Python正则表达式(持续更新,各种字符串筛选,总有一款适合您当前的功能)


![]()
前言
整个文章都是以精华部分为主,主要分文2个部分:
1、python的【re】正则表达式使用方法。
2、【re】正则表达式以及对应的demo。
第一部分让你知道【re】的几个函数的区别,更好的匹配项目中的需求。
第二部分让你快速的匹配具体需要的正则表达式可用拼写方法。
目录
2、re.search函数·单一匹配-推荐指数【★★★★★】
3、re.findall函数·多项匹配-推荐指数【★★★★★】
4、re.finditer函数·多项匹配-推荐指数【★★★★】
一、python【re】的用法
通用函数:
| 函数名 | 作用 |
| span() | 获取匹配字符串下标范围,返回元组。 |
| group() | 返回匹配字符串结果,返回字符串。 |
1、re.match函数·单一匹配-推荐指数【★★】
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string, flags=0)
pattern:正则表达式字符串。
string:需要匹配的字符串。
第三个flags是控制正则的严谨度,常用的两个:re.I不区分大小写,re.S遇到【\n】继续匹配。
示例:
注:re.match弊端:只能匹配是否以某字符串为开头的内容,所以很多场合不合适。
import re
'''
re.match弊端:只能匹配是否以某字符串为开头的内容
'''
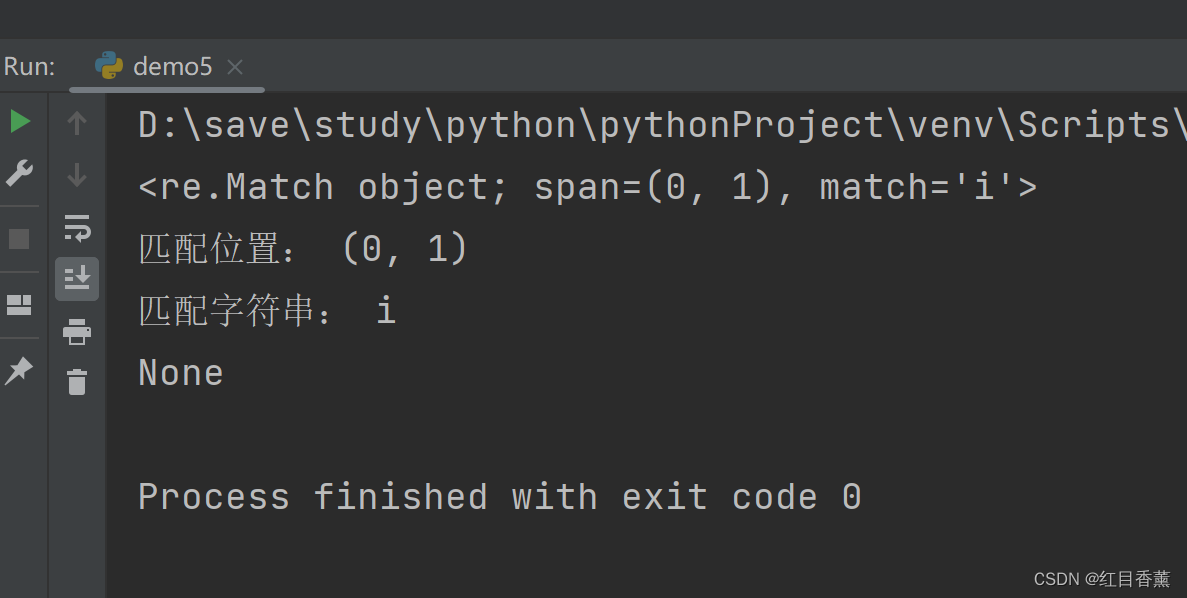
result1 = re.match(r'I', 'i Have A Dream!', re.I) # 在起始位置匹配,不区分大小写
result2 = re.match(r'Dream', 'I Have A dream!', re.I) # 不在起始位置匹配,不区分大小写
print(result1)
print("匹配位置:", result1.span())
print("匹配字符串:", result1.group())
print(result2)
结果中我们能看到是否以字符串开头进行字符串匹配的区别,虽然都含有,但是不是开头的字符串就不匹配。
![]()
2、re.search函数·单一匹配-推荐指数【★★★★★】
注:re.search函数无论在哪里都能匹配字符串。
函数语法与re.match函数一样。
import re
'''
re.search:无论在哪里都能匹配
'''
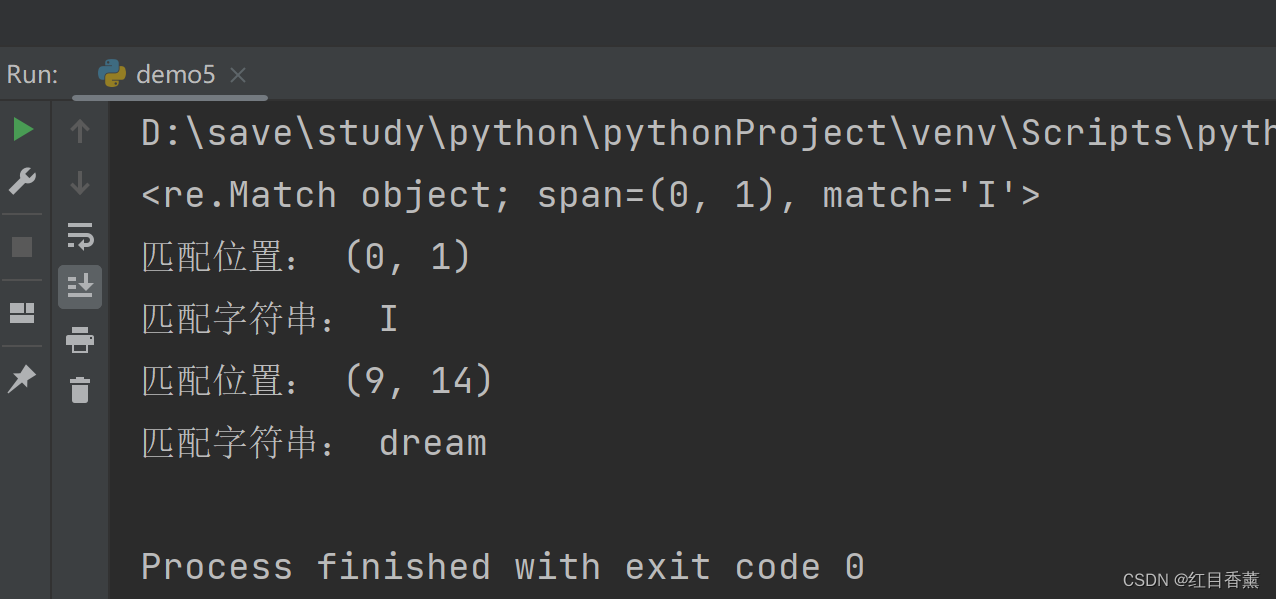
