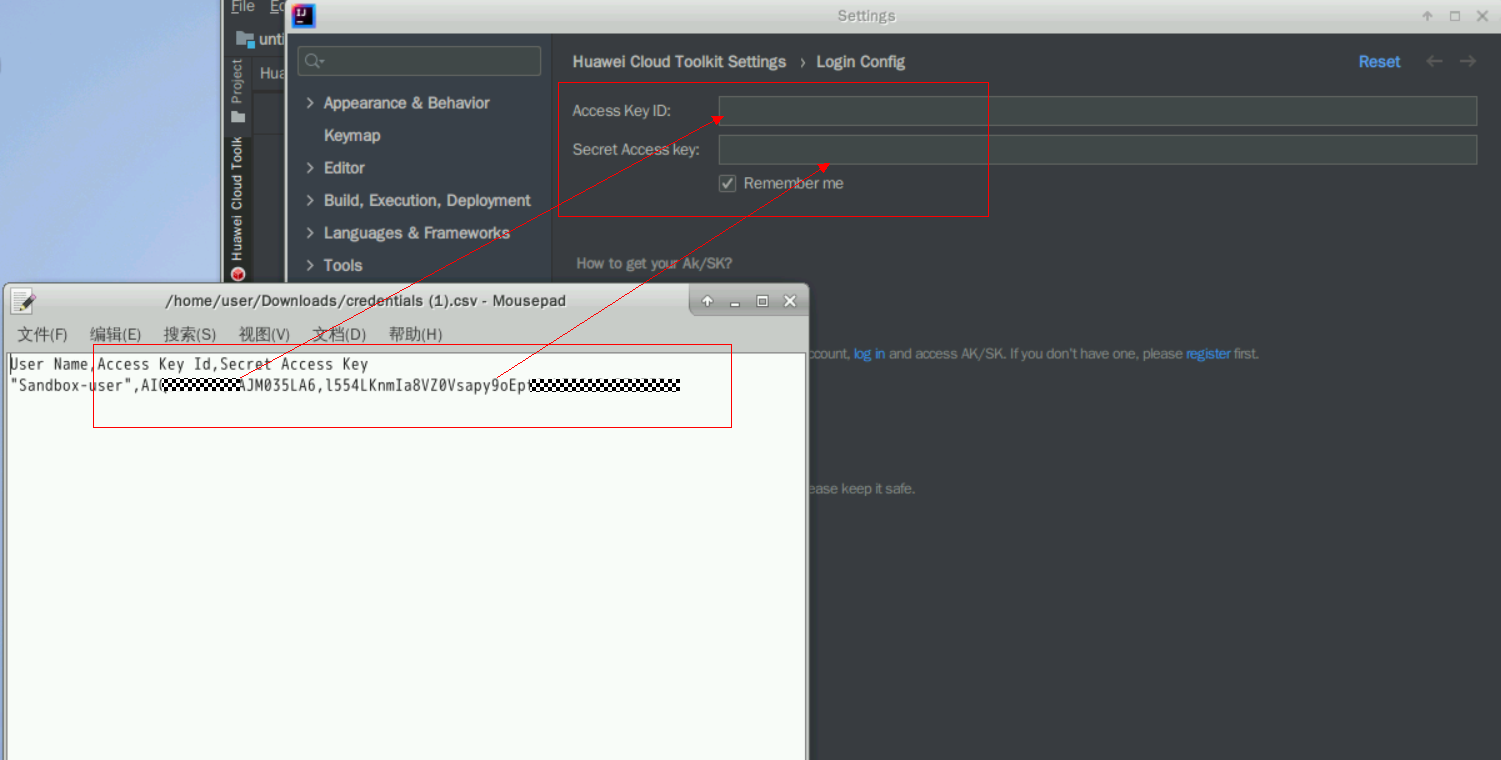
在弹出的Settings内填入刚刚下载的AK/SK到Access Key ID:和Secret Access key:中,依次点击Apply、OK
此时,右下角弹出Welcome!xxxx,表明您已经登录成功!
