JVM学习笔记 04、类加载与字节码技术(下)

2.5、类加载器
双亲委派类加载模式:每个类加载器各管一块,使用哪个类加载器加载类时首先会向上层进行询问!
| 名称 | 加载哪的类 | 说明 |
|---|---|---|
| Bootstrap ClassLoader | JAVA_HOME/jre/lib | 无法直接访问 |
| Extension ClassLoader | JAVA_HOME/jre/lib/ext | 上级为 Bootstrap,显示为 null |
| Application ClassLoader | classpath | 上级为 Extension |
| 自定义类加载器 | 自定义 | 上级为 Application |
-
Bootstrap ClassLoader:其中Bootstrap类加载器是由c++写的并由其进行调用,所有我们无法使用java代码来进行调用实现!
-
Application ClassLoader类加载器:classpath指的是加载类文件路径下的class类。
-
public class Test { public static void main(String[] args) { //获取当前类的类加载器 //sun.misc.Launcher$AppClassLoader@18b4aac2 System.out.println(Test.class.getClassLoader()); } }
-
-
自定义类加载器:自定义类加载器的路径可以进行自己定义。
2.5.1、启动类加载器
对于当前类路径下的类通过Application ClassLoader类加载器进行加载:
class F {
static {
System.out.println("bootstrap F init");
}
}
public class Main {
public static void main(String[] args) throws ClassNotFoundException {
Class<?> aClass = Class.forName("com.changlu.JVM.F");
System.out.println(aClass.getClassLoader());
}
}
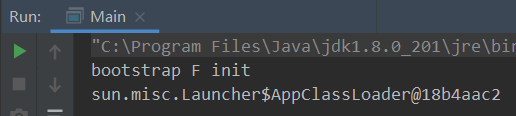
默认加载的话会使用Application ClassLoader类加载器,我们也可以通过设置指令参数将该路径添加到bootclasspath下,之后测试得到null就表明使用的是BootStrap类加载器进行加载:
-
参数:
java -Xbootclasspath/a:. cn.itcast.jvm.t3.load.Load5 -
-Xbootclasspath 表示设置 bootclasspath 其中 /a:. 表示将当前目录追加至 bootclasspath 之后 可以用这个办法替换核心类 java -Xbootclasspath:<new bootclasspath> java -Xbootclasspath/a:<追加路径>:后追加 java -Xbootclasspath/p:<追加路径>:前追加,一般使用前追加可以替换掉一些原有的核心类
理想效果如下:null则表示使用BootStrap类加载器进行加载

- 通常研究开发jvm的工程师会经常使用这类命令来进行替换jre/lib下的一些核心类库!
2.5.2、扩展类加载器
扩展类加载器读取JAVA_HOME/jre/lib/ext目录下的jar包文件!
实验:若是某个jar包预先放置到/ext目录下,我们在程序中再次加载同包名的class类,此时会重新加载吗?以及此时它的类加载器是哪一个?
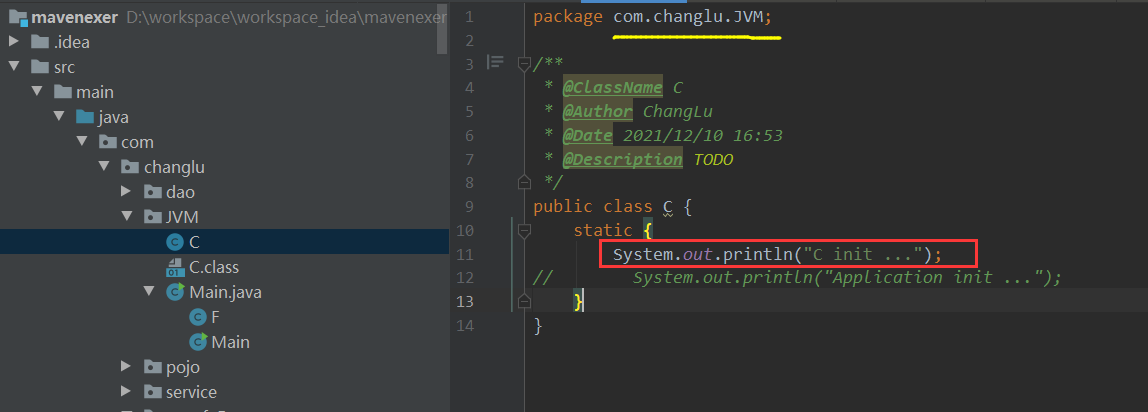
step1:编写一个名为C的类,其包名为com.changlu.JVM,添加初始化static的打印信息
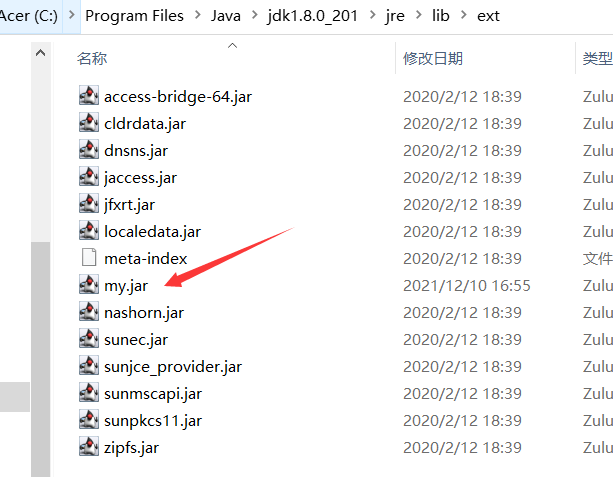
Step2:将该类打成jar包放置到/ext目录下
我们在java目录下使用命令来进行打包:jar -cvf my.jar com\changlu\JVM\C.class
打包完成之后我们将其添加到/ext目录
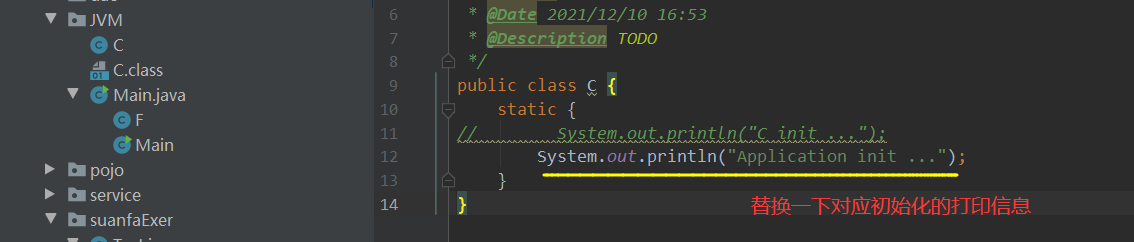
Step3:添加好之后一旦我们程序运行就会进行加载链接指定目录中的jar包,但是不会进行初始化,我们要做的就是在程序里使用java来进行动态加载另一个同包名的类,看一下此时加载的是哪一个Class类文件以及其对应的类加载器
public class Main {
public static void main(String[] args) throws ClassNotFoundException {
Class<?> aClass = Class.forName("com.changlu.JVM.C");//使用Class.forName来进行初始化该类
System.out.println(aClass.getClassLoader());
}
}
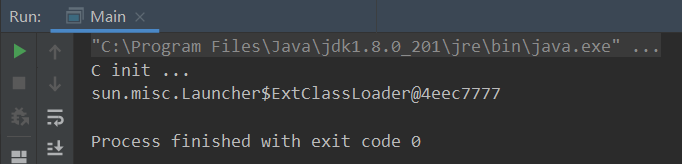
可以看到进行初始化的类文件是我们之前添加到/ext目录下的Class类,而不是我们后面使用程序加载的当前目录下的Class类。
