【数据库】基础知识

17、数据处理函数
本质就是函数,被封装了,只需要知道怎么用

17.1单行处理函数
单行处理函数的特点:一个输入对应一个输出。
和单行处理函数相对的是:多行处理函数。(多行处理函数特点:多个输入,对应1个输出!)
lower
lower 转换小写
mysql> select lower(ename) as ename from emp;
upper
upper 转换大写
mysql> select * from t_student;
substr
取子串(substr( 被截取的字符串, 起始下标,截取的长度))
select substr(ename, 1, 1) as ename from emp;
注意:起始下标从1开始,没有0.
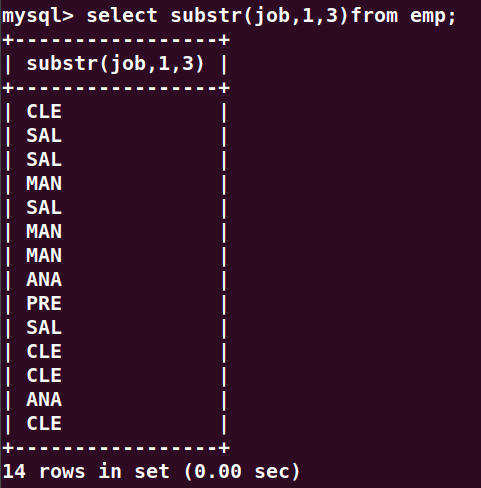
找出员工名字第一个字母是A的员工信息?
第一种方式:模糊查询
select ename from emp where ename like 'A%';
第二种方式:substr函数
select ename from emp where substr(ename,1,1) = 'A';
concat
concat函数进行字符串的拼接
select concat(empno,ename) from emp;