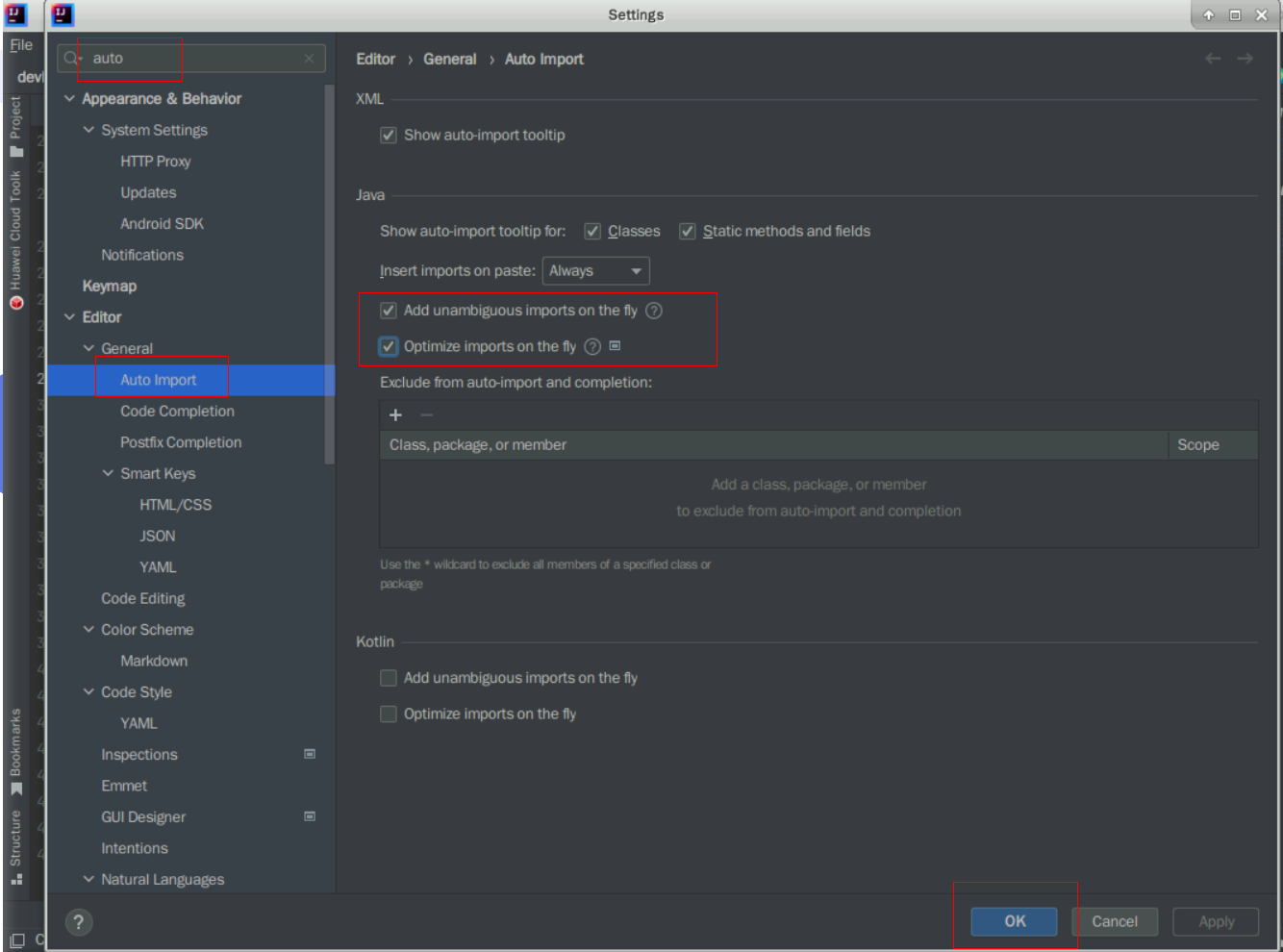
此外,为了方面您写代码,建议您打开IEDA的auto-import功能:点击IDEA左上角的File菜单,选择settings,在settings的左上角搜索框中输入auto,选择auto import配置,勾选Optimize imports on the fly,选择确定
四 应用开发过程
1、搭建本地工程
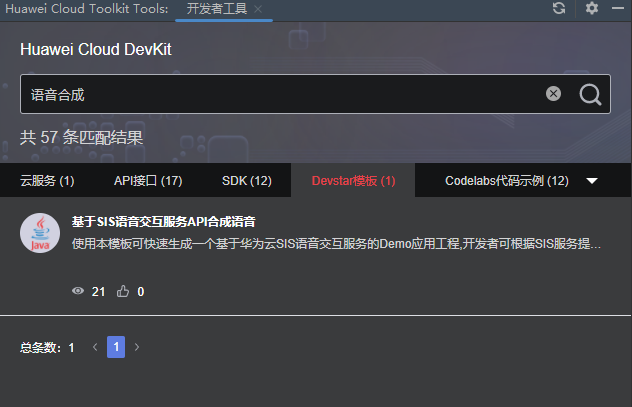
在IDEA里打开Huawei Cloud Toolkit窗口,点击开发者工具按钮,右侧打开开发者工具面板,在搜索栏中输入“语音合成”(P.S.因为沙箱里不支持中文输入,此时可以通过沙箱右上角的复制/粘贴面板功能,在剪贴板中输入中文后,再复制到沙箱里面去),点击搜索按钮,然后选择DevStar模板页签,找到“基于SIS语音交互服务API合成语音”模板并选中

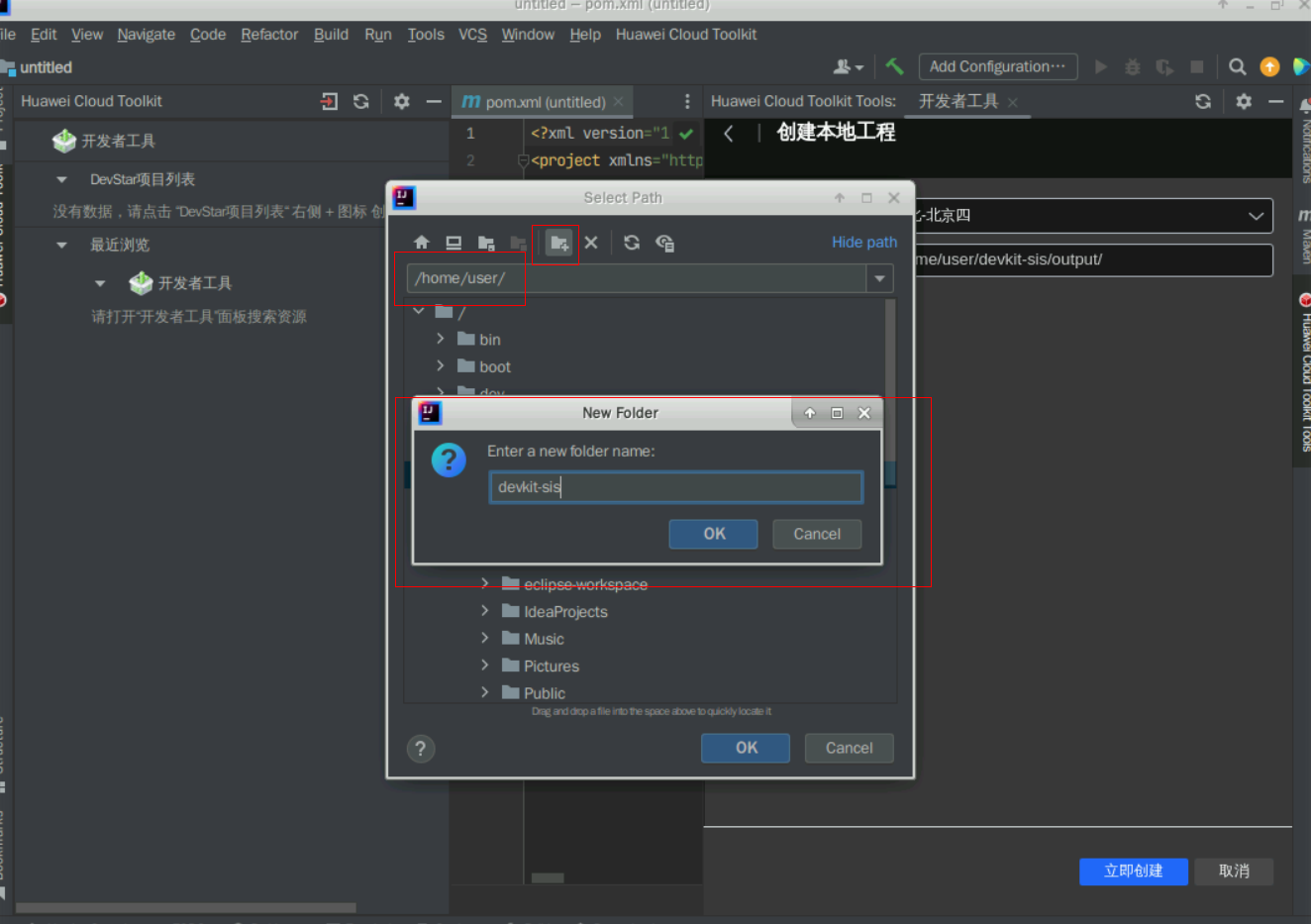
