PGL图学习项目合集&数据集分享&技术归纳业务落地技巧[系列十]

PGL图学习项目合集&数据集分享&技术归纳业务落地技巧[系列十]
1.PGL图学习项目合集
1.1 关于图计算&图学习的基础知识概览:前置知识点学习(PGL)[系列一] :https://aistudio.baidu.com/aistudio/projectdetail/4982973?contributionType=1
本项目对图基本概念、关键技术(表示方法、存储方式、经典算法),应用等都进行详细讲解,并在最后用程序实现各类算法方便大家更好的理解。当然之后所有图计算相关都是为了知识图谱构建的前置条件
1.2 图机器学习(GML)&图神经网络(GNN)原理和代码实现(前置学习系列二)
https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1
现在已经覆盖了图的介绍,图的主要类型,不同的图算法,在Python中使用Networkx来实现它们,以及用于节点标记,链接预测和图嵌入的图学习技术,最后讲了GNN分类应用以及未来发展方向!
1.3 图学习初探Paddle Graph Learning 构建属于自己的图【系列三】
https://aistudio.baidu.com/aistudio/projectdetail/5000517?contributionType=1
本项目主要讲解了图学习的基本概念、图的应用场景、以及图算法,最后介绍了PGL图学习框架并给出demo实践,过程中把老项目demo修正版本兼容问题等小坑,并在最新版本运行便于后续同学更有体验感
1.4 PGL图学习之图游走类node2vec、deepwalk模型[系列四]
https://aistudio.baidu.com/aistudio/projectdetail/5002782?contributionType=1
介绍了图嵌入原理以及了图嵌入中的DeepWalk、node2vec算法,利用pgl对DeepWalk、node2vec进行了实现,并给出了多个框架版本的demo满足个性化需求。
- 图学习【参考资料1】词向量word2vec https://aistudio.baidu.com/aistudio/projectdetail/5009409?contributionType=1
介绍词向量word2evc概念,及CBOW和Skip-gram的算法实现。
- 图学习【参考资料2】-知识补充与node2vec代码注解https://aistudio.baidu.com/aistudio/projectdetail/5012408?contributionType=1
主要引入基本的同构图、异构图知识以及基本概念;同时对deepWalk代码的注解以及node2vec、word2vec的说明总结;(以及作业代码注解)
1.5 PGL图学习之图游走类metapath2vec模型[系列五]
https://aistudio.baidu.com/aistudio/projectdetail/5009827?contributionType=1
介绍了异质图,利用pgl对metapath2vec以及metapath2vec变种算法进行了实现,同时讲解实现图分布式引擎训练,并给出了多个框架版本的demo满足个性化需求。
1.6 PGL图学习之图神经网络GNN模型GCN、GAT[系列六] [https://aistudio.baidu.com/aistudio/projectdetail/5054122?contributionType=1](https://aistudio.baidu.com/aistudio/projectdetail/5054122?c
ontributionType=1)
本次项目讲解了图神经网络的原理并对GCN、GAT实现方式进行讲解,最后基于PGL实现了两个算法在数据集Cora、Pubmed、Citeseer的表现,在引文网络基准测试中达到了与论文同等水平的指标。
1.7 PGL图学习之图神经网络GraphSAGE、GIN图采样算法[系列七] https://aistudio.baidu.com/aistudio/projectdetail/5061984?contributionType=1
本项目主要讲解了GraphSage、PinSage、GIN算法的原理和实践,
并在多个数据集上进行仿真实验,基于PGl实现原论文复现和对比,也从多个角度探讨当前算法的异同以及在工业落地的技巧等。
1.8 PGL图学习之图神经网络ERNIESage、UniMP进阶模型[系列八]
https://aistudio.baidu.com/aistudio/projectdetail/5096910?contributionType=1
ErnieSage 可以同时建模文本语义与图结构信息,有效提升 Text Graph 的应用效果;UniMP 在概念上统一了特征传播和标签传播, 在OGB取得了优异的半监督分类结果。
- PGL图学习之ERNIESage算法实现(1.8x版本)【系列八】
https://aistudio.baidu.com/aistudio/projectdetail/5097085?contributionType=1
ERNIESage运行实例介绍(1.8x版本),提供多个版本pgl代码实现
1.9 PGL图学习之项目实践(UniMP算法实现论文节点分类、新冠疫苗项目)[系列九]
https://aistudio.baidu.com/aistudio/projectdetail/5100049?contributionType=1
本项目借鉴了百度高研黄正杰大佬对图神经网络技术分析以及图算法在业务侧应用落地;实现了论文节点分类和新冠疫苗项目的实践帮助大家更好理解学习图的魅力。
- PGL图学习之基于GNN模型新冠疫苗任务[系列九]
https://aistudio.baidu.com/aistudio/projectdetail/5123296?contributionType=1
图神经网络7日打卡营的新冠疫苗项目拔高实战
- PGL图学习之基于UniMP算法的论文引用网络节点分类任务[系列九]
https://aistudio.baidu.com/aistudio/projectdetail/5116458?contributionType=1
基于UniMP算法的论文引用网络节点分类,在调通UniMP之后,后续尝试的技巧对于其精度的提升效力微乎其微,所以不得不再次感叹百度PGL团队的强大!
