06、Netty学习笔记—(聊天业务优化:扩展序列化算法)

@[toc]
netty笔记汇总:Netty学习指南(资料、文章汇总)
根据黑马程序员netty视频教程学习所做笔记,部分内容图例来源黑马笔记
笔记demo案例仓库地址: Github-【netty-learn】、Gitee-【netty-learn】
一、实现序列化(JDK、JSON)
说明
序列化,反序列化主要是用于在消息正文的转换上
- 序列化时,需要将Java对象变为要传输的数据(可以是byte[]或json等,最终都要编程byte[])。
- 反序列化时,需要将传入的正文数据byte[]还原为Java对象,便于处理。
JSON序列化比JDK好的地方:传输字节数量更少,更具备通用性,无论是java、js或是其他都能够进行很好的反序列化对象。
序列化接口+实现算法
在自定义协议时,我们通常会在协议中定义一个字来表示使用的序列化算法,在聊天室中使用messageType来进行表示。通常序列化算法有多个,所以我们要实现一个序列化接口,并且添加多个序列化算法实现类:
Serializer:序列化接口
/**
* @ClassName Serializer
* @Author ChangLu
* @Date 2022/1/15 14:18
* @Description 自定义序列化接口
*/
public interface Serializer {
/**
* 反序列化方法
* @param clazz 反序列化的Class类型
* @param bytes 传输过来的字节数组
* @param <T>
* @return 返回指定T类型的结果对象
*/
<T> T deserialize(Class<T> clazz, byte[] bytes);
/**
* 序列化方法
* @param object 序列化的对象
* @param <T>
* @return 序列化对象采用指定的算法来转换得到的字节数组
*/
<T> byte[] serialize(T object);
}
SerializerAlgorithm:序列化算法枚举类,目前包含JDK序列化与JSON序列化
import com.google.gson.Gson;
import java.io.*;
import java.nio.charset.StandardCharsets;
/**
* @ClassName SerializeEnum
* @Author ChangLu
* @Date 2022/1/15 15:00
* @Description 序列化实现类
*/
public enum SerializerAlgorithm implements Serializer{
Java{
@Override
public <T> T deserialize(Class<T> clazz, byte[] bytes) {
T obj;
try (ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(bytes))) {
obj = (T) ois.readObject();
} catch (IOException | ClassNotFoundException e) {
throw new RuntimeException("反序列化失败", e);
}
return obj;
}
@Override
public <T> byte[] serialize(T object) {
byte[] bytes;
try (ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
) {
oos.writeObject(object);
bytes = baos.toByteArray();
} catch (IOException e) {
throw new RuntimeException("序列化失败", e);
}
return bytes;
}
},
Json{
@Override
public <T> T deserialize(Class<T> clazz, byte[] bytes) {
String json = new String(bytes, StandardCharsets.UTF_8);
return new Gson().fromJson(json, clazz);
}
@Override
public <T> byte[] serialize(T object) {
String json = new Gson().toJson(object);
return json.getBytes(StandardCharsets.UTF_8);
}
}
}
测试:
import com.changlu.config.Config;
import com.changlu.message.LoginRequestMessage;
import com.changlu.protocol.serialize.Serializer;
import com.changlu.protocol.serialize.SerializerAlgorithm;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import static io.netty.buffer.ByteBufUtil.appendPrettyHexDump;