点击右上角的“创建本地工程”按钮,"区域名称"参数选择“华为-北京四”,"path"参数填写“/home/user/devkit-sis/”,最后再点击下方的“立即创建”按钮,选择创建工程的目录为/home/user/devkit-sis,点击确认后需要等待DevKit帮您创建本地工程;
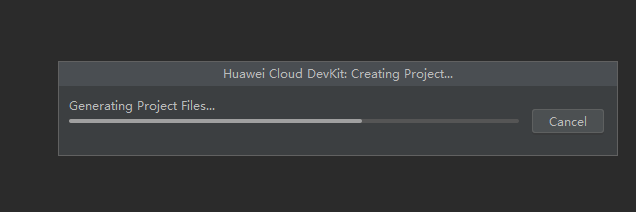
创建完后会弹出窗口“Trust and Open Project ‘XXXX’?”,点击“Trust Project”按钮,然后选This window
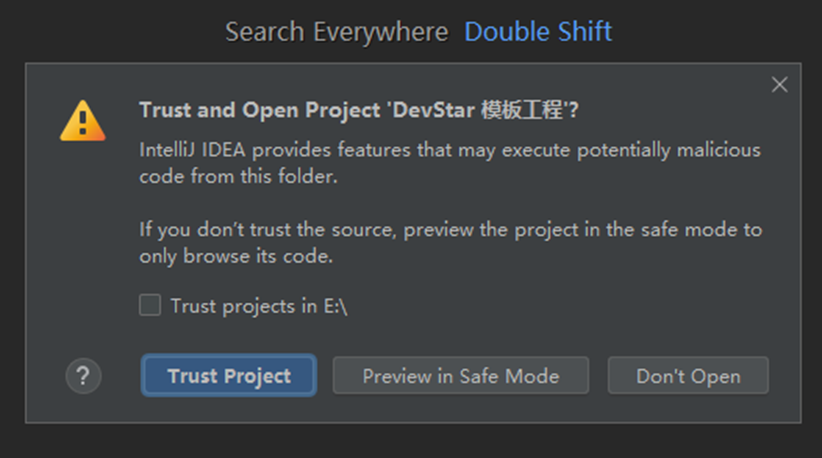
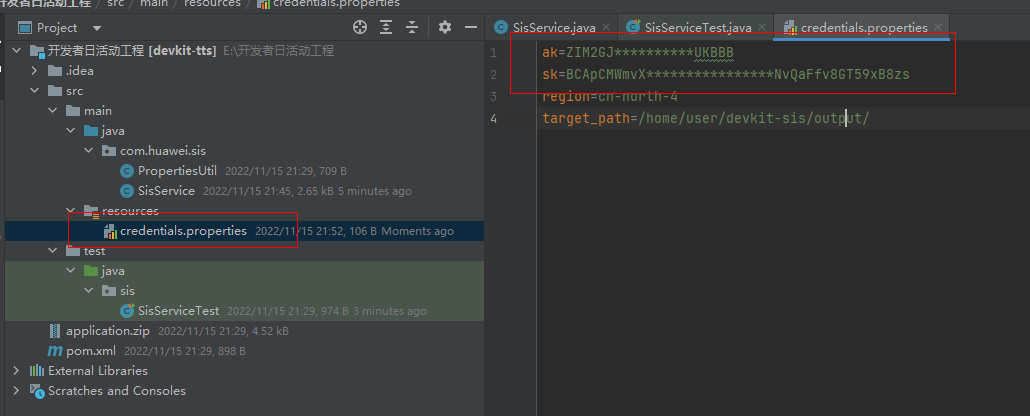
等待工程初始化完成后,打开src/main/resources/credentials.properties,将刚刚下载的credentials.csv中的Access_Key_Id填入ak、Secret_Access_Key填入sk中
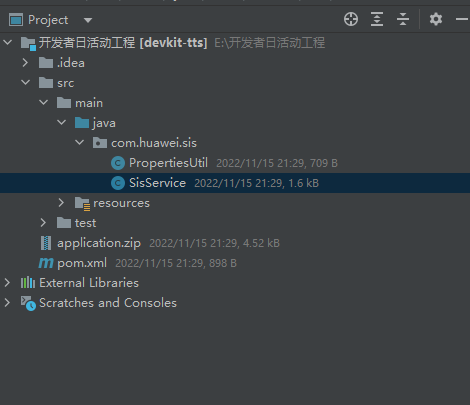
