CDH+Kylin三部曲之三:Kylin官方demo

欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
- 本文是《CDH+Kylin三部曲》系列的终篇,先简单回顾前面的内容:
- 《CDH+Kylin三部曲之一:准备工作》:准备好机器、脚本、安装包;
- 《CDH+Kylin三部曲之二:部署和设置》:完成CDH和Kylin部署,并在管理页面做好相关的设置;
- 现在Hadoop、Kylin都就绪了,接下来实践Kylin的官方demo;
Yarn参数设置
- Yarn的内存参数设置之后一定要重启Yarn使之生效,否则Kylin提交的任务是会由于资源限制而无法执行;
关于Kylin官方demo
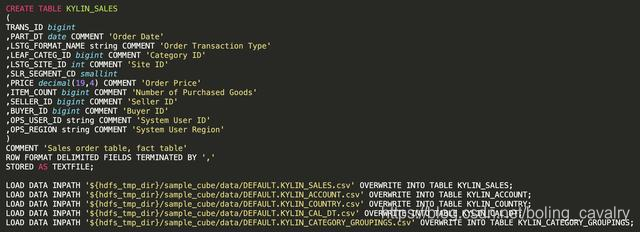
- 下图是官方demo的脚本的一部分(create_sample_tables.sql),基于HDFS数据创建Hive表:

- 通过脚本可见KYLIN_SALES为事实表,其他是维度表,并且KYLIN_ACCOUNT和KYLIN_COUNTRY存在关联,因此维度模型符合Snowflake Schema;