result1 = re.search(r'I', 'I Have A Dream!', re.I) # 不区分大小写
result2 = re.search(r'Dream', 'I Have A dream!dream', re.I) # 不区分大小写
print(result1)
print("匹配位置:", result1.span())
print("匹配字符串:", result1.group())
print("匹配位置:", result2.span())
print("匹配字符串:", result2.group())
在结果中我们可以清晰的看到匹配到匹配到的位置。
![]()
以上两种都只能匹配一次,那么很多时候我们是一个超级大的字符串,或甚至是整个【H5】网页,那么,我们需要多个匹配的时候就不能使用这两个函数了。
3、re.findall函数·多项匹配-推荐指数【★★★★★】
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。个人喜欢用列表所以五星推荐。
注:这里通上面的两个函数的本质却别就出来了,我们可以匹配一个大字符串中所有符合正则表达式的字符串。
示例:
import re
'''
re.findall:匹配所有符合正则表达式的字符串
'''
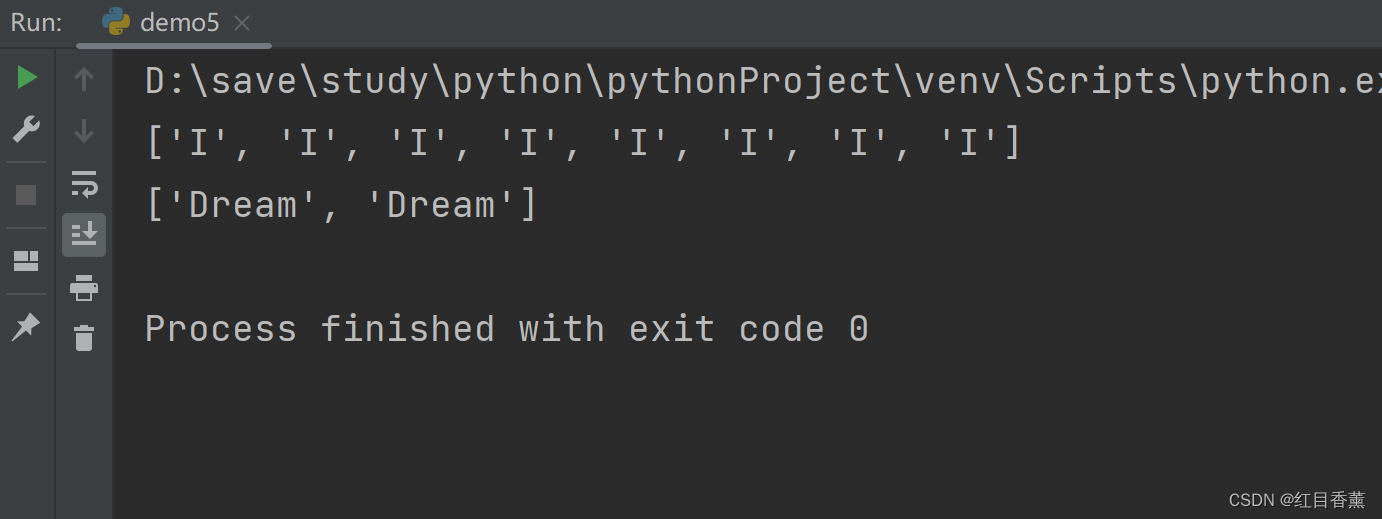
result1 = re.findall(r'I', 'I Have A Dream!I I I I I I I') # 在起始位置匹配
result2 = re.findall(r'Dream', 'I Have A Dream!Dream') # 不在起始位置匹配
print(result1)
print(result2)
结果中我们能看到所有符合的字符串都返回到了列表中,没有去重操作。
![]()
4、re.finditer函数·多项匹配-推荐指数【★★★★】
在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。个人不太喜欢用迭代器,故而推荐指数四颗星。
注:这里我与findall做了个对比,喜欢使用迭代器的可以使用这个函数啊。
import re
content = '''email:372699828@qq.com
email:feng8403000@163.com
email:qwe8403000@126.com
'''
result_findall = re.findall(r"\d+@\w+.com", content)
print("迭代器类型:", type(result_findall))
# 返回list
result_findall