2、弄懂模板工程代码逻辑
在IDEA内,选中左侧的Project侧边栏,打开目录,一直到打开src/main/java/com/huawei/sis/SisService.java文件,可以看到整个工程是用来实现一个语音合成功能的框架。
那么接下来,就需要实现这个应用的核心功能:将一段文字合成语音,最终生成对应的音频文件。
3、找到合适的API
仍是打开Huawei Cloud Toolkit侧边栏,点击开发者工具按钮打开开发者工具面板,在搜索框中搜索“语音合成”,选择“API接口”页签,在API接口的搜索列表中找到“语音合成接口RunTts”,点击“查看文档”(P.S.如果面板太窄看不清可以双击面板顶部,将面板放大)
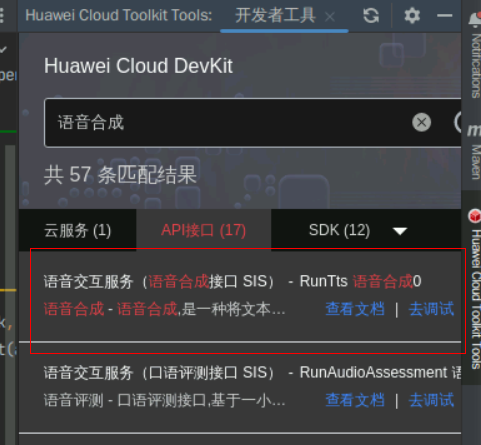
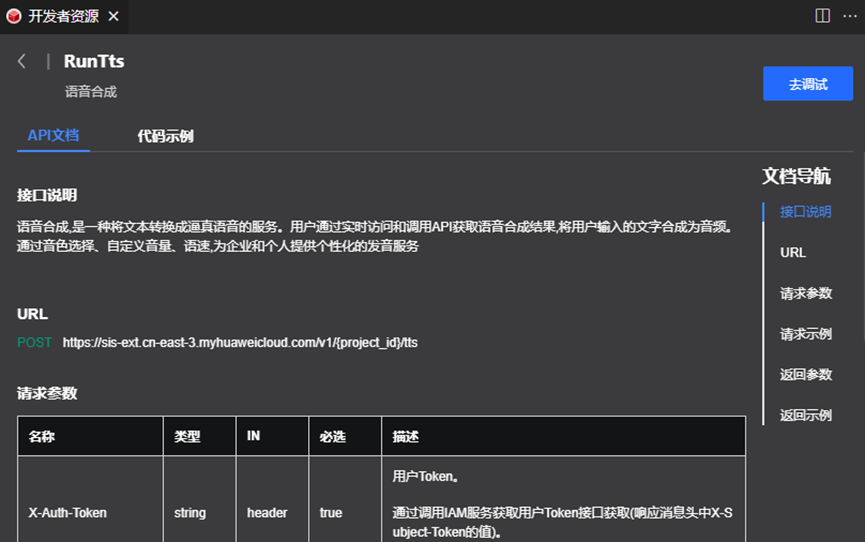
4、学习API
查看这个接口的说明,请求参数是啥、返回结果是啥,再查看请求示例和返回示例,了解到这个API是将文字转换成语音的base64编码,同时,你也可以选择不同类型的声音:温柔的、成熟的、甚至是方言的;