import static io.netty.util.internal.StringUtil.NEWLINE;
/**
* @ClassName com.changlu.TestSerializer
* @Author ChangLu
* @Date 2022/1/15 14:40
* @Description 序列化实现类测试
*/
public class TestSerializer {
private static Serializer algorithm;
public static void main(String[] args) {
// testJDK();
testJSON();
}
/**
* 2、测试JSON序列化
*/
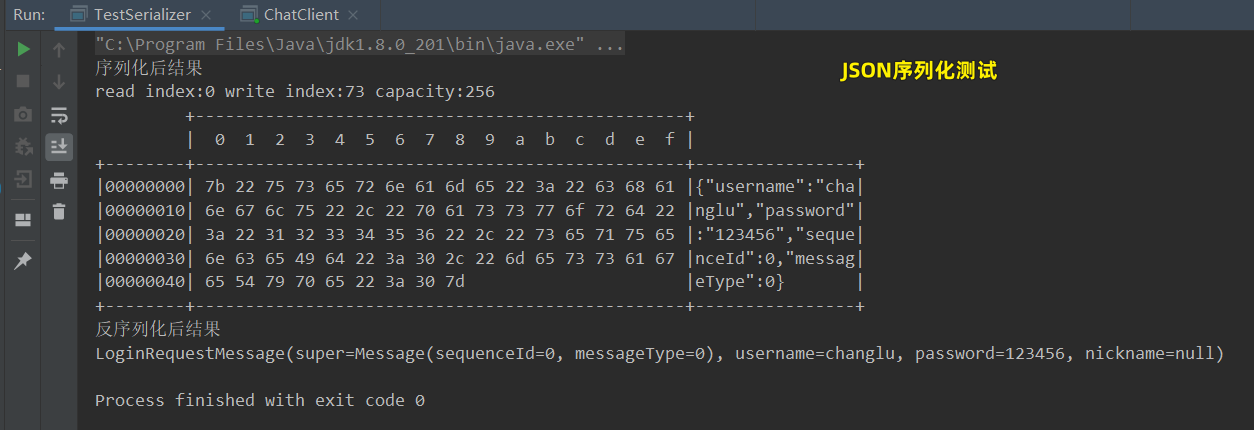
private static void testJSON() {
algorithm = SerializerAlgorithm.Json;
testSerializeAlgorithm();
}
/**
* 1、测试JDK序列化
*/
private static void testJDK() {
algorithm = SerializerAlgorithm.Java;
testSerializeAlgorithm();
}
/**
* 序列化、反序列化通用测试代码
*/
private static void testSerializeAlgorithm() {
final LoginRequestMessage message = new LoginRequestMessage("changlu", "123456");
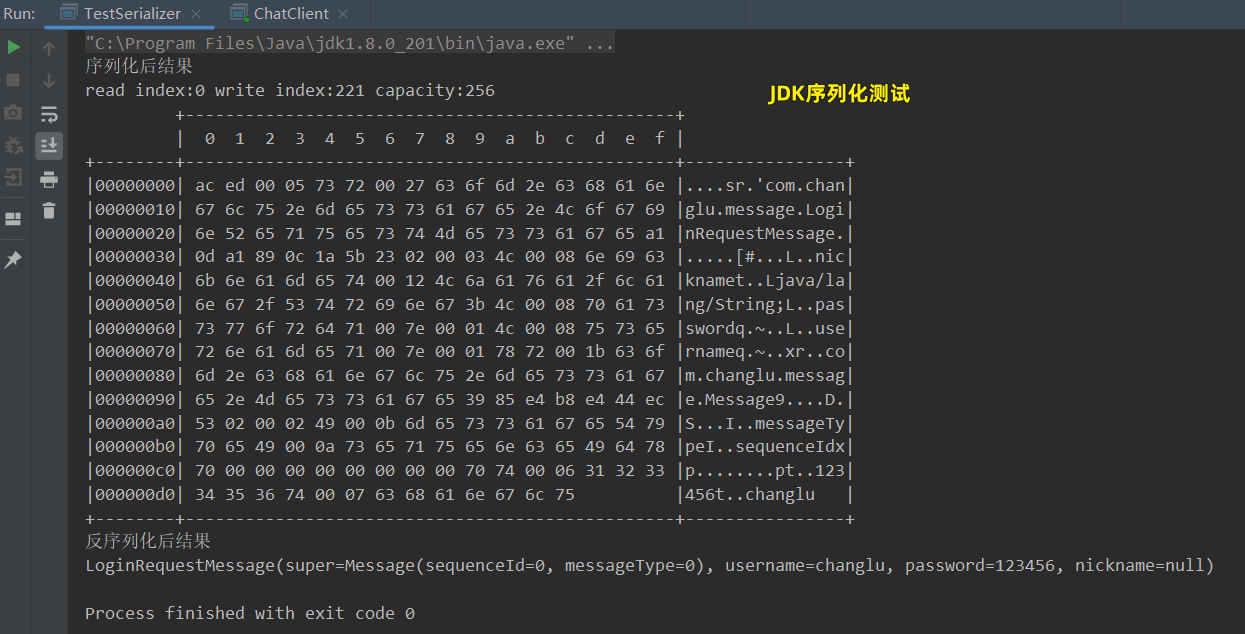
System.out.println("序列化后结果");
//序列化调用
final byte[] bytes = algorithm.serialize(message);
log(ByteBufAllocator.DEFAULT.buffer().writeBytes(bytes));
System.out.println("反序列化后结果");
//进行反序列化
LoginRequestMessage loginRequestMessage = algorithm.deserialize(LoginRequestMessage.class, bytes);
System.out.println(loginRequestMessage);
}
/**
* 工具类:用于方便查看ByteBuf中的具体数据信息
* @param buffer
*/
public static void log(ByteBuf buffer) {
int length = buffer.readableBytes();
int rows = length / 16 + (length % 15 == 0 ? 0 : 1) + 4;
StringBuilder buf = new StringBuilder(rows * 80 * 2)
.append("read index:").append(buffer.readerIndex())
.append(" write index:").append(buffer.writerIndex())
.append(" capacity:").append(buffer.capacity())
.append(NEWLINE);
appendPrettyHexDump(buf, buffer);
System.out.println(buf.toString());
}
}
二、聊天室优化—传输对象编解码(序列化算法指定)
之前聊天室中的序列化算法默认是JDK序列化,可以不需要知道消息对象是什么类型的,直接使用JDK序列化的readObject()就可以读取到源对象。
对于JSON序列化,那么就一定需要知道反序列化的指定的权限定类,才能够够进行反序列化。
自定义协议中的序列化方式字、消息指令类型字在本次优化中都起到了作用。
- 通过
序列化方式字客户端、服务端能够确定根据其指定代表的序列化算法来进行序列化与反序列化。 - 通过
消息指令类型字服务端才能够通过该指定类型字找到指定的消息类(map来存储映射关系),此时在进行反序列化时就能够反序列化得到指定的实例类对象。
在该案例中,我们通过配置文件的方式来进行指定序列化算法(0-Java,1-JSON,按照枚举类顺序决定),对于传输的消息对象映射关系,我们直接存储在Message抽象类中:
①对于反序列化算法实现在一中已经给出。
②对于传输消息对象类型-类的关系在抽象类Message中维护
@Data
public abstract class Message implements Serializable {
public static final int LoginRequestMessage = 0;
public static final int LoginResponseMessage = 1;
public static final int ChatRequestMessage = 2;
public static final int ChatResponseMessage = 3;
//...