结论:对于启动类加载器、扩展类加载器预先加载编译好的Class类,我们之后是不能够加载同包名的Class类的,使用Class.forName得到的Class对象也只是预先加载的类对象,那么自然其类加载器也就是初始时候进行加载的了,这就是双亲委派机制!
2.5.3、双亲委派模式
双亲委派:简单来说就是加载某个class类,首先会先去委派上级去加载,若是上级没有加载才会让本机的类加载器进行加载。
- 国内翻译过来是双亲委派机制,而上级委派机制应该更恰当一些。
测试程序:
package com.changlu.JVM;
class CL{
static {
System.out.println("Cl init .....");
}
}
public class Test {
public static void main(String[] args) throws ClassNotFoundException {
ClassLoader classLoader = Test.class.getClassLoader();
Class<?> aClass = classLoader.loadClass("com.changlu.JVM.CL");
System.out.println(aClass.getClassLoader());
}
}
源码分析:
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 1. 检查该类是否已经加载
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
// 2. 有上级的话,委派上级 loadClass
c = parent.loadClass(name, false);
} else {
//// 3. 如果没有上级了(ExtClassLoader),则委派BootstrapClassLoader
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
long t1 = System.nanoTime();
// 4. 每一层(扩展层、应用程序层)找不到,调用 findClass 方法(每个类加载器自己扩展)来加载。(若是找不到会抛出异常,在17行捕获)
c = findClass(name);
// 5. 记录耗时
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
执行流程为:
sun.misc.Launcher$AppClassLoader//1 处, 开始查看已加载的类,结果没有sun.misc.Launcher$AppClassLoader// 2 处,委派上级
sun.misc.Launcher$ExtClassLoader.loadClass()sun.misc.Launcher$ExtClassLoader// 1 处,查看已加载的类,结果没有sun.misc.Launcher$ExtClassLoader// 3 处,没有上级了,则委派BootstrapClassLoader
查找BootstrapClassLoader是在 JAVA_HOME/jre/lib 下找 H 这个类,显然没有sun.misc.Launcher$ExtClassLoader// 4 处,调用自己的 findClass 方法,是在
JAVA_HOME/jre/lib/ext 下找 H 这个类,显然没有,回到sun.misc.Launcher$AppClassLoader
的 // 2 处- 继续执行到
sun.misc.Launcher$AppClassLoader// 4 处,调用它自己的 findClass 方法,在
classpath 下查找,找到了
2.5.4、线程上下文类加载器(JDBC引出该加载器)
2.5.4.1、分析类加载器
我们在使用 JDBC 时,都需要加载 Driver 驱动,不知道你注意到没有,不写也是可以让 com.mysql.jdbc.Driver 正确加载的,你知道是怎么做的吗?
Class.forName("com.mysql.jdbc.Driver")
源码分析:
package java.sql;
public class DriverManager {
// 注册驱动的集合
private final static CopyOnWriteArrayList<DriverInfo> registeredDrivers
= new CopyOnWriteArrayList<>();
// 初始化驱动
static {
loadInitialDrivers();//在初始化操作中会进行初始化加载驱动
println("JDBC DriverManager initialized");
}
先不看别的,看看 DriverManager 的类加载器:其是JDK的核心类库默认由启动类加载器进行加载
System.out.println(DriverManager.class.getClassLoader());//null
打印 null,表示它的类加载器是 Bootstrap ClassLoader,会到 JAVA_HOME/jre/lib 下搜索类,但JAVA_HOME/jre/lib 下显然没有 mysql-connector-java-5.1.47.jar 包,这样问题来了,在DriverManager 的静态代码块中,怎么能正确加载 com.mysql.jdbc.Driver 呢?