切换“API文档”页签到右边的“代码示例”页签,可以查看这个API整个调用过程的示例代码,当你填入参数时,示例代码将会生成对应的代码块。
此时,你可以将你想合成语音的文字内容输入到text参数中,例如“你好”,在audio_format参数选择wav,property参数根据文档上的描述选择其中一种口音,(注意,部分口音需要将sample_rate参数配置成16000)如下图所示;
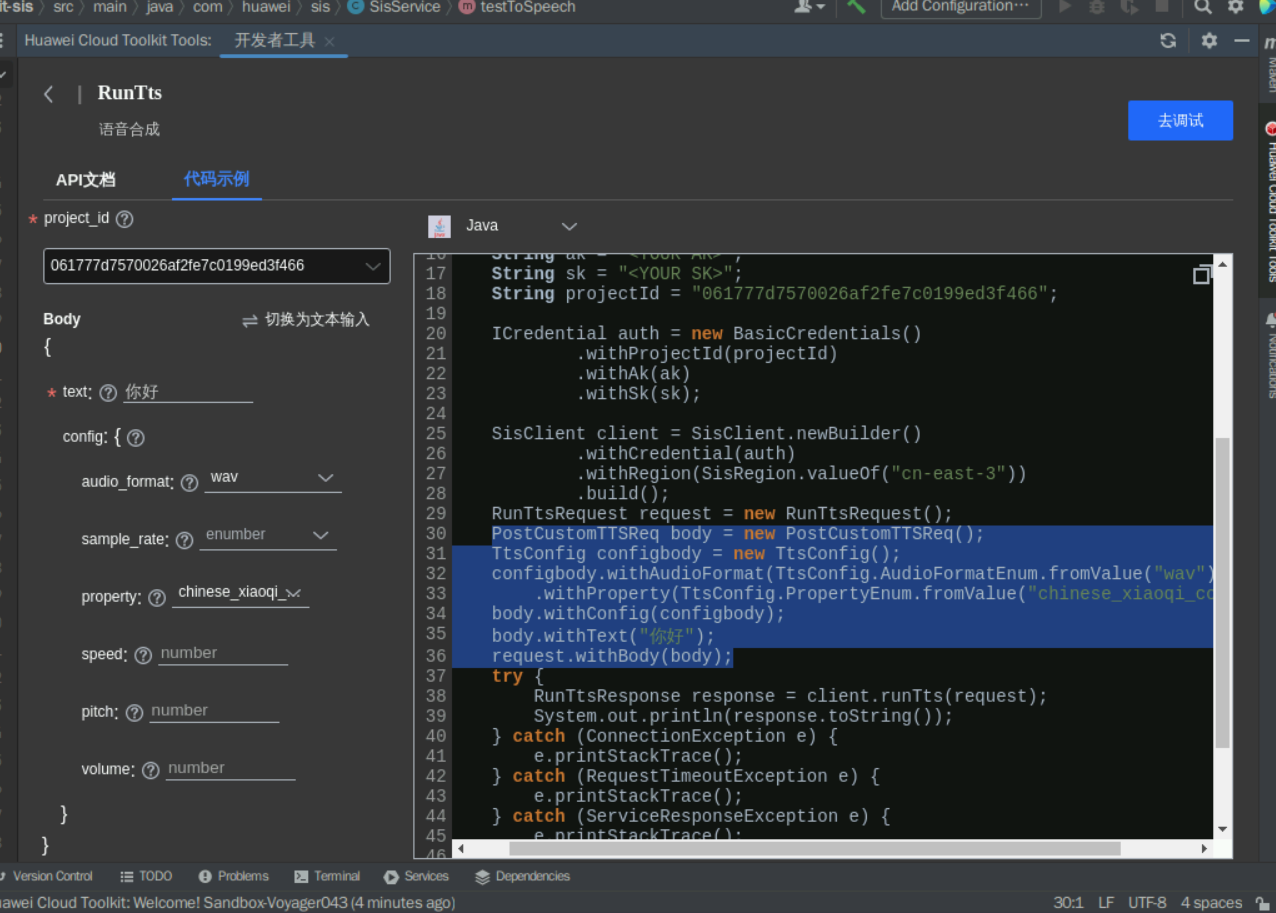
5、完成应用
打开 “\src\main\java\com\huawei\sis\SisService.java”文件,然后定位至第25行代码下方,即需在此处添加语音合成相关的代码:
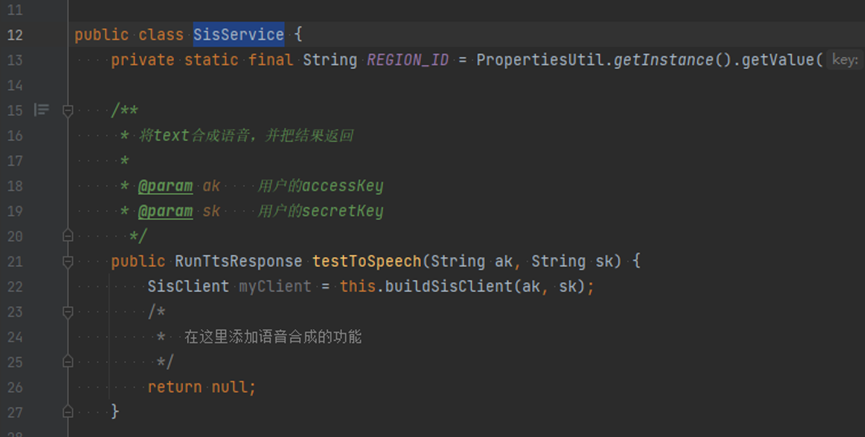
在IDE中输入RunTts,DevKit会自动帮你联想出合适的API,选择RunTts,DevKit会帮你自动把SDK调用实现,并且将代码中涉及到的依赖自动import