for i in result_findall:
print(i)
print("-" * 20)
result_finditer = re.finditer(r"\d+@\w+.com", content)
# 返回iterator
print("list列表类型:", type(result_finditer))
for i in result_finditer:
print(i.group())
5、re.sub函数·替换函数-推荐指数【★★★★】
这个函数用的相对来说不是很多,一般正则梳理好的字符串就直接使用字符串的处理方法来搞定了。但是这个函数还是很方便的,只是我不推荐替换原内容。
示例:
import re
'''
re.sub:替换匹配字符串
'''
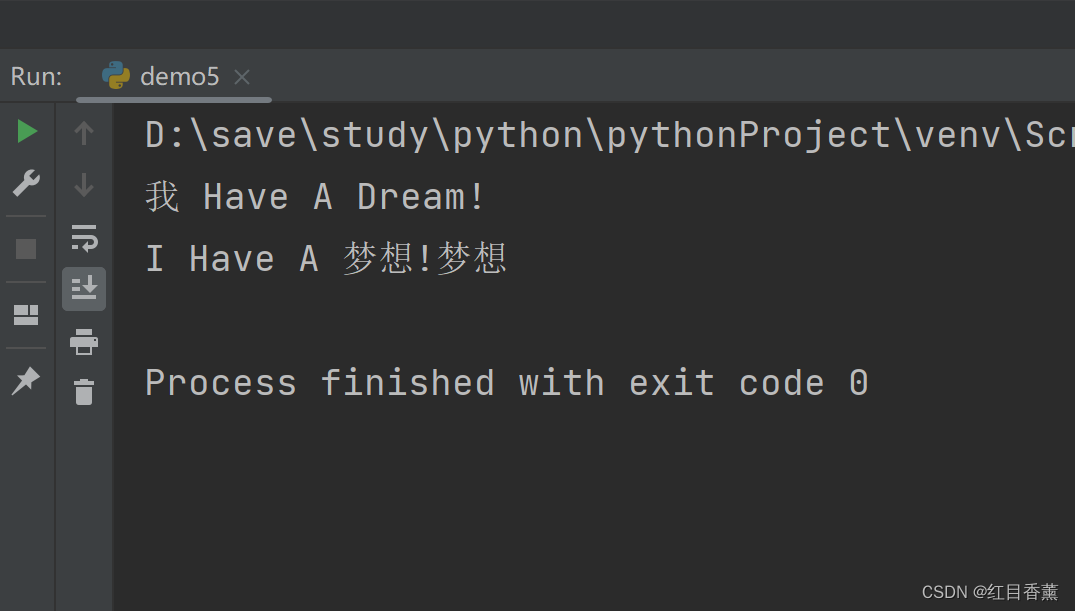
result1 = re.sub(r'I', '我', 'I Have A Dream!')
result2 = re.sub(r'Dream', '梦想', 'I Have A Dream!Dream')
print(result1)
print(result2)
结果中可以看到,这个替换匹配是默认多个匹配的。
![]()
二、正则表达式示例·总有一款适合你
1、正则表达式匹配HTML指定id/class的标签
r"<ul class=\"chapter-list clearfix\">.*?</ul>"
.*?含义是不限任意字符的匹配,直到【?】后面的内容代表结束,这里【?】后面是【</ul>】,所以能截取整个ul标签的内容。以后用处很多,记住。
import re
import requests
'''
获取某网站·某个·class元素下·所有内容·返回字符串
'''
url = "https://book.zongheng.com/showchapter/1243826.html"
context = requests.get(url).content.decode("utf-8")
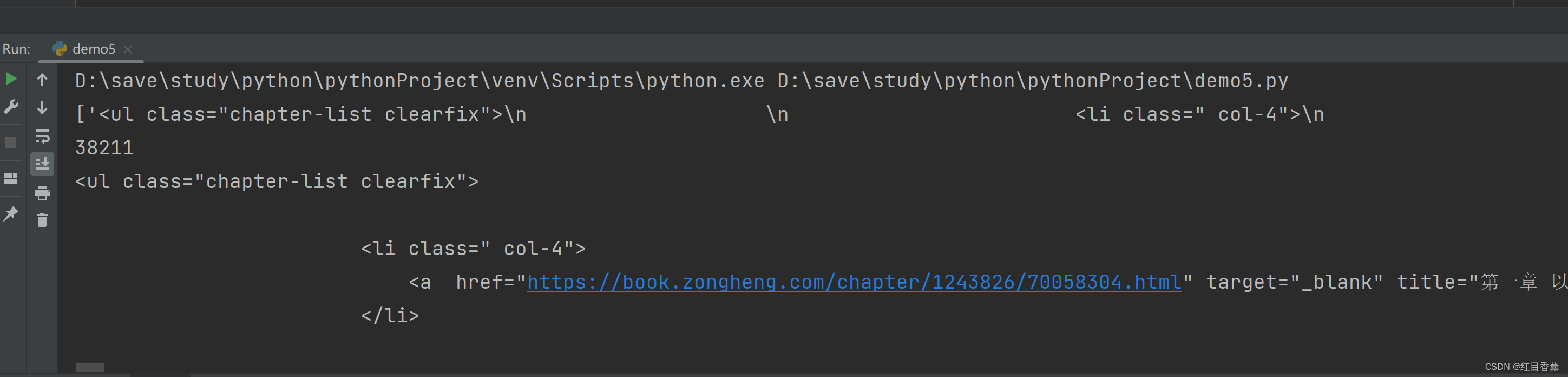
result1 = re.findall(r"<ul class=\"chapter-list clearfix\">.*?</ul>", context, re.S)
print(result1)
print(len(result1[0]))
print(result1[0])
结果中能看截取成功:
![]()
2、正则表达式匹配HTML中所有a标签中的各类属性值
r'<a.*? href="(.*?)".*?>.*?</a>'
同理,想获得【title】标签就将正则表达式中的属性换成想要的就行。
