数据驱动

大家好,我是bug郭,一名双非科班的在校大学生。对C/JAVA、数据结构、Spring系列框架、Linux及MySql、算法等领域感兴趣,喜欢将所学知识写成博客记录下来。 希望该文章对你有所帮助!如果有错误请大佬们指正!共同学习交流
作者简介:
- CSDN java领域新星创作者blog.csdn.net/bug…
- 掘金LV3用户 juejin.cn/user/bug…
- 阿里云社区专家博主,星级博主,developer.aliyun.com/bug…
- 华为云云享专家 bbs.huaweicloud.com/bug…
数据驱动
之前我们的case都是数据和代码在一起编写。考虑如下场景:需要多次执行一个案例,比如baidu搜索,分别输入中文、英文、数字等进行搜索,这时候需要编写3个案例吗?有没有版本一次运行?
python 的unittest 没有自带数据驱动功能。所以如果使用unittest,同时又想使用数据驱动,那么就可以使用DDT来完成。
DDT安装地址:https://ddt.readthedocs.io/en/latest/
在cmd命令窗口输入下面命令即可!
pip install ddt
python setup.py install
可能
pip版本不够,可以使用版本更新命令
查看当前pip版本
pip show pip
更新pip版本
python -m pip install --upgrade pip

安装成功
ddt使用方法:
参考文档:http://ddt.readthedocs.io/en/latest/
dd.ddt:
装饰类,也就是继承自TestCase的类。
ddt.data:
装饰测试方法。参数是一系列的值。
ddt.file_data:
装饰测试方法。参数是文件名。文件可以是json 或者 yaml类型。
注意,如果文件以”.yml”或者”.yaml”结尾,ddt会作为yaml类型处理,其他所有文件都会作为json文件处理。
如果文件中是列表,每个列表的值会作为测试用例参数,同时作为测试用例方法名后缀显示。
如果文件中是字典,字典的key会作为测试用例方法的后缀显示,字典的值会作为测试用例参数。
ddt.unpack:
传递的是复杂的数据结构时使用。比如使用元组或者列表,添加unpack之后,ddt会自动把元组或者列表对应到多个参数上。字典也可以这样处理。
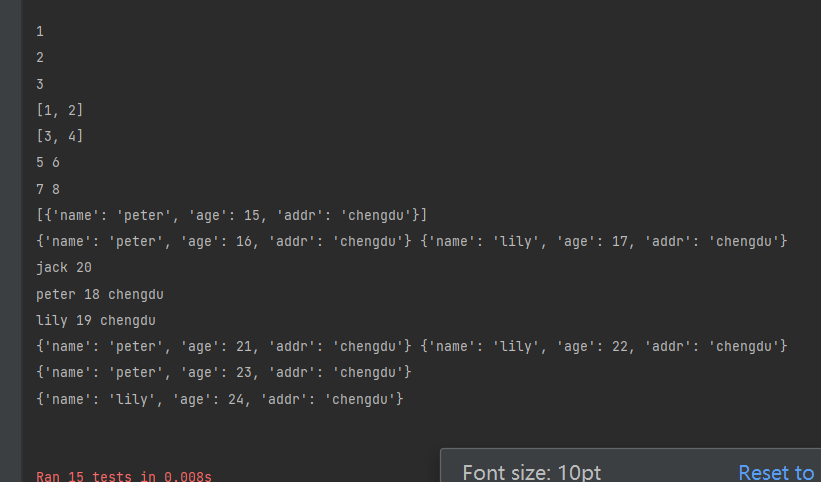
1、传递列表、字典等数据
# get_ddt.py
import unittest
from ddt import ddt, data, unpack, file_data
# 声明了ddt类装饰器
@ddt
class MyddtTest(unittest.TestCase):
# @data方法装饰器
# 单组元素
@data(1,2,3)
def test_01(self, value): # value用来接受data的数据
print(value)
# 多组数据,未拆分
@data([1,2],[3,4])
def test_02(self, value):
print(value)
# 多组数据,拆分
# @unpac拆分,相当于把数据的最外层结构去掉
@data([5,6],[7,8])
@unpack
def test_03(self, value1, value2):
print(value1, value2)
# 单个列表字典,未拆分
@data([{"name": "peter", "age": 15, "addr": "chengdu"}])
def test_04(self, value):
print(value)
# 多个列表字典,拆分
@data([{"name":"peter","age":16,"addr":"chengdu"},{"name":"lily","age":17,"addr":"chengdu"}])
@unpack
def test_05(self, value1, value2):
print(value1, value2)
# 单个字典,拆分
# @data里的数据key必须与字典的key保持一致
@data({"name":"jack","age":20})
@unpack
def test_06(self, name, age):
print(name, age)
# 多个字典, 拆分
@data({"name":"peter","age":18,"addr":"chengdu"},{"name":"lily","age":19,"addr":"chengdu"})
@unpack
def test_07(self, name, age, addr):
print(name, age, addr)
# 多个列表字典,引用数据
testdata = [{"name": "peter", "age": 21, "addr": "chengdu"}, {"name": "lily", "age": 22, "addr": "chengdu"}]
@data(testdata)
@unpack
def test_08(self, value1, value2):
print(value1, value2)
# @data(*testdata):*号意为解包,ddt会按逗号分隔,将数据拆分(不需要@unpack方法装饰器了)
testdata = [{"name":"peter","age":23,"addr":"chengdu"},{"name":"lily","age":24,"addr":"chengdu"}]
@data(*testdata)
def test_09(self, value):
print(value)
if __name__ == "__main__":
unittest.main()
2.传递json、yaml文件
3.python中使用ddt+excel读取测试数据

- 点赞
- 收藏
- 关注作者
评论(0)