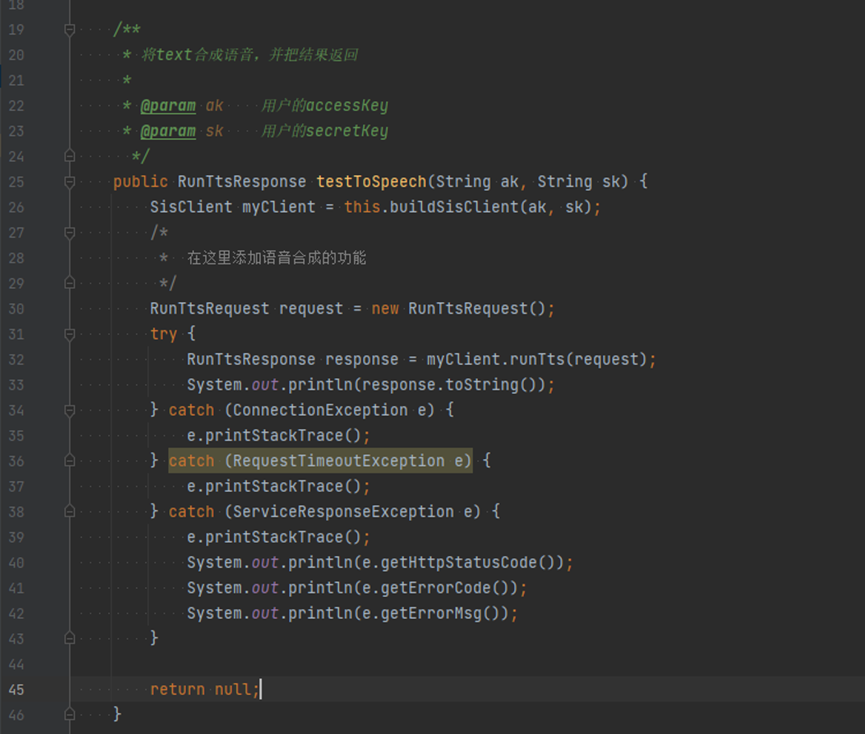
此时,API的调用代码已经自动生成,开始添加API参数,在刚刚的代码示例中,将30~36行代码复制,粘贴到编辑器中的29~30行间:
RunTtsRequest request = new RunTtsRequest();
PostCustomTTSReq body = new PostCustomTTSReq();
TtsConfig configbody = new TtsConfig();
configbody.withAudioFormat(TtsConfig.AudioFormatEnum.fromValue("wav"))
.withProperty(TtsConfig.PropertyEnum.fromValue("chinese_xiaoqi_common"));
body.withConfig(configbody);
body.withText("??");
request.withBody(body);