༄ℳ持续更新中ꦿོ࿐
2.图网络开放数据集
按照任务分类,可以把数据集分成以下几类:
- 引文网络
- 生物化学图
- 社交网络
- 知识图谱
- 开源数据集仓库
2.1 引文网络
1. Pubmed/Cora/Citeseer|
这三个数据集均来自于:《Collective classification in network data》
引文网络,节点为论文、边为论文间的引用关系。这三个数据集通常用于链路预测或节点分类。
数据下载链接:
https://aistudio.baidu.com/aistudio/datasetdetail/177587
https://aistudio.baidu.com/aistudio/datasetdetail/177589
https://aistudio.baidu.com/aistudio/datasetdetail/177591
INQS 实验室使用的数据集和所有展示的关系结构,数据集链接:https://linqs.org/datasets/
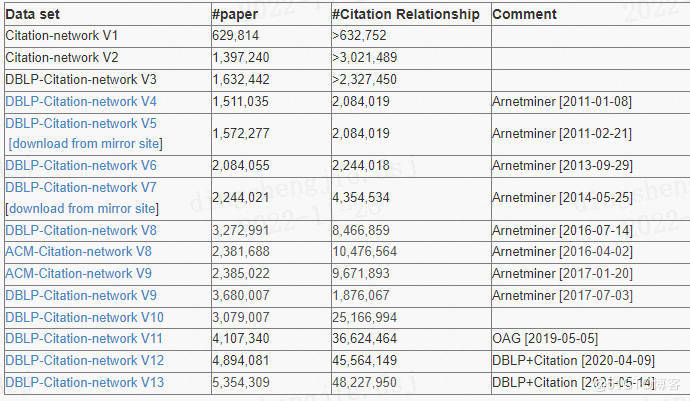
2. DBLP
DBLP是大型的计算机类文献索引库。原始的DBLP只是XML格式,清华唐杰教授的一篇论文将其进行处理并获得引文网络数据集。到目前为止已经发展到了第13个版本。
DBLP引用网络论文:
《ArnetMiner: Extraction and Mining of Academic Social Networks》
原始数据可以从这里获得:
https://dblp.uni-trier.de/xml/
如果是想找处理过的DBLP引文网络数据集,可以从这里获得:
https://www.aminer.cn/citation
2.2 生物化学图
1. PPI
蛋白质-蛋白质相互作用(protein-protein interaction, PPI)是指两个或两个以上的蛋白质分子通过非共价键形成 蛋白质复合体(protein complex)的过程。
PPI数据集中共有24张图,其中训练用20张,验证/测试分别2张。
节点最多可以有121种标签(比如蛋白质的一些性质、所处位置等)。每个节点有50个特征,包含定位基因集合、特征基因集合以及免疫特征。
PPI论文:
《Predicting multicellular function through multi-layer tissue networks》
PPI下载链接:
http://snap.stanford.edu/graph
2. NCI-1
NCI-1是关于化学分子和化合物的数据集,节点代表原子,边代表化学键。NCI-1包含4100个化合物,任务是判断该化合物是否有阻碍癌细胞增长的性质。
NCI-1论文:
《Comparison of descriptor spaces for chemical compound retrieval and classification》
Graph Kernel Datasets提供下载
3. MUTAG
MUTAG数据集包含188个硝基化合物,标签是判断化合物是芳香族还是杂芳族。
MUTAG论文:
《Structure-activity relationship of mutagenic aromatic and heteroaromatic nitro compounds. correlation with molecular orbital energies and hydrophobicity》