导入样例数据
- SSH登录CDH服务器
- 切换到hdfs账号:su - hdfs
- 执行导入命令:${KYLIN_HOME}/bin/sample.sh
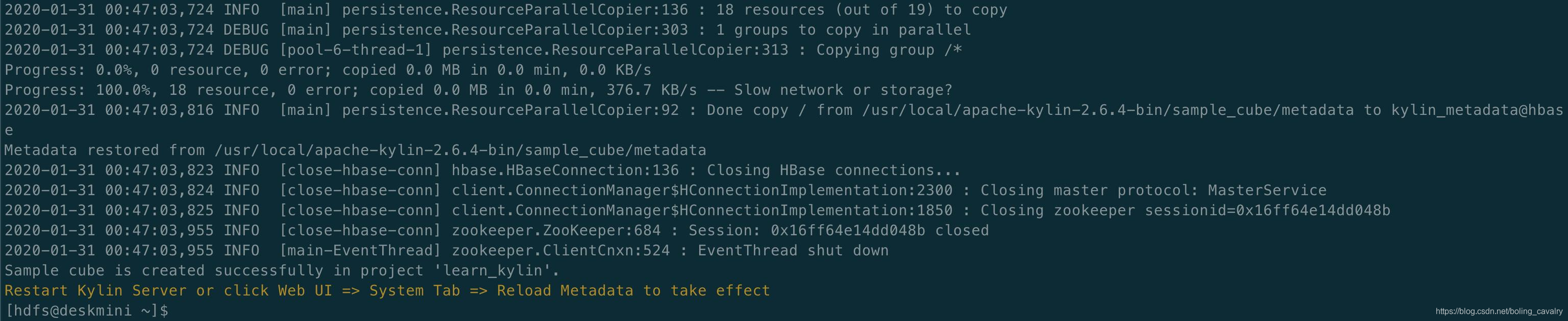
- 导入成功,控制台输出如下:
检查数据
- 检查数据,执行beeline进入会话模式(hive官方推荐用beeline取代Hive CLI):
- 在beeline会话模式输入链接URL:!connect jdbc:hive2://localhost:10000,按照提示输入账号hdfs,密码直接回车:
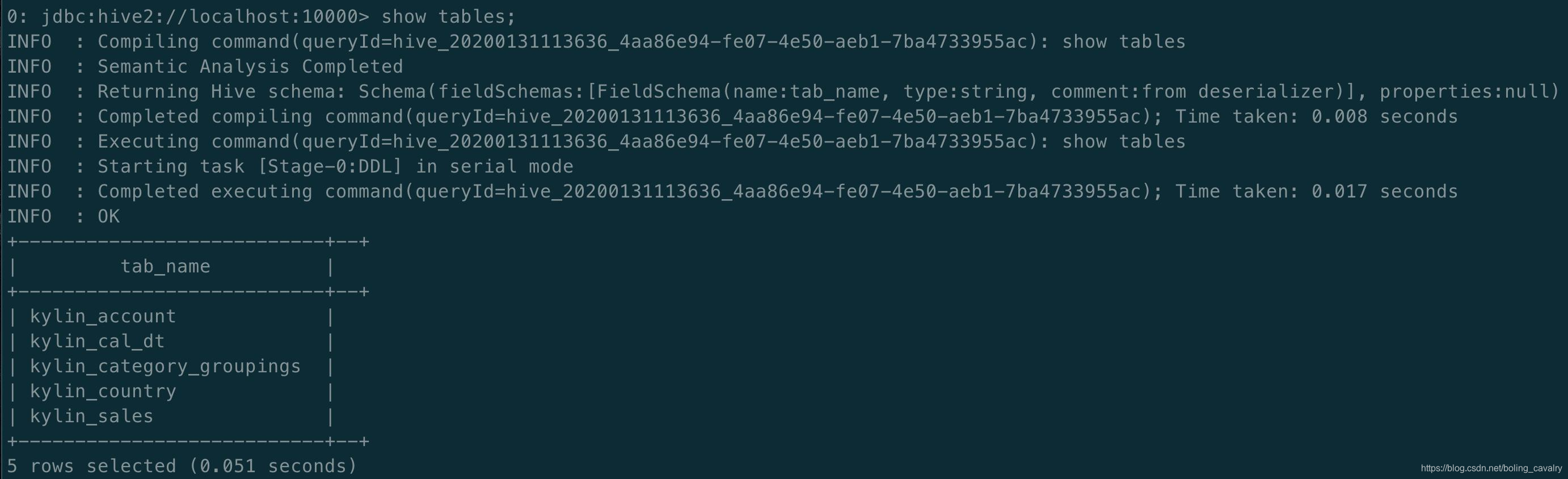
- 用命令show tables查看当前的hive表,已建好:
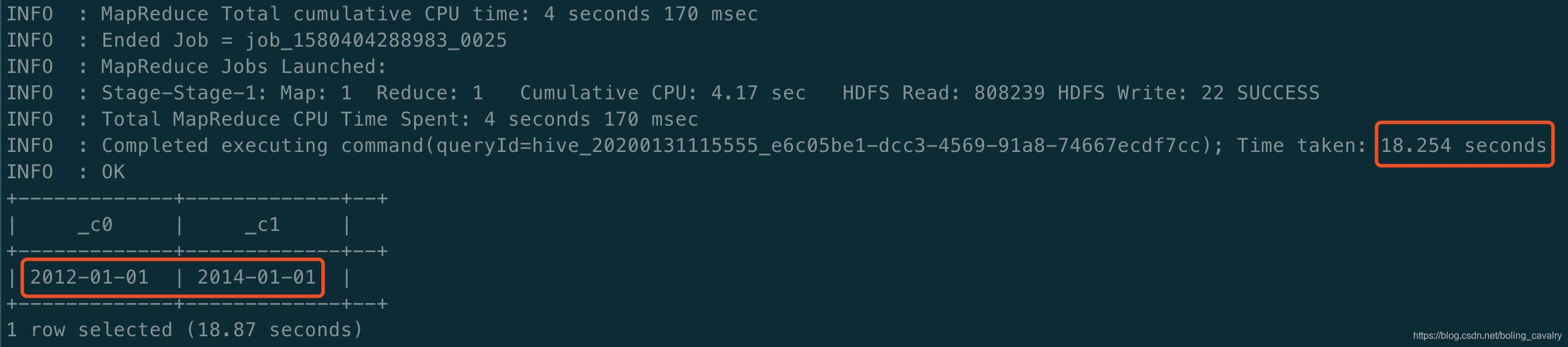
- 查出订单的最早和最晚时间,后面构建Cube的时候会用到,执行SQL:select min(PART_DT), max(PART_DT) from kylin_sales; ,可见最早2012-01-01,最晚2014-01-01,整个查询耗时18.87秒:

构建Cube:
-
数据准备完成,可以构建Kylin Cube了:
-
登录Kylin网页:http://192.168.50.134:7070/kylin
-
加载Meta数据,如下图:
-
如下图红框所示,数据加载成功:
-
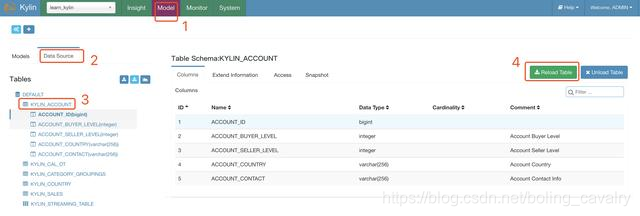
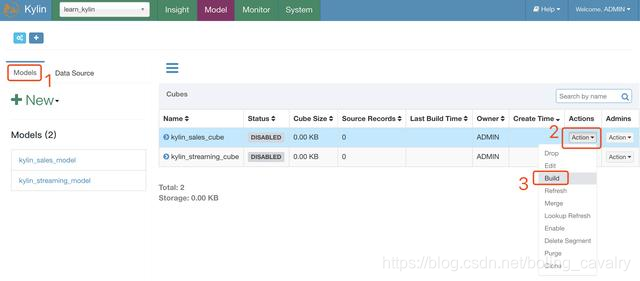
在Model页面可以看到事实表和维度表,如下图的操作可以创建一个MapReduce任务,计算维度表KYLIN_ACCOUNT每个列的基数(Cardinality):
-
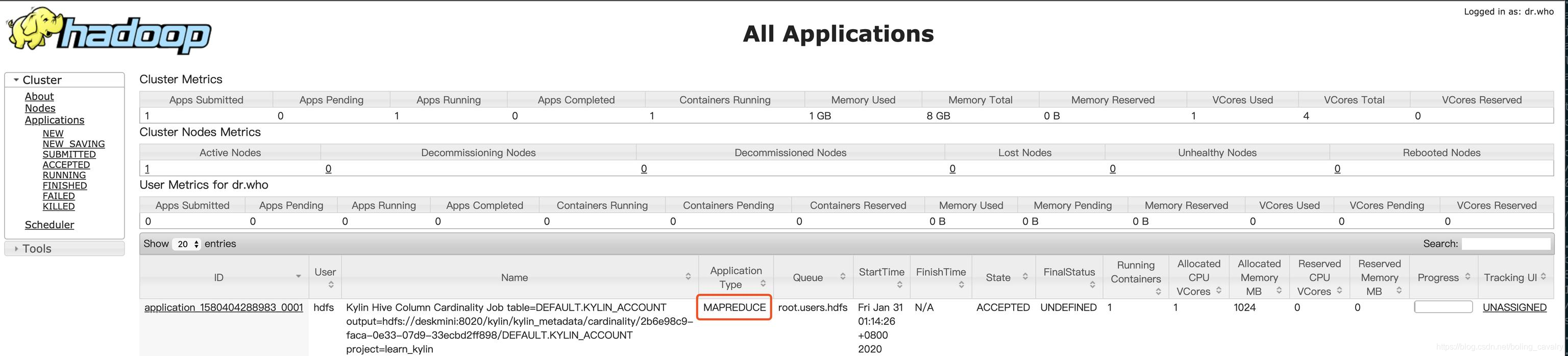
去Yarn页面(CDH服务器的8088端口),如下图,可见有个MapReduce类型的任务正在执行中:
-
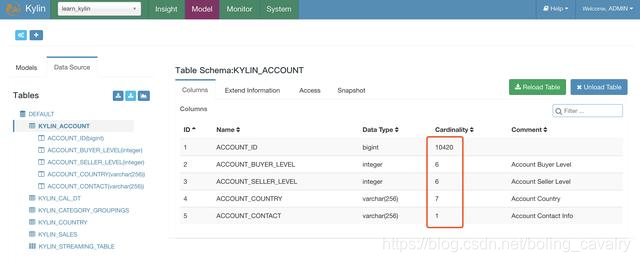