try {再将return response插入到41行下作为方法的返回值:
try {
RunTtsResponse response = myClient.runTts(request);
System.out.println(response.toString());
return response;
}最终代码如下图所示:
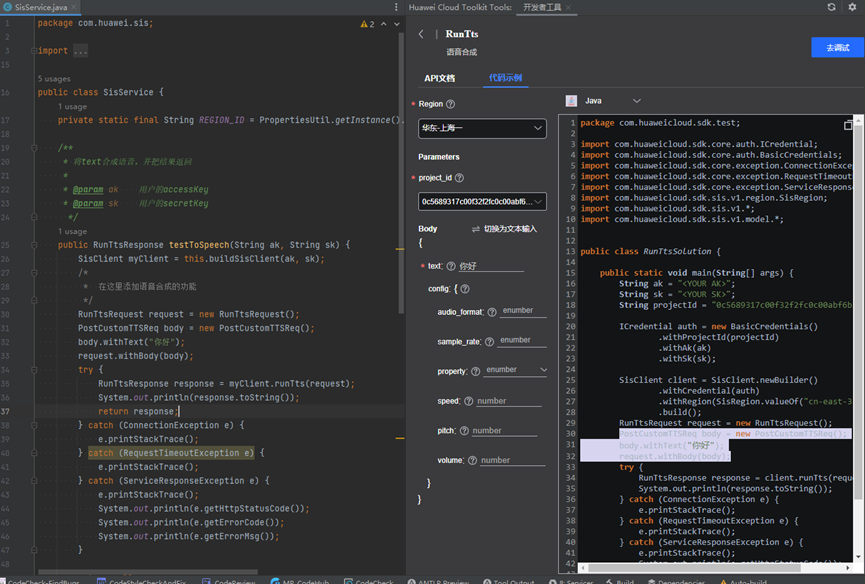
6、运行应用
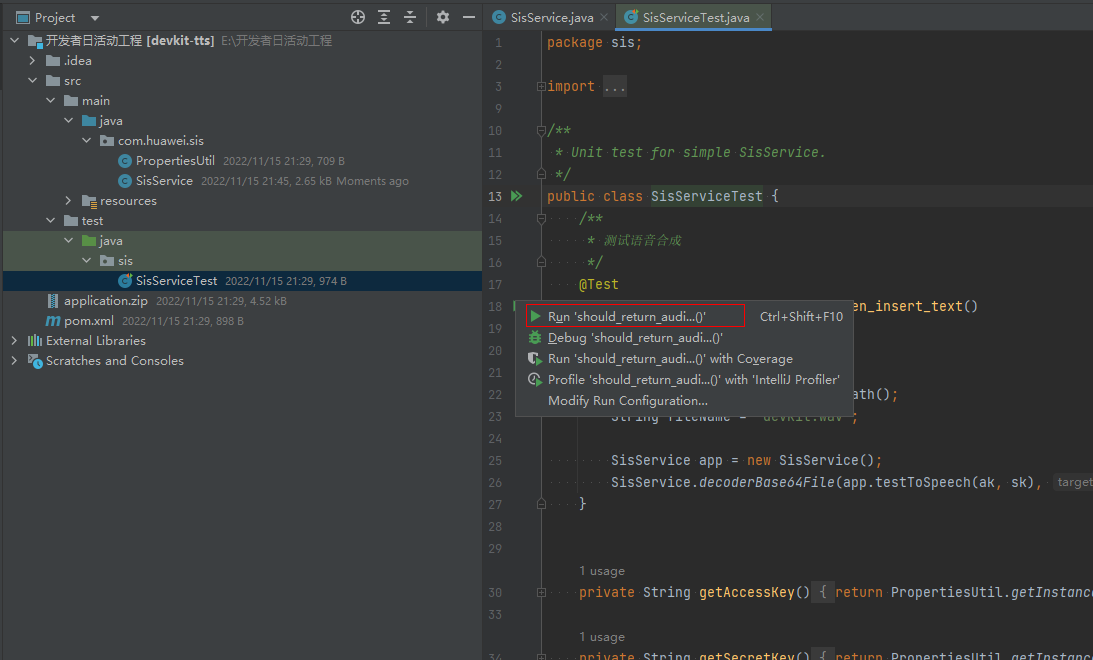
打开test目录下的SisServiceTest文件,点击18行函数旁绿色运行按钮,选择Run 'should_return_audio_when_insert_text()',生成的音频文件就会生成到对应的目录下。
五 下载到本地体验,更多乐趣
扩展内容:大家可以调整API参数,衍生出更多好玩的idea,包括且不限于:可以输入一些好玩的文字(古诗、绕口令、歌词等等),可以转成不同的音频(台湾腔、闽南语、萝莉音),不同的组合会有不同的效果,趣味性就加强了。