import re
'''
正则获取所有a标签的href值
'''
context = """
<a href="https://baidu.com" target="_blank">百度</a>
<a href="https://baidu.com" target="_blank">百度</a>
<a href="https://baidu.com" target="_blank">百度</a>
<a href="https://baidu.com" target="_blank">百度</a>
"""
result1 = re.findall(r'<a.*? href="(.*?)".*?>.*?</a>', context)
print(result1)

![]()
实际示例1:获取href值
import re
import requests
'''
获取某网站·某个·class元素下·所有内容·返回字符串·根据字符串匹配超链接的href值
'''
url = "https://book.zongheng.com/showchapter/1243826.html"
context = requests.get(url).content.decode("utf-8")
result1 = re.findall(r"<ul class=\"chapter-list clearfix\">.*?</ul>", context, re.S)
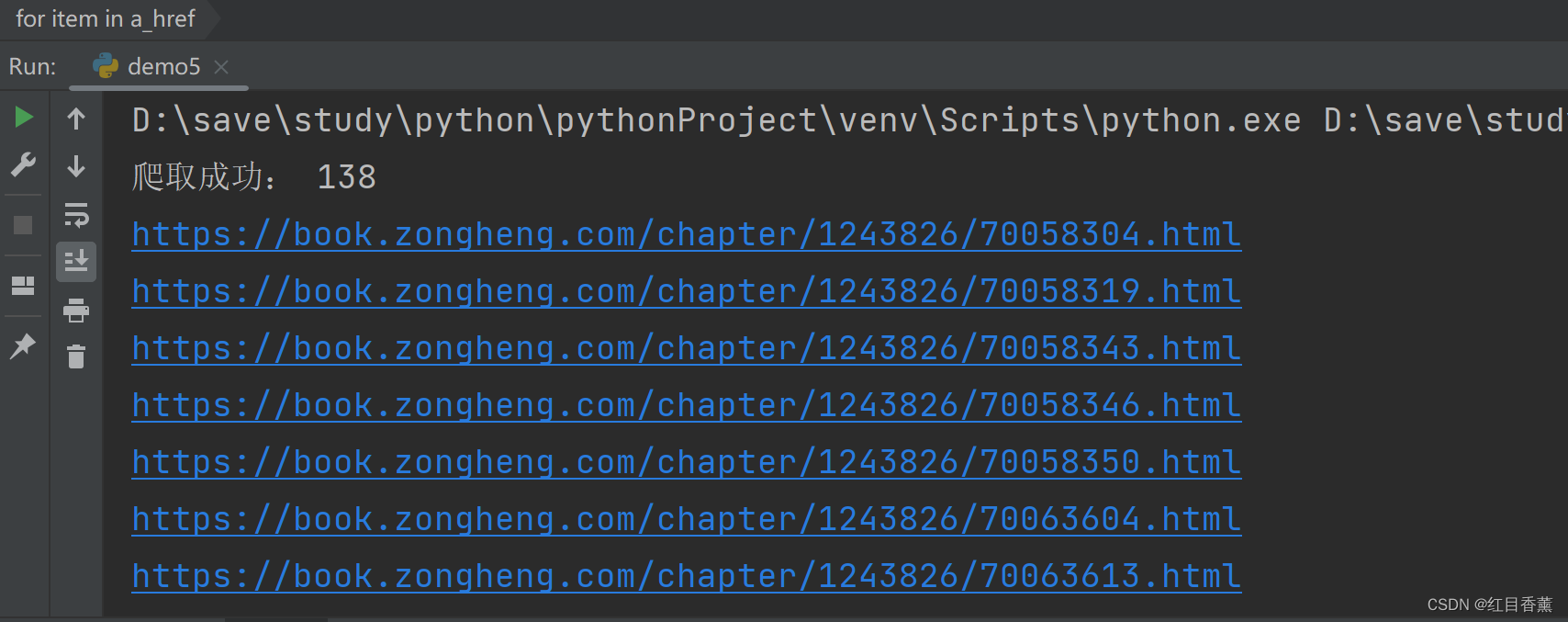
a_href = re.findall(r'<a.*? href="(.*?)".*?>.*?</a>', result1[0], )
print("爬取成功:", len(a_href))
for item in a_href:
print(item)
结果匹配到138条超链接的值:
![]()
实际示例2:获取title值
import re
import requests
'''
获取某网站·某个·class元素下·所有内容·返回字符串·根据字符串匹配超链接的title值
'''
url = "https://book.zongheng.com/showchapter/1243826.html"
context = requests.get(url).content.decode("utf-8")
result1 = re.findall(r"<ul class=\"chapter-list clearfix\">.*?</ul>", context, re.S)
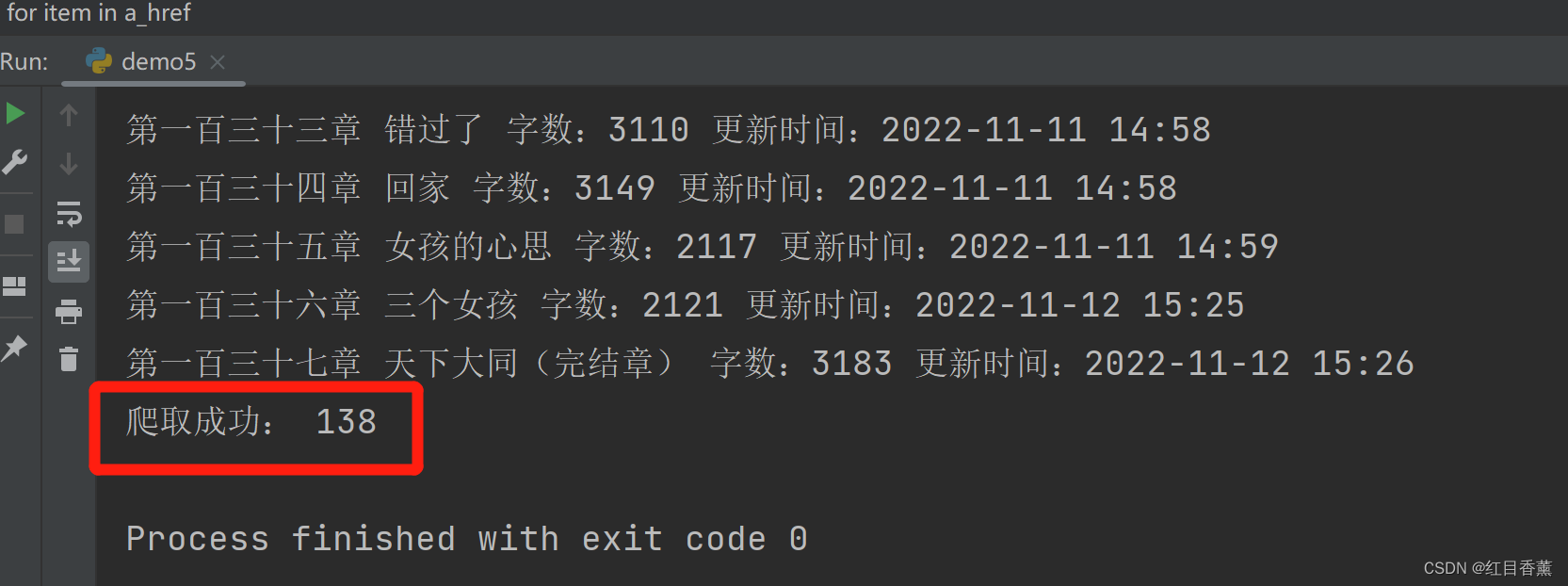