https://aistudio.baidu.com/aistudio/datasetdetail/177591
4. D&D/PROTEIN
D&D在蛋白质数据库的非冗余子集中抽取了了1178个高分辨率蛋白质,使用简单的特征,如二次结构含量、氨基酸倾向、表面性质和配体;其中节点是氨基酸,如果两个节点之间的距离少于6埃(Angstroms),则用一条边连接。
PROTEIN则是另一个蛋白质网络。任务是判断这类分子是否酶类。
D&D论文:
《Distinguishing enzyme structures from non-enzymes without alignments》
D&D下载链接:
https://github.com/snap-stanford/GraphRNN/tree/master/dataset/DD
PROTEIN论文:
《Protein function prediction via graph kernels》
Graph Kernel Datasets提供下载
5. PTC
PTC全称是预测毒理学挑战,用来发展先进的SAR技术预测毒理学模型。这个数据集包含了针对啮齿动物的致癌性标记的化合物。
根据实验的啮齿动物种类,一共有4个数据集:
PTC_FM(雌性小鼠)
PTC_FR(雌性大鼠)
PTC_MM(雄性小鼠)
PTC_MR(雄性大鼠)
PTC论文:
《Statistical evaluation of the predictive toxicology challenge 2000-2001》
Graph Kernel Datasets提供下载
6. QM9
这个数据集有133,885个有机分子,包含几何、能量、电子等13个特征,最多有9个非氢原子(重原子)。来自GDB-17数据库。
QM9论文:
《Quantum chemistry structures and properties of 134 kilo molecules》
QM9下载链接:
http://quantum-machine.org/datasets/
7. Alchemy
Alchemy包含119,487个有机分子,其有12个量子力学特征(quantum mechanical properties),最多14个重原子(heavy atoms),从GDB MedChem数据库中取样。扩展了现有分子数据集多样性和容量。
Alchemy论文:
《Alchemy: A quantum chemistry dataset for benchmarking ai models》
Alchemy下载链接:
https://alchemy.tencent.com/
2.3 社交网络
1. Reddit
Reddit数据集是由来自Reddit论坛的帖子组成,如果两个帖子被同一人评论,那么在构图的时候,就认为这两个帖子是相关联的,标签是每个帖子对应的社区分类。
Reddit论文:《Inductive representation learning on large graphs》
Reddit下载链接:
https://aistudio.baidu.com/aistudio/datasetdetail/177810
https://github.com/linanqiu/reddit-dataset
BlogCatalog
BlogCatalog数据集是一个社会关系网络,图是由博主及其社会关系(比如好友)组成,标签是博主的兴趣爱好。
2.BlogCatalog论文:
《Relational learning via latent social dimensions》BlogCatalog下载链接:
http://socialcomputing.asu.edu
2.4 知识图谱
1.FB13/FB15K/FB15K237
这三个数据集是Freebase的子集。其中:
FB13:包含13种关系、75043个实体。
FB15K:包含1345种关系、14951个实体
FB15K237:包含237种关系、14951个实体
如果希望找到entity id对应的实体数据,可以通过以下渠道(并不是所有的实体都能找到):
https://developers.google.com/freebase/#freebase-wikidata-mappings
http://sameas.org/
2.WN11/WN18/WN18RR
这三个是WordNet的子集:
WN11:包含11种关系、38696个实体
WN18:包含18种关系、40943个实体
WN18RR:包含11种关系、40943个实体
为了避免在评估模型时出现inverse relation test leakage,建议使用FB15K237/WN18RR来替代FB15K/WN18。更多建议阅读《Convolutional 2D Knowledge Graph Embeddings》
FB15K/WN8论文:
《Translating Embeddings for Modeling Multi-relational Data》
FB13/WN11论文:
《Reasoning With Neural Tensor Networks for Knowledge Base Completion》
WN18RR论文:
《Convolutional 2D Knowledge Graph Embeddings》
以上6个知识图谱数据集均可从这里下载:
https://github.com/thunlp/OpenKE/tree/master/benchmarks
2.5 开源数据仓库
1. Network Repository
具有交互式可视化和挖掘工具的图数据仓库。具有以下特点:
- 用表格的形式展示每一个图数据集的节点数、遍数、平均度数、最大度数等。
- 可视化对比图数据集之间的参数。
- 在线GraphVis,可视化图结构和详细参数。

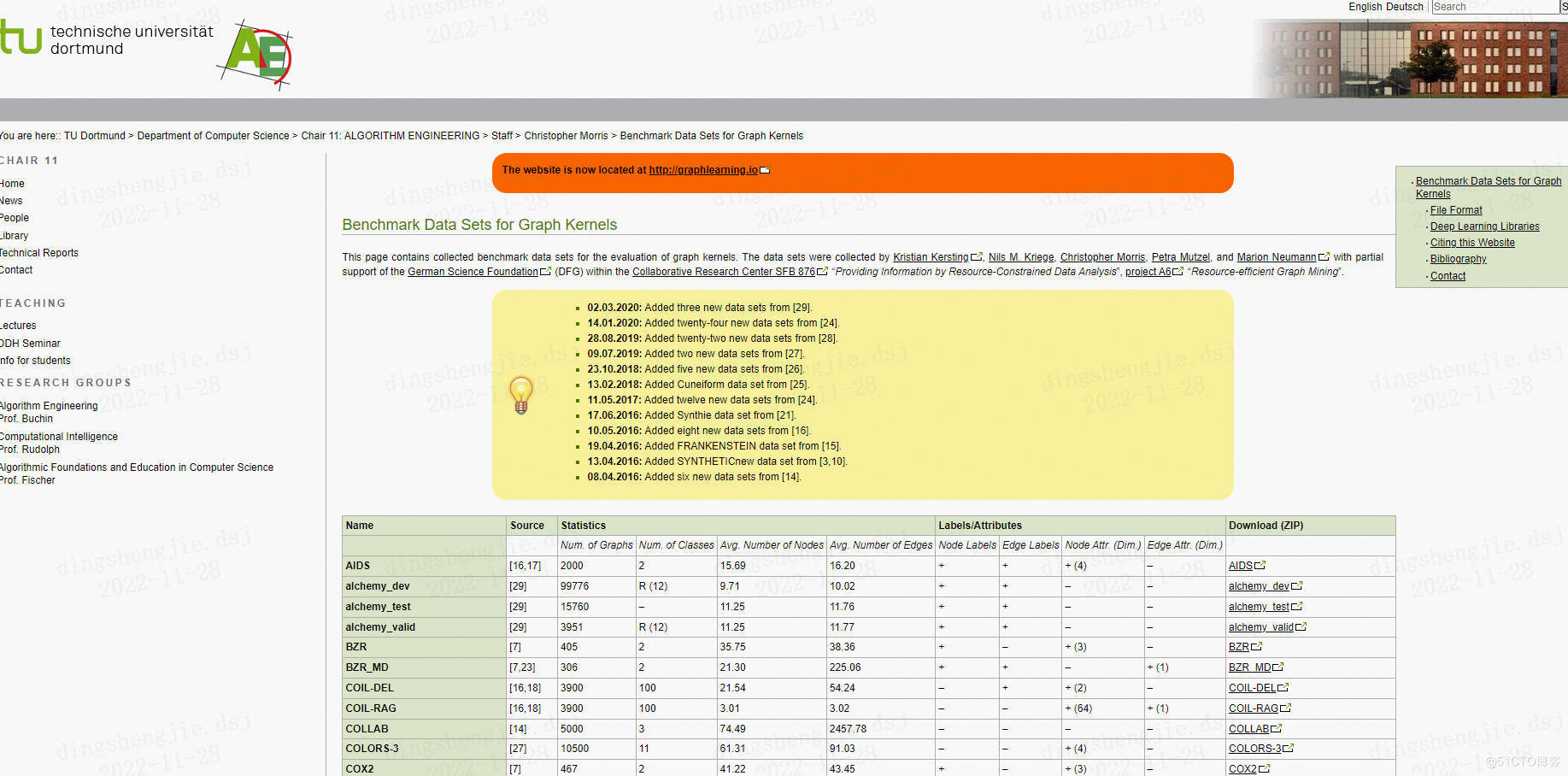
2. Graph Kernel Datasets
图核的基准数据集。提供了一个表格,可以快速得到每个数据集的节点数量、类别数量、是否有节点/边标签、节点/边特征。
https://ls11-www.cs.tu-dortmund.de/staff/morris/graphkerneldatasets
https://chrsmrrs.github.io/datasets/
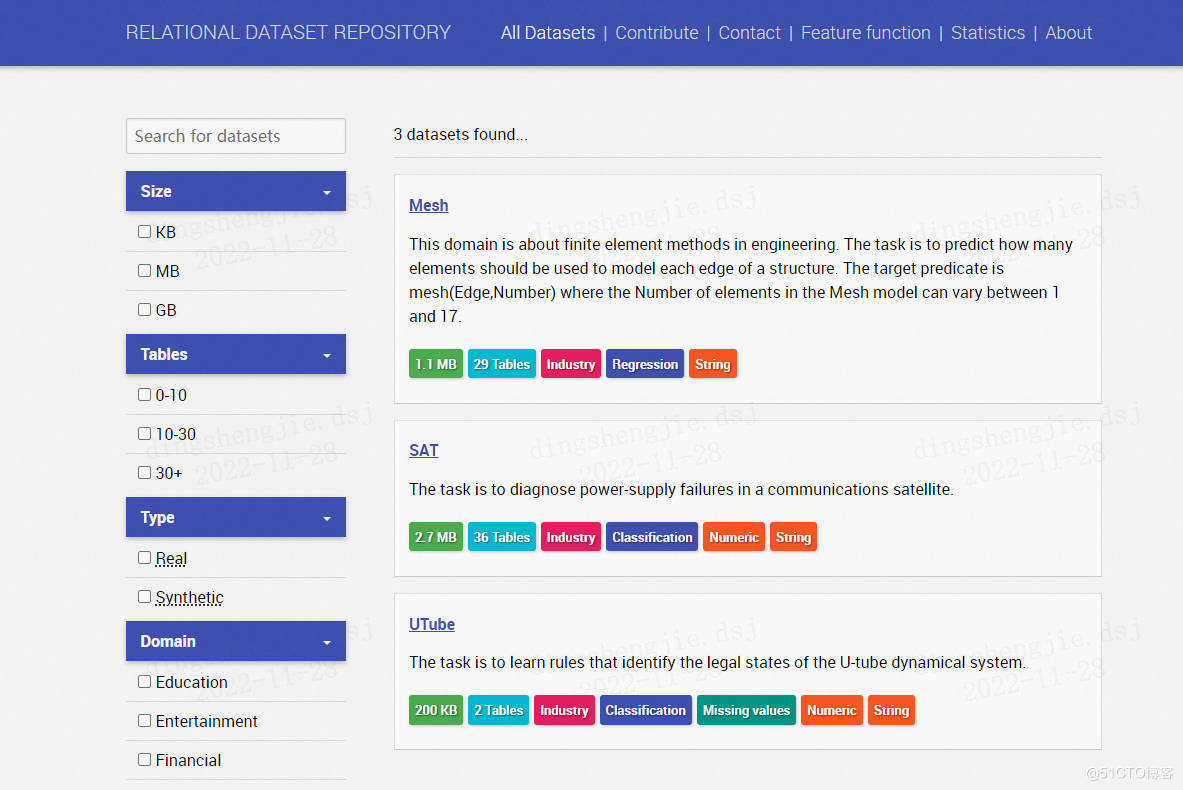
3. Relational Dataset Repository
关系机器学习的数据集集合。能够以数据集大小、领域、数据类型等条件来检索数据集。
https://relational.fit.cvut.cz
https://relational.fit.cvut.cz/search?domain[]=Industry
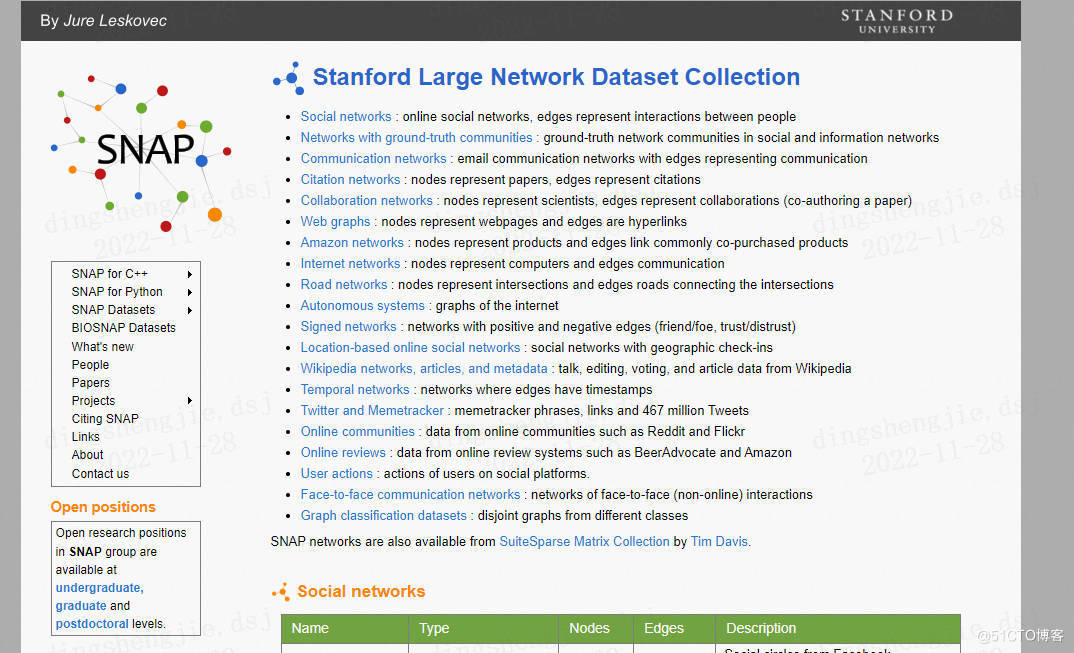
4. Stanford Large Network Dataset Collection
SNAP库用于大型社交、信息网络。包括:图分类数据库、社交网络、引用网络、亚马逊网络等等,非常丰富。