继续看loadInitialDrivers()方法:也就是初始化方法,其中包含了两种方式来加载驱动第一种就是SPI,第二种就是
private static void loadInitialDrivers() {
String drivers;
try {
drivers = AccessController.doPrivileged(new PrivilegedAction<String>
() {
public String run() {
return System.getProperty("jdbc.drivers");
}
});
} catch (Exception ex) {
drivers = null;
}
// 1)使用 ServiceLoader 机制加载驱动,即 SPI
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
ServiceLoader<Driver> loadedDrivers =
ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
println("DriverManager.initialize: jdbc.drivers = " + drivers);
// 2)使用 jdbc.drivers 定义的驱动名加载驱动
if (drivers == null || drivers.equals("")) {
return;
}
String[] driversList = drivers.split(":");
println("number of Drivers:" + driversList.length);
for (String aDriver : driversList) {
try {
println("DriverManager.Initialize: loading " + aDriver);
// 这里的 ClassLoader.getSystemClassLoader() 就是应用程序类加载器。也就是说这里可以看到使用应用程序类加载器进行加载
Class.forName(aDriver, true,
ClassLoader.getSystemClassLoader());
} catch (Exception ex) {
println("DriverManager.Initialize: load failed: " + ex);
}
}
}
- 对于方式2:这里其实打破了双亲委派模式,实际上使用应用程序加载器来去加载的sql驱动实现类,否则有些类是找不到的。
针对于SPI加载机制来说明:对于SPI加载也必定会使用应用程序加载器来进行加载。
2.5.4.2、SPI类加载机制说明(引出线程上下文类加载器)
Service Provider Interface (SPI):约定如下,在 jar 包的 META-INF/services 包下,以接口全限定名名为文件,文件内容是实现类名称。
在META-INF目录下有services这个包,包下写上对应的接口类名,该接口类名则作为该文件名的名称,这个文件内容就是这个接口的实现类,只要按照约定来设计这个jar包,之后即可根据接口来找到对应的实现类并加以进行实例化,通过这样的形式能够实现解耦
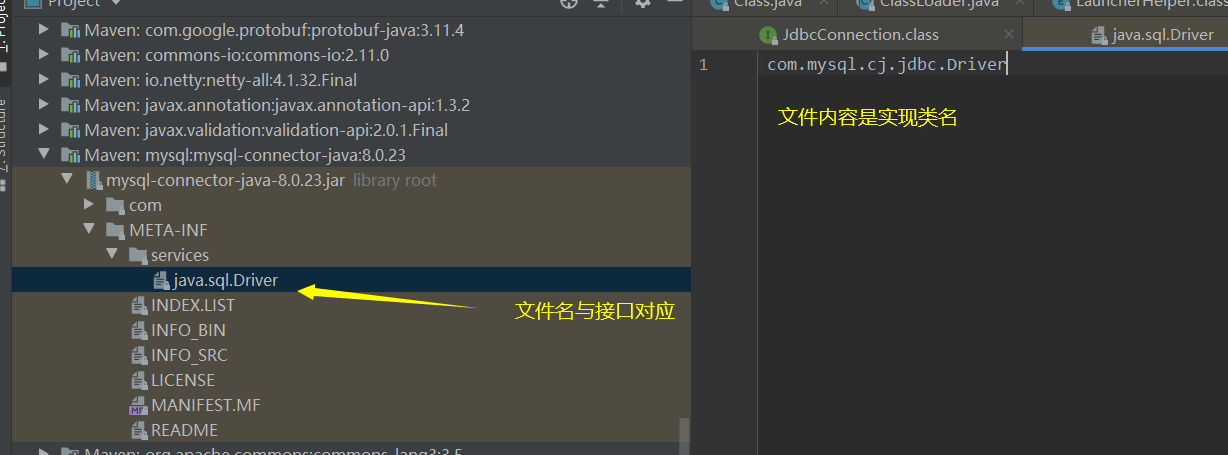
SPI类加载器使用:
public class Test {
public static void main(String[] args) throws ClassNotFoundException {
//使用SPI类加载器来进行加载定义好的接口名:java.sql.Driver。
// 此时内部底层就会使用应用程序加载器来进行加载以指定接口名为文件名中的实现类
ServiceLoader<Driver> load = ServiceLoader.load(Driver.class);
Iterator<Driver> iterator = load.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());//这里即可打印得到对应的接口驱动实现类
}
}
}
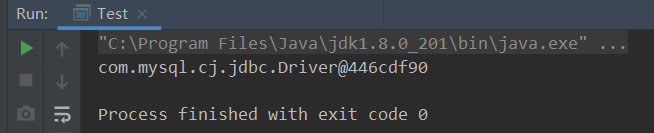
来得到实现类,体现的是【面向接口编程+解耦】的思想,在下面一些框架中都运用了此思想:
- JDBC
- Servlet 初始化器
- Spring 容器
- Dubbo(对 SPI 进行了扩展)
接着我们来看其ServiceLoader.load方法:
public static <S> ServiceLoader<S> load(Class<S> service) {
//通过当前线程对象来获取到类加载器就称为线程上下文类加载器
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
线程上下文类加载器是当前线程使用的类加载器,默认就是应用程序类加载器。它内部又是由Class.forName 调用了线程上下文类加载器完成类加载,具体代码在 ServiceLoader 的内部类LazyIterator 中:在调用next()的过程中完成实现类的初始化操作
//调用next()方法
public S next() {
if (acc == null) {
return nextService();
} else {
PrivilegedAction<S> action = new PrivilegedAction<S>() {
public S run() { return nextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
c = Class.forName(cn, false, loader);//此时你可以看到这里底层依旧使用的是Class.forName()来进行类加载
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}
2.5.5、自定义类加载器(含实操)
知识点补充
- 想加载非 classpath 随意路径中的类文件。
- 都是通过接口来使用实现,希望解耦时,常用在框架设计。
- 这些类希望予以隔离,不同应用的同名类都可以加载,不冲突,常见于 tomcat 容器。
自定义类加载器实现步骤:
1. 继承 ClassLoader 父类
2. 要遵从双亲委派机制,重写 findClass 方法(核心)
注意不是重写 loadClass 方法,否则不会走双亲委派机制。这个loadClass是给使用者来进行使用的
3. 读取类文件的字节码
4. 调用父类的 defineClass 方法来加载类
5. 使用者调用该类加载器的 loadClass 方法
实操
Step1:首先准备好一个class文件编译成class文件后放置在指定目录用于之后自定义类加载器来进行读取:
public class Test {
static {
System.out.println("Test init ....");
}
}

Step2:自定义类加载器,到指定类加载文件目录下进行读取指定的class文件
class MyClassLoader extends ClassLoader{
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
String path = "C:\\Users\\93997\\Desktop\\新建文件夹\\" + name + ".class";
ByteArrayOutputStream os = new ByteArrayOutputStream();