length
length 取长度
select length(ename) enamelength from emp;
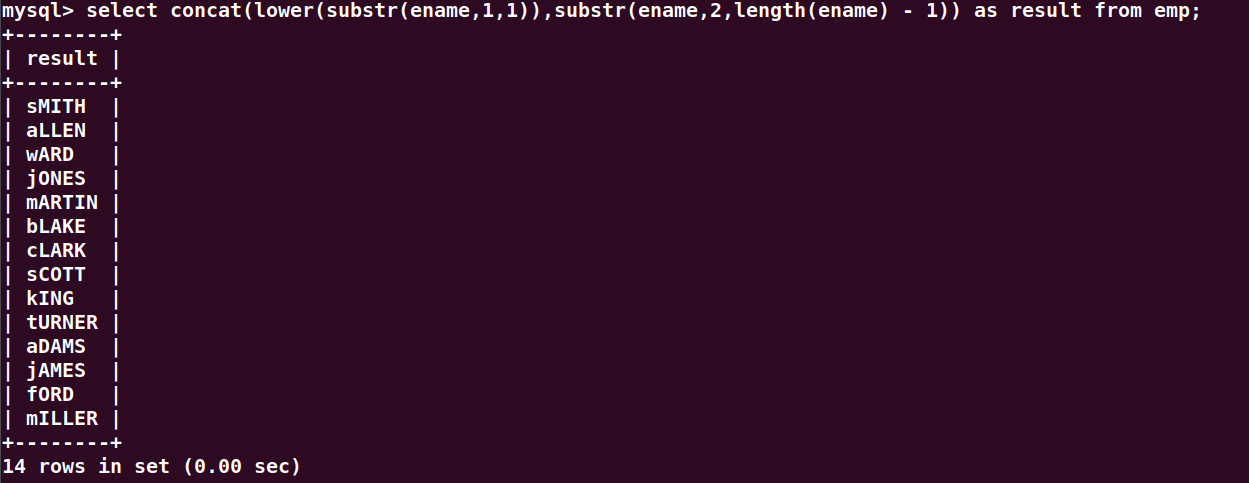
首字母小写
select lower(substr(ename,1,1)) from emp;//截取第一个字符为大写
select substr(ename,2,length(ename) - 1) from emp;截取第二个之后的字符
select concat(lower(substr(ename,1,1)),substr(ename,2,length(ename) - 1)) as result from emp;
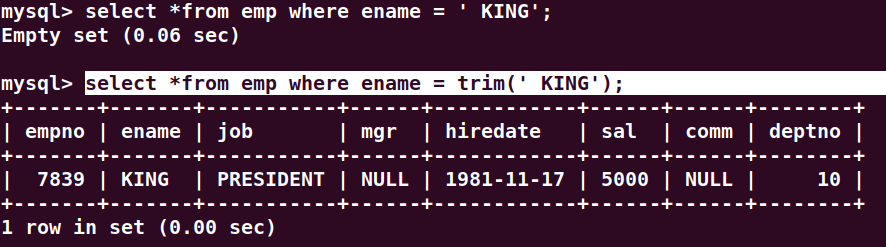
trim
去空格
select *from emp where ename = trim(' KING');
没有空格是查询不出来的
str_to_date 将字符串转换成日期
date_format 格式化日期
format 设置千分位
round
select 'abc' from emp; // select后面直接跟“字面量/字面值”
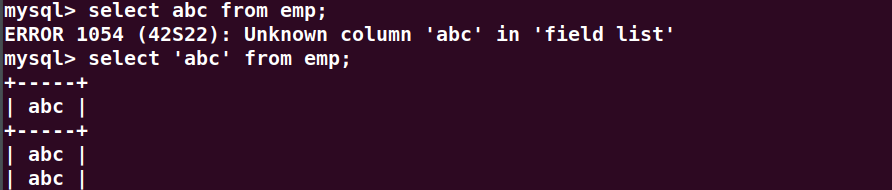
mysql> select abc from emp;ERROR 1054 (42S22): Unknown column 'abc' in 'field list'
这样肯定报错,因为会把abc当做一个字段的名字,去emp表中找abc字段去了。
select 1000 as num from emp; // 1000 也是被当做一个字面量/字面值。
四舍五入,round(数字,保留多少位)
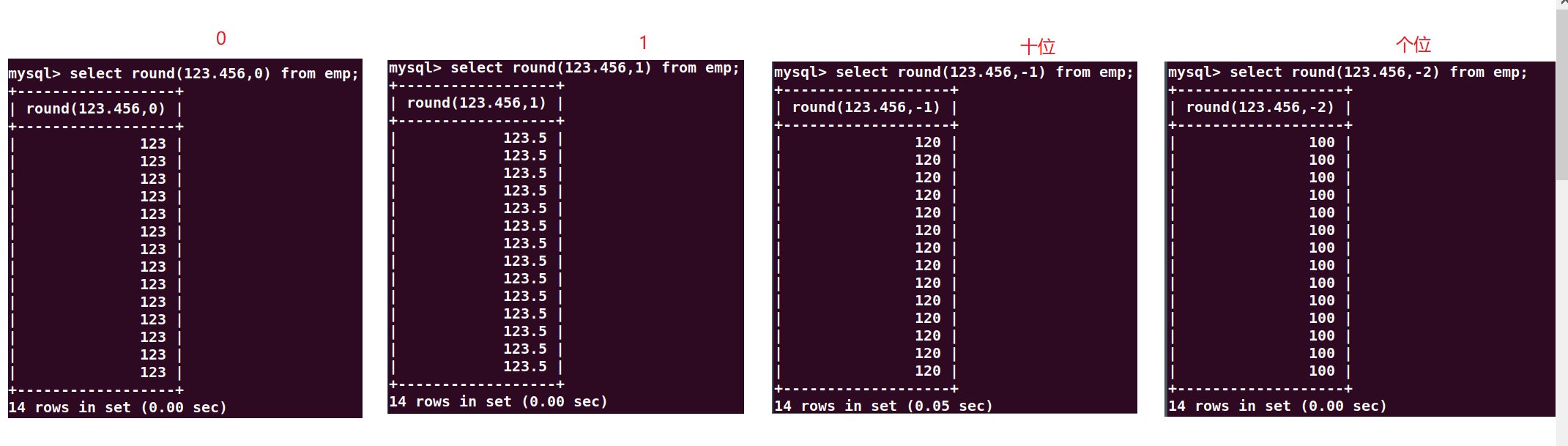
==结论:select后面可以跟某个表的字段名(可以等同看做变量名),也可以跟字面量/字面值(数据)。==
rand
rand() 生成随机数
select round(rand()*100,0) from emp; // 100以内的随机数
ifnull
ifnull 可以将 null 转换成一个具体值
ifnull是空处理函数。专门处理空的。
在所有数据库当中,只要有NULL参与的数学运算,最终结果就是NULL.