https://snap.stanford.edu/data/
5.Open Graph Benchmark
OGB是真实基准数据集的集合,同时提供数据加载器和评估器(PyTorch)。可以自动下载、处理和切割;完全兼容PyG和DGL。
这个大家就比较熟悉了,基本最先进的图算法都是依赖OGB的数据集验证的。
௸持续更新敬请期待~ೄ೨✿
3.图学习相关技术归纳
3.1 GraphSAGE为例技术归纳
-
- GCN和GraphSAGE区别
GCN灵活性差、为新节点产生embedding要求 额外的操作 ,比如“对齐”:
GCN是 直推式(transductive) 学习,无法直接泛化到新加入(未见过)的节点;
GraphSAGE是 归纳式(inductive) 学习,可以为新节点输出节点特征。
GCN输出固定:
GCN输出的是节点 唯一确定 的embedding;
GraphSAGE学习的是节点和邻接节点之间的关系,学习到的是一种映射关系 ,节点的embedding可以随着其邻接节点的变化而变化。
GCN很难应用在超大图上:
无论是拉普拉斯计算还是图卷积过程,因为GCN其需要对 整张图 进行计算,所以计算量会随着节点数的增加而递增。
GraphSAGE通过采样,能够形成 minibatch 来进行批训练,能用在超大图上。
2.GraphSAGE等模型优点:
- 采用 归纳学习 的方式,学习邻居节点特征关系,得到泛化性更强的embedding;
- 采样技术,降低空间复杂度,便于构建minibatch用于 批训练 ,还让模型具有更好的泛化性;
- 多样的聚合函数 ,对于不同的数据集/场景可以选用不同的聚合方式,使得模型更加灵活。
GraphSAGE的基本思路是:利用一个 聚合函数 ,通过 采样 和学习聚合节点的局部邻居特征,来为节点产生embedding。
- 3.跳数(hops)、搜索深度(search depth)、阶数(order)有啥区别?
我们经常听到一阶邻居、二阶邻居,1-hops、2-hops等等,其实他们都是一个概念,就是该节点和目标节点的路径长度,如果路径长度是1,那就是一阶邻接节点、1-hops node。
搜索深度其实和深度搜索的深度的概念相似,也是用路径长度来衡量。
简单来说,这几个概念某种程度上是等价。
在GraphSAGE中,还有聚合层数\迭代次数,比如说只考虑了一阶邻接节点,那就只有一层聚合(迭代了一次),以此类推。
- 4.采样有什么好处
于对计算效率的考虑,对每个节点采样一定数量的邻接节点作为待聚合信息的节点。
从训练效率考虑:通过采样,可以得到一个 固定大小 的领域集,可以拼成一个batch,送到GPU中进行批训练。
从复杂度角度考虑:如果没有采样,单个batch的内存使用和预期运行时间是 不可预测 的;最坏的情况是,即所有的节点都是目标节点的邻接节点。而GraphSAGE的每个batch的空间和时间复杂度都是 固定 的其中K是指层数,也就是要考虑多少阶的邻接节点,是在第i层采样的数量。
- 5.采样数大于邻接节点数怎么办?
设采样数量为K:若节点邻居数少于K,则采用 有放回 的抽样方法,直到采样出K个节点。
若节点邻居数大于K,则采用 无放回 的抽样。
关于邻居的个数,文中提到,即两次扩展的邻居数之积小于500,大约每次只需要扩展20来个邻居时获得较高的性能。
实验中也有关于邻居采样数量的对比,如下图,随着邻居抽样数量的递增,边际效益递减,而且计算时间也会增大。
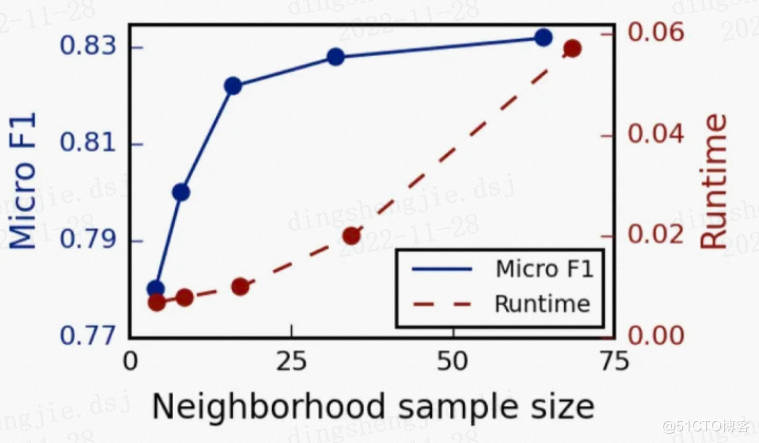
- 6.每一跳采样需要一样吗?