a_href = re.findall(r'<a.*? title="(.*?)".*?>.*?</a>', result1[0], )
for item in a_href:
print(item)
print("爬取成功:", len(a_href))
结果可看到,同样匹配成功。
![]()
3、获取标签的文本值·例如:span标签、a标签文本
我这里处理的是a标签的文本,咱们没有使用框架,相对来说纯使用正则表达式稍微麻烦一些,但是处理方式还是不复杂的,可以看到我获取a标签所有内容后,将左右的标签符号去掉就剩下中间的文本了,还是挺容易获取的。如果是span标签,您直接把a标签替换成span标签就行了。
获取方法1:
import re
import requests
'''
获取某网站·某个·class元素下·所有内容·返回字符串·根据字符串匹配超链接的文本内容
'''
url = "https://book.zongheng.com/showchapter/1243826.html"
context = requests.get(url).content.decode("utf-8")
result1 = re.findall(r"<ul class=\"chapter-list clearfix\">.*?</ul>", context, re.S)
a_href = re.findall(r'<a.*?>.*?</a>', result1[0])
data_list = []
left_text = ">"
right_text = "</a>"
for item in a_href:
result = re.findall(r">.*?</a>", item)
for item1 in result:
item1 = item1.replace(left_text, "", 1).replace(right_text, "", 1)
data_list.append(item1)
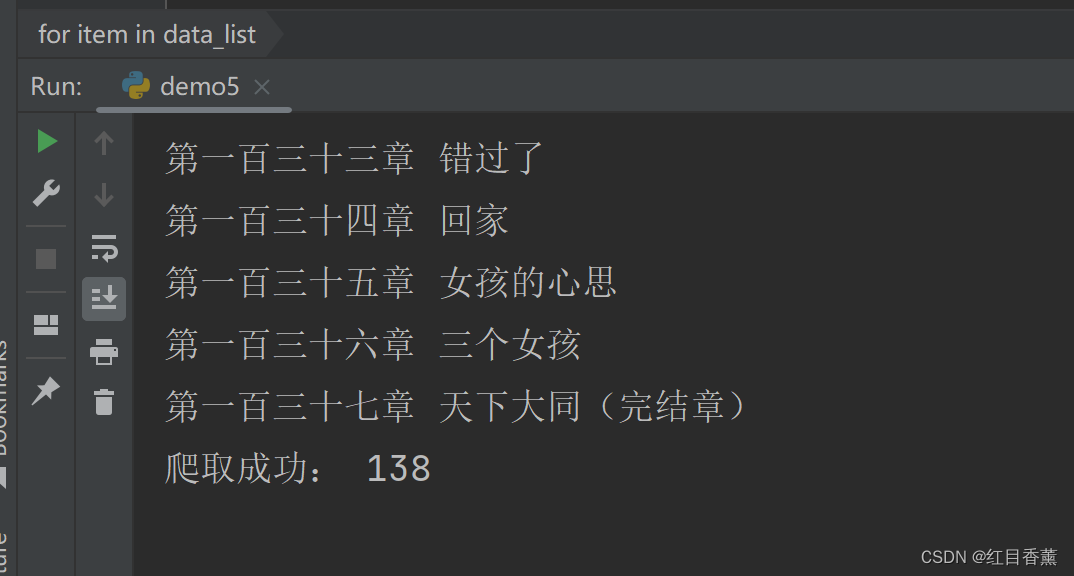
for item in data_list:
print(item)
print("爬取成功:", len(data_list))
结果呈现,可以看到138条都筛选出来了。
![]()
获取方法2:
通过【()】的方法直接获取我们需要的内容
import re
import requests
'''
获取某网站·某个·class元素下·所有内容·返回字符串·根据字符串匹配超链接的文本内容
'''
url = "https://book.zongheng.com/showchapter/1243826.html"