try {
//1、复制Class文件内容到字节数组输出流中
Files.copy(Paths.get(path), os);
//从字节数组输出流取得字节数组
byte[] bytes = os.toByteArray();
//2、生成Class对象返回:类名、读取的class字节数组、范围长度
return defineClass(name, bytes, 0, bytes.length);
} catch (IOException e) {
e.printStackTrace();
throw new ClassNotFoundException("类文件路径找不到");
}
}
}
Step3:使用自定义类加载器进行操作,我们同样来使用loadClass()进行加载指定的Class类文件,其内部会走双亲委派操作,并最终执行findClass方法也就是自定义重写的加载方法
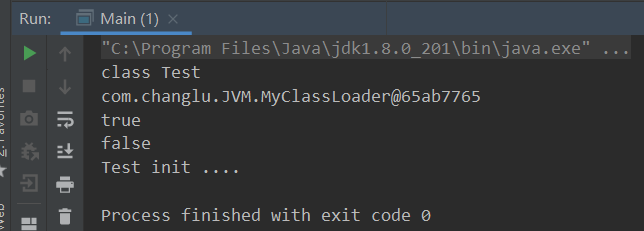
public class Main {
public static void main(String[] args) throws Exception {
//结论:同一个类加载器加载两次指定类取得的class类对象相同
MyClassLoader loader = new MyClassLoader();
Class<?> aClass = loader.loadClass("Test");
System.out.println(aClass);//class Test
System.out.println(aClass.getClassLoader());//com.changlu.JVM.MyClassLoader@65ab7765
Class<?> aClass2 = loader.loadClass("Test");
System.out.println(aClass == aClass2);//true
//结论:使用不同类加载器加载相同的class类文件取得的实例不相同
//原因:对于加载的类包名、类名、同一个加载器加载它们得到的class对象实例才是一致的,而这里由于类加载器不是同一个则导致最终实例不相同,不同类加载器进行加载时会进行相互隔离。
//也就是说使用其他类加载器加载的相同类文件,会覆盖原先的类对象!
//新的类加载器重新加载Test类
MyClassLoader loader2 = new MyClassLoader();
Class<?> aClass3 = loader2.loadClass("Test");
System.out.println(aClass3 == aClass);//false
//利用反射来尝试创建对象
aClass3.newInstance();//创建实例则会触发初始化动作,执行初始化内容 => Test init ....
}
}
2.6、运行期优化
2.6.1、即时编译
2.6.1.2、即时编译器
案例
首先我们来看下创建大量重复的对象锁耗费的时间
public class Main {
//-XX:+PrintCompilation -XX:-DoEscapeAnalysis。打印编译信息、关闭逃逸分析
//统计每创建1000个对象所耗费的纳秒数
public static void main(String[] args) throws Exception {
for (int i = 0; i < 200; i++) {
long start = System.nanoTime();
for (int j = 0; j < 1000; j++) {
new Object();
}
long end = System.nanoTime();
System.out.printf("%s\t%s\n", i, (end - start));
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-347PZirv-1651711342384)(https://pictuhttps://pictured-bed.oss-cn-beijing.aliyuncs.com/img/beifen-gitee/2021/20211211195843.png)]
效果:可以看到当创建到135*1000个对象时,此时创建速度快了100倍,这就与即时编译器相关。
分析
JVM 将执行状态分成了 5 个层次:
- 0 层,解释执行(Interpreter)
- 1 层,使用 C1 即时编译器编译执行(不带 profiling)
- 2 层,使用 C1 即时编译器编译执行(带基本的 profiling)
- 3 层,使用 C1 即时编译器编译执行(带完全的 profiling)
- 4 层,使用 C2 即时编译器编译执行
解释(以下是听课记录):在运行期间JVM会为我们的代码做优化
即时编译器与解释器区别:解释器是边解释边执行;即时编译器就是将返回执行的代码变成机器码,之后存储在一个CodeCache缓存中,此时增加了缓存之后要是再要运行就不会进行解释步骤了会直接将编译好的机器码直接进行使用。效率比逐行解释一定会高。
C1与C2的区别:就是优化程度的不一样,C1的话就是仅仅做一些基本的优化;C2则是更完全彻底的优化。
C1效率能提升5倍左右;C2能够提升10-100倍。
profiling 是指在运行过程中收集一些程序执行状态的数据,例如【方法的调用次数】,【循环的回边次数】等,其是信息统计操作,在代码运行期间会收集字节码运行状态的数据,进行统计信息。
即时编译器(JIT)与解释器的区别:
-
解释器是将字节码解释为机器码,下次即使遇到相同的字节码,仍会执行重复的解释
-
JIT 是将一些字节码编译为机器码,并存入 Code Cache,下次遇到相同的代码,直接执行,无需再编译
-
解释器是将字节码解释为针对所有平台都通用的机器码
-
JIT 会根据平台类型,生成平台特定的机器码
对于占据大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,以达到理想的运行速度。 执行效率上简单比较一下 Interpreter < C1 < C2,总的目标是发现热点代码(hotspot名称的由来)。
2.6.1.3、逃逸分析(分析)
默认JVM是开启逃逸分析的,就拿2.6.1.2中举例来说,JVM会分析整个new Object()是否在循环外被使用到或者说被其他方法进行引用,若是没有就会采取优化手段:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Nx7SgNeu-1651711342384)(https://pictuhttps://pictured-bed.oss-cn-beijing.aliyuncs.com/img/beifen-gitee/2021/20211211200829.png)]
没有则表示该对象不会逃逸,外界不会用到该对象,既然不会用到那就不必创建它,这也是为什么之后速度这么快的原因,这个逃逸分析是在C2编译器中做的优化,会把对应的创建对象字节码进行替换掉
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NYi0i2RG-1651711342384)(https://pictuhttps://pictured-bed.oss-cn-beijing.aliyuncs.com/img/beifen-gitee/2021/20211211201157.png)]
关闭逃逸分析vm参数(手动关闭):-XX:+PrintCompilation -XX:-DoEscapeAnalysis,关闭了之后就不会到达C2编译器的逃逸优化阶段了!