不需要,可以分别设置每一跳的采样数量,来进一步缓解因 阶数越高涉及到的节点越多 的问题。
原文中,一阶采样数是25,二阶采样数是10。这时候二阶的节点总数是250个节点,计算量大大增加。
- 7.聚合函数的选取有什么要求?
由于在图中节点的邻居是 天然无序 的,所以我们希望构造出的聚合函数是 对称 的(即改变输入的顺序,函数的输出结果不变),同时具有 较强的表达能力 (比如可以参数学习)。
- 8.GraphSAGE论文中提供多少种聚合函数?
原文中提供三种聚合函数:
- 均值聚合
- pooling聚合(max-pooling/mean-pooling)
- LSTM聚合
均值聚合的操作:
把目标节点和邻居节点的特征 纵向拼接 起来 ;对拼接起来的向量进行 纵向均值化 操作
将得到的结果做一次 非线性变换 产生目标节点的向量表征。
pooling聚合的操作:先对邻接节点的特征向量进行一次非线性变换;之后进行一次pooling操作(max-pooling or mean-pooling) ;将得到结果与第k-1层的目标节点的表示向量拼接
;最后再经过一次非线性变换得到目标节点的第k层表示向量。
使用LSTM聚合时需要注意什么?
复杂结构的LSTM相比简单的均值操作具有更强的表达能力,然而由于LSTM函数 不是关于输入对称 的,所以在使用时需要对节点的邻居进行 乱序操作 。
- 9.均值聚合和其他聚合函数有啥区别?
除了聚合方式,最大的区别在于均值聚合 没有拼接操作 (算法1的第五行),也就是均值聚合不需要把 当前节点上一层的表征 拼接到 已聚合的邻居表征上。
这一拼接操作可以简单看成不同“搜索深度”之间的“ skip connection ”(残差结构),并且能够提供显著的性能提升。
- 10 这三种聚合方法,哪种比较好?
如果按照其学习参数数量来看,LSTM > Pooling > 均值聚合。
而在实验中也发现,在Reddit数据集中,LSTM和max-pooling的效果确实比均值聚合要好一些。
- 11.一般聚合多少层?层数越多越好吗?
和GCN一样,一般只需要 1~2层 就能获得比较好的结果;如果聚合3层及以上,其时间复杂度也会随着层数的增加而大幅提升,而且效果并没有什么变化。
在GraphSAGE,两层比一层有10-15%的提升;但将层数设置超过2,边际效果上只有0-5%的提升,但是计算时间却变大了10-100倍。
- 12.什么时候和GCN的聚合形式“等价”?
聚合函数为 均值聚合 时,其聚合形式与GCN“近似等价”,也就是论文中提到的GraphSAGE-GCN。
- 13.GraphSAGE怎样进行无监督学习?
基本思想是:希望 邻近 的节点具有相似的向量表征,同时让 远处 的节点的表示尽可能区分。
通过负采样的方法,把邻近节点作为正样本,把远处节点作为负样本,使用类似word2vec的方法进行无监督训练。
GraphSAGE远近节点定义:
从 节点u 出发,能够通过 随机游走 到达的节点,则是邻近节点v;其他则是远处节点 。
- 13.GraphSAGE是怎么随机游走的?
在原文中,为每个节点进行50次步长为5的随机游走,随机游走的实现方式是直接使用DeepWalk的Python代码。
至于具体的实现,可以针对数据集来设计你的随机游走算法,比如考虑了权重的有偏游走。
GraphSAGE在采样的时候和(带权)随机游走进行负采样的时候,考虑边的权重了。
- 14.如果只有图、没有节点特征,能否使用GraphSAGE?
原文里有一段描述:our approach can also make use of structural features that are present in all graphs (e.g., node degrees). Thus, our algorithm can also be applied to graphs without node features.
所以就节点没有特征,但也可以根据其结构信息为其构建特征,比如说节点的度数等等
- 15.训练好的GraphSAGE如何得到节点Embedding?
假设GraphSAGE已经训练好,我们可以通过以下步骤来获得节点embedding
训练过程则只需要将其产生的embedding扔进损失函数计算并反向梯度传播即可。
-
对图中每个节点的邻接节点进行 采样 ,输入节点及其n阶邻接节点的特征向量
-
根据K层的 聚合函数 聚合邻接节点的信息
-
就产生了各节点的embedding
-
16.minibatch的子图是怎么得到的?
其实这部分看一下源码就容易理解了。下图的伪代码,就是在其前向传播之前,多了个minibatch的操作。
- 先对所有需要计算的节点进行采样(算法2中的2~7行)。用一个字典来保存节点及其对应的邻接节点。
- 然后训练时随机挑选n个节点作为一个batch,然后通过字典找到对应的一阶节点,进而找到二阶甚至更高阶的节点。这样一阶节点就形成一个batch,K=2时就有三个batch。
- 抽样时的顺序是:k–>k-1—>k-2;训练时,使用迭代的方式来聚合,其顺序是:k-2–>k-1—>k。简单来说,从上到下采样,形成每一层的batch;每一次迭代都从下到上,计算k-1层batch来获得k层的节点embedding,如此类推。
- 每一个minibatch只考虑batch里的节点的计算,不在的不考虑,所以这也是节省计算方法。
- 在算法2的第3行中,k-1<----k,也就是说采样邻居节点时,也考虑了自身节点的信息。相当于GCN中邻接矩阵增加单位矩阵。

增加了新的节点来训练,需要为所有“旧”节点重新输出embeding吗?
需要。因为GraphSAGE学习到的是节点间的关系,而增加了新节点的训练,这会使得关系参数发生变化,所以旧节点也需要重新输出embedding。
GraphSAGE有监督学习有什么不一样的地方吗?