上述任务很快就能完成(10多秒),此时刷新Kylin页面,可见KYLIN_ACCOUNT表的Cardinality数据已经计算完成了(hive查询得到ACCOUNT_ID数量是10000,但下图的Cardinality值为10420,Kylin对Cardinality的计算采用的是HyperLogLog的近似算法,与精确值有误差,其他四个字段的Cardinality与Hive查询结果一致):
-
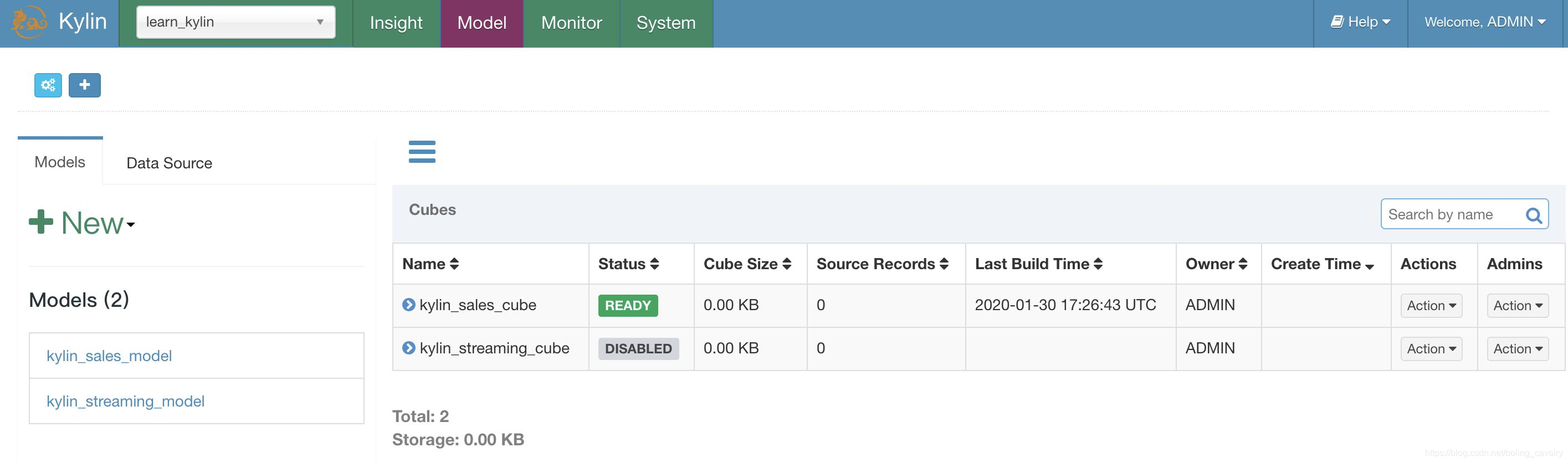
接下来开始构建Cube:
-
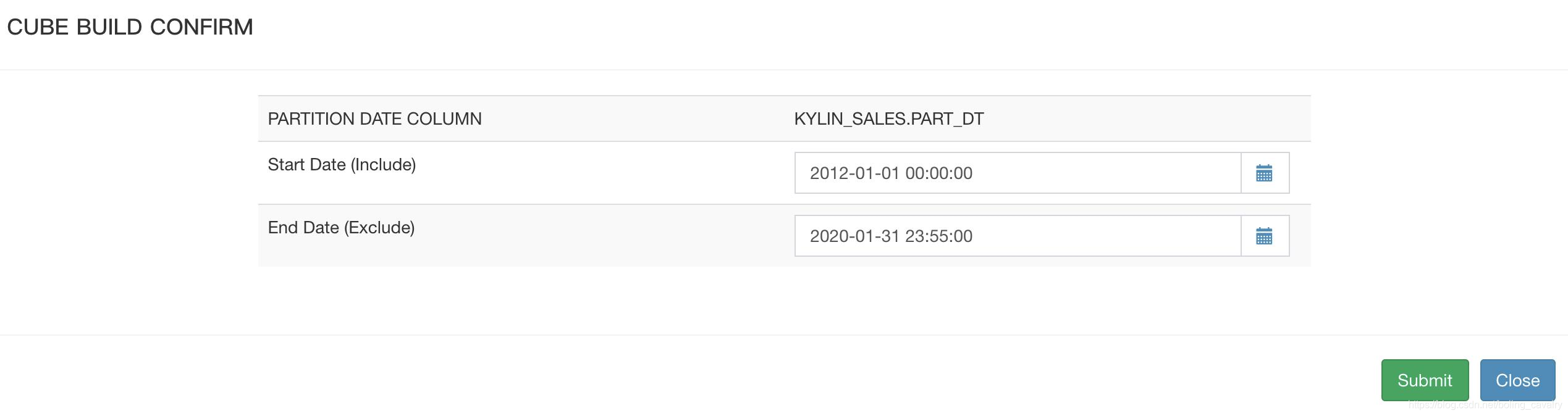
日期范围,刚才Hive查询结果是2012-01-01到2014-01-01,注意截止日期要超过2014-01-01:
-
在Monitor页面可见进度:
-
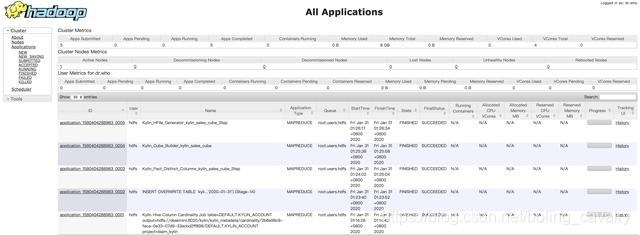
去Yarn页面(CDH服务器的8088端口),可以看到对应的任务和资源使用情况:
-
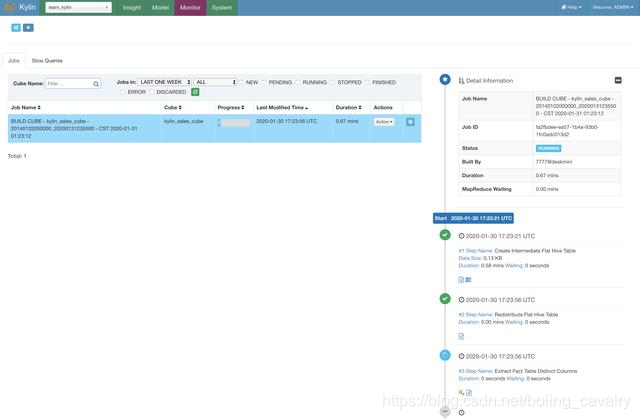
build完成后,会出现ready图标:
查询
- 先尝试查询交易的最早和最晚时间,这个查询在Hive上执行的耗时是18.87秒,如下图,结果一致,耗时0.14秒:
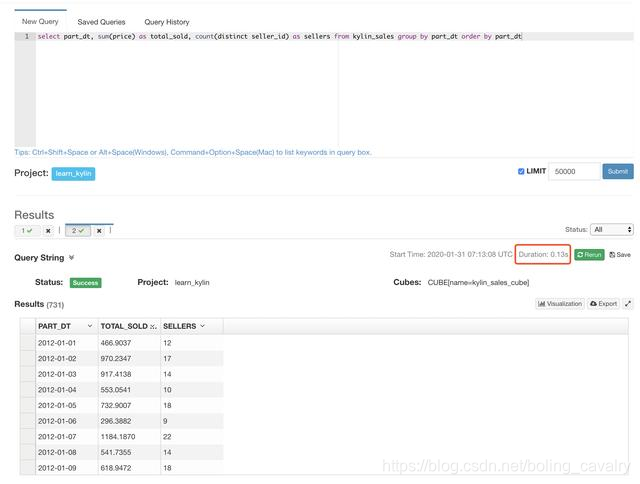
- 下面这个SQL是Kylin官方示例用来对比响应时间的,对订单按日期聚合,再按日期排序,然后接下来分别用Kylin和Hive查询:

select part_dt, sum(price) as total_sold, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt;
-
Kylin查询耗时0.13秒:
-
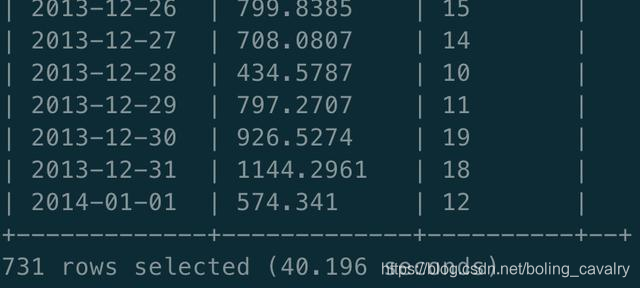
Hive查询,结果相同,耗时40.196秒:
-
最后来看下资源使用情况,Cube构建过程中,18G内存被使用:
-
至此,CDH+Kylin从部署到体验就已完成,《CDH+Kylin三部曲》系列也结束了,如果您正在学习Kylin,希望本文能够给您一些参考。
欢迎关注华为云博客:程序员欣宸

- 点赞
- 收藏
- 关注作者
评论(0)