context = requests.get(url).content.decode("utf-8")
result1 = re.findall(r"<ul class=\"chapter-list clearfix\">.*?</ul>", context, re.S)
a_href = re.findall(r'<a.*?>.*?</a>', result1[0])
data_list = []
left_text = ">"
right_text = "</a>"
for item in a_href:
result = re.findall(r">(.*?)</a>", item)
data_list.append(result[0])
for item in data_list:
print(item)
print("爬取成功:", len(data_list))
这种方法直接就能获取我们需要的内容:
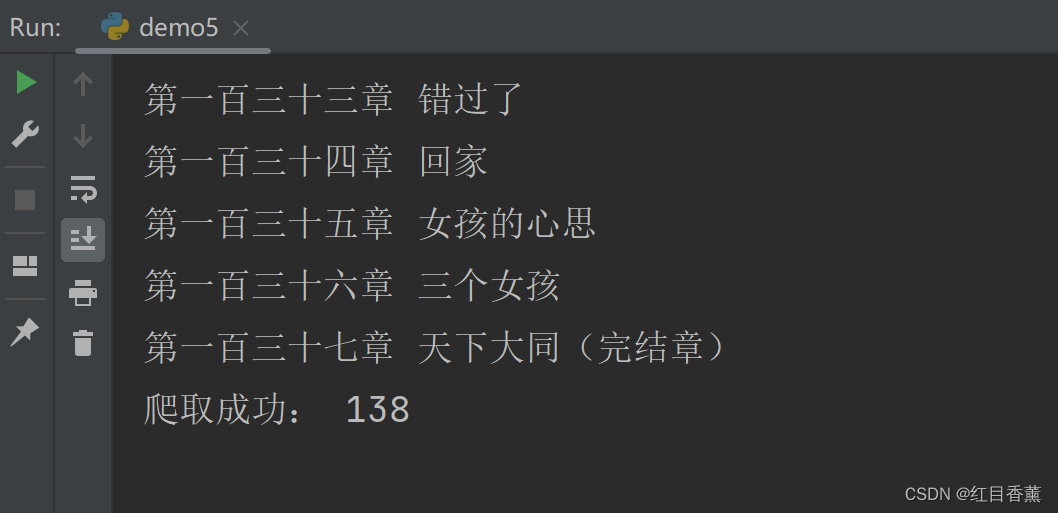
![]()
4、key:value格式的数据
在下图中可以看到字典格式的数据,{"adv_type":"bookDirectory00","adv_res":"zongheng","pos":""}我们想要其中的"adv_type"的值,那么,我们需要用另外一种正则表达式了:

![]()
import re
import requests
'''
获取key:value的数据
'''
url = "https://book.zongheng.com/showchapter/1243826.html"
context = requests.get(url).content.decode("utf-8")
result1 = re.findall('"adv_type":"(.*?)"', context)
for item in result1:
print(item)
结果示例:
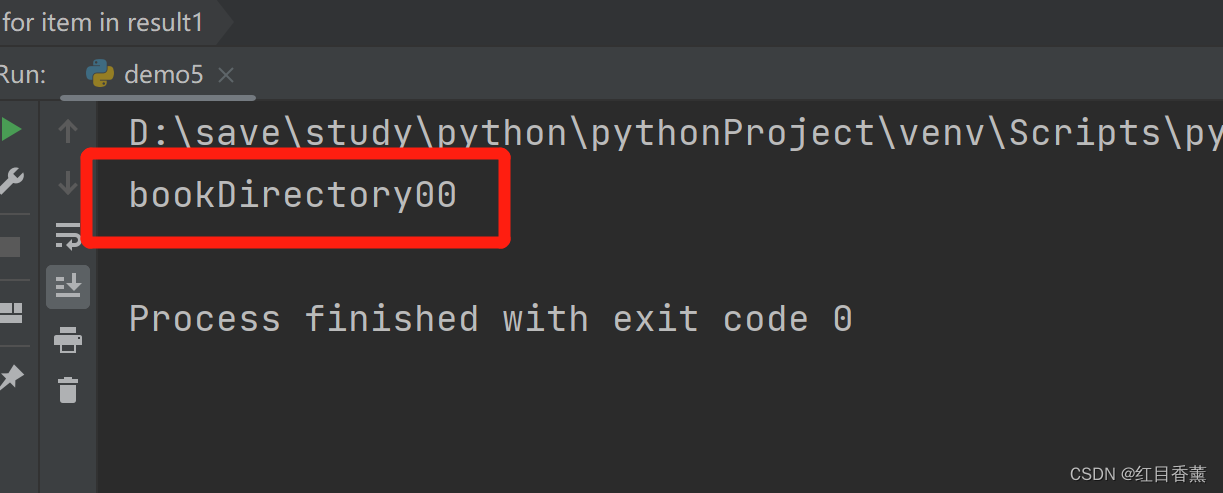
![]()
5、匹配url
1、匹配短连接
r'(http[|s]?://[^\s]*/)'
import re
import requests
'''
提取字符串中的链接
'''
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
}
url_info = """6.69 Cuf:/ 售价888一碗的面!自己在家做需要花多少钱?# 百蟹面 # 六虾面 https://v.douyin.com/rhkGMfh/ 复制此链接,打开Dou音搜索,直接观看视频!"""