没有。监督学习形式根据任务的不同,直接设置目标函数即可,如最常用的节点分类任务使用交叉熵损失函数。
- 17.那和DeepWalk、Node2vec这些有什么不一样?
DeepWalk、Node2Vec这些embedding算法直接训练每个节点的embedding,本质上依然是直推式学习,而且需要大量的额外训练才能使他们能预测新的节点。同时,对于embedding的正交变换(orthogonal transformations),这些方法的目标函数是不变的,这意味着生成的向量空间在不同的图之间不是天然泛化的,在再次训练(re-training)时会产生漂移(drift)。
与DeepWalk不同的是,GraphSAGE是通过聚合节点的邻接节点特征产生embedding的,而不是简单的进行一个embedding lookup操作得到。
3.2 PinSAGE为例技术归纳
- 1.PinSAGE论文中的数据集有多大?
论文中涉及到的数据为20亿图片(pins),10亿画板(boards),180亿边(pins与boards连接关系)。
用于训练、评估的完整数据集大概有18TB,而完整的输出embedding有4TB。
- 2.PinSAGE使用的是什么图?
在论文中,pins集合(用I表示)和boards集合(用C表示)构成了 二分图 ,即pins仅与boards相连接,pins或boards内部无连接。
同时,这二分图可以更加通用:
I 可以表示为 样本集 (a set of items),
C 可以表示为 用户定义的上下文或集合 (a set of user-defined contexts or collections)。
- 3.PinSAGE的任务是什么?
利用pin-board 二分图的结构与节点特征 ,为pin生成高质量的embedding用于下游任务,比如pins推荐。
- 4.和GraphSAGE相比,PinSAGE改进了什么?
- 采样 :使用重要性采样替代GraphSAGE的均匀采样;
- 聚合函数 :聚合函数考虑了边的权重;
- 生产者-消费者模式的minibatch构建 :在CPU端采样节点和构建特征,构建计算图;在GPU端在这些子图上进行卷积运算;从而可以低延迟地随机游走构建子图,而不需要把整个图存在显存中。
- 高效的MapReduce推理 :可以分布式地为百万以上的节点生成embedding,最大化地减少重复计算。
这里的计算图,指的是用于卷积运算的局部图(或者叫子图),通过采样来形成;与TensorFlow等框架的计算图不是一个概念。
- 4.PinSAGE使用多大的计算资源?
训练时,PinSAGE使用32核CPU、16张Tesla K80显卡、500GB内存;
推理时,MapReduce运行在378个d2.8xlarge Amazon AWS节点的Hadoop2集群。
落地业务真的可怕:
-
- PinSAGE和node2vec、DeepWalk这些有啥区别?
node2vec,DeepWalk是无监督训练;PinSAGE是有监督训练;
node2vec,DeepWalk不能利用节点特征;PinSAGE可以;
node2vec,DeepWalk这些模型的参数和节点数呈线性关系,很难应用在超大型的图上;
- 6.PinSAGE的单层聚合过程是怎样的?
和GraphSAGE一样,PinSAGE的核心就是一个 局部卷积算子 ,用来学习如何聚合邻居节点信息。PinSAGE的聚合函数叫做CONVOLVE。
主要分为3部分:
-
聚合 (第1行):k-1层邻居节点的表征经过一层DNN,然后聚合(可以考虑边的权重),是聚合函数符号,聚合函数可以是max/mean-pooling、加权求和、求平均;
-
更新 (第2行): 拼接 第k-1层目标节点的embedding,然后再经过另一层DNN,形成目标节点新的embedding;
-
归一化 (第3行): 归一化 目标节点新的embedding,使得训练更加稳定;而且归一化后,使用近似最近邻居搜索的效率更高。
-
为什么要将邻居节点的聚合embedding和当前节点的拼接?
因为根据T.N Kipf的GCN论文,concat的效果要比直接取平均更好。
- 7.PinSAGE是如何采样的?
如何采样这个问题从另一个角度来看就是:如何为目标节点构建邻居节点。和GraphSAGE的均匀采样不一样的是,PinSAGE使用的是重要性采样。PinSAGE对邻居节点的定义是:对目标节点 影响力最大 的T个节点。
PinSAGE的邻居节点的重要性其影响力的计算方法有以下步骤:
- 从目标节点开始随机游走;
- 使用 正则 来计算节点的“访问次数”,得到重要性分数;
- 目标节点的邻居节点,则是重要性分数最高的前T个节点。
这个重要性分数,其实可以近似看成Personalized PageRank分数。
- 8.重要性采样的好处是什么?
和GraphSAGE一样,可以使得 邻居节点的数量固定 ,便于控制内存/显存的使用。
在聚合邻居节点时,可以考虑节点的重要性;在PinSAGE实践中,使用的就是 加权平均 (weighted-mean),原文把它称作 importance pooling 。
- 9.采样的大小是多少比较好?