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Dh3B9I7n-1651711342385)(https://pictuhttps://pictured-bed.oss-cn-beijing.aliyuncs.com/img/beifen-gitee/2021/20211211202207.png)]
2.6.2、方法内联
优化策略(默认开启)
一句话:将函数中的代码拷贝到方法调用者部分去,针对于一些高频及较短函数方法。
private static int square(final int i) {
return i * i;
}
System.out.println(square(9));
优化点1:如果发现 square 是热点方法,并且长度不太长时,会进行内联,所谓的内联就是把方法内代码拷贝、粘贴到调用者的位置。
System.out.println(9 * 9);
优化点2:还能够进行常量折叠(constant folding)的优化,若是某个方法长期取得同一个结果就会执行常量折叠优化
System.out.println(81);
实操:
public class Main {
// -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining (解锁隐藏参数)打印
inlining 信息
// -XX:CompileCommand=dontinline,*JIT2.square 禁止类名中带有JIT2某个方法 inlining
// -XX:+PrintCompilation 打印编译信息
public static void main(String[] args) {
int x = 0;
for (int i = 0; i < 500; i++) {
//对1000次方法调用时间进行统计
long start = System.nanoTime();
for (int j = 0; j < 1000; j++) {
x = square(9);
}
long end = System.nanoTime();
System.out.printf("%d\t%d\t%d\n", i, x, (end - start));
}
}
private static int square(final int i) {
return i * i;
}
}
效果:可以看到到之后791*1000次调用时,其速度已经被优化到0,也就是说进行方法内联两个优化后,压根没有进行方法调用操作。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UM3XS6MX-1651711342385)(https://pictuhttps://pictured-bed.oss-cn-beijing.aliyuncs.com/img/beifen-gitee/2021/20211211203651.png)]
虚拟机参数1:-XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining,打印内联信息
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LnIKkK9R-1651711342385)(https://pictuhttps://pictured-bed.oss-cn-beijing.aliyuncs.com/img/beifen-gitee/2021/20211211204501.png)]
虚拟机参数2:-XX:CompileCommand=dontinline,*Main.square,禁用类名为含有Main的square方法进行内联(指定类中的指定方法)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GIiEsEiX-1651711342385)(https://pictuhttps://pictured-bed.oss-cn-beijing.aliyuncs.com/img/beifen-gitee/2021/20211211204708.png)]
2.6.3、字段优化
字段优化:针对于成员变量、静态成员变量的读写操作的优化,对于经常要进行读写的进行缓存优化!
2.6.3.1、JMH 基准测试
笔记-JMH(Java Microbenchmark Harness):包含介绍、注解描述信息
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.9.3</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.9.3</version>
<scope>provided</scope>
</dependency>
进行基准测试:对三种遍历取数组的方式进行测试
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.Random;
import java.util.concurrent.ThreadLocalRandom;
@Warmup(iterations = 2, time = 1) //让jvm进行热身,让jvm对代码进行一系列相关优化
@Measurement(iterations = 5, time = 1) //进行五轮测试
@State(Scope.Benchmark)
public class Benchmark1 {
int[] elements = randomInts(1_000);
private static int[] randomInts(int size) {
Random random = ThreadLocalRandom.current();
int[] values = new int[size];
for (int i = 0; i < size; i++) {
values[i] = random.nextInt();
}
return values;
}
@Benchmark //将要进行对比测试的
public void test1() {
for (int i = 0; i < elements.length; i++) {
doSum(elements[i]);
}
}
@Benchmark
public void test2() {
int[] local = this.elements;
for (int i = 0; i < local.length; i++) {
doSum(local[i]);
}
}
@Benchmark
public void test3() {
for (int element : elements) {
doSum(element);
}
}
static int sum = 0;
@CompilerControl(CompilerControl.Mode.INLINE) //编译控制该方法进行内联,这里允许方法的内联
static void doSum(int x) {
sum += x;
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(Benchmark1.class.getSimpleName())
.forks(1)
.build();
new Runner(opt).run();
}
}
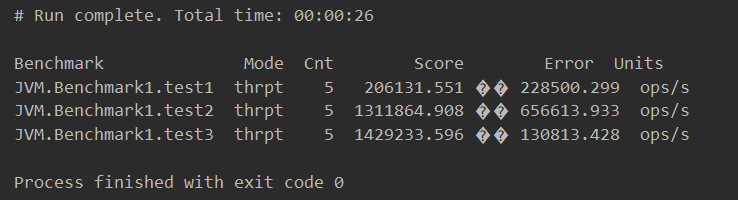
我们可以看到使用了方法内联每秒的被调用此时可以达到百万级别,禁用方法内联时调用测试仅仅只有十几二十万次:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4dilJOgV-1651711342385)(https://pictuhttps://pictured-bed.oss-cn-beijing.aliyuncs.com/img/beifen-gitee/2021/20211211212756.png)]
针对于三种不同的方法取值其底层优化方式不同而导致ops的此时相差较大,在下面2.6.3.2中进行分析。
2.6.3.2、分析
static void doSum(int x) { //要进行内联优化的代码
sum += x;
}
@Benchmark //将要进行对比测试的
public void test1() { // =>运行期间优化
for (int i = 0; i < elements.length; i++) {
doSum(elements[i]);
}
}
@Benchmark
public void test2() { // =>自己手动优化
int[] local = this.elements;
for (int i = 0; i < local.length; i++) {
doSum(local[i]);
}
}
@Benchmark
public void test3() { // =>编译器进行优化
for (int element : elements) {
doSum(element);
}
}
在刚才的示例中,doSum 方法是否内联会影响 elements 成员变量读取的优化:
如果 doSum 方法内联了,刚才的 test1 方法会被优化成下面的样子(伪代码)
@Benchmark
public void test1() {
// elements.length 首次读取会缓存起来 -> int[] local
for (int i = 0; i < elements.length; i++) { // 后续 999 次 求长度 <- local
sum += elements[i]; // 1000 次取下标 i 的元素 <- local
}
}
可以节省 1999 次 Field 读取操作,但如果 doSum 方法没有内联,则不会进行上面的优化!
