【Datawhale动手学数据分析笔记】第四章 数据可视化

【摘要】 数据可视化数据可视化,主要给大家介绍一下Python数据可视化库Matplotlib,在本章学习中,你也许会觉得数据很有趣。在打比赛的过程中,数据可视化可以让我们更好的看到每一个关键步骤的结果如何,可以用来优化方案,是一个很有用的技巧。 导入numpy、pandas包和数据# 加载所需的库# 如果出现 ModuleNotFoundError: No module named 'xxxx'#...
数据可视化
数据可视化,主要给大家介绍一下Python数据可视化库Matplotlib,在本章学习中,你也许会觉得数据很有趣。在打比赛的过程中,数据可视化可以让我们更好的看到每一个关键步骤的结果如何,可以用来优化方案,是一个很有用的技巧。
导入numpy、pandas包和数据
# 加载所需的库
# 如果出现 ModuleNotFoundError: No module named 'xxxx'
# 你只需要在终端/cmd下 pip install xxxx 即可
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
环境没有安装这三个库的话执行以下命令安装相应的库
pip install pandas
pip install numpy
pip install matplotlib
导入result.csv这个文件
text = pd.read_csv(r'result.csv')
text.head()
结果:

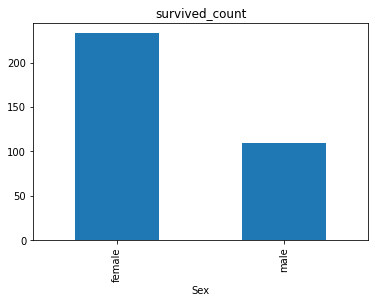
可视化展示泰坦尼克号数据集中男女中生存人数分布情况(用柱状图试试)
sex = text.groupby('Sex')['Survived'].sum()
sex.plot.bar()
plt.title('survived_count')
plt.show()
结果:
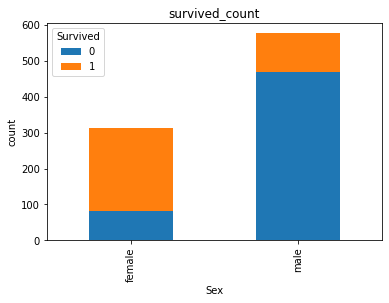
可视化展示泰坦尼克号数据集中男女中生存人与死亡人数的比例图(用柱状图试试)