**注意,部分口音需要将sample_rate参数配置成16000**
同时,您也可以将沙箱中合成的音频下载到本地,体验最终的效果
1、创建OBS
登录华为云控制台,鼠标移动到左侧的服务列表,在右侧弹框中输入OBS,选择下面的对象存储服务OBS
左侧选择桶列表,然后点击右上角的"创建桶"按钮
在桶名称输入devkit,依次选择"单AZ存储",“公共读”,企业项目选择“default”,点击立即创建,然后确定

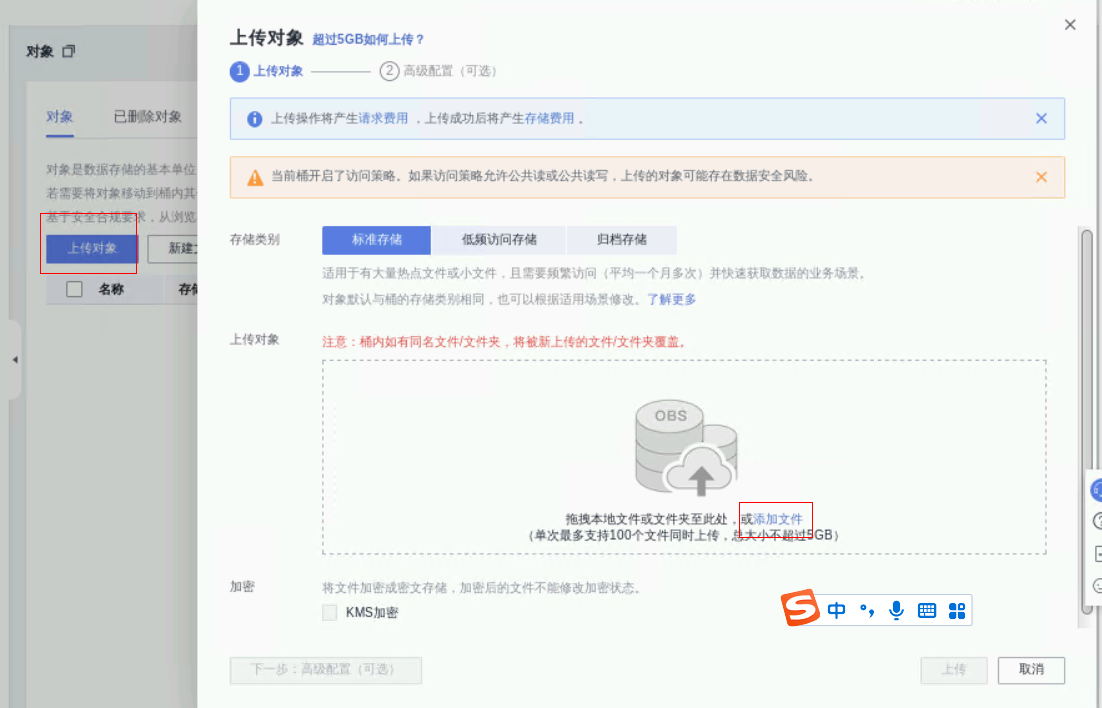
创建完成后进入刚刚创建的桶,点击上传对象,添加文件,选中刚刚生成的文件(/home/user/devkit-sis/devkit.wav)后,点击上传,刚刚生成的音频就会上传到OBS桶中
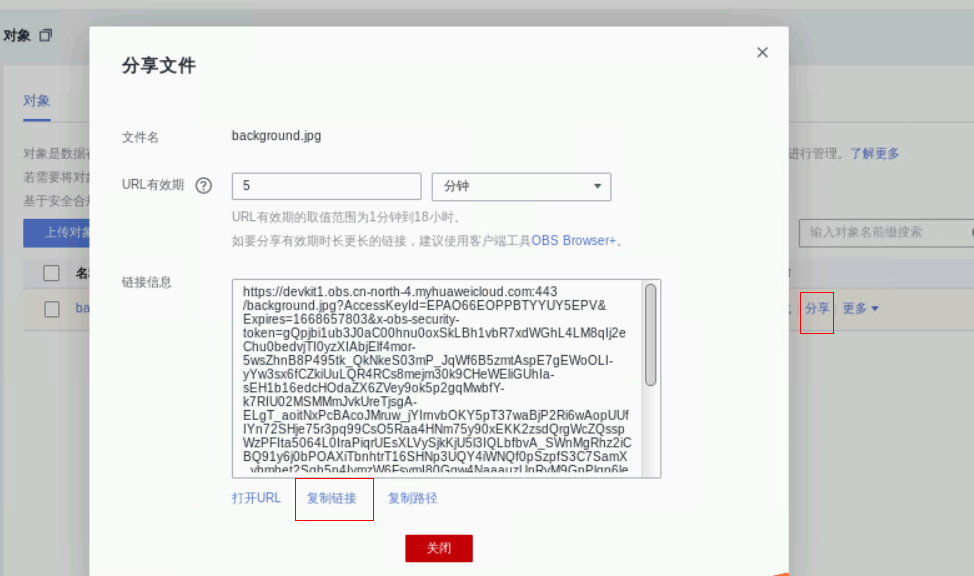
选中刚刚上传的对象,点击右侧的分享按钮,弹窗中选择复制链接,再通过沙箱实验中的剪贴板功能,将链接复制到用户的本地,用浏览器打开后,本地即可体验到刚刚生成的音频文件

- 点赞
- 收藏
- 关注作者
评论(0)