short_url = re.findall(r'(http[|s]?://[^\s]*/)', url_info)[0]
print(short_url)
url = requests.get(url=short_url, headers=headers).url
item_id = url.split('/')[4][0:19]
url = "https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids={0}".format(item_id)
html = requests.get(url, headers=headers)
title = html.json()['item_list'][0]['desc'] # 标题获取
print(title)
结果获取:
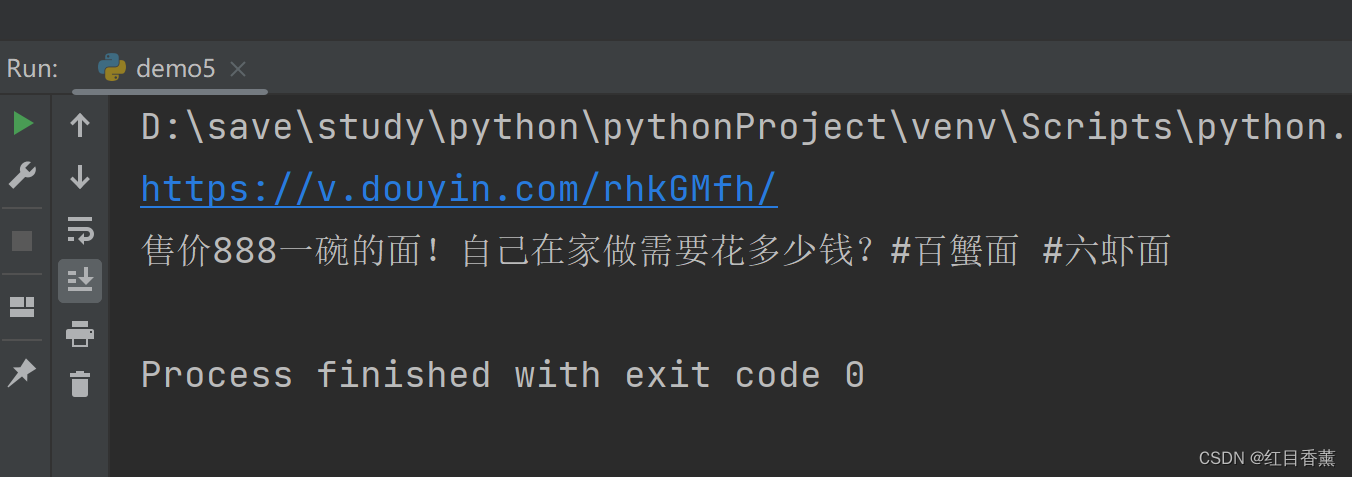
![]()
2、匹配长连接
r"""(http|ftp|https):\/\/[\w\-_]+(\.[\w\-_]+)+([\w\-\.,@?^=%&:/~\+#]*[\w\-\@?^=%&/~\+#])?"""
import re
import requests
'''
获取某网站·获取所有的长链接
'''
url = "https://book.zongheng.com/showchapter/1243826.html"
context = requests.get(url).content.decode("utf-8")
result1 = re.findall(r"<ul class=\"chapter-list clearfix\">.*?</ul>", context, re.S)
# result1中包含多个长连接
rule = r"""(http|ftp|https):\/\/[\w\-_]+(\.[\w\-_]+)+([\w\-\.,@?^=%&:/~\+#]*[\w\-\@?^=%&/~\+#])?"""