# 提示:计算男女中死亡人数 1表示生存,0表示死亡
text.groupby(['Sex','Survived'])['Survived'].count().unstack().plot(kind='bar',stacked='True')
plt.title('survived_count')
plt.ylabel('count')
结果:
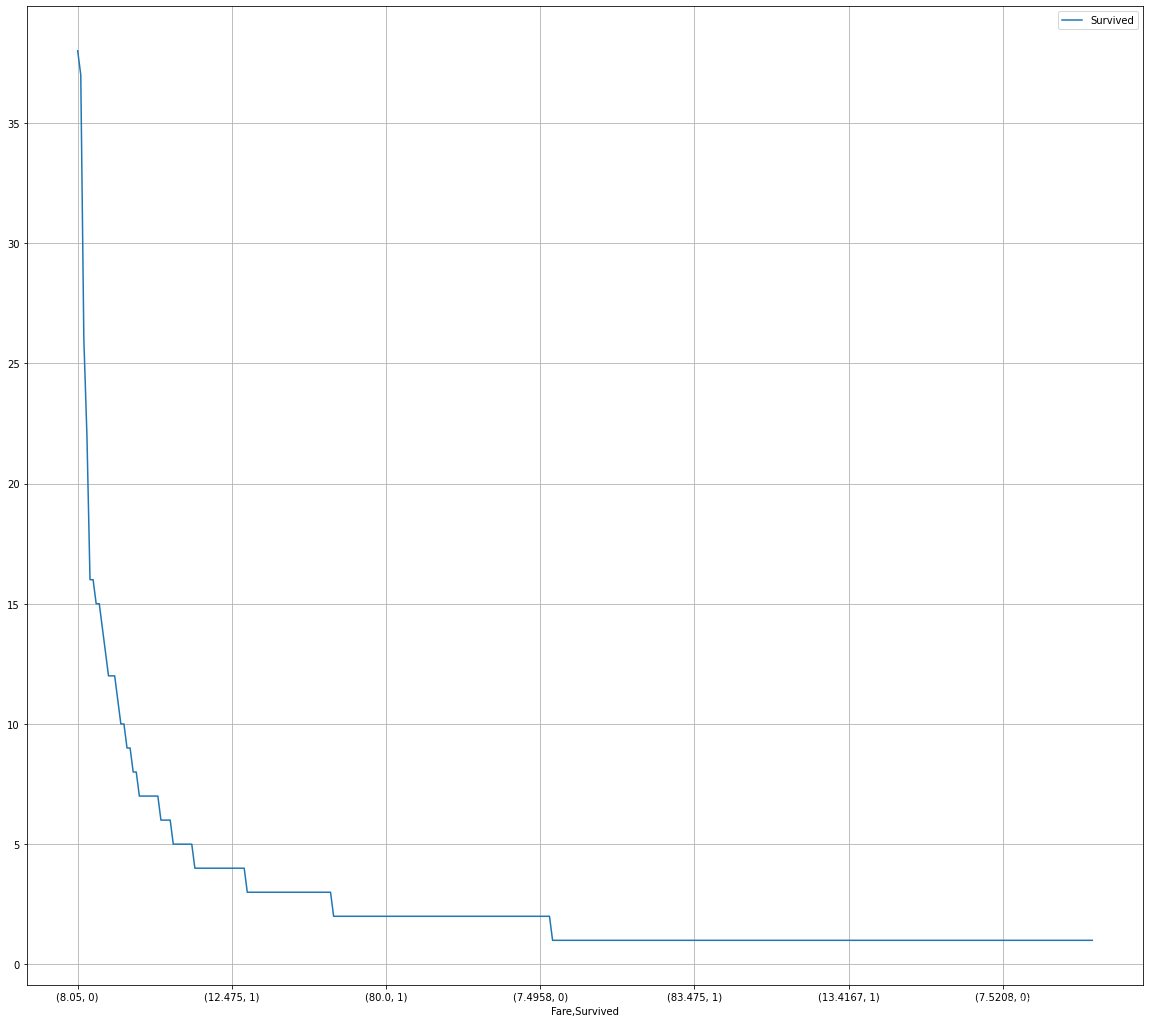
可视化展示泰坦尼克号数据集中不同票价的人生存和死亡人数分布情况(用折线图试试)(横轴是不同票价,纵轴是存活人数)
# 计算不同票价中生存与死亡人数 1表示生存,0表示死亡
fare_sur = text.groupby(['Fare'])['Survived'].value_counts().sort_values(ascending=False)
fare_sur
运行结果
Fare Survived
8.0500 0 38
7.8958 0 37
13.0000 0 26
7.7500 0 22
13.0000 1 16
..
7.7417 0 1
26.2833 1 1
7.7375 1 1
26.3875 1 1
22.5250 0 1
Name: Survived, Length: 330, dtype: int64
# 排序后绘折线图
fig = plt.figure(figsize=(20, 18))
fare_sur.plot(grid=True)
plt.legend()
plt.show()
结果:
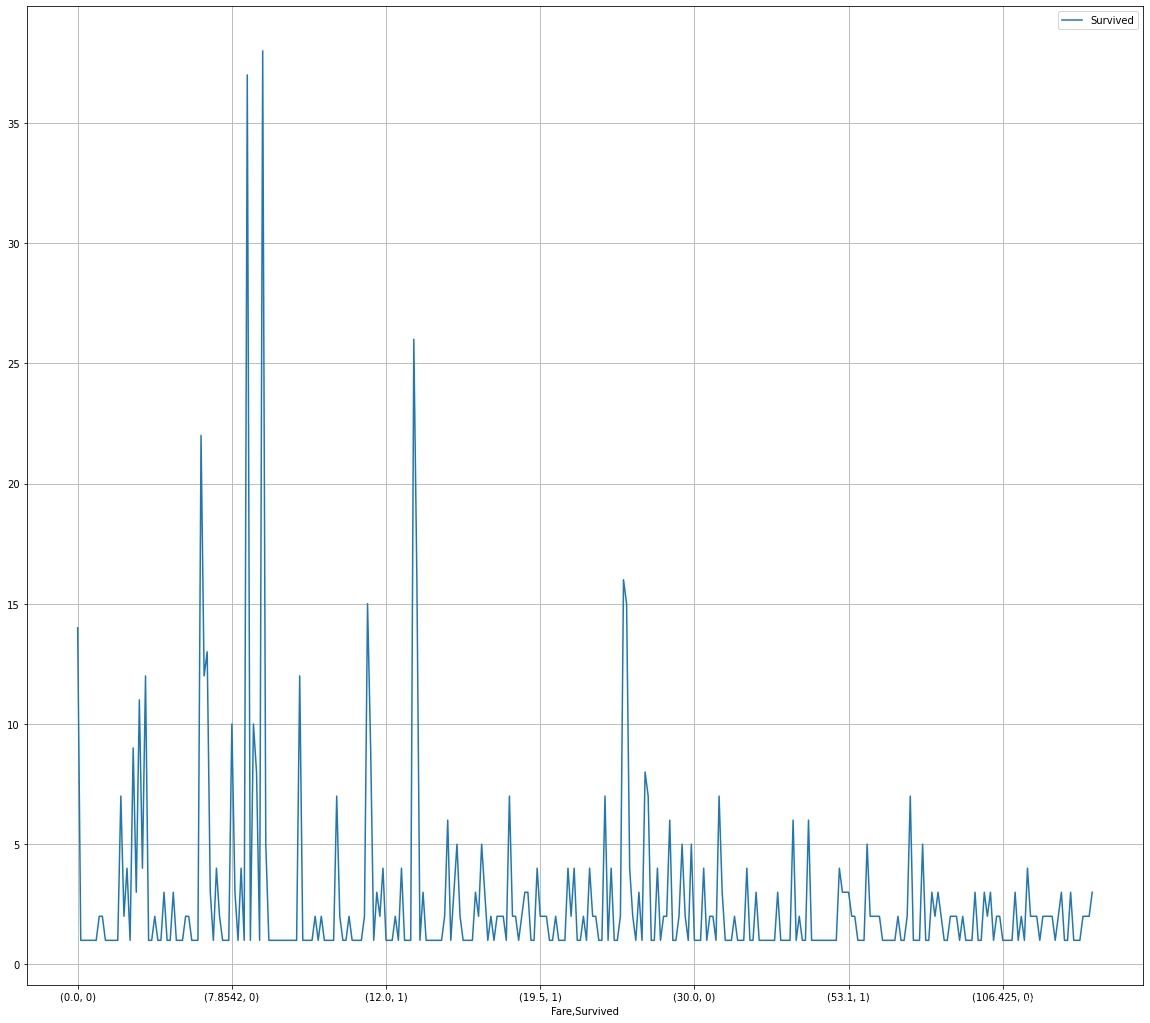
# 排序前绘折线图
fare_sur1 = text.groupby(['Fare'])['Survived'].value_counts()
fare_sur1
运行结果:
Fare Survived
0.0000 0 14
1 1
4.0125 0 1
5.0000 0 1
6.2375 0 1
..
247.5208 1 1
262.3750 1 2
263.0000 0 2
1 2
512.3292 1 3
Name: Survived, Length: 330, dtype: int64
fig = plt.figure(figsize=(20, 18))
fare_sur1.plot(grid=True)
plt.legend()