计算每个员工的年薪?
年薪 = (月薪 + 月补助) * 12
select ename, (sal + comm) * 12 as yearsal from emp;
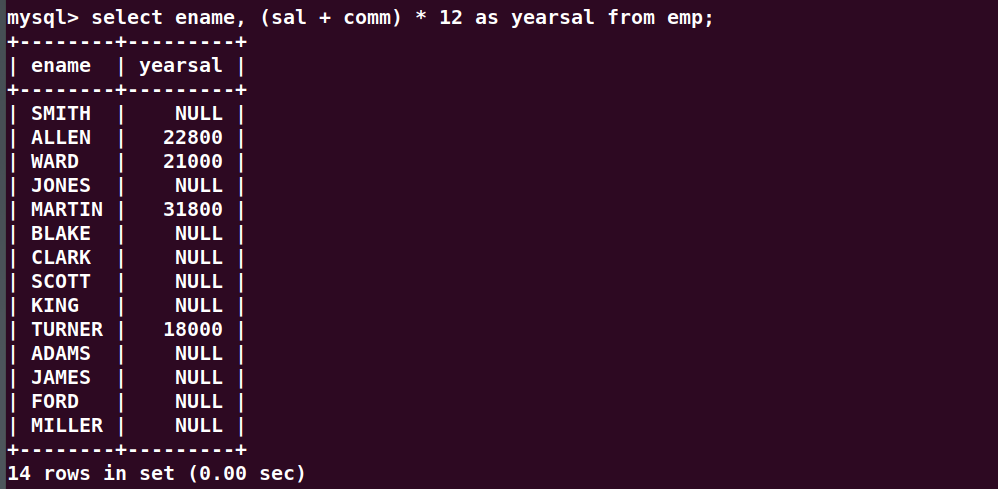
注意:NULL只要参与运算,最终结果一定是NULL。为了避免这个现象,需要使用ifnull函数。
ifnull函数用法:ifnull(数据, 被当做哪个值)
如果“数据”为NULL的时候,把这个数据结构当做哪个值。
补助为NULL的时候,将补助当做0
select ename, (sal + ifnull(comm, 0)) * 12 as yearsal from emp;
case…when…then…when…then…else…end
case 取字段 when 条件1 then 执行1
when 条件2 then 执行2
else 其它条件
end(结束)
当员工的工作岗位是MANAGER的时候,工资上调10%,当工作岗位是SALESMAN的时候,工资上调50%,其它正常。
(注意:不修改数据库,只是将查询结果显示为工资上调)
select
ename,
job,
sal as oldsal,
(case job when 'MANAGER' then sal*1.1 when 'SALESMAN' then sal*1.5 else sal end) as newsal
from
emp;
18 、多行处理函数
多行处理函数的特点:输入多行,最终输出一行。
5个:
count 计数
sum 求和
avg 平均值
max 最大值
min 最小值
注意:
分组函数在使用的时候必须先进行分组,然后才能用。
如果你没有对数据进行分组,整张表默认为一组。

分组函数在使用的时候需要注意哪些?
第一点:分组函数自动忽略NULL,你不需要提前对NULL进行处理。
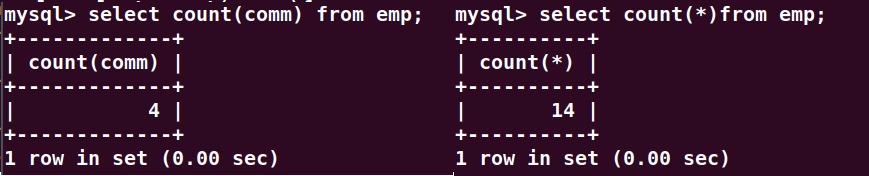
第二点:分组函数中count(*)和count(具体字段)有什么区别?
count(具体字段):表示统计该字段下所有不为NULL的元素的总数。
count(*):统计表当中的总行数。(只要有一行数据count则++)
因为每一行记录不可能都为NULL,一行数据中有一列不为NULL,则这行数据就是有效的。
第三点:分组函数不能够直接使用在where子句中。
找出比最低工资高的员工信息。
select ename,sal from emp where sal > min(sal);
表面上没问题,运行一下?

无效的使用了分组函数,为什么呢?说完分组查询(group by)之后就明白了。
第四点:所有的分组函数可以组合起来一起用。
select sum(sal),max(sal),min(sal),avg(sal),count(*)from emp;