- 局部变量存储在帧栈中,而静态、成员变量存储在堆中,通过该优化之后存取速度也会提升!
如果自己想要进行优化,尽可能使用局部变量不要使用成员变量以及静态成员变量,忘了也没事当其称为热点代码之后通过方法内联会自动帮你做优化。
2.6.3.3、数组成员变量添加volatile+方法内联
volatile int[] elements = randomInts(1_000);
效果:可以看到方法一的ops大大减少,说明尽管jvm会进行方法内联优化,但是对于volatile修改的成员变量并不会单独额外进行缓存!
2.6.4、反射优化
2.6.4.1、案例介绍+源码分析
下面的方法是对反射方法进行15次调用:
import java.lang.reflect.Method;
/**
* @ClassName Reflect1
* @Author ChangLu
* @Date 2021/12/12 10:51
* @Description TODO
*/
public class Reflect1 {
public static void foo(){
System.out.println("foo...");
}
public static void main(String[] args)throws Exception {
Method foo = Reflect1.class.getMethod("foo");
for (int i = 0; i <= 16; i++) {
System.out.println(i);
foo.invoke(null);//进行反射方法调用
}
System.in.read();
}
}
foo.invoke 前面 0 ~ 15 次调用使用的是 MethodAccessor 的 NativeMethodAccessorImpl 实现
@CallerSensitive
public Object invoke(Object obj, Object... args)
throws IllegalAccessException, IllegalArgumentException,
InvocationTargetException
{
if (!override) {
if (!Reflection.quickCheckMemberAccess(clazz, modifiers)) {
Class<?> caller = Reflection.getCallerClass();
checkAccess(caller, clazz, obj, modifiers);
}
}
MethodAccessor ma = methodAccessor; //方法访问器 // read volatile
if (ma == null) {
ma = acquireMethodAccessor();
}
return ma.invoke(obj, args);//调用方法访问器的invoke方法来进行调用
}
默认的话初始进行反射调用都是走的本地方法访问器访问:
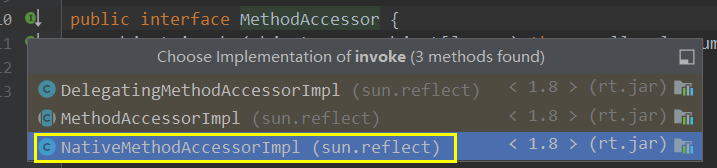