plt.show()
结果:
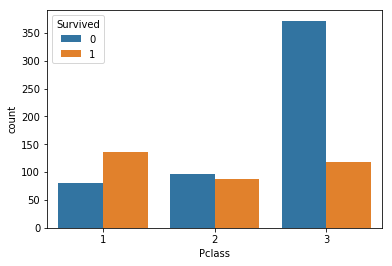
可视化展示泰坦尼克号数据集中不同仓位等级的人生存和死亡人员的分布情况。(用柱状图试试)
# 1表示生存,0表示死亡
pclass_sur = text.groupby(['Pclass'])['Survived'].value_counts()
pclass_sur
运行结果:
Pclass Survived
1 1 136
0 80
2 0 97
1 87
3 0 372
1 119
Name: Survived, dtype: int64
import seaborn as sns
sns.countplot(x="Pclass", hue="Survived", data=text)
结果:
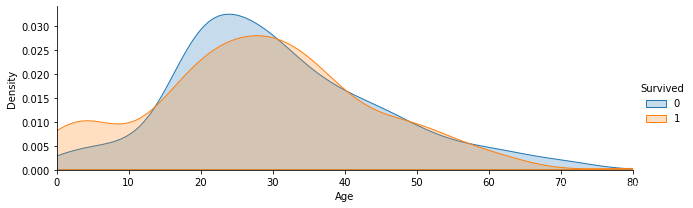
可视化展示泰坦尼克号数据集中不同年龄的人生存与死亡人数分布情况。(不限表达方式)
这一步需要使用到seaborn包,安装seaborn包如下
pip install seaborn
import seaborn as sns
facet = sns.FacetGrid(text, hue="Survived",aspect=3)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, text['Age'].max()))
facet.add_legend()
结果:
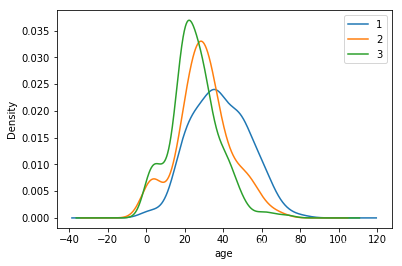
可视化展示泰坦尼克号数据集中不同仓位等级的人年龄分布情况。(用折线图试试)
text.Age[text.Pclass == 1].plot(kind='kde')
text.Age[text.Pclass == 2].plot(kind='kde')
text.Age[text.Pclass == 3].plot(kind='kde')
plt.xlabel("age")
plt.legend((1,2,3),loc="best")
结果:

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)