static {
messageClasses.put(LoginRequestMessage, LoginRequestMessage.class);
messageClasses.put(LoginResponseMessage, LoginResponseMessage.class);
messageClasses.put(ChatRequestMessage, ChatRequestMessage.class);
messageClasses.put(ChatResponseMessage, ChatResponseMessage.class);
//...
}
}
对于指定使用的序列化算法我们通过配置文件来配置,对应搭配一个Config配置类:
application.properties:
serialize.algorithm=Json
Config.class:
import com.changlu.protocol.serialize.Serializer;
import com.changlu.protocol.serialize.SerializerAlgorithm;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
/**
* @ClassName Config
* @Author ChangLu
* @Date 2022/1/15 15:20
* @Description 配置类
*/
public class Config {
static Properties properties;
public static byte serializerNum;
static {
try (InputStream is = Config.class.getResourceAsStream("/application.properties")) {
properties = new Properties();
properties.load(is);
init();
} catch (IOException e) {
throw new RuntimeException("读取配置文件/application.properties异常", e);
}
}
private static void init() {
//ordinal()则是指定枚举实例在枚举类中的顺序
serializerNum = (byte) getSerializerAlgorithm().ordinal();
}
/**
* 获取配置文件中的序列化方式
* @return 序列化算法实现枚举类
*/
public static SerializerAlgorithm getSerializerAlgorithm(){
String algorithmName = properties.getProperty("serialize.algorithm");
if (algorithmName == null) {
return SerializerAlgorithm.Java;
} else {
//从枚举类中根据序列化算法名字来取到枚举类算法实例
return SerializerAlgorithm.valueOf(algorithmName);
}
}
}
那么最终就是我们在自定义协议编解码器中的代码替换了,由原本的绑定JDK序列化算法,到现在的根据配置内容来进行调整序列化算法进行:
MessageCodecSharable.class:
@Slf4j
@ChannelHandler.Sharable
/**
* 必须和 LengthFieldBasedFrameDecoder 一起使用,确保接到的 ByteBuf 消息是完整的
*/
public class MessageCodecSharable extends MessageToMessageCodec<ByteBuf, Message> {
@Override
protected void encode(ChannelHandlerContext ctx, Message msg, List<Object> outList) throws Exception {
ByteBuf out = ctx.alloc().buffer();
//...其他字写入
// 指定的序列化算法(一个字节,从配置文件中读取)
out.writeByte(Config.serializerNum);
// 指令类型(一个字节)
out.writeByte(msg.getMessageType());
//原生JDK序列化
// ByteArrayOutputStream bos = new ByteArrayOutputStream();
// ObjectOutputStream oos = new ObjectOutputStream(bos);
// oos.writeObject(msg);
// byte[] bytes = bos.toByteArray();
// 根据序列化算法序号来从枚举类中取出指定的序列化实现算法
byte[] bytes = SerializerAlgorithm.values()[Config.serializerNum].serialize(msg);
// 7. 长度
out.writeInt(bytes.length);
// 8. 写入内容
out.writeBytes(bytes);
outList.add(out);
}
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
//...其他字写入
byte serializerType = in.readByte();//读取序列化算法
byte messageType = in.readByte();//读取之后进行反序列化得到的对象类型
//...其他字写入
in.readByte();//读取序列化字节数组
int length = in.readInt();
byte[] bytes = new byte[length];
in.readBytes(bytes, 0, length);
//原生JDK反序列化
// ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(bytes));
// Message message = (Message) ois.readObject();
//根据serializerType来从枚举类中取到序列化算法进行反序列化
Object message = SerializerAlgorithm.values([serializerType].deserialize(Message.getMessageClass(messageType), bytes);
out.add(message);
}
}
最终测试一下:




- 点赞
- 收藏
- 关注作者
评论(0)