本地方法的性能调用起来比较低,前十五次调用的是本地方法,膨胀阈值为15
调换本地方法访问器为一个运行期间动态生成的新的方法访问器,根据当前调用的方法信息来生成访问器。其无源代码是在运行期间生成的。
public Object invoke(Object var1, Object[] var2) throws IllegalArgumentException, InvocationTargetException {
//比较膨胀阈值 ,默认是15次,也就是说第16次的时候会进行反射优化,使用运行期间动态生成的新的方法访问器
if (++this.numInvocations > ReflectionFactory.inflationThreshold() && !ReflectUtil.isVMAnonymousClass(this.method.getDeclaringClass())) {
//该访问器中的invoke方法实际本质就是直接调用方法,能够提升运行效率
// 使用 ASM 动态生成的新实现代替本地实现,速度较本地实现快 20 倍左右
MethodAccessorImpl var3 = (MethodAccessorImpl)(new MethodAccessorGenerator()).generateMethod(this.method.getDeclaringClass(), this.method.getName(), this.method.getParameterTypes(), this.method.getReturnType(), this.method.getExceptionTypes(), this.method.getModifiers());//传入关于该类的相关信息
this.parent.setDelegate(var3);
}
// 调用本地实现
return invoke0(this.method, var1, var2);
}
2.6.4.2、arthas-boot来查看动态生成的方法访问器
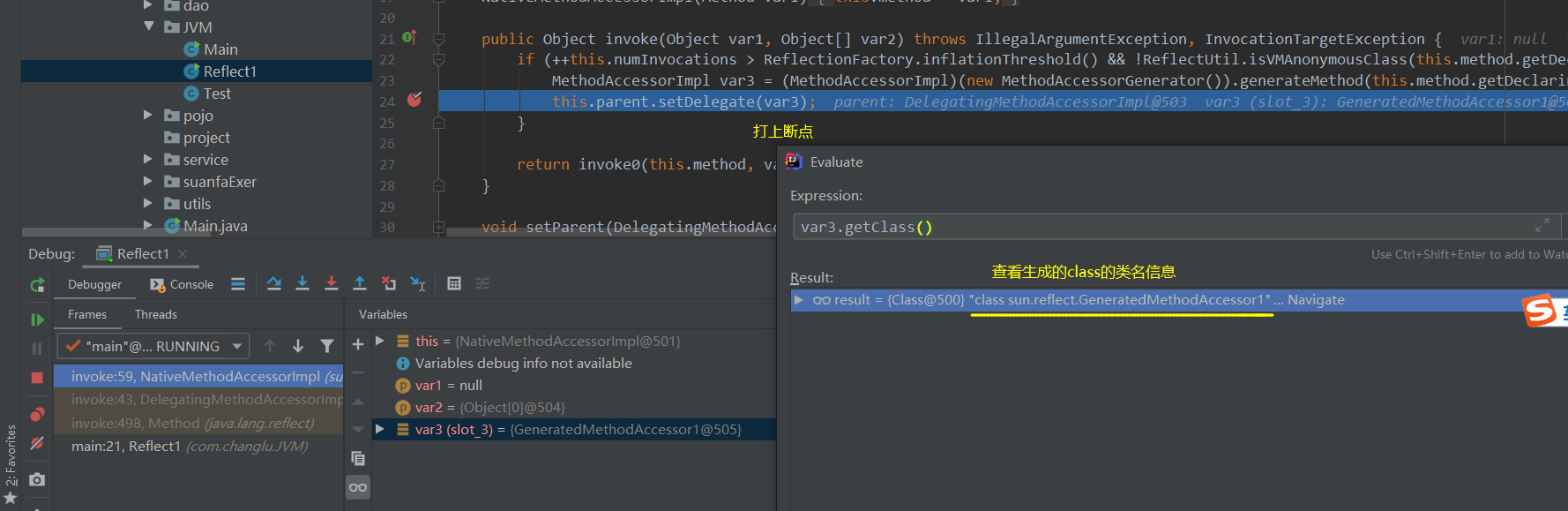
对于在16次调用指定的方法反射时,就会在运行期间创建一个方法访问器,该访问器由于是运行期间产生的所以无法在源码中查看,在这里我们使用arthas-boot工具俩进行查看:arthas-boot 使用
首先通过打上断点来查看动态生成的方法访问器的类名信息:
运行案例demo,并让其处在运行过程中:
# 运行arthas-boot的jar包
java -jar arthas-boot.jar
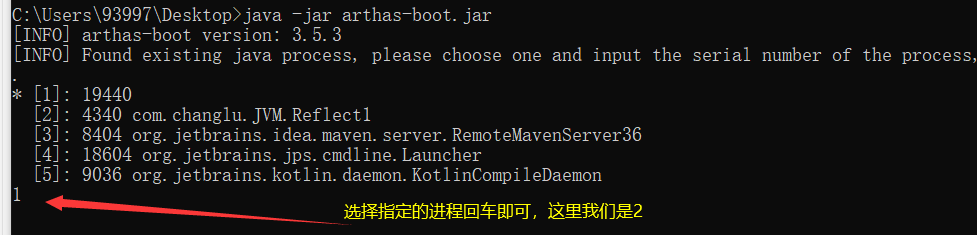
此时会与当前运行的项目进行连接,此时我们与当前运行的项目连接起来了,接下来我们就是要查看当前运行时创建的class类(使用jad):jad sun.reflect.GeneratedMethodAccessor1
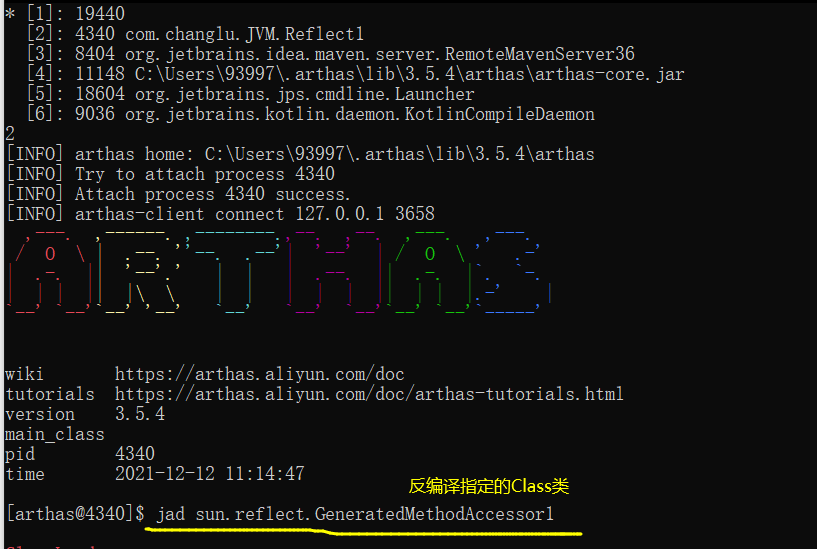
下面就是动态生成的Class类,我们可一看到其中反射方法是直接进行类名.方法的调用执行的!
/*
* Decompiled with CFR.