从PinSAGE的实验可以看出,随着邻居节点的增加,而收益会递减;
并且两层GCN在 邻居数为50 时能够更好的抓取节点的邻居信息,同时保持运算效率。
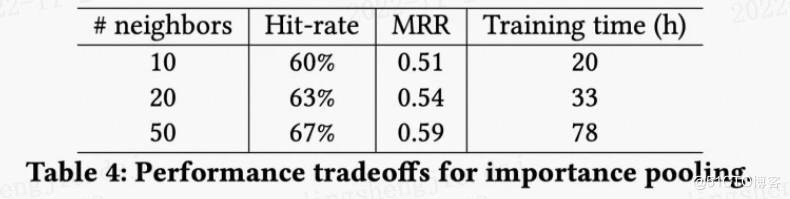
- 10.PinSAGE的minibatch和GraphSAGE区别:
基本一致,但细节上有所区别。比如说:GraphSAGE聚合时就更新了embedding;PinSAGE则在聚合后需要再经过一层DNN才更新目标embedding。
batch应该选多大
毕竟要在大量的样本上进行训练(有上亿个节点),所以原文里使用的batch比较大,大小为512~4096。
从下面表格可以看到, batch的大小为2048 时,能够在每次迭代时间、迭代次数和总训练时间上取得一个不错的综合性能。
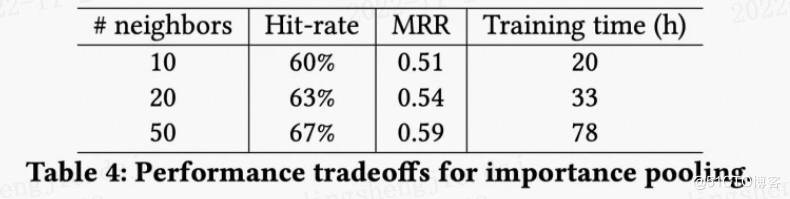
更多的就不展开了
4.业务落地技巧
-
负样本生成 首先是简单采样:在每个minibatch包含节点的范围之外随机采样500个item作为minibatch所有正样本共享的负样本集合。但考虑到实际场景中模型需要从20亿的物品item集合中识别出最相似的1000个,即要从2百万中识别出最相似的那一个,只是简单采样会导致模型分辨的粒度过粗,分辨率只到500分之一,因此增加一种“hard”负样本,即对于每个 对,和物品q有些相似但和物品i不相关的物品集合。这种样本的生成方式是将图中节点根据相对节点q的个性化PageRank分值排序,随机选取排序位置在2000~5000的物品作为“hard”负样本,以此提高模型分辨正负样本的难度。
-
渐进式训练(Curriculum training):如果训练全程都使用hard负样本,会导致模型收敛速度减半,训练时长加倍,因此PinSage采用了一种Curriculum训练的方式,这里我理解是一种渐进式训练方法,即第一轮训练只使用简单负样本,帮助模型参数快速收敛到一个loss比较低的范围;后续训练中逐步加入hard负样本,让模型学会将很相似的物品与些微相似的区分开,方式是第n轮训练时给每个物品的负样本集合中增加n-1个hard负样本。
-
样本的特征信息:Pinterest的业务场景中每个pin通常有一张图片和一系列的文字标注(标题,描述等),因此原始图中每个节点的特征表示由图片Embedding(4096维),文字标注Embedding(256维),以及节点在图中的度的log值拼接而成。其中图片Embedding由6层全连接的VGG-16生成,文字标注Embedding由Word2Vec训练得到。
-
基于random walk的重要性采样:用于邻居节点采样,这一技巧在上面的算法理解部分已经讲解过,此处不再赘述。
-
基于重要性的池化操作:这一技巧用于上一节Convolve算法中的 函数中,聚合经过一层dense层之后的邻居节点Embedding时,基于random walk计算出的节点权重做聚合操作。据论文描述,这一技巧在离线评估指标中提升了46%。
-
on-the-fly convolutions:快速卷积操作,这个技巧主要是相对原始GCN中的卷积操作:特征矩阵与全图拉普拉斯矩阵的幂相乘。涉及到全图的都是计算量超高,这里GraphSage和PinSage都是一致地使用采样邻居节点动态构建局部计算图的方法提升训练效率,只是二者采样的方式不同。
-
生产者消费者模式构建minibatch:这个点主要是为了提高模型训练时GPU的利用率。保存原始图结构的邻居表和数十亿节点的特征矩阵只能放在CPU内存中,GPU执行convolve卷积操作时每次从CPU取数据是很耗时的。为了解决这个问题,PinSage使用re-index技术创建当前minibatch内节点及其邻居组成的子图,同时从数十亿节点的特征矩阵中提取出该子图节点对应的特征矩阵,注意提取后的特征矩阵中的节点索引要与前面子图中的索引保持一致。这个子图的邻接列表和特征矩阵作为一个minibatch送入GPU训练,这样一来,convolve操作过程中就没有GPU与CPU的通信需求了。训练过程中CPU使用OpenMP并设计了一个producer-consumer模式,CPU负责提取特征,re-index,负采样等计算,GPU只负责模型计算。这个技巧降低了一半的训练耗时。
-
多GPU训练超大batch:前向传播过程中,各个GPU等分minibatch,共享一套参数,反向传播时,将每个GPU中的参数梯度都聚合到一起,执行同步SGD。为了适应海量训练数据的需要,增大batchsize从512到4096。为了在超大batchsize下快速收敛保证泛化精度,采用warmup过程:在第一个epoch中将学习率线性提升到最高,后面的epoch中再逐步指数下降。
-
使用MapReduce高效推断:模型训练完成后生成图中各个节点的Embedding过程中,如果直接使用上述PinSage的minibatch算法生成Embedding,会有大量的重复计算,如计算当前target节点的时候,其相当一部分邻居节点已经计算过Embedding了,而当这些邻居节点作为target节点的时候,当前target节点极有可能需要再重新计算一遍,这一部分的重复计算既耗时又浪费。
5.总结
本项目对PGL图学习系列项目进行整合方便大家后续学习,同时对图学习相关技术和业务落地侧进行归纳总结,以及对图网络开放数据集很多学者和机构发布了许多与图相关的任务。
༄ℳ后续将持续更新PGL以及前沿算法和应用,敬请期待! ꦿོ࿐

- 点赞
- 收藏
- 关注作者
评论(0)