result2 = re.findall(rule, result1[0], re.S)
data_list = []
for item in result2:
new_url = "{0}://book.zongheng.com{1}".format(item[0], item[2])
data_list.append(new_url)
for item in data_list:
print(item)
print("获取连接:", len(data_list))
匹配的内容需要拼接一下:
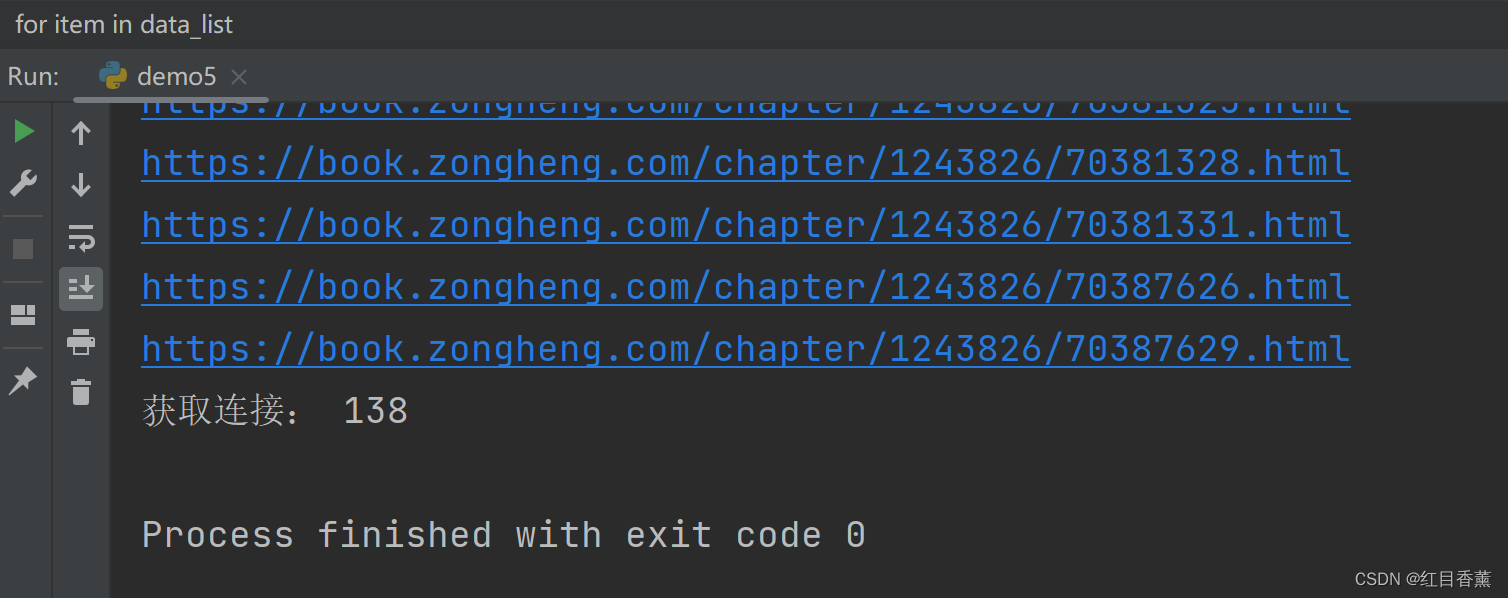
![]()
3、各类网址url列表
| 正则表达式 | 匹配网址类型示例 |
| (http|ftp|https):\/\/[\w\-_]+(\.[\w\-_]+)+([\w\-\.,@?^=%&:/~\+#]*[\w\-\@?^=%&/~\+#])? | |
| ^\\{2}[\w-]+\\(([\w-][\w-\s]*[\w-]+[$$]?$)|([\w-][$$]?$)) | 没有后缀的网址/server/view_6/show |
| ^(http|https|ftp)\://([a-zA-Z0-9\.\-]+(\:[a-zA-Z0-9\.&%\$\-]+)*@)?((25[0-5]|2[0-4][0-9]|[0-1]{1}[0-9]{2}|[1-9]{1}[0-9]{1}|[1-9])\.(25[0-5]|2[0-4][0-9]|[0-1]{1}[0-9]{2}|[1-9]{1}[0-9]{1}|[1-9]|0)\.(25[0-5]|2[0-4][0-9]|[0-1]{1}[0-9]{2}|[1-9]{1}[0-9]{1}|[1-9]|0)\.(25[0-5]|2[0-4][0-9]|[0-1]{1}[0-9]{2}|[1-9]{1}[0-9]{1}|[0-9])|([a-zA-Z0-9\-]+\.)*[a-zA-Z0-9\-]+\.[a-zA-Z]{2,4})(\:[0-9]+)?(/[^/][a-zA-Z0-9\.\,\?\'\\/\+&%\$#\=~_\-@]*)*$ | 匹配长链接 |
| ^([a-zA-Z]\:|\\\\[^\/\\:*?"<>|]+\\[^\/\\:*?"<>|]+)(\\[^\/\\:*?"<>|]+)+(\.[^\/\\:*?"<>|]+)$ | 匹配电脑中的绝对路径 |
| \b(([\w-]+://?|www[.])[^\s()<>]+(?:[\w\d]+[\w\d]+|([^[:punct:]\s]|/))) | 匹配没有.后缀的网址 |
4、网页中中文提取
r"[\u4E00-\u9FA5]"
import re
import requests
'''
获取某网站·获取网站中所有中文
'''
url = "https://book.zongheng.com/showchapter/1243826.html"
context = requests.get(url).content.decode("utf-8")
rule = r"[\u4E00-\u9FA5]"
result2 = re.findall(rule, context, re.S)
count = 0
for item in result2:
if count % 10 == 0:
print()
print(item, end="")
count += 1
print("\n共计提取:", len(result2), "个中文")
结果展示:
 总结:
总结:
暂时先写这些,后面随时用到随时写。

- 点赞
- 收藏
- 关注作者
评论(0)