*
* Could not load the following classes:
* com.changlu.JVM.Reflect1
*/
package sun.reflect;
import com.changlu.JVM.Reflect1;
import java.lang.reflect.InvocationTargetException;
import sun.reflect.MethodAccessorImpl;
public class GeneratedMethodAccessor1
extends MethodAccessorImpl {
/*
* Loose catch block
*/
public Object invoke(Object object, Object[] objectArray) throws InvocationTargetException {
// 比较奇葩的做法,如果有参数,那么抛非法参数异常
block4: {
if (objectArray == null || objectArray.length == 0) break block4;
throw new IllegalArgumentException();
}
try {
// 可以看到,已经是直接调用了😱😱😱
Reflect1.foo();
// 因为没有返回值
return null;
}
catch (Throwable throwable) {
throw new InvocationTargetException(throwable);
}
catch (ClassCastException | NullPointerException runtimeException) {
throw new IllegalArgumentException(super.toString());
}
}
}
那么本质就是:某个反射方法调用次数达到阈值就会将原本的方法访问器调用反射方法转为正常方法调用以达到优化的效果。
2.6.4.3、自定义膨胀阈值以及是否动态生成
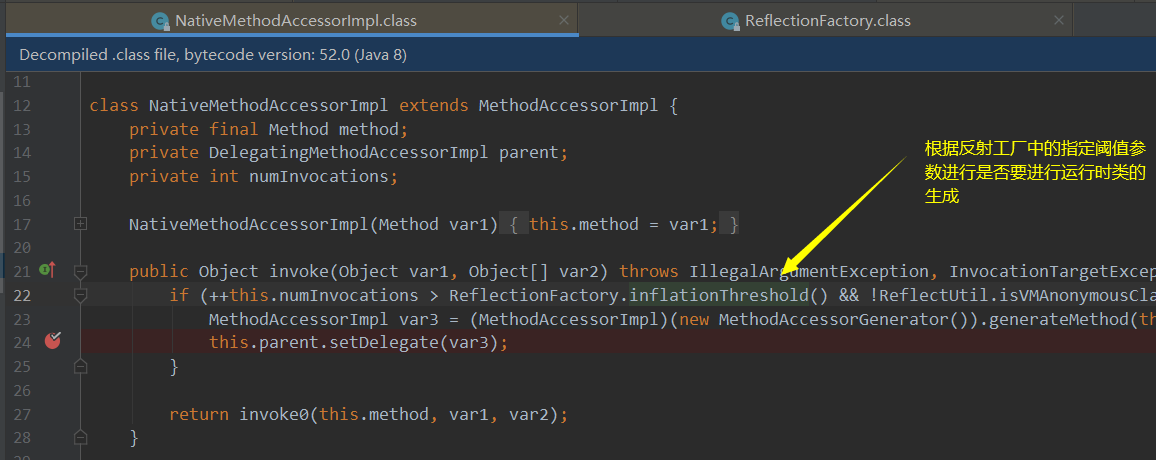
在反射工厂中碰撞阈值、是否反射优化的读取是通过环境变量来进行设置的:
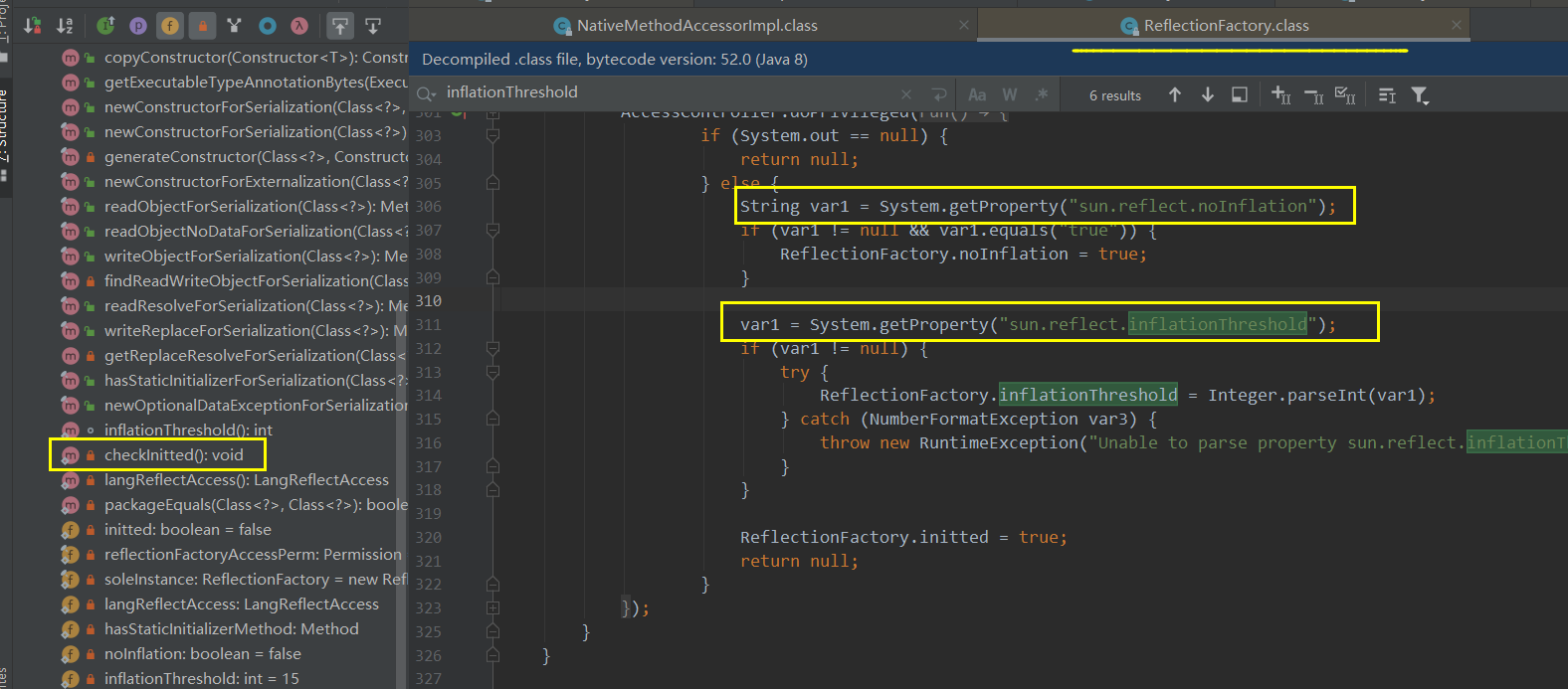
设置方式:-Dsun.reflect.inflationThreshold=5 -Dsun.reflect.noInflation=true,前者是膨胀阈值的次数、后者设置为true则表示不会进行反射优化也就是运行期动态生成的方法访问器
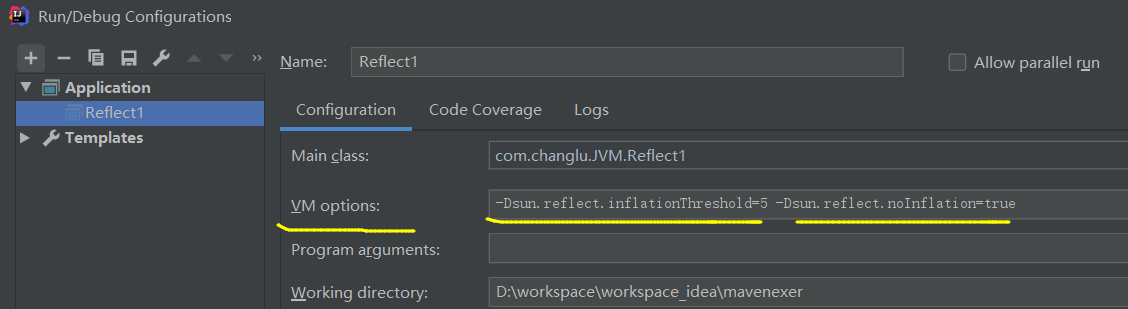
- sun.reflect.noInflation:可以用来禁用膨胀(直接生成 GeneratedMethodAccessor1,但首次生成比较耗时,如果仅反射调用一次,不划算)
- sun.reflect.inflationThreshold:可以修改膨胀阈值
参考文章
[1]. jvm类加载和解析过程(总结性质)

- 点赞
- 收藏
- 关注作者
评论(0)