19、分组函数(重点)
19.1 什么是分组函数?
在实际的应用中,可能有这样的需求,需要先进行分组,然后对每一组的数据进行操作。
这个时候我们需要使用分组查询,怎么进行分组查询呢?
19.2 执行顺序
select
...
from
...
where
...
group by
...
order by
...
以上关键字的顺序不能颠倒,需要记忆。
执行顺序是什么?
1. from
2. where
3. group by
4. select
5. order by
为什么分组函数不能直接使用在where后面?
select ename,sal from emp where sal > min(sal);//报错。
因为分组函数在使用的时候必须先分组之后才能使用。而where还没执行完就使用分组函数
where执行的时候,还没有分组。所以where后面不能出现分组函数。
select sum(sal) from emp;
这个没有分组,为啥sum()函数可以用呢?
因为select在group by之后执行。
19.3 练习
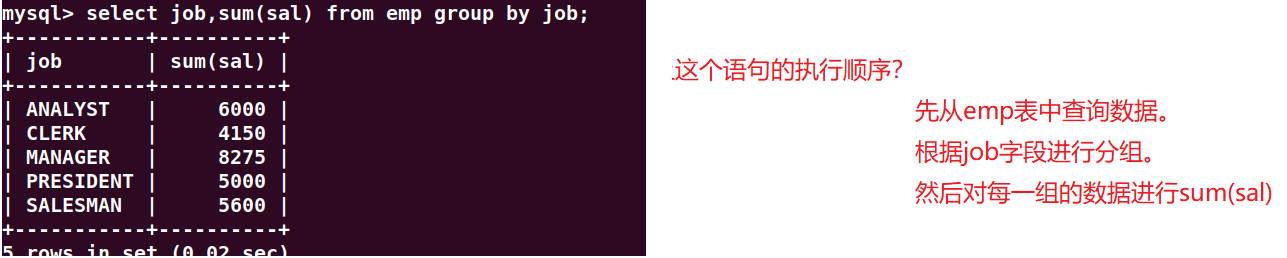
1.找出每个工作岗位的工资和?
实现思路:按照工作岗位分组,然后对工资求和。
select job,sum(sal) from emp group by job;
select ename,job,sum(sal) from emp group by job;

==重点结论:==
在一条select语句当中,如果有group by语句的话,
select后面只能跟:参加分组的字段,以及分组函数。
其它的一律不能跟。
2.找出“每个部门,不同工作岗位”的最高薪资?
技巧:两个字段联合成1个字段看。(两个字段联合分组)
select
deptno, job, max(sal)
from
emp
group by
deptno, job;
19.4 having
使用having可以对分完组之后的数据进一步过滤。
having不能单独使用,having不能代替where,having必须
和group by联合使用。
找出每个部门最高薪资,要求显示最高薪资大于3000的?
第一步:找出每个部门最高薪资
按照部门编号分组,求每一组最大值。
select deptno,max(sal) from emp group by deptno;
第二步:要求显示最高薪资大于3000
select
deptno,max(sal)
from
emp
group by
deptno
having
max(sal) > 3000;
思考一个问题:以上的sql语句执行效率是不是低?
比较低,实际上可以这样考虑:先将大于3000的都找出来,然后再分组。
select
deptno,max(sal)
from
emp
where
sal > 3000
group by
deptno;
优化策略:
where和having,优先选择where,where实在完成不了了,再选择having。
19.7、where没办法的????
找出每个部门平均薪资,要求显示平均薪资高于2500的。
第一步:找出每个部门平均薪资
select deptno,avg(sal) from emp group by deptno;
第二步:要求显示平均薪资高于2500的
select
avg(sal) ,deptno
from
emp
group by
deptno
having
avg(sal) > 2500;

19.5 distinct
把查询结果去除重复记录【distinct】
注意:原表数据不会被修改,只是查询结果去重。
去重需要使用一个关键字:distinct
mysql> select distinct job from emp;
+-----------+
| job |
+-----------+
| CLERK |
| SALESMAN |
| MANAGER |
| ANALYST |
| PRESIDENT |
+-----------+
// 这样编写是错误的,语法错误。
// distinct只能出现在所有字段的最前方。
mysql> select ename,distinct job from emp;
// distinct出现在job,deptno两个字段之前,表示两个字段联合起来去重。
mysql> select distinct job,deptno from emp;
+-----------+--------+
| job | deptno |
+-----------+--------+
| CLERK | 20 |
| SALESMAN | 30 |
| MANAGER | 20 |
| MANAGER | 30 |
| MANAGER | 10 |
| ANALYST | 20 |
| PRESIDENT | 10 |
| CLERK | 30 |
| CLERK | 10 |
+-----------+--------+
统计一下工作岗位的数量?
select count(distinct job) from emp;
+---------------------+
| count(distinct job) |
+---------------------+
| 5 |
+---------------------+
20、大总结(单表的查询)
select …from…where…group by…having…order by…
以上关键字只能按照这个顺序来,不能颠倒。
执行顺序?
1. from
2. where
3. group by
4. having
5. select
6. order by
从某张表中查询数据,
先经过where条件筛选出有价值的数据。
对这些有价值的数据进行分组。
分组之后可以使用having继续筛选。
select查询出来。
最后排序输出!
找出每个岗位的平均薪资,要求显示平均薪资大于1500的,除MANAGER岗位之外,
要求按照平均薪资降序排。
select
job, avg(sal) as avgsal
from
emp
where
job <> 'MANAGER'
group by
job
having
avg(sal) > 1500
order by
avgsal desc

- 点赞
- 收藏
- 关注作者
评论(0)